基于Redisson实现分布式锁源码解读
文章目录
- 一、分布式锁的概念 和 使用场景
- 二、将redis官网对于分布式锁(红锁)的定义和Redisson实现做概括性总结
- 三、基于Redisson的分布式实现方案
- 四、加锁过程分析
- 五、锁重入过程分析
- 六、未获取到锁的线程继续获取锁
- 七、锁释放过程分析
- 八、易混淆概念
一、分布式锁的概念 和 使用场景
分布式锁是控制分布式系统之间同步访问共享资源的一种方式。
在分布式系统中,常常需要协调他们的动作。如果不同的系统或是同一个系统的不同主机之间共享了一个或一组资源,那么访问这些资源的时候,往往需要互斥来防止彼此干扰来保证一致性,这个时候,便需要使用到分布式锁。
二、将redis官网对于分布式锁(红锁)的定义和Redisson实现做概括性总结
该部分可以先粗略的浏览一下,领略其官方的理论定义,读完后续内容会对该环节有更清晰的理解。
对于Redis分布式锁(红锁)官网定义:
 中文对如上5点做出解释:
中文对如上5点做出解释:
redis红锁算法:
在Redis的分布式环境中,我们假设有N个Redis master。这些节点完全互相独立,不存在主从复制或者其他集群协调机制。我们确保将在N个实例上使用与在Redis单实例下相同方法获取和释放锁。现在我们假设有5个Redis master节点,同时我们需要在5台服务器上面运行这些Redis实例,这样保证他们不会同时都宕掉。
为了取到锁,客户端应该执行以下操作:
- 1、获取当前时间,以毫秒为单位。
- 2、依次尝试从5个实例,使用相同的key和随机值(Redisson中给出的是UUID + ThreadId)获取锁。当向Redis请求获取锁时,客户端应该设置一个网络连接和响应超时时间(我们接下来会在加锁的环节多次提到这个时间),这个超时时间应该小于锁的失效时间。