Computer Networking : Principles, Protocols and Practice prr算法 快速恢复
https://beta.computer-networking.info/syllabus/default/exercises/tcp-2.html
转载:https://blog.csdn.net/m0_38068229/article/details/80417503
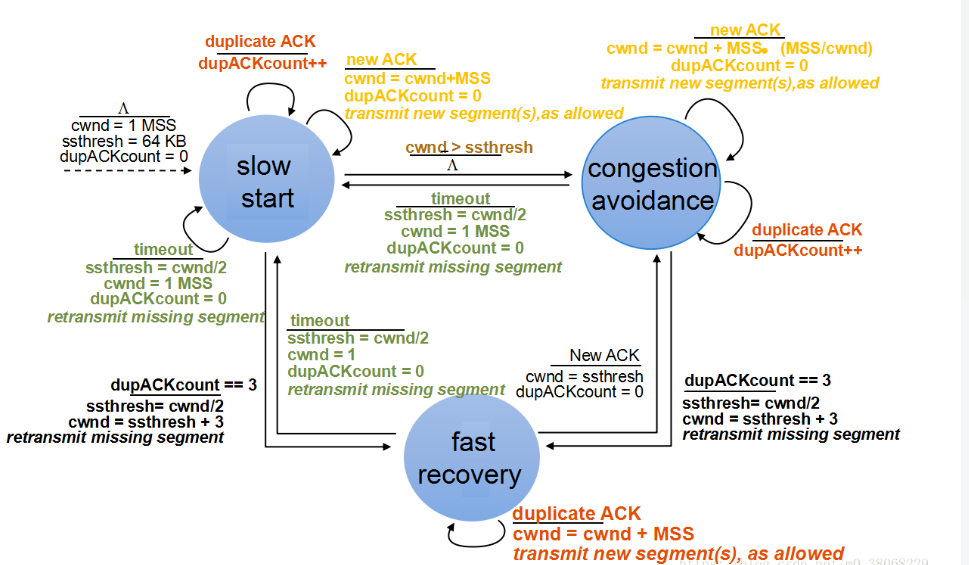
- 一次拥塞中丢失多个报文时若采用Reno算法:(TCP Reno收到新的 ACK就会结束快速恢复,进入拥塞避免阶段)
会多次将拥塞窗口(cwnd)和慢启动阈值(ssthresh)减半,造成TCP的发送速率呈指数降低系统吞吐量急剧下降,(当发送窗口小于3时)无足够的重复ACK可以触发快速恢复,只能等待超时重传。TCP Reno 终端会陷入仅通过传输超时来发现报文丢失的困境中。
- 超时对于TCP的效果有很大的影响:
1、若遗失的数据包无法使用Fast-Retransmit/ Fast-recovery重送,就必须等待超时来触发重送的机制,在等待超时的这段时间,TCP不能重送新的数据,使得链路的使用率很低;
2、超时之后,cwnd的值会被重设为1,大大较低了TCP的传输效果。
New Reno:基于Reno算法的改进\
NewReno TCP在Reno TCP的基础上对快速恢复算法进行修改,只有一个数据包丢失的情况下,其机制和Reno是一样的;当同时有多个包丢失时就显示出了它的优势。
Reno快速恢复算法中发送方收到一个新的ACK就退出快速恢复状态,New Reno算法中只有当所有报文都被应答后才退出快速恢复状态。
NewReno TCP添加了恢复应答判断功能,以增强TCP终端通过ACK报文信息分析报文传输状况的能力。
使TCP终端可以把一次拥塞丢失多个报文的情形与多次拥塞的情形区分开来,进而在每一次拥塞发生后拥塞窗口仅减半一次,从而提高了TCP的顽健性和吞吐量。
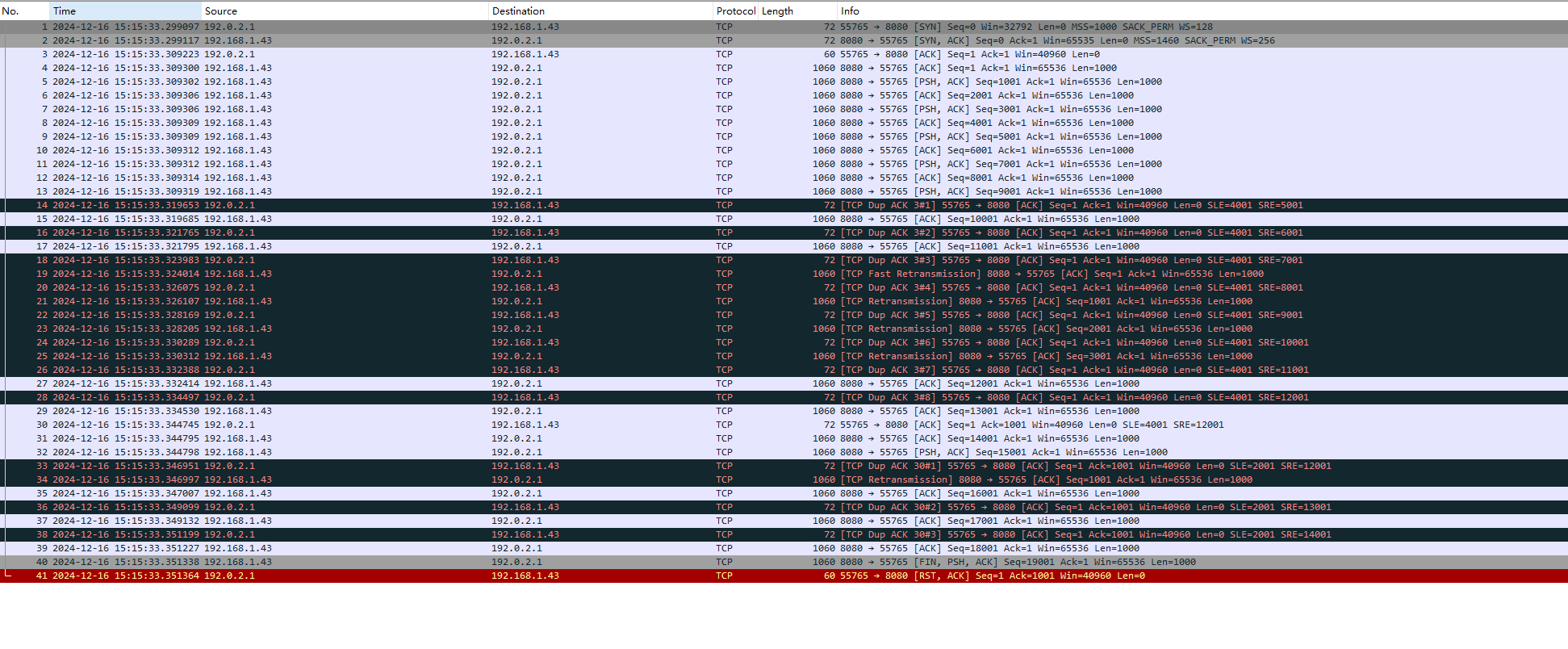
如果4、5、6号包丢了,现在只重传4,只收到了4的ACK,后面的5、6没有确认,这就是部分应答Partial ACK。如果收到了6的ACK,则是恢复应答Recovery ACK。
NewReno发送端在收到第一个Partial ACK时,并不会立即结束Fast-recovery,而会持续地重送Partial ACK之后的数据包,直到将所有遗失的数据包重送后才结束Fast-recovery。收到一个Partial ACK时,重传定时器就复位。这使得NewReno的发送端在网络有大量数据包遗失时不需等待Timeout就能更正此错误,减少大量数据包遗失对传输效果造成的影响。
NewReno大约每一个RTT时间可重传一个丢失的数据包,如果一个发送窗口有M个数据包丢失,TCP NewReno的快速恢复阶段将持续M个RTT。
改进的快速恢复算法具体步骤:
- 重新定义恢复阶段
- 进入恢复阶段后,发送端重传被认定为丢失的报文,设置慢启动阈值(ssthresh)和拥塞窗口大小(cwnd)。ssthresh = cwnd/2,cwnd = ssthresh + 3MSS。
- 收到一个重复ACK,cwnd=cwnd+MSS。
