允许“定向广播”的数据包使用路由缓存

-
进货: 收到一大袋邮件(
head链表)。 -
查看第一封: 查一下地址,发现是去“北京”的。把它作为“提示(Hint)”。
-
快速分拣: 拿起第二封,看一眼发现也是去“北京”的(利用 Hint),直接扔进“北京堆(sublist)”。
-
遇到变化: 拿起第三封,发现是去“上海”的。
-
先把“北京堆”里的所有邮件打包发走(
ip_sublist_rcv_finish)。 -
把“上海”这封信作为新的“提示(Hint)”,开始建立“上海堆”。
-
-
收尾: 邮件分完了,把最后剩下的那一堆发走。
关键点总结
-
hint(提示) 是灵魂: 只要目的地curr_dst没变,hint就一直有效。这意味着后续的包在执行ip_rcv_finish_core时,根本不需要查路由表,直接抄hint的作业就行,速度极快。 -
curr_dst != dst是分界线: 一旦发现当前包的路由跟刚才的不一样,说明“连胜断了”。必须立刻把之前积攒的包发走,然后重新开始下一轮积累。 -
ip_sublist_rcv_finish是消费者: 它负责接收整理好的、去往同一目的地的“纯净”链表,然后根据路由类型(是转发还是本地接收),批量调用后续的处理函数。
结合之前的补丁
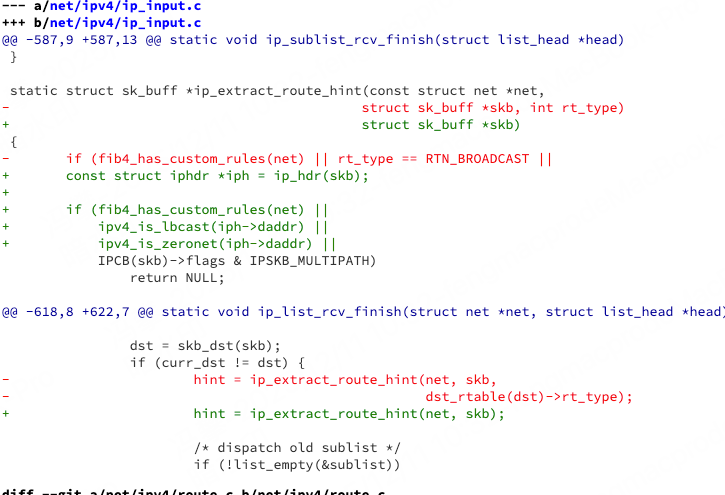
你之前给出的 定向广播补丁,就是修改了上面代码中步骤 5-A 里的 ip_extract_route_hint。
-
修改前: 如果
skb是定向广播,ip_extract_route_hint返回 NULL。导致hint变成 NULL。下一个包进来时,没有 hint 可用,只能慢速查表。 -
修改后: 定向广播也能返回
skb作为hint。下一个定向广播包进来时,直接复用路由,性能起飞。
static void ip_list_rcv_finish(struct net *net, struct list_head *head)
{
struct sk_buff *skb, *next, *hint = NULL;
struct dst_entry *curr_dst = NULL;
LIST_HEAD(sublist);
list_for_each_entry_safe(skb, next, head, list) {
-----------
if (ip_rcv_finish_core(net, skb, dev, hint) == NET_RX_DROP)
continue;
dst = skb_dst(skb);
if (curr_dst != dst) {
hint = ip_extract_route_hint(net, skb);
}
list_add_tail(&skb->list, &sublist);
}
/* dispatch final sublist */
ip_sublist_rcv_finish(&sublist);
}
static struct sk_buff *ip_extract_route_hint(const struct net *net,
struct sk_buff *skb)
{
const struct iphdr *iph = ip_hdr(skb);
if (fib4_has_custom_rules(net) ||
ipv4_is_lbcast(iph->daddr) ||
ipv4_is_zeronet(iph->daddr) ||
IPCB(skb)->flags & IPSKB_MULTIPATH)
return NULL;
return skb;
}
static int ip_rcv_finish_core(struct net *net,
struct sk_buff *skb, struct net_device *dev,
const struct sk_buff *hint)
{
const struct iphdr *iph = ip_hdr(skb);
struct rtable *rt;
int drop_reason;
if (ip_can_use_hint(skb, iph, hint)) {
drop_reason = ip_route_use_hint(skb, iph->daddr, iph->saddr,
ip4h_dscp(iph), dev, hint);
if (unlikely(drop_reason))
goto drop_error;
}
」
/* Implements all the saddr-related checks as ip_route_input_slow(),
* assuming daddr is valid and the destination is not a local broadcast one.
* Uses the provided hint instead of performing a route lookup.
*/
enum skb_drop_reason
ip_route_use_hint(struct sk_buff *skb, __be32 daddr, __be32 saddr,
dscp_t dscp, struct net_device *dev,
const struct sk_buff *hint)
{
enum skb_drop_reason reason = SKB_DROP_REASON_NOT_SPECIFIED;
struct in_device *in_dev = __in_dev_get_rcu(dev);
struct rtable *rt = skb_rtable(hint);
struct net *net = dev_net(dev);
u32 tag = 0;
if (!in_dev)
return reason;
if (ipv4_is_multicast(saddr) || ipv4_is_lbcast(saddr)) {
reason = SKB_DROP_REASON_IP_INVALID_SOURCE;
goto martian_source;
}
-----------------------------
if (!(rt->rt_flags & RTCF_LOCAL))
goto skip_validate_source;
reason = fib_validate_source_reason(skb, saddr, daddr, dscp, 0, dev,
in_dev, &tag);
if (reason)
goto martian_source;
skip_validate_source:
skb_dst_copy(skb, hint);
return SKB_NOT_DROPPED_YET;
martian_source:
ip_handle_martian_source(dev, in_dev, skb, daddr, saddr);
return reason;
}
以前所有的广播包(不管是本地的 255.255.255.255 还是定向的 192.168.1.255)都会在这一步被 return NULL,被踢出快速路径。
现在这段代码里,这个检查被拿掉了。 取而代之的是 ipv4_is_lbcast。 这意味着:定向广播 (Directed Broadcast)(例如 192.168.1.255)不属于 ipv4_is_lbcast,所以它现在可以绕过这个检查,成功返回 skb(即成功拿到了路由提示),进入了快速处理通道。也就是走到最后的 return skb,从而享受到内核的路由缓存加速。这就是性能提升的来源。
-
修改前: 发送大量定向广播包 -> 每次都查路由表 -> 慢,性能差。
-
修改后: 发送大量定向广播包 -> 利用缓存 (hint) -> 快,性能好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号