基于深度学习的杂草检测系统演示与介绍(YOLOv12/v11/v8/v5模型+Pyqt5界面+训练代码+数据集)
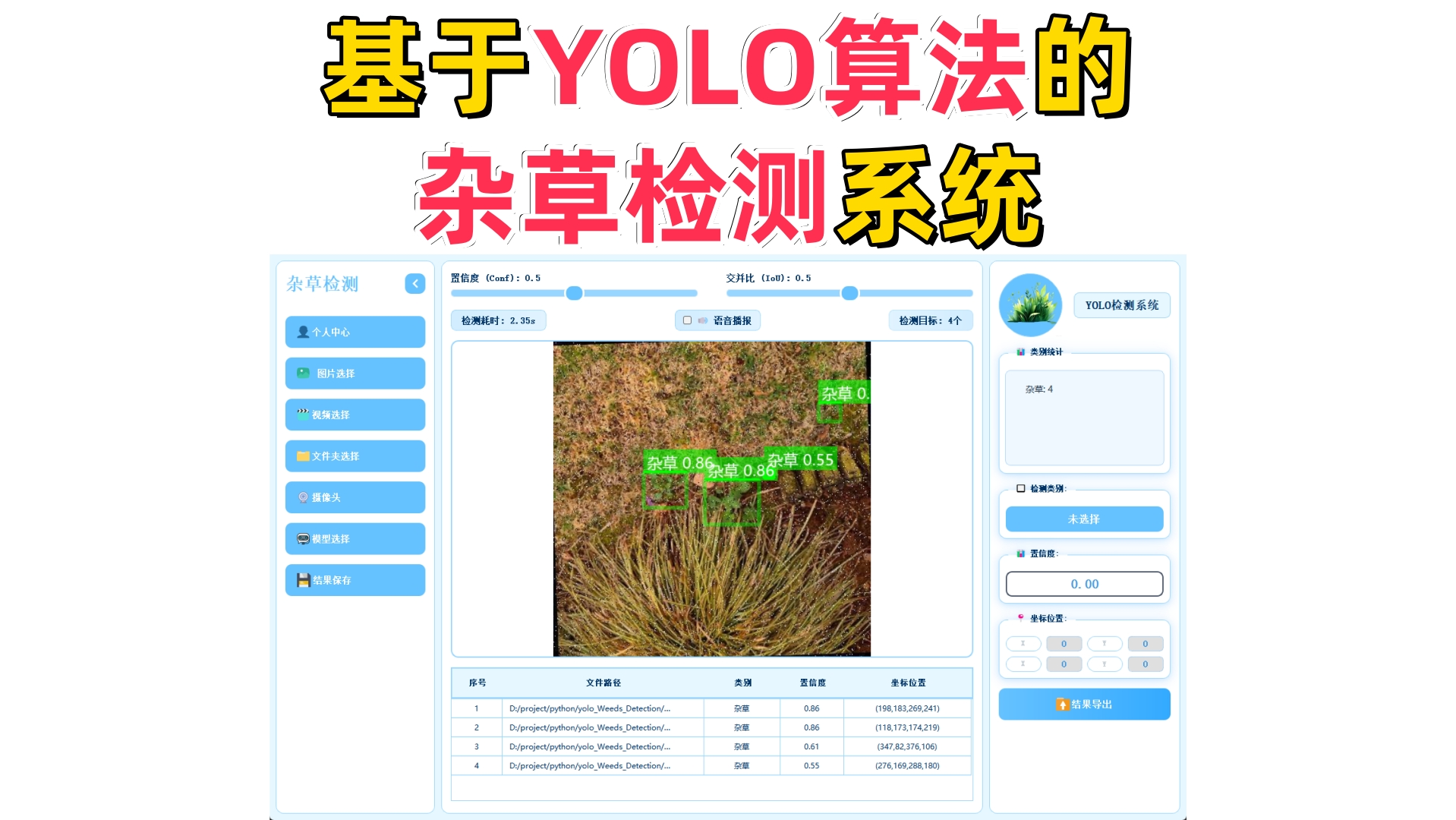 本文介绍了一套基于YOLO算法的杂草检测系统,支持图片、视频及实时视频流的多模态检测。系统具备模型管理、结果导出、参数调节、语音提醒等功能,采用YOLOv5/v8/v11/v12等模型进行训练,在4000张农田影像数据集上实现了87.5%的mAP@0.5准确率。其中YOLO12n模型表现最优(mAP40.6%),YOLO11n推理速度最快(56.1ms)。系统提供完整的训练脚本和跨平台部署方案,可应用于精准农业中的杂草识别与自动化除草场景。
本文介绍了一套基于YOLO算法的杂草检测系统,支持图片、视频及实时视频流的多模态检测。系统具备模型管理、结果导出、参数调节、语音提醒等功能,采用YOLOv5/v8/v11/v12等模型进行训练,在4000张农田影像数据集上实现了87.5%的mAP@0.5准确率。其中YOLO12n模型表现最优(mAP40.6%),YOLO11n推理速度最快(56.1ms)。系统提供完整的训练脚本和跨平台部署方案,可应用于精准农业中的杂草识别与自动化除草场景。
视频演示
1. 前言
在农业生产中,杂草的及时检测与精准识别对作物生长、产量保障及农药科学施用具有重要意义。传统杂草识别多依赖人工田间巡查或人工判读影像,不仅费时费力,而且受主观经验和环境条件影响,易出现漏检或误判。随着精准农业和智慧农业的发展,利用计算机视觉与深度学习技术实现自动化杂草检测成为研究热点。
目前,基于深度学习的目标检测算法已在植物表型分析和农田监测中得到应用,其中 YOLO 系列算法因检测速度快、精度高,尤其适合大田实时监测与边缘设备部署。然而,现有杂草检测系统往往仅支持单一图片检测,缺乏视频流实时检测、批量处理、结果提醒与导出、便捷模型训练及跨平台脚本化部署等综合功能,难以满足实际农业生产中对高效、易用、可扩展检测工具的需求。
本文设计并实现了一套 基于 YOLO 算法的杂草检测系统,能够自动检测图片与视频中的杂草目标,并输出类别、置信度及位置信息。
系统主要功能包括:
-
多源检测:支持单张图片、视频文件、文件夹批量图片及摄像头实时视频流的杂草检测。
-
模型管理:可灵活选择不同训练好的模型进行检测,并支持加载自定义权重文件。
-
结果处理:可将检测结果叠加到图片或视频中并保存为新文件,支持导出检测数据至 Excel 表格,便于后续统计与分析。
-
参数调节:提供置信度与交并比等检测参数的动态调节,可按需过滤低置信度目标。
-
智能提醒:检测到目标时可进行语音播报提醒,播报内容可自定义替换,适用于无人值守或视觉关注受限的场景。
-
用户管理:具备登录、注册、个人信息修改及注销功能,保障系统与数据安全。
-
脚本检测:提供无界面脚本模式,可在服务器或嵌入式设备上批量或实时检测图片、视频和摄像头视频流,便于生产环境部署。
-
模型训练:内置多模型训练脚本,支持批量训练并可配置训练轮次与批次大小,输出最佳权重文件及评估指标(F1 曲线、混淆矩阵、标注示例等),方便用户基于自有数据优化模型。
系统基于 22,000 余张农田影像数据进行训练,涵盖训练集、验证集与测试集,确保模型具备良好的泛化能力与检测稳定性。可广泛应用于大田监测、精准除草、农业机器人视觉感知等场景,为智慧农业提供高效、准确且具备实时语音提醒能力的杂草检测方案。
系统主要功能包括:
-
多源检测:支持单张图片、视频文件、文件夹批量图片及摄像头实时视频流的船舶分类检测。
-
模型管理:可灵活选择不同训练好的模型进行检测,并支持加载自定义权重文件。
-
结果处理:可将检测结果叠加到图片或视频中并保存,支持导出检测数据到 Excel 表格,便于后续分析与存档。
-
参数调节:提供置信度与交并比等检测参数的动态调节,以适配不同场景需求。
-
智能提醒:支持检测到目标时的语音播报提醒,可自定义播报内容,便于在无视觉关注的情况下及时获知检测结果。
-
用户管理:具备登录、注册、个人信息修改及注销功能,保障系统与数据安全。
-
脚本检测:提供无界面脚本模式,可在服务器或嵌入式设备上批量或实时检测图片、视频和摄像头视频流,便于生产环境部署。
-
模型训练:内置训练脚本,支持多模型批量训练,可配置训练轮次与批次大小,输出最佳权重文件及评估指标(F1 曲线、混淆矩阵、标注示例等),方便用户基于自有数据优化模型。