- 当收到PACK --Partial ACK(部分应答)时,发送端重传PACK所确认报文的下一个报文,如果拥塞窗口允许,继续发送新的数据包。
- 当收到Recovery ACK(恢复应答)时,发送端认为拥塞中所有被丢弃的报文都已经被重传,拥塞结束,设置cwnd=ssthresh并退出快速恢复状态。
实践意义的快速恢复
另一种做法是通过 EFS(Estimated FlightSize,表示发送端对网络中徘徊的包的一个猜测值)来完成,一般来说,EFS 就是 cwnd。有了 EFS 的概念,那么每一次 ACK 到来,那意味着传输过程中已经少了一个包,EFS 应该减去 1。当 EFS 一直减到小于 cwnd/2 时,那么就可以进行新的数据包的传输。当丢包的数据成功传达确认后,设为 cwnd=cwnd/2。
 EFS 应用示例,注意加粗部分
EFS 应用示例,注意加粗部分
可以看到 EFS=N-3 时(接收 3 次 dupACK),就触发了快速重传,但是 cwnd 并没有立刻紧缩到 1(而是 N/2+3,加 3 是因为已经收到 3 次 dupACK。原 cwnd 值可以用 ssthresh 暂存);后续在接收 N/2-3 次 dupACK 后就开始恢复新数据的发送(因为每次 dupACK 都会 cwnd+=1),再接下来 N/2-1 次 dupACK 中,每一次 dupACK 都发一个新的数据包。后续窗口会静止直到 non-dup ACK 的到来(ACK[19])。

MPL 问题以及 NewReno
TCP Reno 的拥塞控制仍然残有单个窗口内的 MPL(Multiple-Packet-Loss)问题需要解决。TCP Reno 的观点是接收到一个 partial ACK(non-dup ACK)就是一次成功的重传,因此会从快速恢复回到拥塞避免(见上面的状态机图示)。如果存在多个包丢失的情况,那需要再次走拥塞避免 - 快速重传 - 快速恢复的状态转换,这在实际意义上表明没法在一个 RTT 内处理多个丢包的情况。与之相反,TCP NewReno 视 partial ACK 为一种进一步丢包的信号,因此收到后仍会继续重传(行为上等同于收到一个 dupACK),这使得 TCP NewReno 可以在一个 RTT 范围内处理单个窗口的多个丢包。

如上图,这种状态需要维持到不再接收 partial ACK 为止(即补上了丢包的“空洞”data[1] 和 data[4])。
拥塞避免实现
进入拥塞避免的情况有 2 种,一是 cwnd 早已超过了 ssthresh,二是 cwnd 没有超过 ssthresh,但是 cwnd+acked 超过 ssthresh。
/* In theory this is tp->snd_cwnd += 1 / tp->snd_cwnd (or alternative w),
* for every packet that was ACKed.
*/
__bpf_kfunc void tcp_cong_avoid_ai(struct tcp_sock *tp, u32 w, u32 acked)
{
/* If credits accumulated at a higher w, apply them gently now. */
if (tp->snd_cwnd_cnt >= w) {
tp->snd_cwnd_cnt = 0;
