Linux VRF
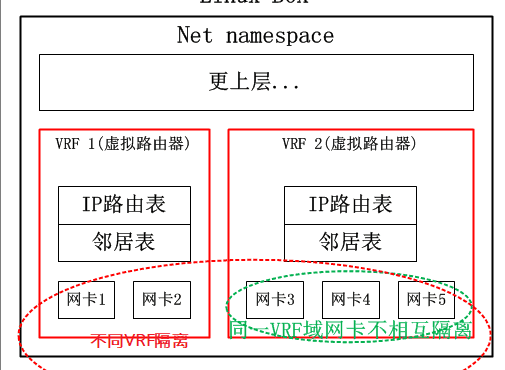
VRF顾名思义就是虚拟路由转发(Virtual Routing Forwarding),VRF 允许在同一物理设备上维护多个独立的路由实例;简单点来讲,就是把一台路由器当多台虚拟路由器来用。
不同 VRF 实例之间的流量是相互隔离的。这对于提供多租户服务非常有用,确保一个租户的流量不会影响到其他租户。
-
IP 地址重用:
- VRF 允许在不同的虚拟路由表中重用相同的 IP 地址。例如,在一个 VRF 中可以使用 IP 地址
192.168.1.1,而在另一个 VRF 中也可以使用相同的地址,这样可以节省地址空间。
- VRF 允许在不同的虚拟路由表中重用相同的 IP 地址。例如,在一个 VRF 中可以使用 IP 地址
-
灵活的路由管理:
- VRF 提供了更灵活的路由管理,可以为每个 VRF 配置不同的路由策略、路由协议和网络配置。
-
支持复杂网络设计:
- VRF 支持更复杂的网络设计,例如 MPLS(多协议标签交换)网络,在这些网络中,流量可以通过不同的路径路由,并在多个 VRF 之间进行交换。
OpenVPN典型的多处理拓扑,在一台服务器上会构建超级多的TAP网卡,每个TAP服务一个特定的VPN客户端,有了VRF的支撑后,不同的VPN节点便可以使用相同的IP网段了,所要做的仅仅是将不同的TAP网卡置入不同的VRF域即可。
VRF是一台物理路由器当多台虚拟路由器使用的,那么在这多台虚拟路由器之间就必须做到从物理层到三层路由的全部隔离,而策略路由仅仅是路由表的隔离,甚至在仅仅使能了策略路由的路由器上,其二层三层之间的邻居表都是共享的。
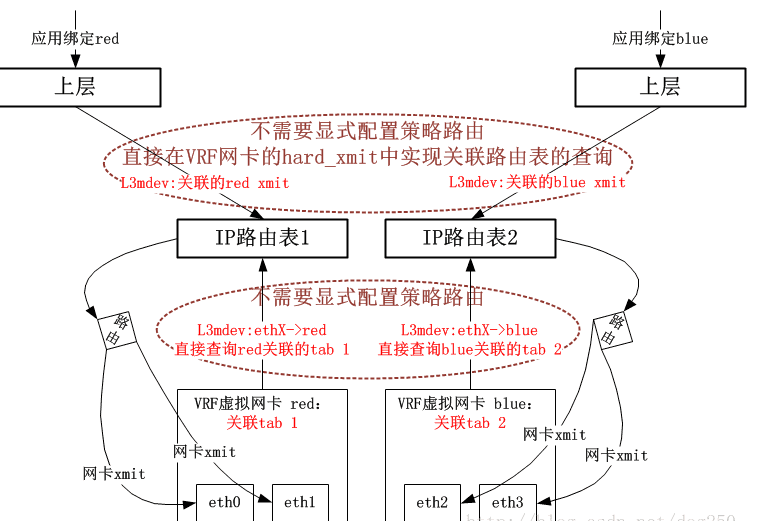
不过,策略路由确实是实现VRF的组件之一,它确实可以完成VRF的路由表隔离。为了实现二层隔离以及网卡的隔离,还需要另外的技术,Linux的VRF实现中,采用了一种叫做L3mdev的技术来支持一种三层的虚拟网卡,利用这种虚拟网卡来隐藏网卡之间的可见性
进程可以通过将套接字绑定到 VRF 设备来实现“VRF 感知”。通过该套接字的报文将使用与 VRF 设备相关联的路由表。VRF 设备实现的一个重要特性是,它仅影响第三层及以上,因此二层工具(例如 LLDP)不受影响(即不需要在每个 VRF 中运行)。该设计还允许使用更高优先级的 IP 规则(基于策略的路由,PBR)优先于 VRF 设备规则,从而根据需要定向特定流量。
应用
需要在 VRF 内部工作的应用程序需要将其套接字绑定到 VRF 设备:
`setsockopt(sd, SOL_SOCKET, SO_BINDTODEVICE, dev, strlen(dev)+1);` 或使用 cmsg 和 IP_PKTINFO 指定输出设备。
默认情况下,未绑定套接字的端口绑定范围限于默认 VRF。也就是说,它将不会被到达 l3mdev 奴役接口的数据包匹配,如果进程绑定到 l3mdev,它们可以绑定到同一端口。
在默认 VRF 上下文中运行的 TCP 和 UDP 服务(即,不绑定到任何 VRF 设备)可以通过启用 tcp_l3mdev_accept 和 udp_l3mdev_accept sysctl 选项跨所有 VRF 域工作:
`sysctl -w net.ipv4.tcp_l3mdev_accept=1` `sysctl -w net.ipv4.udp_l3mdev_accept=1` 这些选项默认是禁用的,因此 VRF 中的套接字仅选择来自该 VRF 的数据包。RAW 套接字有类似的选项,出于向后兼容的原因默认启用。这使得可以使用 cmsg 和 IP_PKTINFO 指定输出设备,但使用未绑定到相应 VRF 的套接字。这允许例如,旧的 ping 实现可以在指定设备但不在 VRF 中执行的情况下运行。可以禁用此选项,以便在 VRF 上下文中接收到的数据包仅由绑定到 VRF 的原始套接字处理,而默认 VRF 中的数据包仅由未绑定到任何 VRF 的套接字处理:
`sysctl -w net.ipv4.raw_l3mdev_accept=0`采用新的L3mdev机制的VRF实现框图
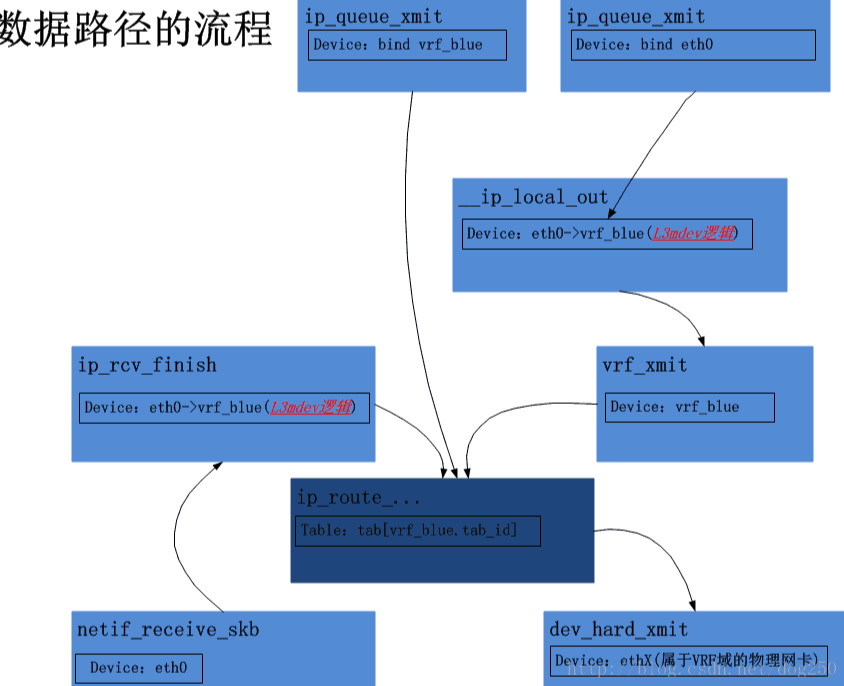
网卡收包过程的VRF实现分析
从独立的物理网卡,比如ethx收到数据包,依次经过网卡驱动程序,netif_receive_skb,ip_rcv等调用,直到ip_rcv_finish被调用之前,VRF的逻辑和非VRF逻辑并没有任何不同支持,在ip_rcv_finish中处理vrf l3mdev
static int ip_rcv_finish(struct net *net, struct sock *sk, struct sk_buff *skb) { struct net_device *dev = skb->dev; int ret; /* if ingress device is enslaved to an L3 master device pass the * skb to its handler for processing */ // 这里增加了这么一个L3mdev调用,正是该L3mdev逻辑实现了VRF的核心:路由表使用与VRF域关联的策略路由表 skb = l3mdev_ip_rcv(skb); if (!skb) return NET_RX_SUCCESS; ret = ip_rcv_finish_core(net, sk, skb, dev, NULL); if (ret != NET_RX_DROP) ret = dst_input(skb); return ret; }
l3mdev_ip_rcv的逻辑非常简单,对于VRF而言,实现l3mdev_l3_rcv回调函数完成的功能仅仅是:
- 将skb的dev字段重新修改为该dev的master设备,即该物理网卡附着的VRF虚拟网卡设备
当我们配置了至少一个VRF域的时候,我们将会看到如下的结果:
[root@ubuntu22 ~]# ip rule ls 0: from all lookup local 1000: from all lookup [l3mdev-table] 32766: from all lookup main 32767: from all lookup default
多了一个l3mdev-table,系统在遍历rules链表的时候,遇到[l3mdev-table]表的时候,采用的是一种隐式的处理方式。意思是说,
即便你创建了多个VRF域,关联了多张策略路由表,系统中依然只能看到一张[l3mdev-table]表。
既然这样,系统又是如何定位到与特定的VRF域关联的那张路由表呢?比如说,vrf-blue关联了路由表10,vrf-red关联了路由表20

xxx