例如你的锁自动失效时间为10秒,则超时时间应该在5-50毫秒之间。这样可以避免服务器端Redis已经挂掉的情况下,客户端还在一直等待响应结果。如果服务器端没有在规定时间内响应,客户端应该尽快尝试去另外一个Redis实例请求获取锁。
- 3、客户端使用当前时间减去开始获取锁时间(步骤1记录的时间)就得到获取锁使用的时间。当且仅当从大多数(N/2+1,这里是3个节点)的Redis节点都取到锁,并且使用的时间小于锁失效时间时,锁才算获取成功。
- 4、如果取到了锁,key的真正有效时间等于有效时间减去获取锁所使用的时间(步骤3计算的结果)。
- 5、如果因为某些原因,获取锁失败(没有在至少N/2+1个Redis实例取到锁或者取锁时间已经超过了有效时间),客户端应该在所有的Redis实例上进行解锁(即便某些Redis实例根本就没有加锁成功,防止某些节点获取到锁但是客户端没有得到响应而导致接下来的一段时间不能被重新获取锁)。
针对如上几点,redisson的实现:

三、基于Redisson的分布式实现方案
在分析Redisson的源码前,先重申一下我们本文的重点放在分布式锁的加锁、锁重入、未获取到锁的线程继续获取锁、释放锁四个过程!希望可以对大家有所帮助。
锁重入:我们假设,一次加锁时间为30秒,当然Redisson默认的也是30秒,但是业务执行时间大于30秒,如果没有锁重入的实现,那么30秒后锁失效,业务逻辑就会陷入无法保证正确性的严重后果中。
第一步:添加依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.12.5</version>
</dependency>
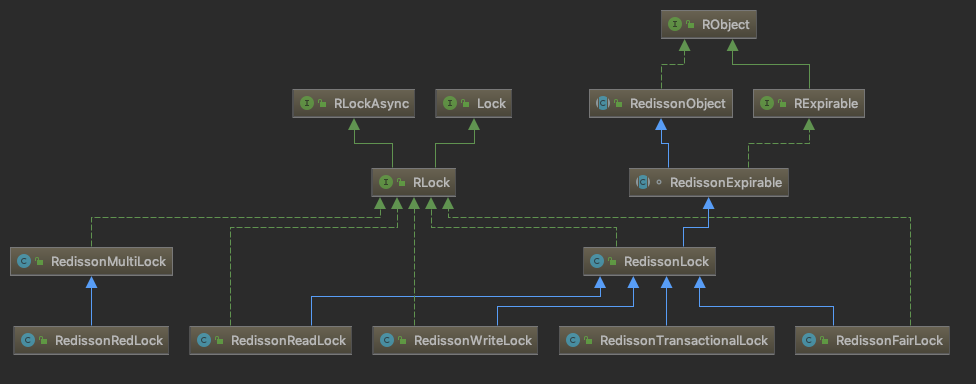
