布隆过滤器
相信研究过爬虫的应该对布隆过滤器都有所了解,在URL去重,文章去重等方面,布隆过滤器的用处很大。
布隆过滤器是一个很长的二进制向量和一系列的映射hash函数。
布隆过滤器不能准确地判断一个值真正的存在,但是可以判断一个值一定不存在,就好比两个值A、B,当使用布隆过滤器,判断A存在时,其实A不一定存在,但是判断B不存在,B一定不存在。
布隆过滤器使用bit数组,极大程度的降低了存储的消耗,每一位为0,如果计算一个数后,得到的这个数为123,那么就将123位的0分别置1.
举个栗子:“您好”经过hash函数计算得到357,“hello”经hash函数计算得到468,那么bit数组的345678位都会置为1,这时候来了一个“Hi”,计算后得到13,因为1位为0,那么可以判定这个值一定不存在,反之这个值经过hash计算后得到58,那么会判定这个数存在,但是实际上是不存在的。
在实现布隆过滤器最主要的是要知道hash函数的个数k,以及布隆过滤器的长度m.下面是一个公式
k为hash函数个数、m为布隆过滤器长度、n为插入的元素个数、p为误报率
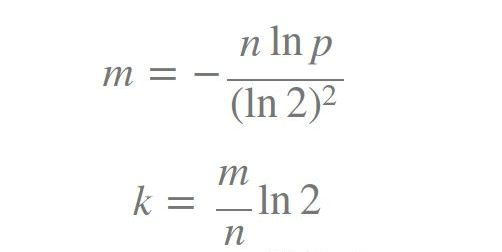
我们只需要设置我们需要插入的元素个数,和我们理想的误报率,比如10000000,0.0000001即可得到我们应该设置多长的长度,多少个hash函数
在Redis里可以使用指令bf.add添加元素,bf.exists查询是否存在,bf.madd批量添加元素
详情可以参考下面两篇文章:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号