系统基于 4,000 余张船舶影像数据进行训练,涵盖训练集、验证集与测试集,确保模型的泛化能力与可靠性。可广泛应用于港口监控、海事巡逻、无人设备巡检等场景,为智慧航运与海洋安全管理提供高效、准确且具备实时语音提醒能力的船舶分类检测方案。
2. 项目演示
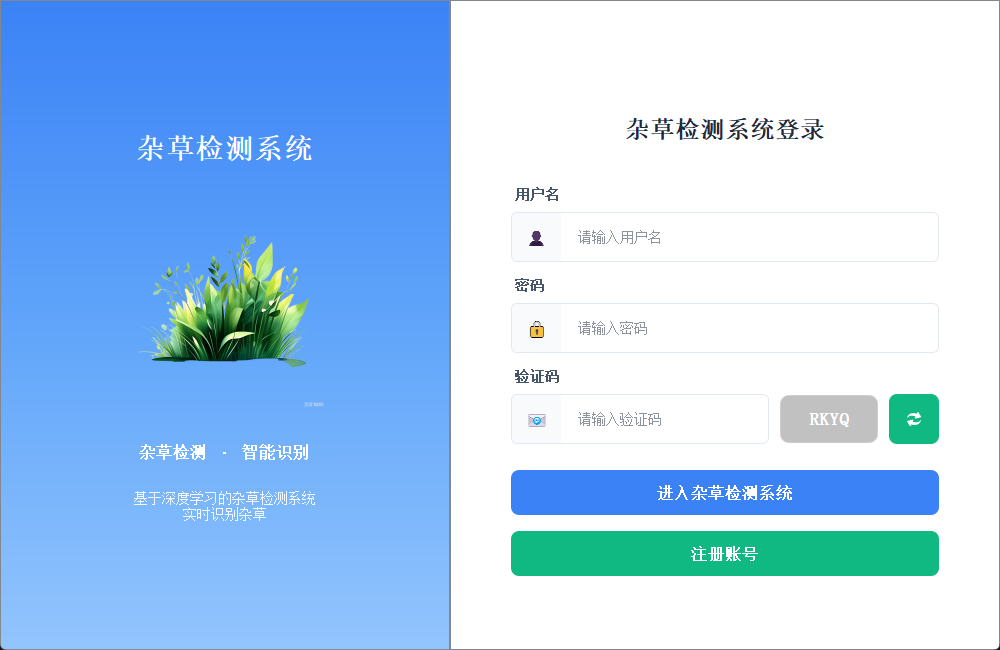
2.1 用户登录界面
登录界面布局简洁清晰,左侧展示系统主题,用户需输入用户名、密码及验证码完成身份验证后登录系统。
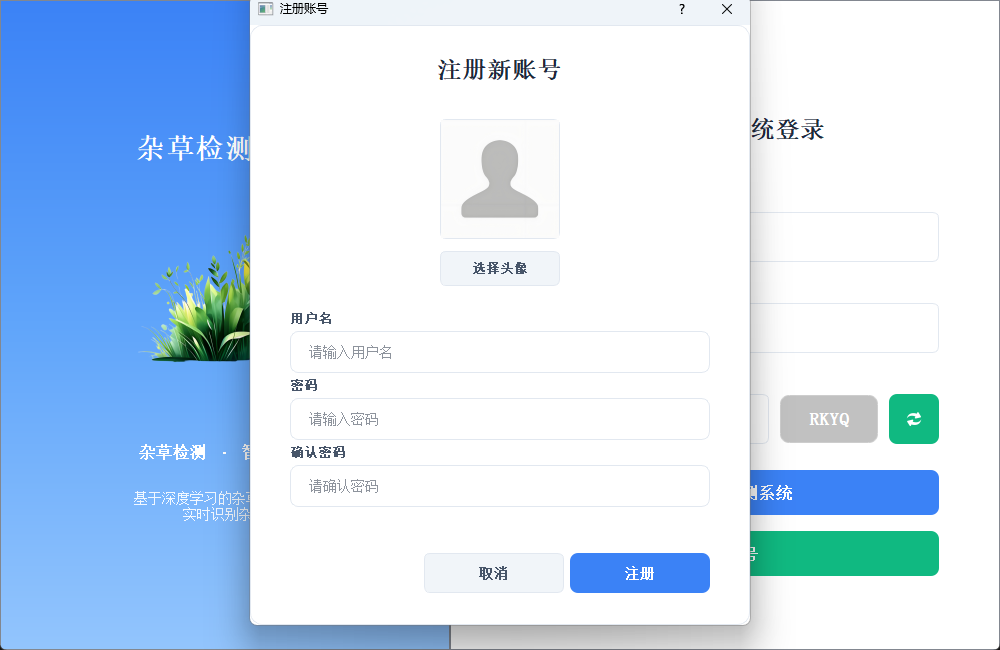
2.2 新用户注册
注册时可自定义用户名与密码,支持上传个人头像;如未上传,系统将自动使用默认头像完成账号创建。
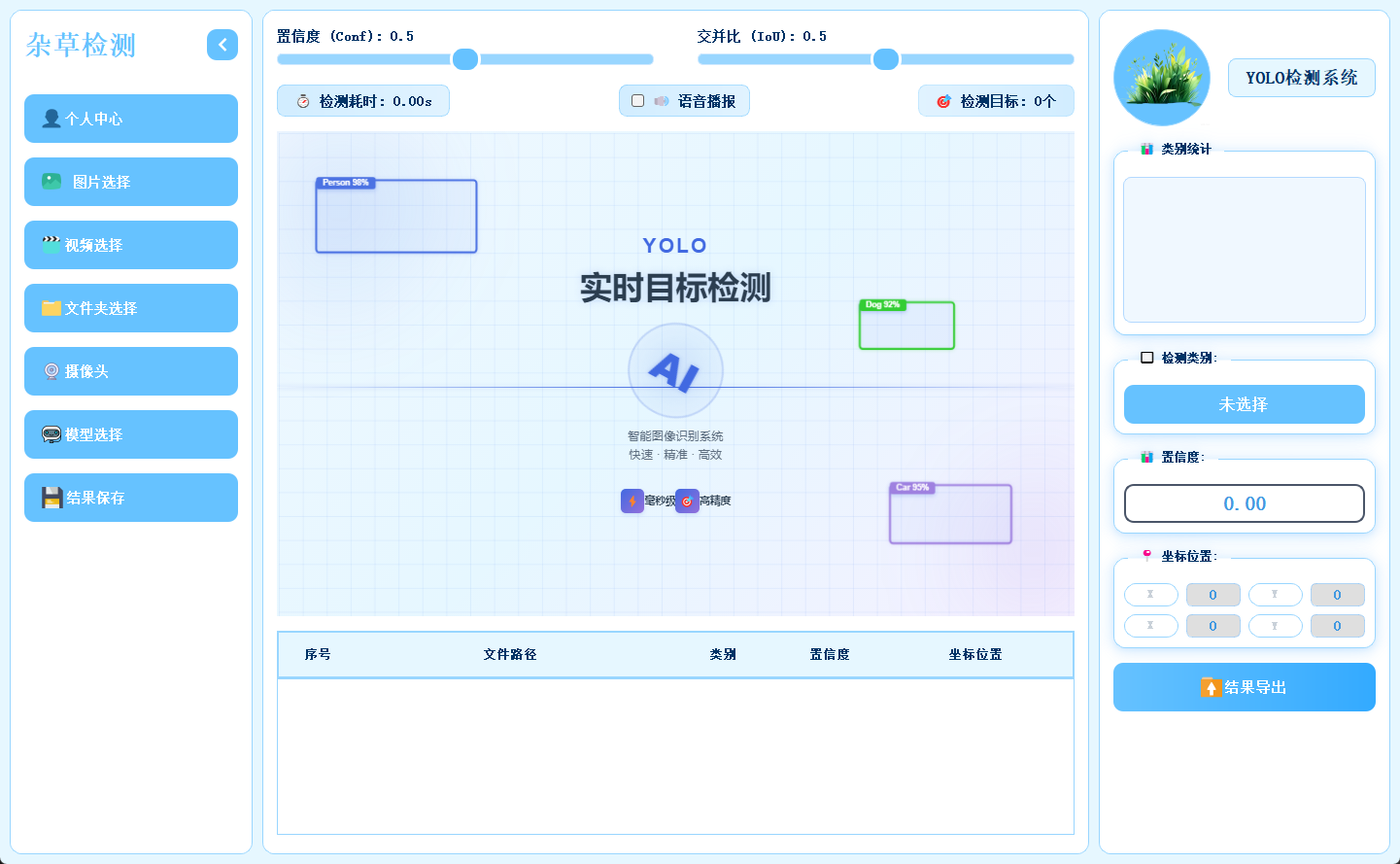
2.3 主界面布局
主界面采用三栏结构,左侧为功能操作区,中间用于展示检测画面,右侧呈现目标详细信息,布局合理,交互流畅。
2.4 个人信息管理
用户可在此模块中修改密码或更换头像,个人信息支持随时更新与保存。
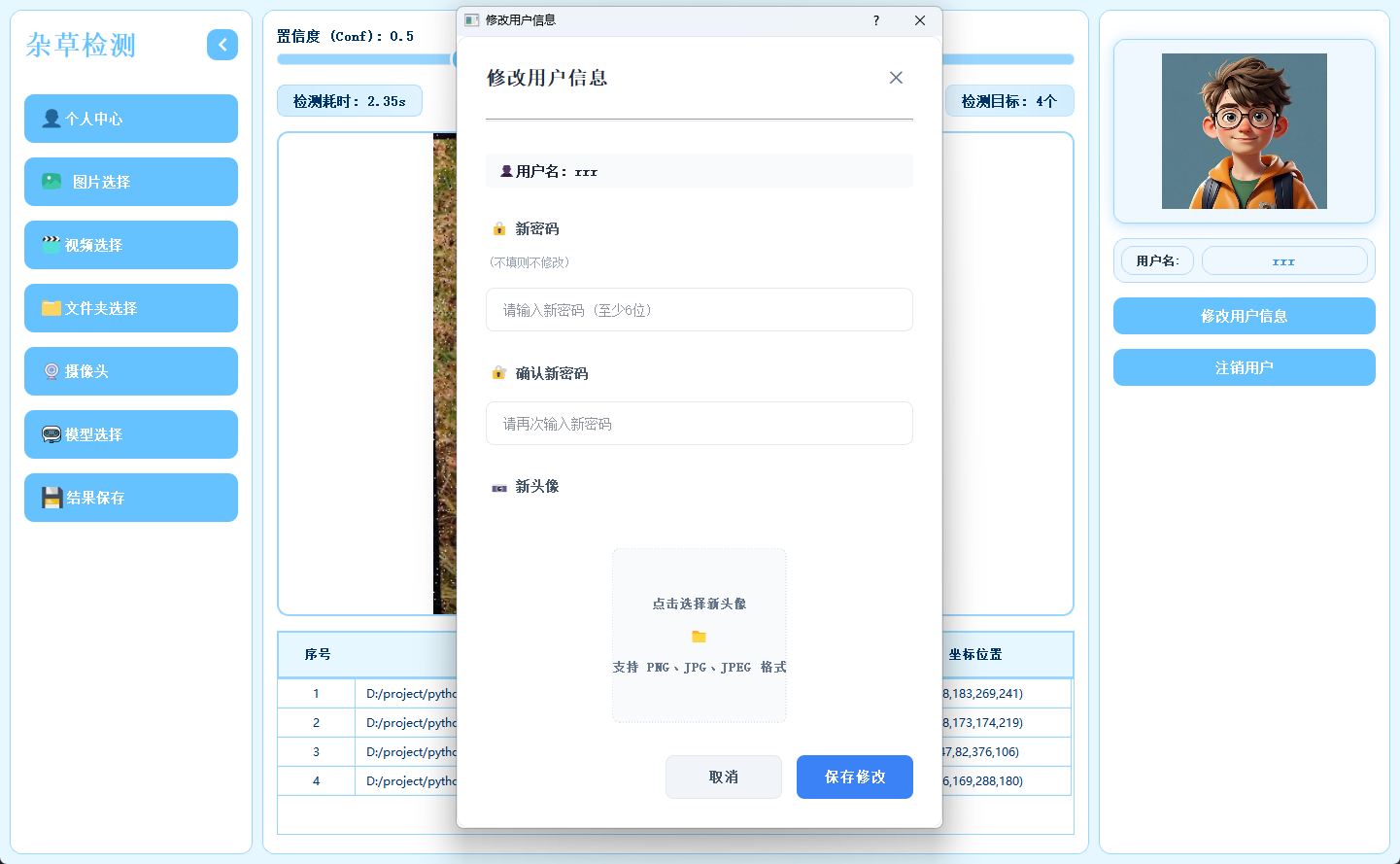
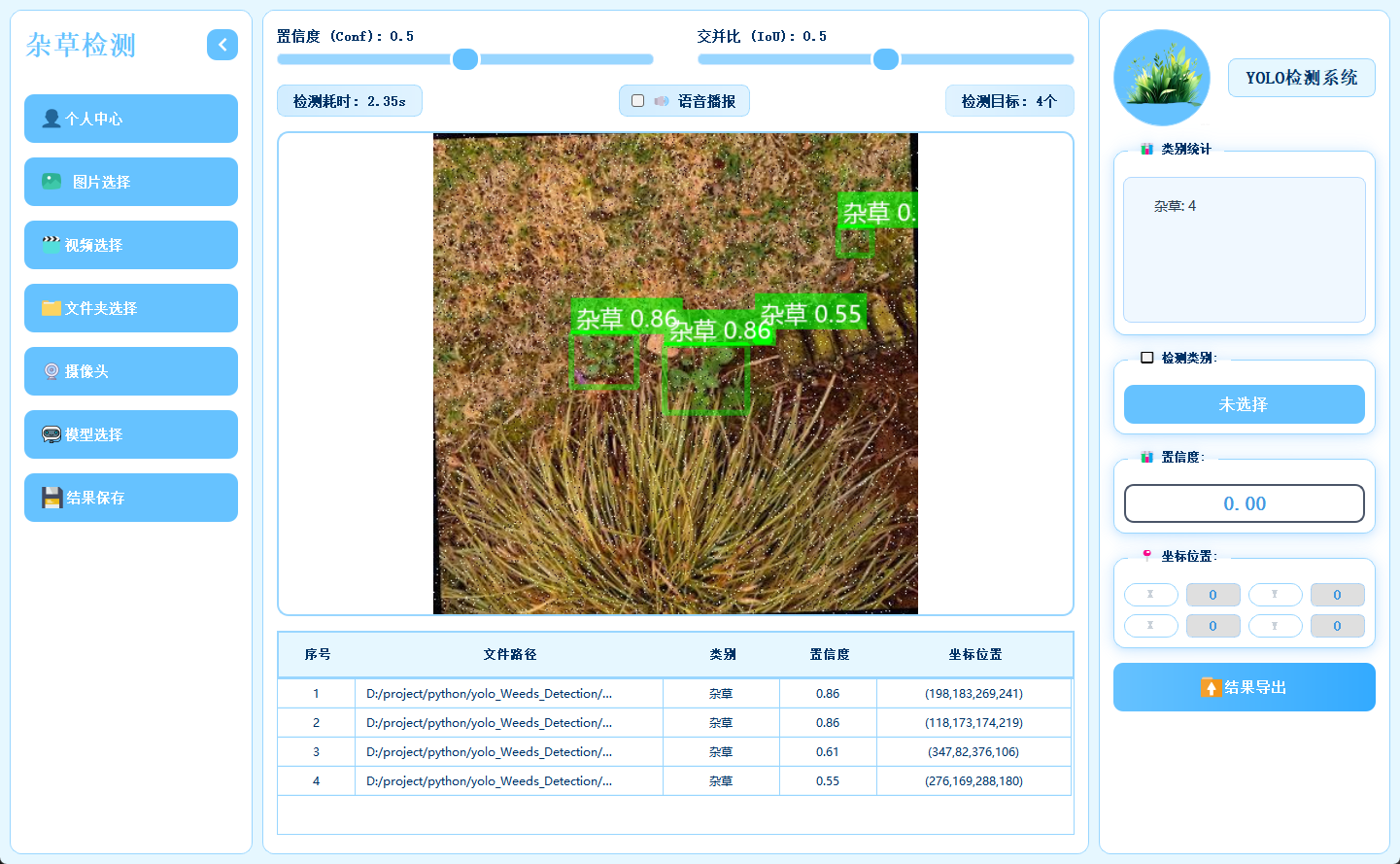
2.5 多模态检测展示
系统支持图片、视频及摄像头实时画面的目标检测。识别结果将在画面中标注显示,并且带有语音播报提醒,并在下方列表中逐项列出。点击具体目标可查看其类别、置信度及位置坐标等详细信息。
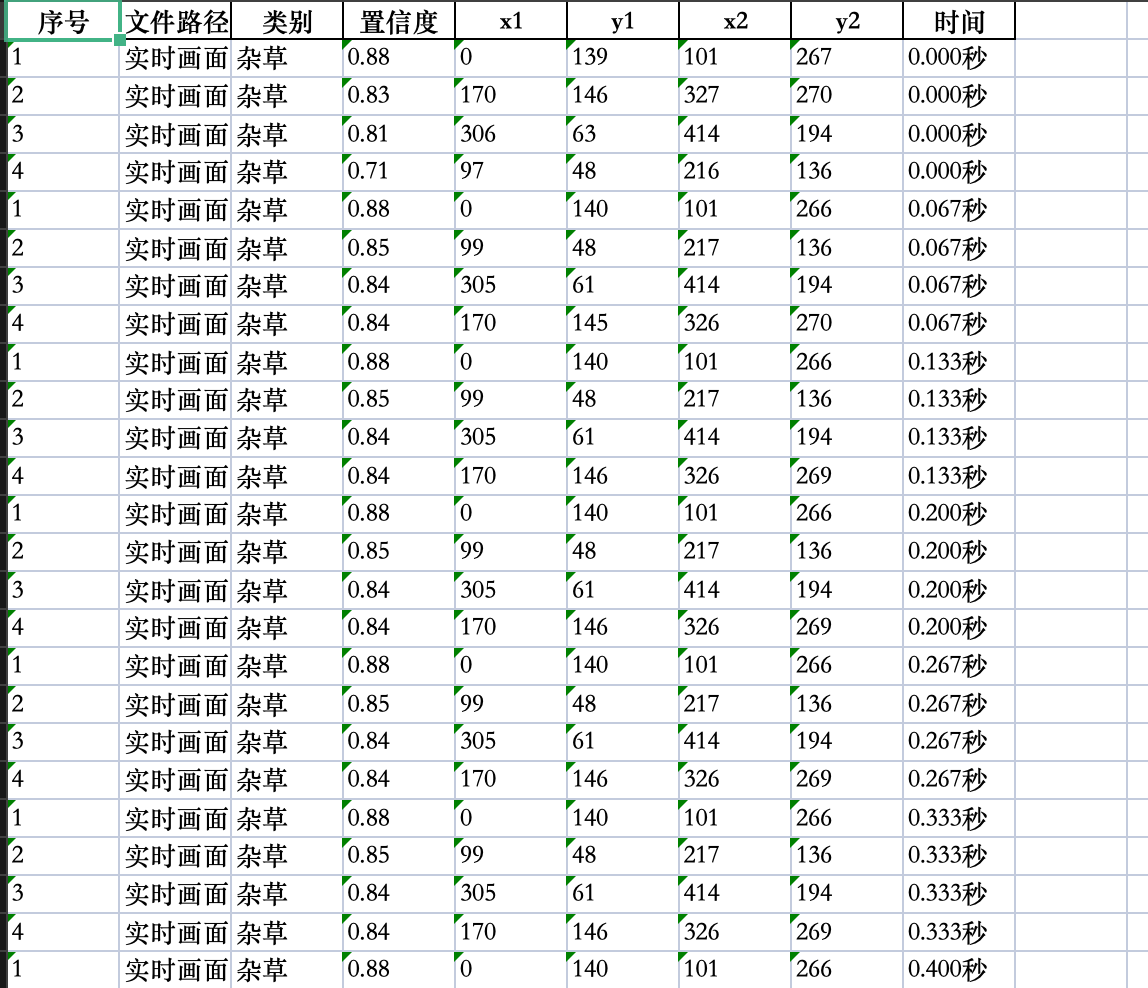
2.6 检测结果保存
可以将检测后的图片、视频进行保存,生成新的图片和视频,新生成的图片和视频中会带有检测结果的标注信息,并且还可以将所有检测结果的数据信息保存到excel中进行,方便查看检测结果。

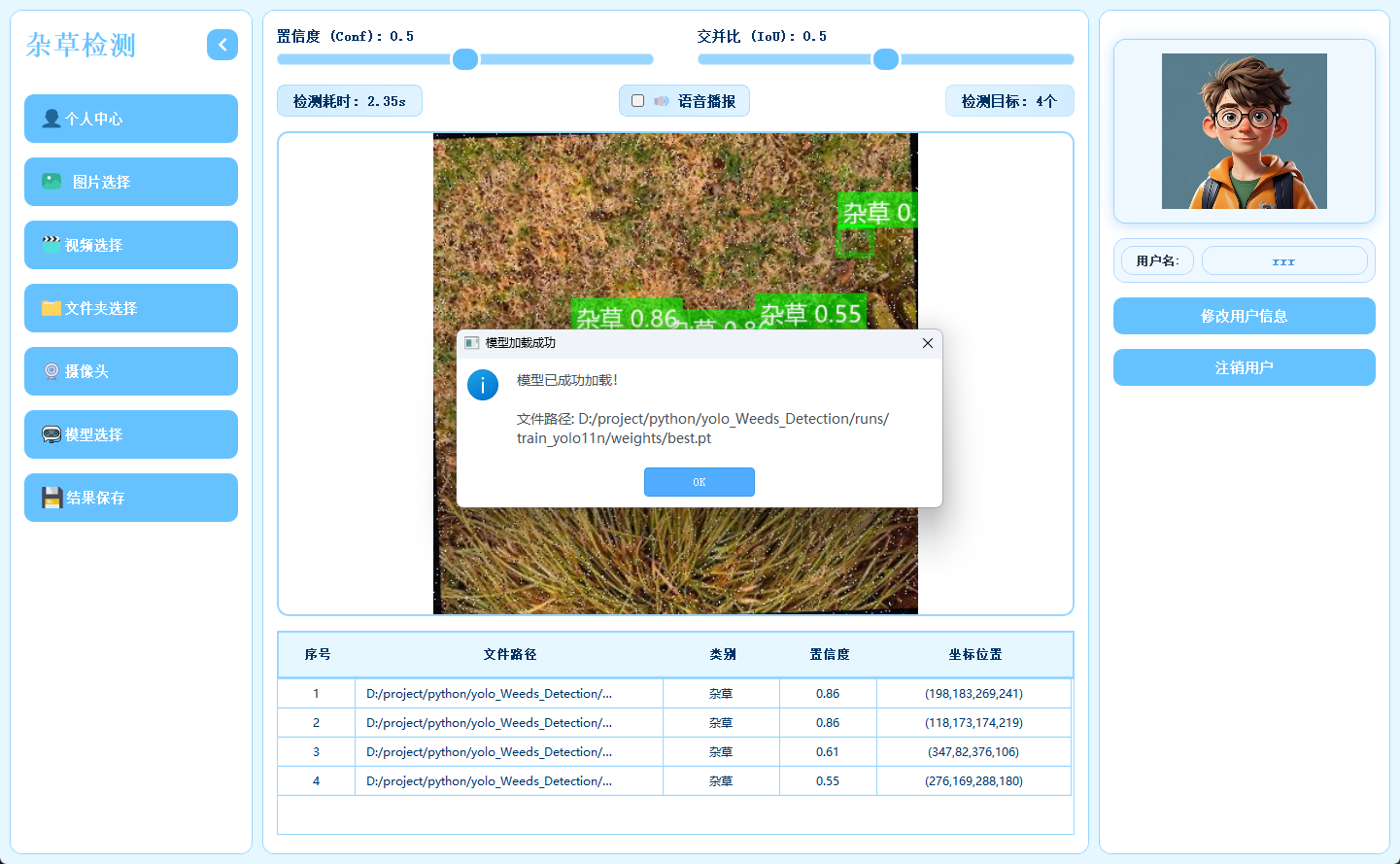
2.7 多模型切换
系统内置多种已训练模型,用户可根据实际需求灵活切换,以适应不同检测场景或对比识别效果。
3.模型训练核心代码