static int fib_rule_match(struct fib_rule *rule, struct fib_rules_ops *ops, struct flowi *fl, int flags, struct fib_lookup_arg *arg) { // 前面的逻辑是常规的iif,oif,mark等匹配,以下的这个l3mdev不一般! // rule->l3mdev即ip rule ls看到的那个[l3mdev-table] if (rule->l3mdev && !l3mdev_fib_rule_match(rule->fr_net, fl, arg)) goto out;
static u32 vrf_fib_table(const struct net_device *dev) { struct net_vrf *vrf = netdev_priv(dev); return vrf->tb_id; }
/** * l3mdev_fib_rule_match - Determine if flowi references an * L3 master device * @net: network namespace for device index lookup * @fl: flow struct */ int l3mdev_fib_rule_match(struct net *net, struct flowi *fl, struct fib_lookup_arg *arg) { struct net_device *dev; int rc = 0; rcu_read_lock(); dev = dev_get_by_index_rcu(net, fl->flowi_oif); if (dev && netif_is_l3_master(dev) && dev->l3mdev_ops->l3mdev_fib_table) { // 如果这个dev是一个VRF master虚拟网卡设备 // 那么便通过其自身的回调函数取出和该VRF关联的策略路由表! arg->table = dev->l3mdev_ops->l3mdev_fib_table(dev); rc = 1; goto out; } dev = dev_get_by_index_rcu(net, fl->flowi_iif); if (dev && netif_is_l3_master(dev) && dev->l3mdev_ops->l3mdev_fib_table) { arg->table = dev->l3mdev_ops->l3mdev_fib_table(dev); rc = 1; goto out; } out: rcu_read_unlock(); return rc; }
- 首先在ip_rcv_finish的l3mdev_ip_rcv调用中定位到与收包物理网卡关联的VRF master虚拟网卡
- 然后在fib_lookup内层的l3mdev_fib_rule_match调用中取出与VRF master虚拟网卡关联的策略路由表
- 最终在该特定的路由表中进行路由查找
本地始发包的VRF实现
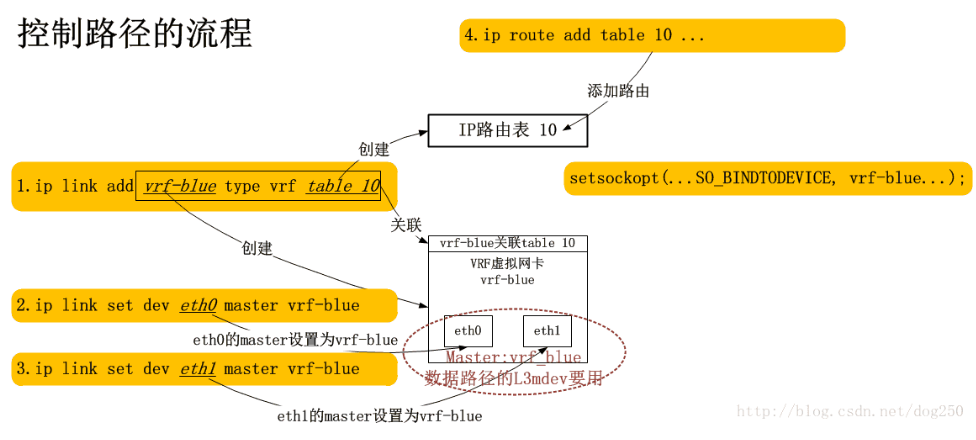
如若一个socket程序想使用VRF机制,就必须为一个socket去绑定一个特定的网卡:
setsockopt(sd, SOL_SOCKET, SO_BINDTODEVICE, vrf_dev, strlen(vrf_dev)+1);
有了这个调用,在ip_queue_xmit中查找路由的时候,自然就会在fib_rule_match中定位到与参数vrf_dev关联的策略路由表了,
然而,如果socket程序并不知情,它只是bind了一个隶属于该vrf_dev的slave物理网卡,比如eth0,那要怎么处理呢?
