Java集合--Map集合
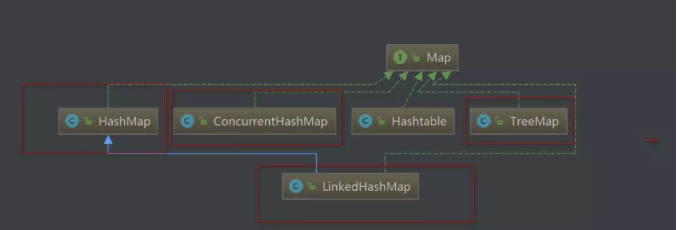
Map:
- Map的底层实现是散列表,不在意元素的顺序,能快速的查找元素的数据,散列表是用数组链表实现的,每个列表称之为桶
- 散列表为每个对象计算出一个散列码,通过hashCode函数,当数据量比较大的时候会出现散列码相同的情况,称之为散列冲突,因此在数组后引用了链表
- 在Java1.8中,如果桶满了就会从链表变成红黑树
- 如果散列表太满,就会对散列表再散列,创建一个桶数更多的散列表,将元素插入,旧的丢弃
- 何时散列由装填因子决定,默认的是0.75,如果表中超过75%的位置已经填入元素,那么就会散列
红黑树:
- 红黑树是二叉搜索树
- 根节点是黑色的
- 每个红色结点的两个子节点都是黑色
- 每个叶子结点都是黑色的空节点
- 从任一节点到其叶子节点的所有路径都包含有相同的黑色节点
HashMap:
- 初始容量为16,最大容量为231次方,默认装载因子0.75
- 默认的链表长度为8,当超过这个数时就会转换为红黑树存储,并不是说有一个桶的链表为8了,就转换,首先需要桶的长度大于64
- 无序,允许为null,非同步
- 底层由哈希表(散列表)实现
- 初始装载因子的设置很重要
方法:
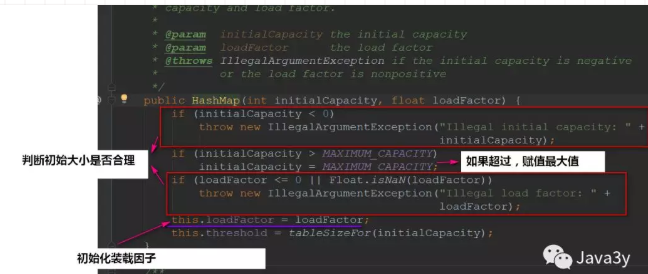
- 构造方法中,首先会判断初始大小是否合理,太大的话会赋值默认的最大值,然后初始话装载因子,还有一个threshold阈值,决定是否散列,值等于capacity * loadfactor
![]()
- put(key, value) 调用了putVal()方法,以key的值计算哈希值,得到Hashcode,与HashCode的高16位做异或运算,因为默认是16,而存储到散列表时就是0-15,可能会导致计算出来的很多哈希值重复,增加了随机性
- get(key) 计算哈希值,调用getNode():计算出来哈希值,如果在桶的首位就直接返回,否则就会遍历红黑树或者链表
- remove(key) 计算哈希值,判断桶不为空,映射的哈希值也存在,是否在桶的首位,不是就去红黑树、列表找,然后三种情况删除
![]()
![]()
![]()



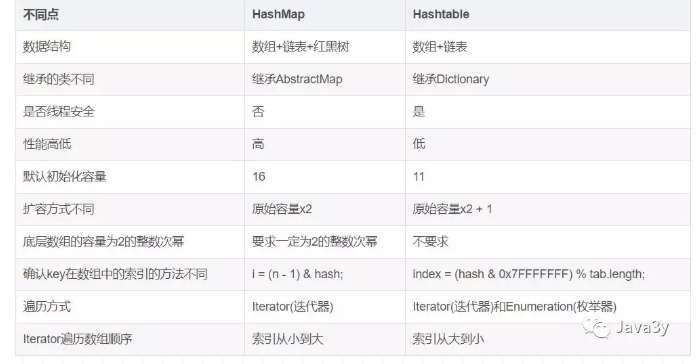
HashMap与Hashtable对比:
![]()
- Hashtable存储结构和实现基本上相同,不过它是线程安全的,不允许值为null
- 给定初始容量后,HashMap会自动将其扩容到大于初始值最接近2的幂次方的数
装载因子和默认容量:
- 装载因子过大,散列的次数减少了,但是会增加哈希冲突
- 装载因子太小,散列的次数会增加,很耗性能
- 初始容量过大,遍历时速度会受影响
- 初始容量过小,散列的次数会变多
LinkedHashMap:
- 是hashMap的一个子类,保存了记录的插入顺序,使用Iterator遍历
- 先得到的记录先插入,构造时带参数,按照访问次序排序
TreeMap:
- 底层是红黑树,时间复杂度不高
- 使用Comparator和Comparable比较Key是否相等与排序的问题
- 继承自NavigableMap接口,后者有继承SortedMap,所以TreeMap是有序的
- 如果在构造方法中传递了Comparator对象,就会以Comparator对象的方法进行比较,否则则使用Comparable的comparaTo(To)方法来比较,按照自然顺序比较
- key一定不能为null,TreeMap非同步的,想要同步使用collections进行封装
ConCurrentHashMap:
- 他和HashMap思路差不多,支持并发操作,由一个一个Segment组成,“一段”、“部分”,常常被称为“分段锁”
- ConCurrentHashMap简单理解是一个Segment数组,Segment通过继承ReentrantLock来进行加锁,保证每个Segment线程安全,那么就实现了全局线程安全
- ConCurrencyLevel:并行数、并发数,默认是16,也就是说有16个Segment,可以初始化其他值,但是不可以扩容,每个segment类似HashMap
以上是个人学习总结,参考了公众号Java3y大佬的文章,原文源码讲解很详细,大佬的文章没得说,学习Java的话很值得去看一看,推荐一波~
大佬Github:https://github.com/ZhongFuCheng3y/3y

 浙公网安备 33010602011771号
浙公网安备 33010602011771号