在正式编码前,我们先看下有关Redisson实现分布式锁的核心类之间的关系,如下图:
第二步:正式编码测试代码
@Slf4j @RunWith(SpringRunner.class) @SpringBootTest(classes = BootIntegrationComponentApplication.class) public class ReidsRedLockTest { private ExecutorService executorService = Executors.newCachedThreadPool(); public RedissonRedLock getRedLock(){ Config config1 = new Config(); config1.useClusterServers() .addNodeAddress("redis://127.0.0.1:9001","redis://127.0.0.1:9002","redis://127.0.0.1:9003" ,"redis://127.0.0.1:9004","redis://127.0.0.1:9005","redis://127.0.0.1:9006") .setPassword("123"); RedissonClient redissonClient1 = Redisson.create(config1);//创建redissonClient对象,设置一系列的redis参数 RLock rLock1 = redissonClient1.getLock("red_lock"); //如果有多个redis cluster集群,则参考如上的写法创建对应的RLock对象,并传入下面的RedissonRedLock构造方法中。 return new RedissonRedLock(rLock1);//获取redisson红锁 } @Test public void redisRedLock() throws Exception { RedissonRedLock redLock = getRedLock(); int[] count = {0}; for (int i = 0; i < 1000; i++) { executorService.submit(() -> { try { redLock.tryLock(10, TimeUnit.SECONDS);//加锁 count[0]++; Thread.sleep(50000L); } catch (Exception e) { log.error("添加分布式锁异常:",e); } finally { try { redLock.unlock();//释放锁 } catch (Exception e) { log.error("解除分布式锁异常:",e); } } }); } executorService.shutdown(); executorService.awaitTermination(1, TimeUnit.HOURS); log.info("计算后的结果:{}",count[0]); } }
四、加锁过程分析
首先我们将加锁过程的方法调用栈列出,按照调用步骤分析加锁的源码实现:
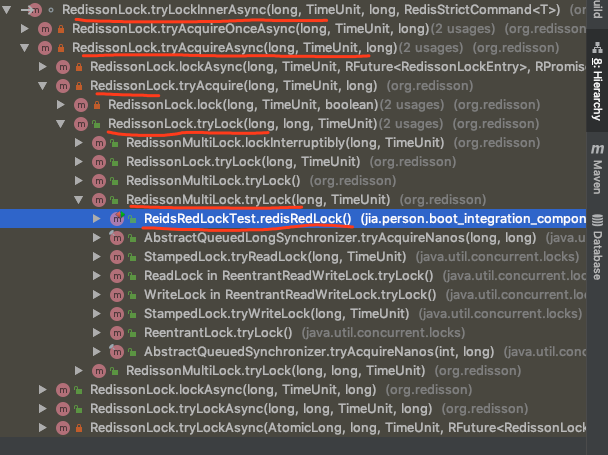
由上述调用栈可以看到,实现加锁的核心方法是:
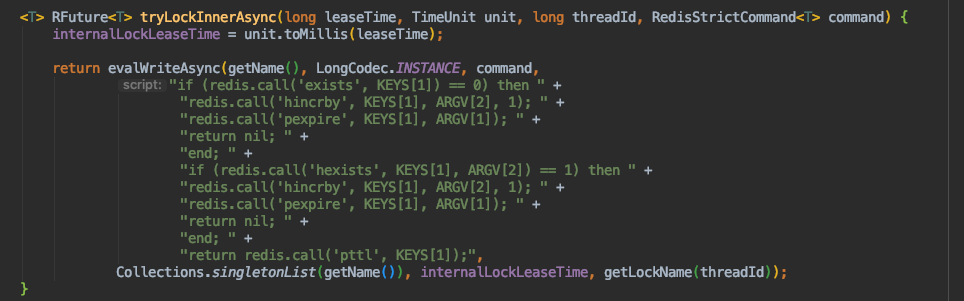
这是一个调用lua脚本的执行过程,接下来对该方法做详细解释:
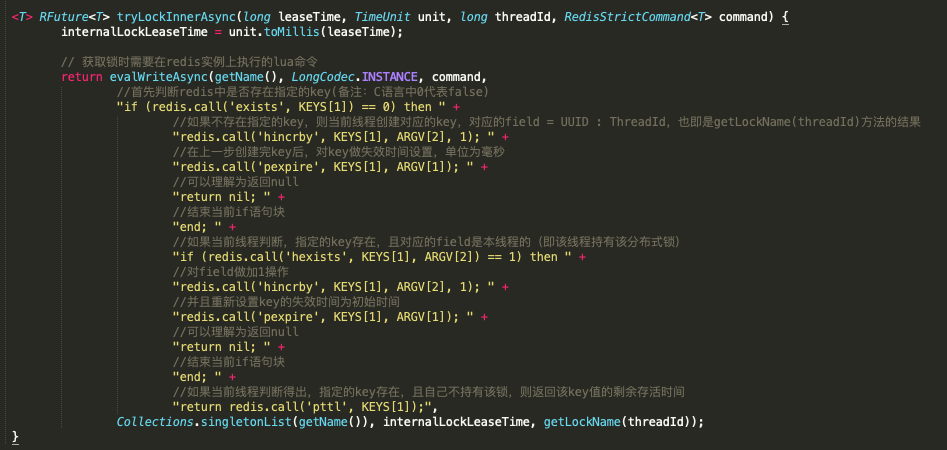
针对lua脚本中参数占位符的问题:
- KEYS[1] = getName(),
- ARGV[1] = internalLockLeaseTime
- ARGV[2] = getLockName(threadId)
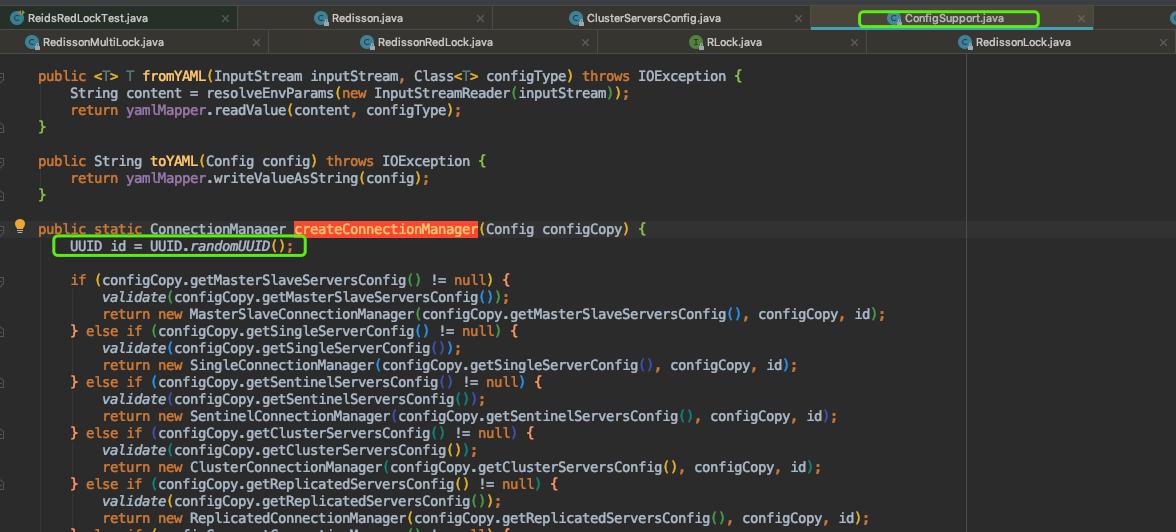
针对getLockName(threadId)方法,在创建redis连接管理器时,设置了id = UUID,具体如下
我们假设线程A,执行完上面的lua脚本,并且持有了该分布式锁,接下来针对线程A来说,直到业务逻辑结束,释放锁之前,该线程A,都将进入锁重入的环节,一直持续到业务逻辑执行完成,线程主动释放锁。而没有持有锁的线程,则进入争抢锁的过程,一直到持有锁(至于是公平竞争还是非公平竞争,我们先留一个悬念,欢迎各位看官老爷在评论区留言讨论)。
五、锁重入过程分析
再让我们回到加锁过程中方法调用栈的图片上,我们可以看到方法:

上图中的红框即是锁重入的实现方法,详细解释如下:

同样是利用lua脚本实现,

具体逻辑为:
- 0、我们假设线程A持有了该锁,则后台线程会在该锁持续了初始失效时间除3取整数的时间节点,做锁重入的操作。
- 1、if判断指定的key是否存在,且是否为当前线程所持有
- 2、如果被当前线程持有,则将失效时间重置为初始失效时间,redisson默认为30秒。
- 3、如果上面两步操作成功,则返回1,也即是true;否则返回false。
六、未获取到锁的线程继续获取锁
让我们将思路继续回到线程A获取锁的逻辑中,我们通过加锁方法调用栈可以看到方法:
public boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException
该方法实属有些长,我们就分段截取分析。
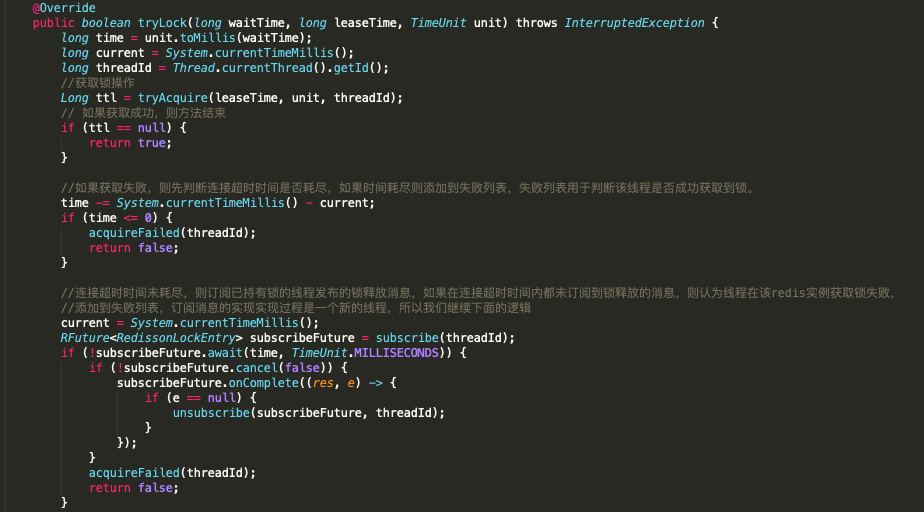