本脚本是YOLO模型批量训练工具,可自动修正数据集路径为绝对路径,从pretrained文件夹加载预训练模型,按设定参数(100轮/640尺寸/批次8)一键批量训练YOLOv5nu/v8n/v11n/v12n模型。
# -*- coding: utf-8 -*-
"""
该脚本用于执行YOLO模型的训练。
它会自动处理以下任务:
1. 动态修改数据集配置文件 (data.yaml),将相对路径更新为绝对路径,以确保训练时能正确找到数据。
2. 从 'pretrained' 文件夹加载指定的预训练模型。
3. 使用预设的参数(如epochs, imgsz, batch)启动训练过程。
要开始训练,只需直接运行此脚本。
"""
import os
import yaml
from pathlib import Path
from ultralytics import YOLO
def main():
"""
主训练函数。
该函数负责执行YOLO模型的训练流程,包括:
1. 配置预训练模型。
2. 动态修改数据集的YAML配置文件,确保路径为绝对路径。
3. 加载预训练模型。
4. 使用指定参数开始训练。
"""
# --- 1. 配置模型和路径 ---
# 要训练的模型列表
models_to_train = [
{'name': 'yolov5nu.pt', 'train_name': 'train_yolov5nu'},
{'name': 'yolov8n.pt', 'train_name': 'train_yolov8n'},
{'name': 'yolo11n.pt', 'train_name': 'train_yolo11n'},
{'name': 'yolo12n.pt', 'train_name': 'train_yolo12n'}
]
# 获取当前工作目录的绝对路径,以避免相对路径带来的问题
current_dir = os.path.abspath(os.getcwd())
# --- 2. 动态配置数据集YAML文件 ---
# 构建数据集yaml文件的绝对路径
data_yaml_path = os.path.join(current_dir, 'train_data', 'data.yaml')