显然SO_BINDTODEVICE参数会为数据包在__ip_route_output_key_hash调用中的路由查找失败而负责,为其暂时绑定一个dummy dst_entry,从而逻辑可以到达__ip_local_out:
int __ip_local_out(struct net *net, struct sock *sk, struct sk_buff *skb) { struct iphdr *iph = ip_hdr(skb); iph->tot_len = htons(skb->len); ip_send_check(iph); /* if egress device is enslaved to an L3 master device pass the * skb to its handler for processing */ skb = l3mdev_ip_out(sk, skb); if (unlikely(!skb)) return 0; skb->protocol = htons(ETH_P_IP); return nf_hook(NFPROTO_IPV4, NF_INET_LOCAL_OUT, net, sk, skb, NULL, skb_dst(skb)->dev, dst_output); }
和网卡收包过程的l3mdev调用一样,我们看下这个与l3mdev_ip_rcv相对的l3mdev_ip_out调用里做了什么文章,实现对应回调函数的是vrf_ip_out:
/* called with rcu lock held */ static struct sk_buff *vrf_l3_out(struct net_device *vrf_dev, struct sock *sk, struct sk_buff *skb, u16 proto) { switch (proto) { case AF_INET: return vrf_ip_out(vrf_dev, sk, skb); case AF_INET6: return vrf_ip6_out(vrf_dev, sk, skb); } return skb; }
static struct sk_buff *vrf_ip_out(struct net_device *vrf_dev, struct sock *sk, struct sk_buff *skb) { /* don't divert multicast or local broadcast */ if (ipv4_is_multicast(ip_hdr(skb)->daddr) || ipv4_is_lbcast(ip_hdr(skb)->daddr)) return skb; if (qdisc_tx_is_default(vrf_dev) || IPCB(skb)->flags & IPSKB_XFRM_TRANSFORMED) return vrf_ip_out_direct(vrf_dev, sk, skb); return vrf_ip_out_redirect(vrf_dev, skb); } /* set dst on skb to send packet to us via dev_xmit path. Allows * packet to go through device based features such as qdisc, netfilter * hooks and packet sockets with skb->dev set to vrf device. */ static struct sk_buff *vrf_ip_out_redirect(struct net_device *vrf_dev, struct sk_buff *skb) { struct net_vrf *vrf = netdev_priv(vrf_dev); struct dst_entry *dst = NULL; struct rtable *rth; rcu_read_lock(); // 取出VRF关联的那个唯一的dst_entry,以便将数据包定向到vrf_xmit rth = rcu_dereference(vrf->rth); if (likely(rth)) { dst = &rth->dst; dst_hold(dst); } rcu_read_unlock(); if (unlikely(!dst)) { vrf_tx_error(vrf_dev, skb); return NULL; } skb_dst_drop(skb); skb_dst_set(skb, dst); return skb; }
很简单,在这里仅仅是将skb的那个dummy dst_entry换成了和VRF设备绑定的那个dst_entry。
与VRF设备绑定的dst_entry只有一个且只做一件事,那就是,调用VRF设备的dev_hard_xmit回调函数,VRF机制正是在该dev_hard_xmit回调函数中实现了真正的路由查询,在dev_hard_xmit回调中真正做事的函数是vrf_process_v4_outbound:
static netdev_tx_t vrf_process_v4_outbound(struct sk_buff *skb, struct net_device *vrf_dev) { struct iphdr *ip4h; ip4h = ip_hdr(skb); memset(&fl4, 0, sizeof(fl4)); /* needed to match OIF rule */ // 这个会让l3mdev_fib_rule_match定位到正确的路由表 fl4.flowi4_oif = vrf_dev->ifindex; fl4.flowi4_iif = LOOPBACK_IFINDEX; fl4.flowi4_tos = RT_TOS(ip4h->tos); fl4.flowi4_flags = FLOWI_FLAG_ANYSRC | FLOWI_FLAG_SKIP_NH_OIF; fl4.flowi4_proto = ip4h->protocol; fl4.daddr = ip4h->daddr; fl4.saddr = ip4h->saddr; // 真实查路由 rt = ip_route_output_flow(net, &fl4, NULL); skb_dst_drop(skb); /* if dst.dev is loopback or the VRF device again this is locally * originated traffic destined to a local address. Short circuit * to Rx path */ if (rt->dst.dev == vrf_dev) return vrf_local_xmit(skb, vrf_dev, &rt->dst); skb_dst_set(skb, &rt->dst); /* strip the ethernet header added for pass through VRF device */ __skb_pull(skb, skb_network_offset(skb)); if (!ip4h->saddr) { ip4h->saddr = inet_select_addr(skb_dst(skb)->dev, 0, RT_SCOPE_LINK); } // 真实发送skb ret = vrf_ip_local_out(dev_net(skb_dst(skb)->dev), skb->sk, skb); }
