LSM详解
概念
LSM是通过将磁盘的随机写改为顺序写来提高写的性能,核心思想是把数据的添加或修改放到内存中,当内存中数据达到一定size后,然后dump(也就是变成了顺序写)到磁盘中。LSM中有MemTable、ImmutableMemTable、SSTable等几个概念

1、MemTable
MemTable在内存中,记录最近修改的数据。一般其内部使用SkipList结构存储按key排序后的有序数据,当其存储的数据达到一定size后,就变成ImmutableMemTable,同时新建一个新的MemTable;后续的数据修改操作均在新的MemTable内进行。
2、ImmutableMemTable
ImmutableMemTable就是只读不写的MemTable,它与MemTable一起保证的写操作无锁化。其内部的数据是有序的,所以dump到磁盘时保证了高效的顺序写,形成了新的SSTable文件。
3、SSTable
Sorted-String-Table,存储的是一系列的有序键值对,当SSTable文件较大时,为了提高读的性能,也可以生成key-offset索引,此索引一般都记录在内存中。
4、放大
读(速率)放大
写(速率)放大
空间放大
5、write stall
write stall受影响因素:过多的memtable、过多的L0文件,过多的compaction
flush、compaction线程要配置好,前者高优,后者低优
compaction策略
如果不compaction,相当于是极低写放大,极高读放大和空间放大,因此需要对SSTable文件进行定期Compaction,将多个SSTable文件合并成一个SSTable文件,并对同一个key,只保留最新的值。一方面减少SSTable文件的数量,同时也删除过期的数据。
合并策略是指:一选择什么时候做合并;二选择哪些SSTable合并成一个SSTable
1、Size-tiered
适合写密集场景,有较低的写放大,但读放大、空间放大较高。用于HBase
基于文件大小分层和合并,每当某个尺寸(即一层)的SSTable数量达到阈值时,把这层所有的SSTable合成一个大SSTable直接放到更高一层,不需要读更高一层的数据进行合并
最基础、易于实现的策略,但因为它需要将一层所有SSTable文件合并成一个文件,只有在合并完成后才能删除小的SSTable文件,空间、读放大很大。那如果我们可以每次只处理小部分SSTable文件,就可以大大改善空间放大问题了,催生了Leveled策略
2、Universal
是Rocksdb对size-tiered策略进行优化后的变种策略,也用于Paimon。合并触发条件除了达到文件数量阈值level0_file_num_compaction_trigger外,还要检查
- 空间放大比例
假设L0层现有的SST文件为(R1, R1, R2, ..., Rn),其中R1是最新写入的SST,Rn是较旧的SST。所谓空间放大比例,就是指R1~Rn-1文件的总大小除以Rn的大小,如果这个比值比max_size_amplification_percent / 100要大,那么就会将L0层所有SST做compaction。
- 相邻文件大小比例
有一个参数size_ratio用于控制相邻文件大小比例的阈值。如果size(R2) / size(R1) < 1 + size_ratio / 100,就表示R1和R2两个SST可以做compaction。接下来继续检查size(R3) / size(R1 + R2)是否小于1 + size_ratio / 100,若仍满足,就将R3也加入待compaction的SST里来。如此往复,直到不再满足上述比例条件为止。
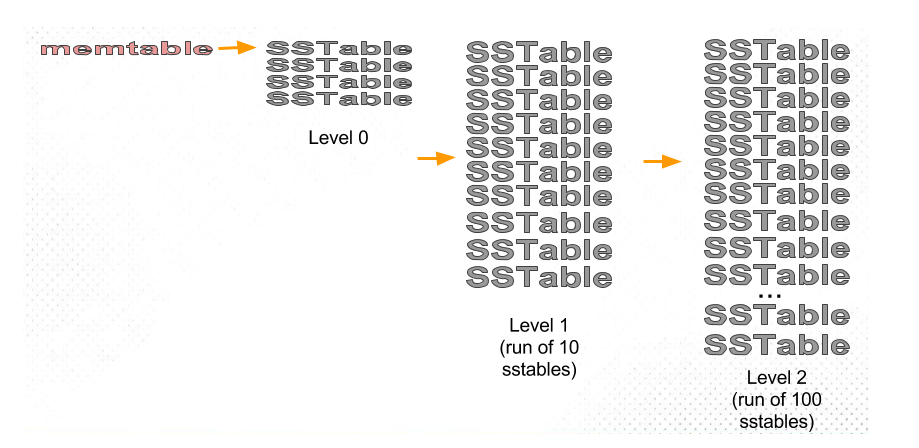
3、Leveled
减少读放大、空间放大,但写放大较高。用于LevelDB
基于文件数量分层和合并,0层-N层,每层之间的文件数量维持T倍。每个文件的大小固定,假设1层大小是512MB,level multiplier是10,2层的大小会是5GB,3层是51GB,4层是512GB。若数据库大小是500GB,5层以上会是空的。将数据分成互不重叠的一系列固定大小(例如 2 MB)的SSTable文件,再将其分层(level)管理。对每个Level,我们都有一份清单文件记录着当前Level内每个SSTable文件存储的key的范围。Level和Level的区别在于它所保存的SSTable文件的最大数量
0层的不同文件key是重叠的,L0->L1只能单线程合并。其他层内的key是不重叠的,可以多线程合并到其他层。可以自定义compaction线程数,当只有1个时,L0->L1时,其他层不能合并
详细的Leveled Compaction算法描述如下:
- 每个SSTable文件的固定大小为160M
- 从ImmutableMemTable创建的SSTable文件划分到Level-0中
- 每个Level有SSTable文件数量的限制。在除了Level-0的任意Level中,两级Level之间的SSTable文件数量呈指数级倍数。比如:Level-1中有10个SSTable文件,Level-2有100个SSTable文件
- 在除了Level-0的任意Level中,SSTable文件之间所包含的key的范围不重叠。(也就是说,每个Level的所有SSTable文件,可以看做是一个大的SSTable文件)
- 如果Level-0中SSTable数量超过限制(比如:4),那么自动将这4个Level-0的SSTable文件与Level-1的所有10个SSTable文件进行Compaction。
- 在Compaction过程中,首先对所有的SSTable文件按key进行归并排序,然后将排序后结果写入到新的SSTable文件中,如果SSTable文件大小到了160M上限,就新生成SSTable继续写。如此类推,直到写完所有数据。
- 删除参与Compaction的Level-0的4个和Level-1的10个旧的SSTable文件
- 此时Level-0的SSTable便merge到Level-1中了,那么如果Level-1的SSTable文件数量超过上限,那么就从Level-1中选出 1 个超量的SSTable文件,然后将其与Level-2中的SSTable文件进行Compaction。注:一般情况下,Level-1和Level-2的Compaction,只会涉及Level-2内大概1/10的SSTable文件,这样可以大幅降低参与Compcation的SSTable文件数量(相比于Size-Tired Compaction),进一步提升提升性能
- 查看选出的Level-1 SSTable文件中key的范围
- 从Level-2中选出能覆盖该范围的所有SSTable文件
- 将以上的所有SSTable文件根据上面介绍的算法继续进行Compaction
- 如果Level-2中的文件数量超过限制,则继续按照上述算法选出超量的SSTable文件与Level-3中的SSTable文件进行Compaction
4、Hybrid
用于RocksDB
Level0层使用Size-tiered(universal)策略,优先降低写放大不阻塞ImmutableMemTable快速落盘
Level1+层使用Leveled策略,多层间的compaction可并行执行,最大并行度max_background_compactions,优先降低读放大和空间放大

 浙公网安备 33010602011771号
浙公网安备 33010602011771号