# 读取原始yaml文件内容
with open(data_yaml_path, 'r', encoding='utf-8') as f:
data_config = yaml.safe_load(f)
# 将yaml文件中的 'path' 字段修改为数据集目录的绝对路径
# 这是为了确保ultralytics库能正确定位到训练、验证和测试集
data_config['path'] = os.path.join(current_dir, 'train_data')
# 将修改后的配置写回yaml文件
with open(data_yaml_path, 'w', encoding='utf-8') as f:
yaml.dump(data_config, f, default_flow_style=False, allow_unicode=True)
# --- 3. 循环训练每个模型 ---
for model_info in models_to_train:
model_name = model_info['name']
train_name = model_info['train_name']
print(f"\n{'='*60}")
print(f"开始训练模型: {model_name}")
print(f"训练名称: {train_name}")
print(f"{'='*60}")
# 构建预训练模型的完整路径
pretrained_model_path = os.path.join(current_dir, 'pretrained', model_name)
if not os.path.exists(pretrained_model_path):
print(f"警告: 预训练模型文件不存在: {pretrained_model_path}")
print(f"跳过模型 {model_name} 的训练")
continue
try:
# 加载指定的预训练模型
model = YOLO(pretrained_model_path)
# --- 4. 开始训练 ---
print(f"开始训练 {model_name}...")