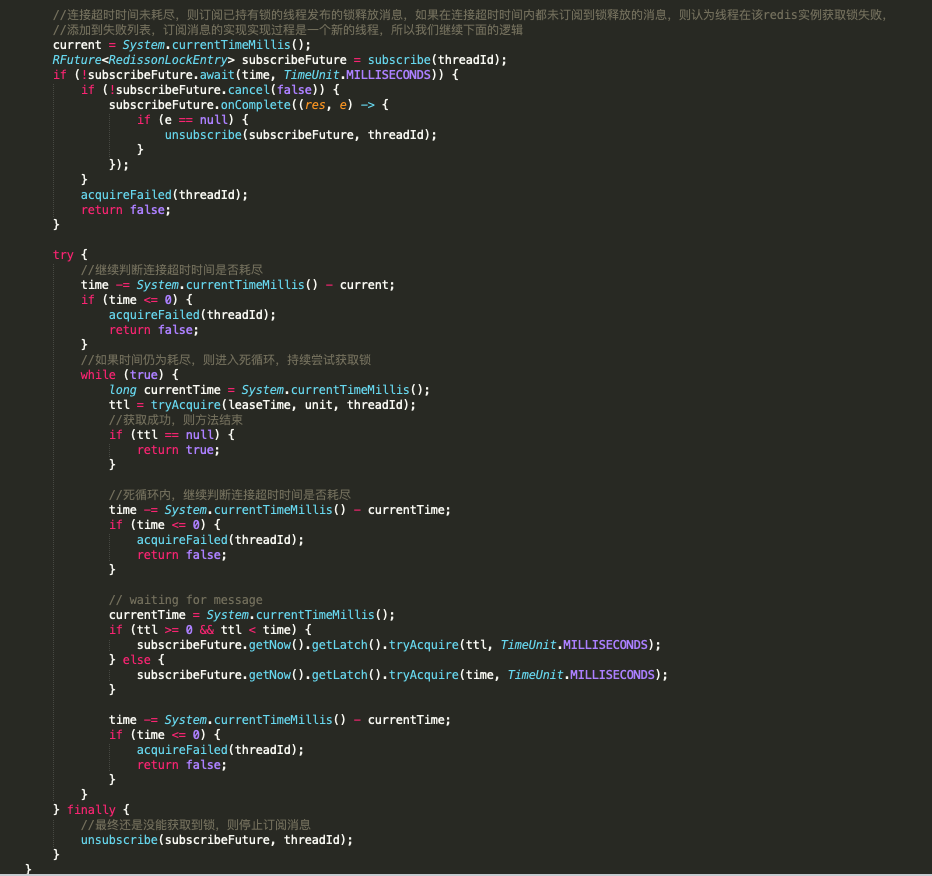
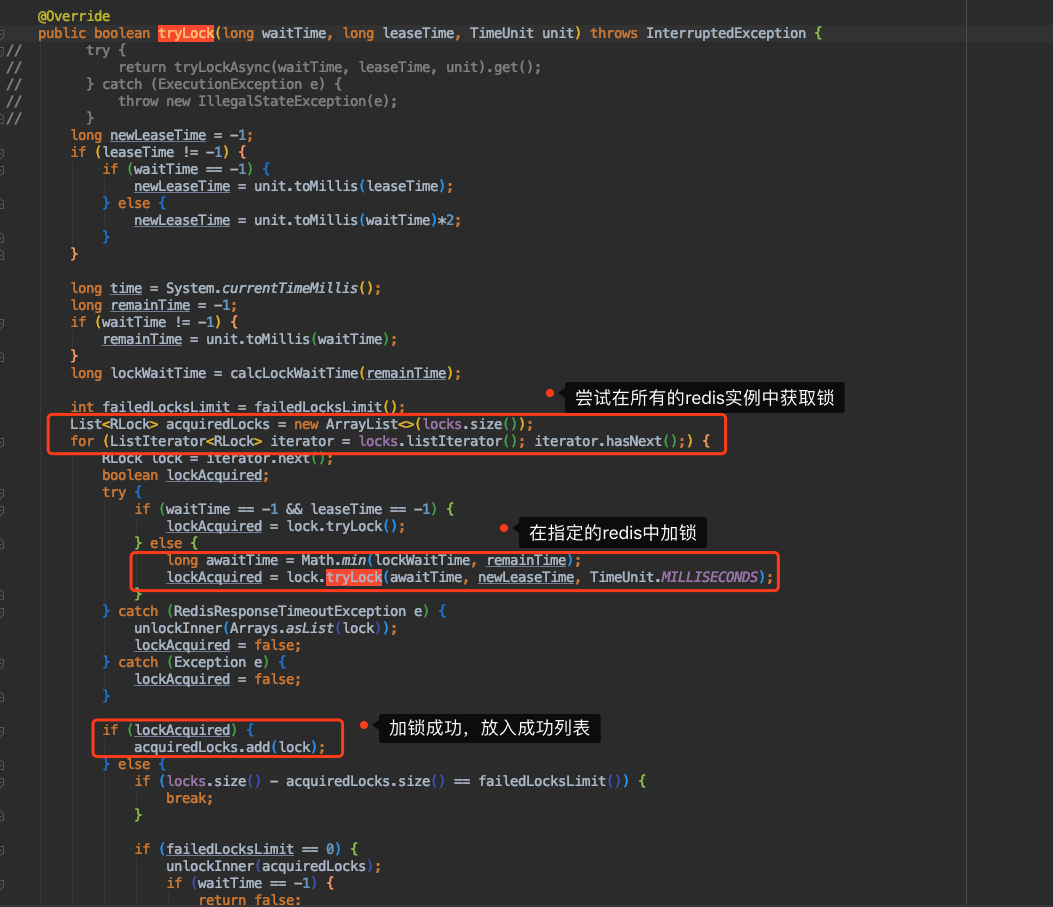
通过上图的分析,我们知道,如果一个线程初次没有获取到锁,则会一直尝试获取锁,直到我们设置的针对获取该redis实例锁的超时时间耗尽才罢休,在这个过程中没有获取到锁,则认为在该redis实例获取锁失败。
七、锁释放过程分析
我们还是先将锁释放过程方法调用栈列出:
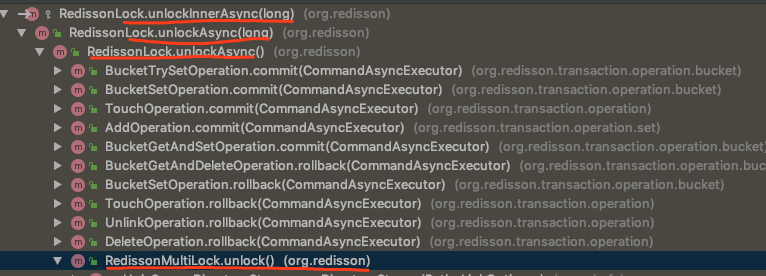

通过上图可以看到,在锁释放的过程中,最核心的方法就是:
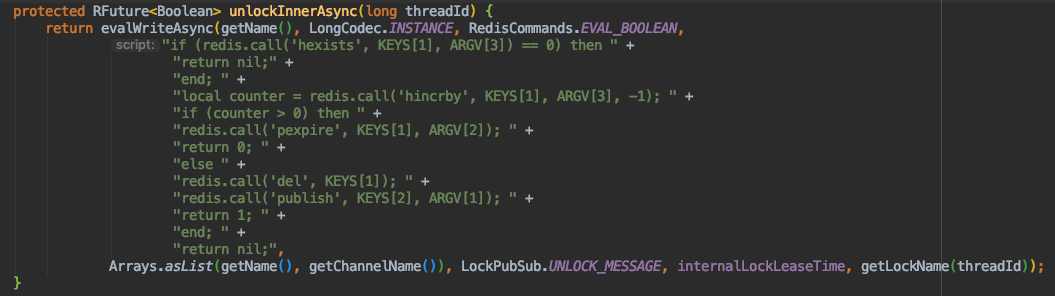
分析其lua脚本实现逻辑:
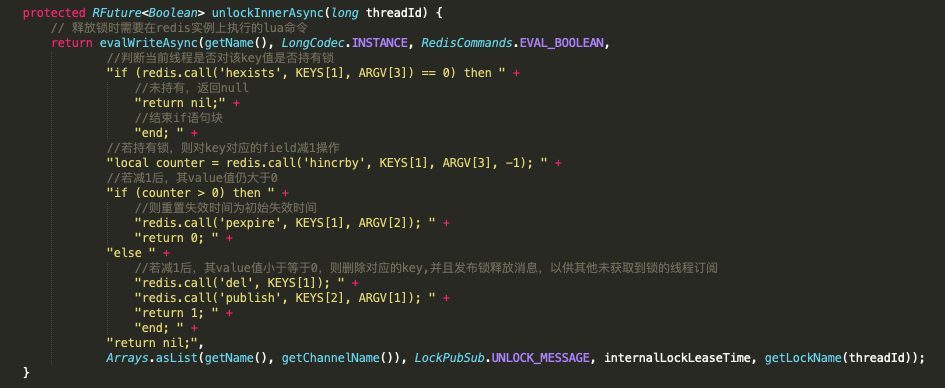
分析可知,在删除对应的key之后,会发布一条消息以供其他未获取到锁的线程订阅,此逻辑和加锁过程遥相呼应,并且在删除key之后做了移除锁重入资格的操作,以保证当前线程彻底释放锁。
八、易混淆概念
我们所说的一个redis实例,并不是一个Redis集群中的某一个master节点或者Slave节点,针对redis集群,一个集群在redLock算法中只是一个实例节点,至于我们的key值放在了哪个slot,是由Redis集群的一致性算法决定的。同样对于哨兵模式也是这样。所以针对RedLock算法来说,如果有N个实例,则是指N个cluster集群、N个sentinel集群、N个redis单实例节点。而不是一个集群中的N个实例。
系列高质量文章,请参阅公众号:编码技术团队 ,承诺 :无广告!持续推送优质系列原创博文


 浙公网安备 33010602011771号
浙公网安备 33010602011771号