快速恢复prr prr-ss-ack-below-snd_una
// Test PRR-slowstart implementation. // In this variant we verify that the sender uses SACK info on an ACK // below snd_una. // Set up config. `../common/defaults.sh` // Establish a connection. 0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3 +0 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0 +0 bind(3, ..., ...) = 0 +0 listen(3, 1) = 0 +0 < S 0:0(0) win 32792 <mss 1000,sackOK,nop,nop,nop,wscale 8> +0 > S. 0:0(0) ack 1 <mss 1460,nop,nop,sackOK,nop,wscale 8> // RTT 10ms +.01 < . 1:1(0) ack 1 win 320 +0 accept(3, ..., ...) = 4 // Send 10 data segments. +0 write(4, ..., 10000) = 10000 +0 > P. 1:10001(10000) ack 1 // Lost packet 1:1001,4001:5001,7001:8001. +.01 < . 1:1(0) ack 1 win 320 <sack 1001:2001,nop,nop> +0 < . 1:1(0) ack 1 win 320 <sack 1001:3001,nop,nop> +0 < . 1:1(0) ack 1 win 320 <sack 1001:3001 8001:9001,nop,nop> +0 > . 1:1001(1000) ack 1 +.012 < . 1:1(0) ack 4001 win 320 <sack 8001:9001,nop,nop> +0 > . 4001:7001(3000) ack 1 +0 write(4, ..., 10000) = 10000 // The following ACK was reordered - delayed so that it arrives with // an ACK field below snd_una. Here we check that the newly-SACKed // 2MSS at 5001:7001 cause us to send out 2 more MSS. +.002 < . 1:1(0) ack 3001 win 320 <sack 5001:7001,nop,nop> +0 > . 7001:8001(1000) ack 1 +0 > . 10001:11001(1000) ack 1
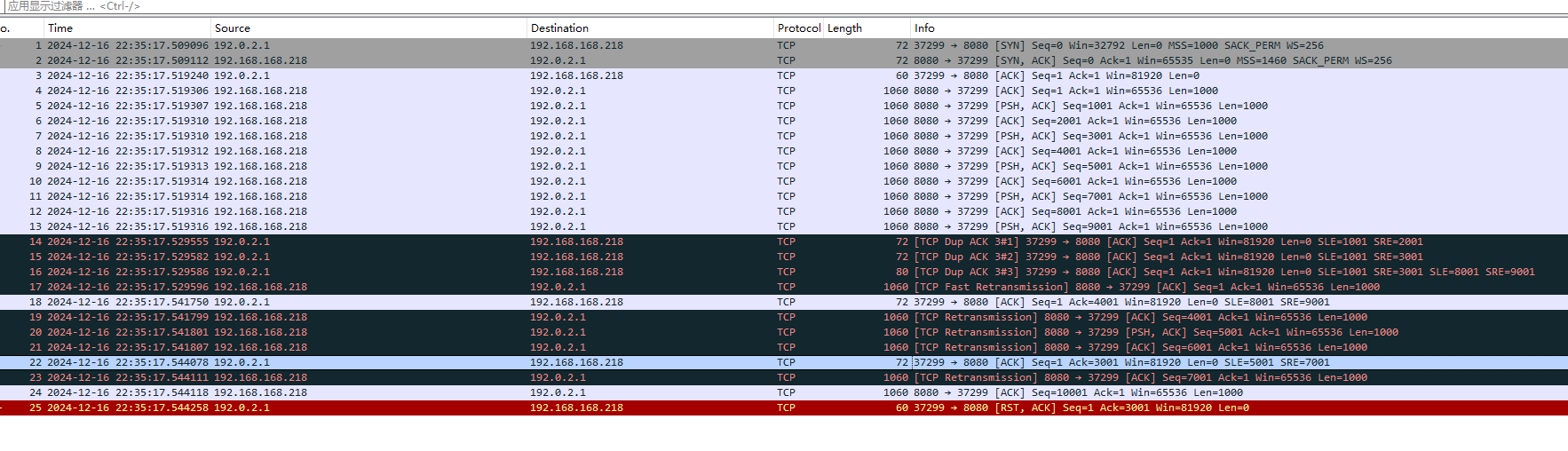
看下报文:
为何不重传 4001:5001??难道是因为?--->
- 目前丢失的块(
4001:5001)并未被包含在 SACK 块中,但堆栈选择优先发送新数据(7001:8001和10001:11001)。 - 这种行为与 Proportional Rate Reduction (PRR) 策略一致,确保新数据发送速率与接收方的 ACK 进度保持一致。
- 如果稍后发现
4001:5001仍未被确认,TCP 将在后续传输中处理
不直接重传 4001:5001,因为:
- SACK 信息提供了更精确的接收状态。
- PRR 策略确保发送速率与 ACK 进度保持一致。
TCP 为什么选择一次性重传多个段而非逐段发送4000-6000 这三段???
原因是:PRR(Proportional Rate Reduction)策略
- PRR 是 TCP 在快速恢复(Fast Recovery)阶段的拥塞控制机制,用于平衡数据重传和新数据发送的速率。
- 根据 PRR 的设计:
- 如果网络允许(由窗口大小、ACK 进度决定),发送方可以在一个 RTT 内重传多个丢失的段。
- PRR 尝试利用可用的带宽最大化数据恢复效率,而非严格逐段重传。
http代理服务器(3-4-7层代理)-网络事件库公共组件、内核kernel驱动 摄像头驱动 tcpip网络协议栈、netfilter、bridge 好像看过!!!!
但行好事 莫问前程
--身高体重180的胖子

 浙公网安备 33010602011771号
浙公网安备 33010602011771号