tcp_snd_cwnd_set(tp, tcp_snd_cwnd(tp) + 1);
}
tp->snd_cwnd_cnt += acked;
if (tp->snd_cwnd_cnt >= w) {
u32 delta = tp->snd_cwnd_cnt / w;
tp->snd_cwnd_cnt -= delta * w;
tcp_snd_cwnd_set(tp, tcp_snd_cwnd(tp) + delta);
}
tcp_snd_cwnd_set(tp, min(tcp_snd_cwnd(tp), tp->snd_cwnd_clamp));
}
可以看出内核维护一个 snd_cwnd_cnt 计数器避免了浮点计算,来实现 cwnd+=1/cwnd 的效果。
更改 ssthresh
在内核实现中,拥塞控制是通过维护一个状态机 CA 来实现的。状态机进入到 TCP_CA_CWR/Recovery/Loss 状态时,将执行 tcp_reno_ssthresh() 更改 ssthresh。
在一段注释中提到状态机的工作原理:Linux NewReno/SACK/ECN state machine。
/* Enter Loss state. */
void tcp_enter_loss(struct sock *sk)
{
const struct inet_connection_sock *icsk = inet_csk(sk);
struct tcp_sock *tp = tcp_sk(sk);
struct net *net = sock_net(sk);
bool new_recovery = icsk->icsk_ca_state < TCP_CA_Recovery;
u8 reordering;
tcp_timeout_mark_lost(sk);
/* Reduce ssthresh if it has not yet been made inside this window. */
if (icsk->icsk_ca_state <= TCP_CA_Disorder ||
!after(tp->high_seq, tp->snd_una) ||
(icsk->icsk_ca_state == TCP_CA_Loss && !icsk->icsk_retransmits)) {
tp->prior_ssthresh = tcp_current_ssthresh(sk);
tp->prior_cwnd = tcp_snd_cwnd(tp);
tp->snd_ssthresh = icsk->icsk_ca_ops->ssthresh(sk);
tcp_ca_event(sk, CA_EVENT_LOSS);
tcp_init_undo(tp);
}
tcp_snd_cwnd_set(tp, tcp_packets_in_flight(tp) + 1);
tp->snd_cwnd_cnt = 0;
tp->snd_cwnd_stamp = tcp_jiffies32;
/* Timeout in disordered state after receiving substantial DUPACKs
* suggests that the degree of reordering is over-estimated.
