计算机视觉-经典解析网络

经典解析网络
AlexNet
层数统计说明:
-
-
池化层与各种归一化层都是对它们前面卷积层输出的特征图进行后处理,不单独算作一层。
图像在输入模型之前都对其进行了去均值操作,因为绝对数值在对图像分类的过程中是没有意义的,有意义的是图像之间的相对数值。
maxpool:
-
作用:降低特征图尺寸,对抗轻微的目标偏移带来的影响。
-
参数个数:它没有参数。
卷积层操作时为了提取图像的特征,在卷积层后需要接入全连接层来对提取的特征进行分类操作。在卷积操作之后得到的是一个HxWxD的特征向量图组,需要对其进行拉伸为向量才能放入全连接层进行训练。
重要说明:
-
用于提取图像特征的卷积层以及用于分类的全连接层是同时学习的;
-
卷积层与全连接层在学习过程中会相互影响、相互促进。
重要技巧:
-
dropout策略防止过拟合;
-
使用加入动量的随机梯度下降算法,加速收敛;
-
验证集损失不下降时,手动降低10倍的学习率;
-
采用样本增强策略增加训练样本数量,防止过拟合;
-
集成多个模型,进一步提高精度。
卷积层在做什么:
-
从数据中学习对于分类有意义的结构特征。
-
描述输入图像中的结构信息。
-
描述结果存储在256个6×6的特征响应图里。
AlexNet
相较于AlexNet网络结构基本一致,其主要改进点:
-
将第一个卷积层的卷积核大小改为7×7;
-
将第二、第三个卷积层的卷积步长都设置为2;
-
增加了第三、第四个卷积层的卷积核个数。
VGG
VGG网络共享:
-
使用尺寸更小的3×3卷积核串联来获得更大的感受野;
-
放弃使用11×11和5×5这样的大尺寸卷积核;
-
深度更深、非线性更强,网络的参数更少;
-
去掉了AlexNet中的局部响应归一化层。
之前去均值处理是使用每一个像素点的RGB各个通道的均值进行相减,也就是图片有多少个像素点,就有多少个RGB均值。而VGG是一张图片整体只算一个RGB均值,然后让每个像素点都减去这个RGB均值。区别在于一个是一个一,一个是一对多。
VGG16是现在依旧使用很多的方法。它包含13(2+2+3+3+3)个卷积层与3个全连接层。分为5段,每一段中卷积层的卷积核个数均相同。所有卷积层均采用3×3的卷积核及ReLu激活函数。池化层均采用最大池化,其窗口大小为2×2,步长为2。经过一次池化操作,其后卷积层的卷积核个数就增加一倍,直至达到512。全连接层中也使用了Dropout策略。
小卷积核有哪些优势:
-
多个小尺寸卷积核串联可以得到与大尺寸卷积核相同的感受野。例如两个3×3的卷积核串联与一个5×5的卷积核具有相同的感受野。
-
使用小卷积核串联构建的网络深度更深、非线性更强、参数也更少。
为什么VGG网络前四段里,每经过一次池化操作,卷积核个数就增加一倍?
-
池化操作可以减小特征图尺寸,降低显存占用。
-
增加卷积核个数有助于学习更多的结构特征,但是会增加网络参数数量以及内存消耗。
-
一减一增的设计平衡了识别精度与存储、计算开销。最终提升了网络性能。
为什么卷积核个数增加到512后就不再增加了?
-
第一个全连接层含102M参数,占总参数个数的74%;
-
这一层的参数个数是特征图的尺寸与个数的乘积;
-
参数过多容易过拟合,且不易被训练。
VGG证明了网络深度越深,网络模型性能越好;小卷积核能仿真大卷积核的结果且比大卷积核拥有更少的参数。
GoogLeNet
GoogLeNet创新点:
-
提出了一种Inception结构,它能保留输入信号中的更多特征信息;(核心改进)
-
去掉了AlexNet的前两个全连接层,并采用了平均池化,这一设计是的GoogLeNet只有500万参数,比AlexNet少了12倍;
-
在网络的中部引入了辅助分类器,克服了训练过程中的梯度消失问题。
串联结构(如VGG)存在的问题:后面的卷积层只能处理前面层输出的特征图;前层因某些原因(比如感受野限制)丢失重要信息,后层无法找回。
解决方法:每一层中尽量多的保留输入信号中的信息。
Inception V1优点:层数更深、参数更少、计算效率更高、非线性表达能力更强。
采用两个辅助分类损失的原因:
-
原因:虽然ReLu单元能够一定程度解决梯度消失问题,但是并不能完全解决深层网络难以训练的问题。离输出远的层不如靠近输出的层训练得好。
-
结果:让低层的卷积层学习到的特征也有很好地区分能力,从而让网络更好地被训练,而且低层的卷积层学到了好的特征也能加速整个网络的收敛。
-
网络推断:仅利用网络最后的输出作为预测结果,忽略辅助分类器的输出。
平均池化向量化与直接展开向量化有什么区别?
-
特征响应图上每个位置的值反应了图像对应位置的结构与卷积核记录的语义结构的相似程度。
-
平均池化丢失了语义结构的空间位置信息。
-
忽略语义结构的位置信息,有助于提升卷积层提取到的特征的平移不变性。
利用1×1卷积进行压缩会损失信息吗?
