机器学习-聚类算法K-means数据分析
在机器学习里面,聚类属于无监督学习的算法。实现步骤:
1、准备数据(随机样本)
2、初始化K个聚类中心
3、迭代聚类并进行聚类中心更新
4、结果可视化
一、数学模型
import numpy as np
import matplotlib.pyplot as plt
#计算欧式距离
def euclDistance(V1, V2):
return np.sqrt(sum((V2 - V1) ** 2))
#初始化质心
def initCentroids(data, k):
Samples_num, dim = data.shape
print(Samples_num)
# k个质心,列数跟样本的列数一样
centroids = np.zeros((k, dim))
# 随机选出k个质心
for i in range(k):
# 随机选取一个样本的索引
index = int(np.random.uniform(0, Samples_num))
# 作为初始化的质心
centroids[i, :] = data[index, :]
return centroids
# 传入数据集和k值
def k_means(data, k):
# 计算样本个数
Samples_num = data.shape[0]
# 样本的属性,第一列保存该样本属于哪个簇,第二列保存该样本跟它所属簇的误差
clusterData = np.array(np.zeros((Samples_num, 2)))
# 决定质心是否要改变的质量
clusterChanged = True
# 初始化质心
centroids = initCentroids(data, k)
while clusterChanged:
clusterChanged = False
# 循环每一个样本
for i in range(Samples_num):
# 最小距离
minDist = 100000.0
# 定义样本所属的簇
minIndex = 0
# 循环计算每一个质心与该样本的距离
for j in range(k):
# 循环每一个质心和样本,计算距离
distance = euclDistance(centroids[j, :], data[i, :])
# 如果计算的距离小于最小距离,则更新最小距离
if distance < minDist:
minDist = distance
# 更新最小距离
clusterData[i, 1] = minDist
# 更新样本所属的簇
minIndex = j
# 如果样本的所属的簇发生了变化
if clusterData[i, 0] != minIndex:
# 质心要重新计算
clusterChanged = True
# 更新样本的簇
clusterData[i, 0] = minIndex
# 更新质心
for j in range(k):
# 获取第j个簇所有的样本所在的索引
cluster_index = np.nonzero(clusterData[:, 0] == j)
# 第j个簇所有的样本点
pointsInCluster = data[cluster_index]
# 计算质心
centroids[j, :] = np.mean(pointsInCluster, axis=0)
return centroids, clusterData
#可视化结果
def showCluster(data, k, centroids, clusterData):
Samples_num, dim = data.shape
if dim != 2:
print('dimension of your data is not 2!')
return 1
# 用不同颜色形状来表示各个类别
mark = ['or', 'ob', 'og', 'ok', '^r', '+r', 'dr', '<r', 'pr']
if k > len(mark):
print('your k is too large!')
return 1
# 画样本点
for i in range(Samples_num):
markIndex = int(clusterData[i, 0])
plt.plot(data[i, 0], data[i, 1], mark[markIndex])
# 用不同颜色形状来表示各个类别
mark = ['*r', '*b', '*g', '*k', '^b', '+b', 'sb', 'db', '<b', 'pb']
# 画质心点
for i in range(k):
plt.plot(centroids[i, 0], centroids[i, 1], mark[i], markersize=20)
plt.show()
if __name__=="__main__":
#产生二维随机样本数
data = np.random.randint(100, size=(200, 2))
#聚类个数
k = 4
centroids, clusterData = k_means(data, k)
if np.isnan(centroids).any():
print('Error')
else:
print('cluster complete!')
# 显示结果
showCluster(data, k, centroids, clusterData)
结果:
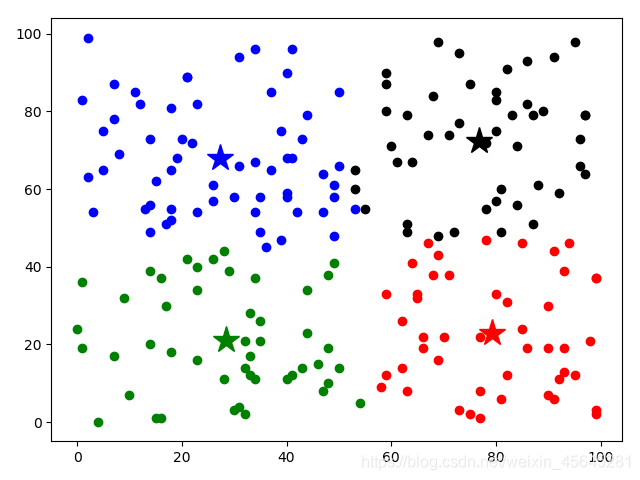
二、OpenCV机器学习模块
import numpy as np
import matplotlib.pyplot as plt
import cv2
#随机样本
data=np.random.randint(100, size=(200, 2))
data = np.float32(data)
k_num=4
#调用聚类函数
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
ret,label,center=cv2.kmeans(data,k_num,None,criteria,10,cv2.KMEANS_RANDOM_CENTERS)
#颜色空间
mark=['B', 'G', 'R', 'pink', 'yellow']
for i in range(k_num):
z=data[label.ravel()==i]
plt.scatter(z[:, 0], z[:, 1], c=mark[i])
plt.scatter(center[i, 0], center[i, 1], c='black', marker='*', s=500)
plt.show()
结果:
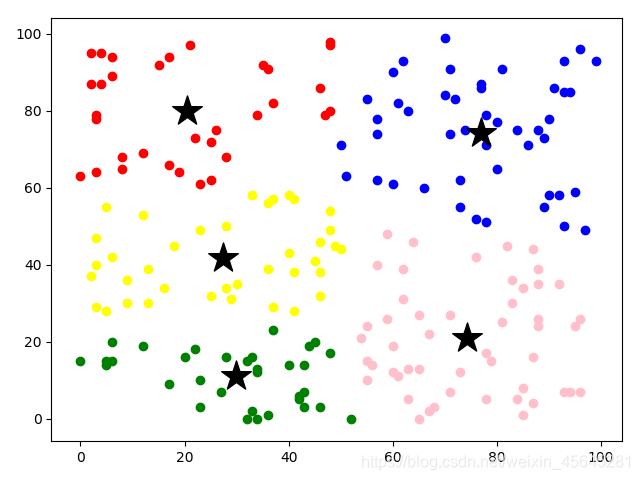
三、图片像素点聚类
import numpy as np
import cv2
#读取图片
img=cv2.imread("D:/testimage/Stanford.jpg")
Z = img.reshape((-1,3))
Z = np.float32(Z)
#调用聚类模型
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
K = 8
ret,label,center=cv2.kmeans(Z,K,None,criteria,10,cv2.KMEANS_RANDOM_CENTERS)
#变换数据类型
center = np.uint8(center)
res = center[label.flatten()]
res2 = res.reshape((img.shape))
cv2.imshow('res2',res2)
cv2.imwrite("D:/testimage/result_Stanford.jpg",res2)
cv2.waitKey(0)
cv2.destroyAllWindows()
原图:

结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号