# 调用train方法开始训练
model.train(
data=data_yaml_path, # 数据集配置文件
epochs=100, # 训练轮次
imgsz=640, # 输入图像尺寸
batch=8, # 每批次的图像数量
name=train_name, # 模型名称
)
print(f"{model_name} 训练完成!")
except Exception as e:
print(f"训练 {model_name} 时出现错误: {str(e)}")
print(f"跳过模型 {model_name},继续训练下一个模型")
continue
print(f"\n{'='*60}")
print("所有模型训练完成!")
print(f"{'='*60}")
if __name__ == "__main__":
# 当该脚本被直接执行时,调用main函数
main()4. 技术栈
-
语言:Python 3.10
-
前端界面:PyQt5
-
数据库:SQLite(存储用户信息)
-
模型:YOLOv5、YOLOv8、YOLOv11、YOLOv12
5. YOLO模型对比与识别效果解析
5.1 YOLOv5/YOLOv8/YOLOv11/YOLOv12模型对比
基于Ultralytics官方COCO数据集训练结果:
|
模型 |
尺寸(像素) |
mAPval 50-95 |
速度(CPU ONNX/毫秒) |
参数(M) |
FLOPs(B) |
|---|---|---|---|---|---|
|
YOLO12n |
640 |
40.6 |
- |
2.6 |
6.5 |
|
YOLO11n |
640 |
39.5 |
56.1 ± 0.8 |
2.6 |
6.5 |
|
YOLOv8n |
640 |
37.3 |
80.4 |
3.2 |
8.7 |
|
YOLOv5nu |
640 |
34.3 |
73.6 |
2.6 |
7.7 |
关键结论:
-
精度最高:YOLO12n(mAP 40.6%),显著领先其他模型(较YOLOv5nu高约6.3个百分点);
-
速度最优:YOLO11n(CPU推理56.1ms),比YOLOv8n快42%,适合实时轻量部署;
-
效率均衡:YOLO12n/YOLO11n/YOLOv8n/YOLOv5nu参数量均为2.6M,FLOPs较低(YOLO12n/11n仅6.5B);YOLOv8n参数量(3.2M)与计算量(8.7B)最高,但精度优势不明显。
综合推荐:
-
追求高精度:优先选YOLO12n(精度与效率兼顾);
-
需高速低耗:选YOLO11n(速度最快且精度接近YOLO12n);
-
YOLOv5nu/YOLOv8n因性能劣势,无特殊需求时不建议首选。
5.2 数据集分析