*/
reordering = READ_ONCE(net->ipv4.sysctl_tcp_reordering);
if (icsk->icsk_ca_state <= TCP_CA_Disorder &&
tp->sacked_out >= reordering)
tp->reordering = min_t(unsigned int, tp->reordering,
reordering);
tcp_set_ca_state(sk, TCP_CA_Loss);
tp->high_seq = tp->snd_nxt;
tcp_ecn_queue_cwr(tp);
/* F-RTO RFC5682 sec 3.1 step 1: retransmit SND.UNA if no previous
* loss recovery is underway except recurring timeout(s) on
* the same SND.UNA (sec 3.2). Disable F-RTO on path MTU probing
*/
tp->frto = READ_ONCE(net->ipv4.sysctl_tcp_frto) &&
(new_recovery || icsk->icsk_retransmits) &&
!inet_csk(sk)->icsk_mtup.probe_size;
}
一个 ca_ops->ssthresh() 的调用时机在 tcp_enter_loss(),通过它来改动 tp->snd_ssthresh 取值。
/* Slow start threshold is half the congestion window (min 2) */
__bpf_kfunc u32 tcp_reno_ssthresh(struct sock *sk)
{
const struct tcp_sock *tp = tcp_sk(sk);
return max(tcp_snd_cwnd(tp) >> 1U, 2U);
}
具体的实现接近如上面描述的算法 ssthresh=cwnd/2,唯一的差异是确保最小 ssthresh=2。
丢失恢复实现
这一块已经不在 tcp_cong.c 的范围内(这是 NewReno 实现的文件),而是在 tcp_input.c 或者 tcp_recovery.c,并且加入了非常多的高级特性。
/*
* The sender is in fast recovery and retransmitting lost packets,
* typically triggered by ACK events.
*/
TCP_CA_Recovery = 3,
// ...
/*
* The sender is in loss recovery triggered by retransmission timeout.
*/
TCP_CA_Loss = 4
对于 CA 状态机,我关注这两个:TCP_CA_Recovery 和 TCP_CA_Loss。如果是 ACK 确认,那可能进入 TCP_CA_Recovery,表明 cwnd 已经缩减,并且是进入快速重传的状态;如果是 RTO 超时,那么相对的进入 TCP_CA_Loss,该状态也可能是 SACK 导致的。
/* RFC6582 NewReno recovery for non-SACK connection. It simply retransmits
* the next unacked packet upon receiving
* a) three or more DUPACKs to start the fast recovery
* b) an ACK acknowledging new data during the fast recovery.
*/
void tcp_newreno_mark_lost(struct sock *sk, bool snd_una_advanced)
{
const u8 state = inet_csk(sk)->icsk_ca_state;
struct tcp_sock *tp = tcp_sk(sk);
if ((state < TCP_CA_Recovery && tp->sacked_out >= tp->reordering) ||
(state == TCP_CA_Recovery && snd_una_advanced)) {
struct sk_buff *skb = tcp_rtx_queue_head(sk);
u32 mss;
if (TCP_SKB_CB(skb)->sacked & TCPCB_LOST)
return;
mss = tcp_skb_mss(skb);
if (tcp_skb_pcount(skb) > 1 && skb->len > mss)
tcp_fragment(sk, TCP_FRAG_IN_RTX_QUEUE, skb,
mss, mss, GFP_ATOMIC);
tcp_mark_skb_lost(sk, skb);
}
}
对于 non-SACK 的 NewReno 实现,接收超过 3 个 dupACK 就触发快速重传/恢复过程。调用关系为:
tcp_ack()
tcp_fastretrans_alert(num_dupack)
tcp_identify_packet_loss()
tcp_newreno_mark_lost()
tcp_mark_skb_lost()
tcp_mark_skb_lost() 会更新 lost_out 统计(用于估算 in-flght packet 的数目),并且记录首个应当(快速)重传的报文。
tcp_fastretrans_alert() 通过 tcp_enter_recovery() 使得状态机进入 TCP_CA_Recovery。这个在前面的状态机注释中也提到:tcp_fastretrans_alert() is entered: … when arrived ACK is unusual, namely: … Duplicate ACK.
/* Congestion control has updated the cwnd already. So if we're in
* loss recovery then now we do any new sends (for FRTO) or
* retransmits (for CA_Loss or CA_recovery) that make sense.
*/
static void tcp_xmit_recovery(struct sock *sk, int rexmit)
{
struct tcp_sock *tp = tcp_sk(sk);
if (rexmit == REXMIT_NONE || sk->sk_state == TCP_SYN_SENT)
return;
if (unlikely(rexmit == REXMIT_NEW)) {
__tcp_push_pending_frames(sk, tcp_current_mss(sk),
TCP_NAGLE_OFF);
if (after(tp->snd_nxt, tp->high_seq))
return;
tp->frto = 0;
}
tcp_xmit_retransmit_queue(sk);
}
tcp_xmit_recovery() 过程在 tck_ack() 的尾部,当 tck_ack() 函数中已经更新好 cwnd 后,则开始重传处理 retransmit queue

 浙公网安备 33010602011771号
浙公网安备 33010602011771号