-
不会,因为压缩前的那个点假设通道数是64,则就是用64维特征去表述这个点,而这64维是一个稀疏向量,因此在压缩后信息量不会产生损失。
ResNet
ResNet具有以下贡献:
-
提出了一种残差模块,通过堆叠残差模块可以构建任意深度的神经网络,而不会出现“退化”现象。
-
提出了批归一化方法来对抗梯度消失,该方法降低了网络训练过程对于权重初始化的依赖。
-
提出了一种针对ReLu激活函数的初始化方法。
解决方案:
-
假设卷积层学习的变换为F(X),残差结构的输出是H(X),则有:H(X)=F(X)+X。
所谓残差就是输入和输出之间的差异。
残差结构:
-
残差结构能够避免普通的卷积层堆叠存在信息丢失问题,保证前向信息流的顺畅。
-
残差结构能够应对梯度反传过程中的梯度消失问题,保证反向梯度流的通畅。
为什么残差网络性能这么好?
-
残差网络可以看做是一种集成模型。
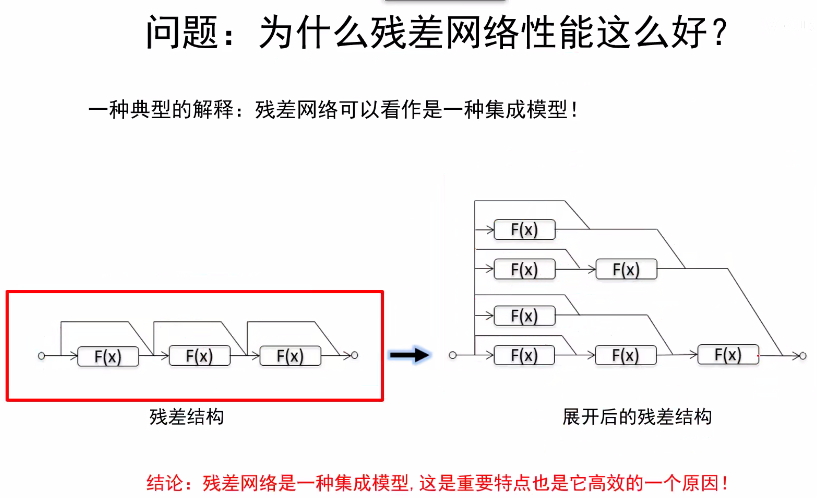
残差网络和Inception V4是公认的推广性能最好的两个分类模型。
视觉识别任务:分类、语义分割、目标检测、实例分割。
语义分割(UNET)
思路:
-
全卷积:让整个网络只包含卷积层,一次性输出所有像素的类别预测。
全卷积网络能够减少像素点的运算量,加快神经网络。
问题:
-
处理过程中如果一直保持原始分辨率,对显存的需求会非常庞大。
解决方案:
-
让整个网络只包含卷积层,并在网络中嵌入下采样与上采样过程。先下采样尽量提取到高级语义特征,在通过高级语义特征再上采样采样回来。
上采样方法:
-
反池化操作:“Unpooling”。包含近邻法,0填充法(但以上两个都不常用)。index pooling(标准位置映射)。以上方法都是写死的硬编码。
-
可学习的上采样:转置卷积
目标检测
单目标(分类+定位):
利用先前的图像分类网络模型,来进一步训练得到物体的边界核。
R-CNN:
-
找出所有潜在可能包含目标的区域;
-
运行速度需要相对较快;比如,Selective Search在CPU上仅需要运行几秒钟就可以产生2000个候选区域。
-
主要方法是:利用区域建议方法产生的感兴趣区域(~2k),然后对区域进行缩放(224×224),然后将图像区域送入卷积网络进行特征提取,最后使用支持向量机对区域进行分类。
-
R-CNN的问题:计算效率低下!每一张图像大约有2k个区域需要卷积网络进行特征提取,重叠区域反复计算。
-
想法:在特征图上进行区域扣取。
Fast R-CNN:
-
首先是对输入图像进行利用卷积网络对全图进行特征提取,然后再提取的特征上选择出感兴趣的区域(~2k),然后对特征选择出来的区域进行裁剪和缩放,最后对处理后的结果进行分类,得到目标类别和边界。
Rol Pool:
-
将候选区域投影到特征图上,然后将区域顶点规整到网格交点上,将其粗略的分成面积相等的2×2个子区域。对每个子区域进行最大池化。
-
ROI Pool处理前不同的区域特征的空间尺寸可能不一致,但是处理后的所有区域特征尺寸都是一样的。
-
问题:处理后的区域特征会有轻微的对不齐。
ROI Align:
-
将候选区域投影到特征图上,不进行规整操作,而是在每个区域等间隔规则的选取4个点,采用双线性差值来计算每个点的值,然后对每个子区域进行最大池化。
Faster R-CNN:
-
区域建议:(有点懵!)
-
四种损失联合训练:RPN分类损失(目标/非目标);RPN边界框坐标回归损失;候选区域分类损失;最终边界框坐标回归损失。
-
两阶段目标检测器:
-
-
第一阶段:每张图运行一次:主干网络和区域建议网络(RPN)
-
第二阶段:每个区域运行一次:扣取区域特征(ROI pool/align);预测目标类别;预测边界框偏移量。
-
一阶段目标检测:YOLO/SSD/RetinaNet

实例分割
Mask R-CNN:在Faster R-CNN中加入了Mask Prediction。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号