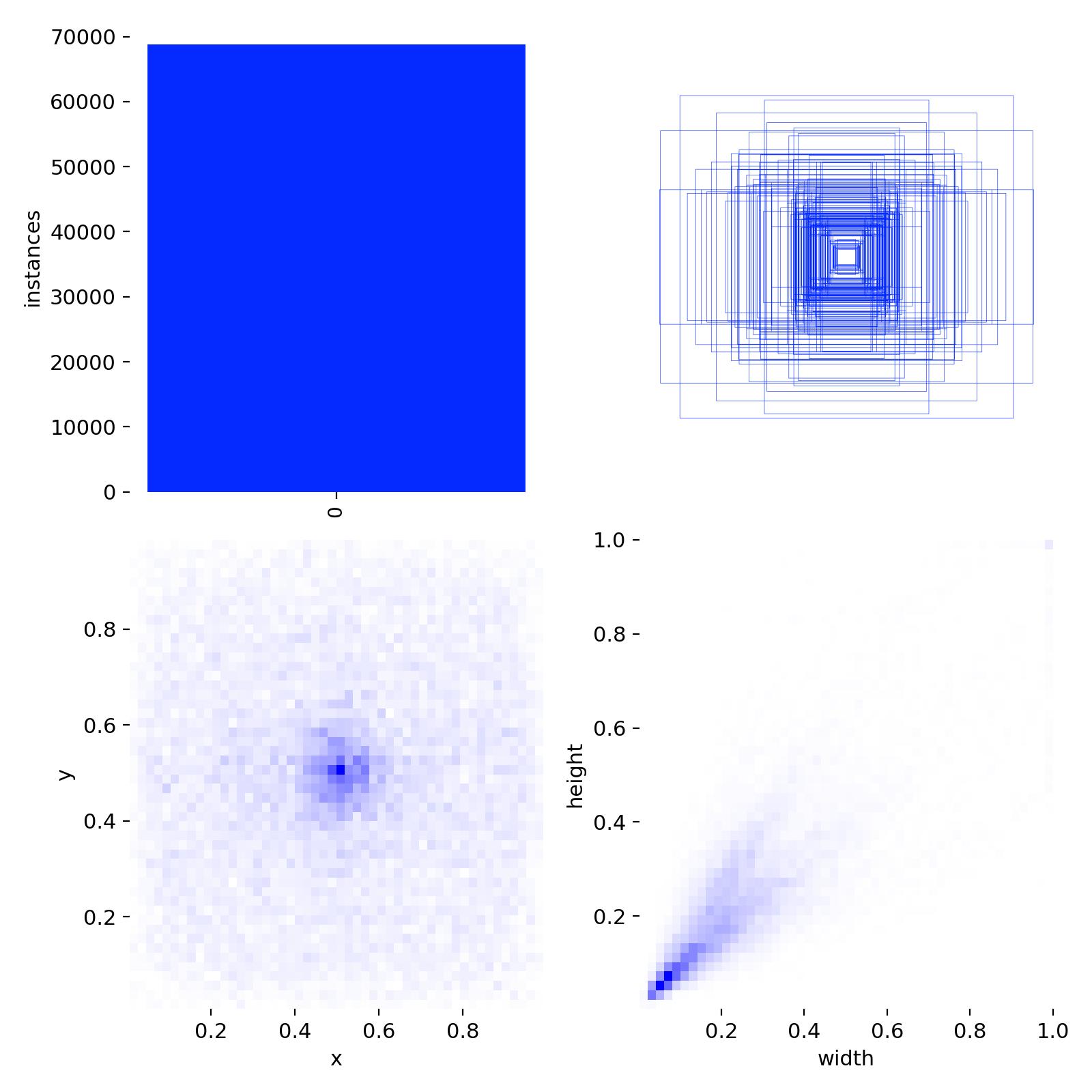
数据集中训练集和验证集一共4000张图片,数据集目标类别两种:正常肾脏,肾结石,数据集配置代码如下:


上面的图片就是部分样本集训练中经过数据增强后的效果标注。
5.3 训练结果
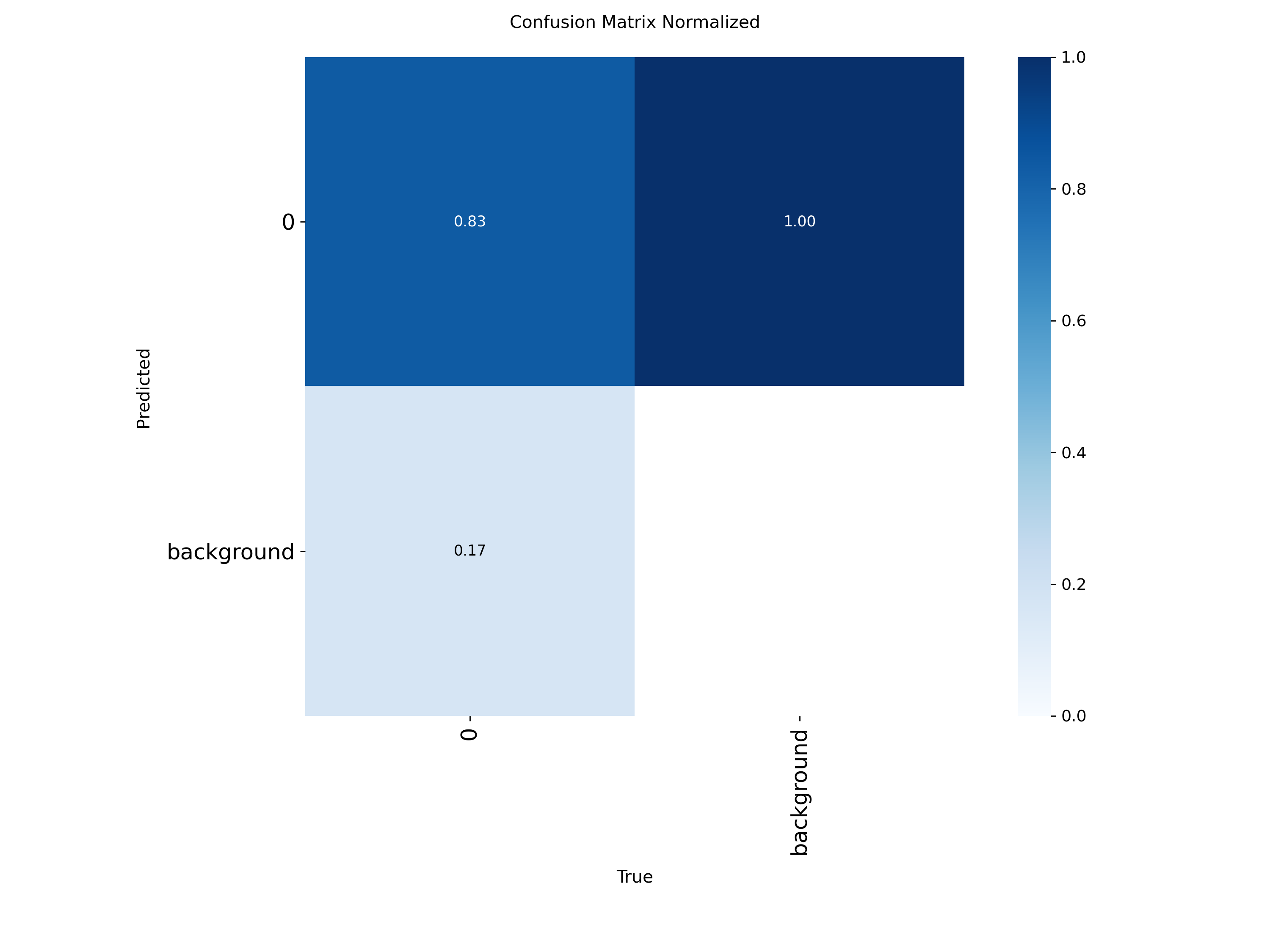
混淆矩阵显示中识别精准度显示是一条对角线,方块颜色越深代表对应的类别识别的精准度越高。
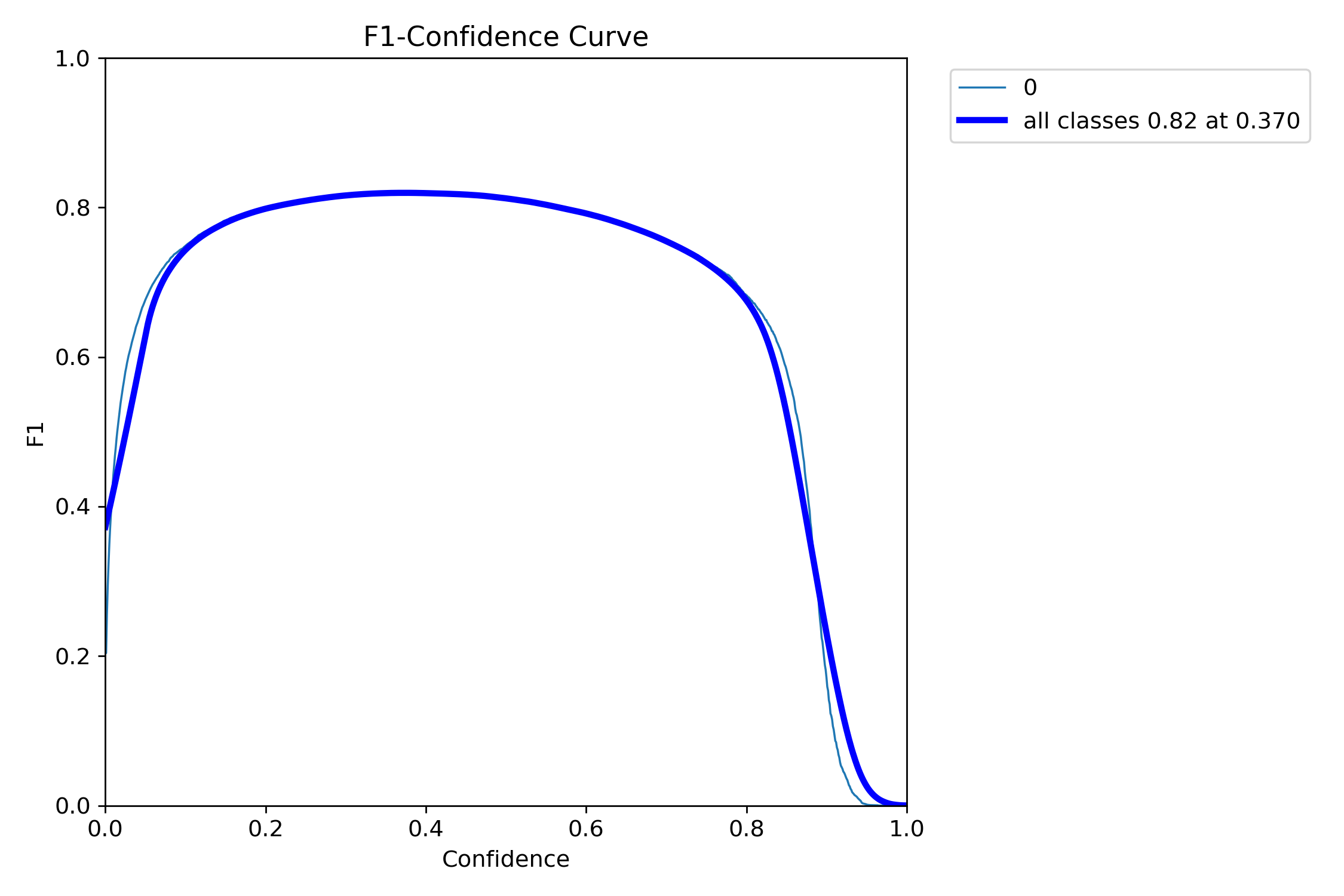
F1指数(F1 Score)是统计学和机器学习中用于评估分类模型性能的核心指标,综合了模型的精确率(Precision)和召回率(Recall),通过调和平均数平衡两者的表现。
当置信度为0.370时,所有类别的综合F1值达到了0.82(蓝色曲线)。
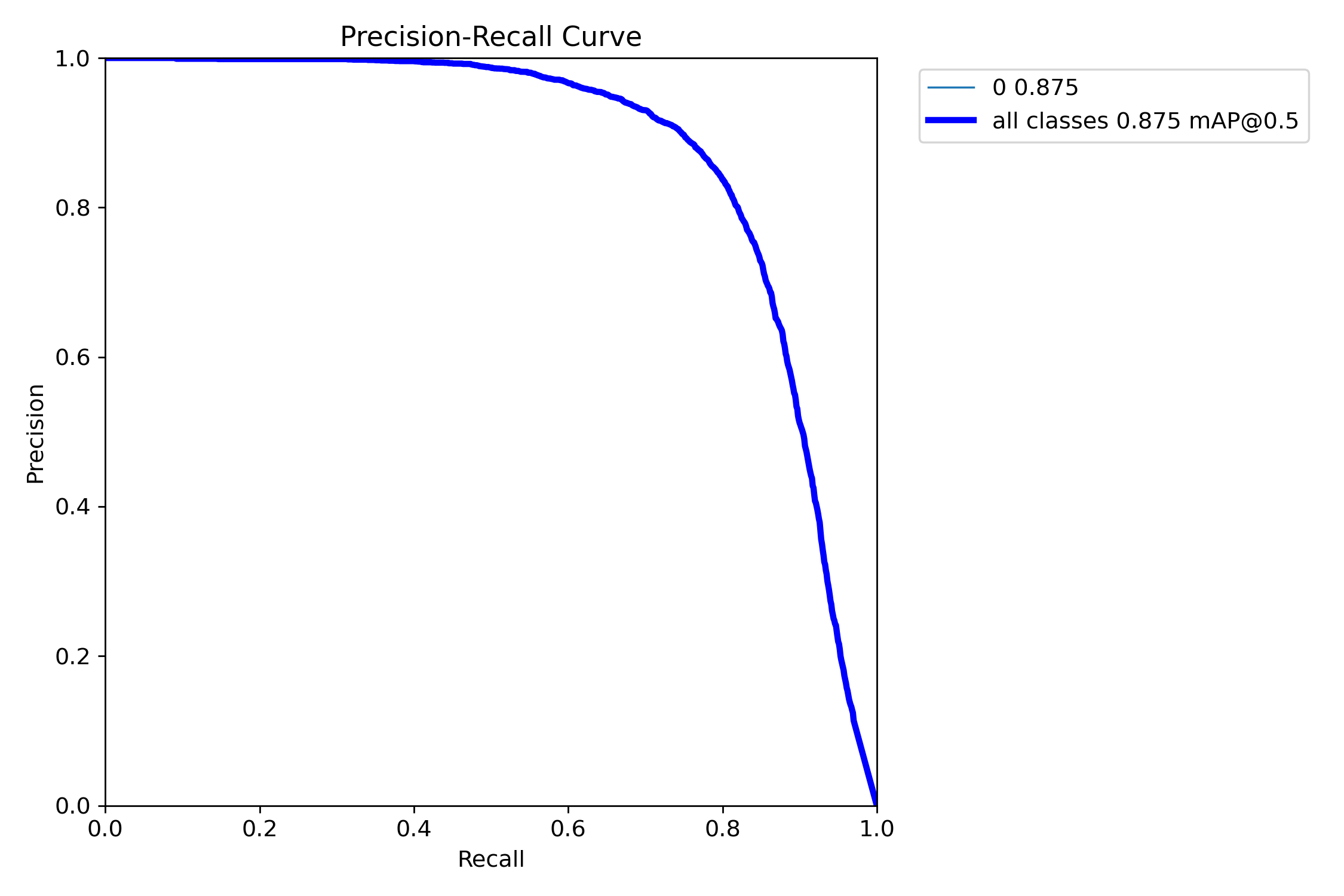
mAP@0.5:是目标检测任务中常用的评估指标,表示在交并比(IoU)阈值为0.5时计算的平均精度均值(mAP)。其核心含义是:只有当预测框与真实框的重叠面积(IoU)≥50%时,才认为检测结果正确。
图中可以看到综合mAP@0.5达到了0.875(87.5%),准确率非常高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号