Linux的网络协议栈实现中体现为要先强制查询Local路由表,然后再查Main路由表;
The kernel uses FIB rules (Policy Based Routing, PBR) to direct a packet's lookup through the different FIB tables. By default, packets first undergo a lookup in the local table and in case of a miss in the main table as well. $ ip [-6] rule show 0: from all lookup local 32766: from all lookup main 32767: from all lookup default Upon the creation of the first VRF device, an FIB rule is inserted with priority 1000 to direct lookup of packets passing through enslaved devices to the VRF's table: $ ip link add name vrf-blue type vrf table 10 $ ip [-6] rule show 0: from all lookup local 1000: from all lookup [l3mdev-table] 32766: from all lookup main 32767: from all lookup default Therefore, when packets are forwarded by the kernel they first undergo a lookup in the local table and then in the VRF's table. This is in contrast to the device's data path, where packets only perform a lookup in the VRF's table. It is thus recommended to change the order of the default rules, so that the rule for the local table is just before the main table: $ ip [-6] rule add pref 32765 table local $ ip [-6] rule del pref 0 $ ip [-6] rule show 1000: from all lookup [l3mdev-table] 32765: from all lookup local 32766: from all lookup main 32767: from all lookup default Note: Prior to kernel 4.8, iif and oif FIB rules were needed for each VRF device, instead of a single l3mdev rule for all VRF devices. The old model is not supported and upon the insertion of such rules the device's
FIB tables are flushed and forwarding is performed by the kernel.
TCP Listener问题
本send的流量,必须要为其通过显式的setsockopt调用绑定一个VRF设备才能路由
由于绑定VRF虚拟网卡设备的setsockopt是针对特定socket的,如果我们仅仅针对Listener socket做了这样的setsocketopt,那么对于别的那些被这个Listener socket给Accept的那些socket,谁来负责呢(需要一种机制,让所有相关的socket都绑定VRF网卡)
我们实在没有必要在accept返回后为每一个返回的client socket都去bind一个VRF device,系统可以自动做到这一点:
sysctl -w net.ipv4.tcp_l3mdev_accept=0
tcp_l3mdev_accept=0(默认):
- 默认情况下,此选项是禁用的,表示 TCP 套接字只能处理绑定到相同 VRF 的流量。未绑定 VRF 的套接字只能处理默认 VRF 的流量,而绑定到特定 VRF 的套接字只能处理该 VRF 内部的流量。
- 当
tcp_l3mdev_accept设置为 1 时,意味着 TCP 服务能够跨 VRF 域接受连接请求。也就是说,TCP 套接字不需要绑定到特定的 VRF 设备,而是可以接受来自任意 VRF 的连接。这种行为打破了 VRF 的隔离边界,允许所有 VRF 域中的数据包与未绑定 VRF 的 TCP 套接字进行通信。
TCP & UDP services running in the default VRF context (ie., not bound to any VRF device) can work across all VRF domains by enabling the tcp_l3mdev_accept and udp_l3mdev_accept sysctl options:
sysctl -w net.ipv4.tcp_l3mdev_accept=1 sysctl -w net.ipv4.udp_l3mdev_accept=1
Applications ------------ Applications that are to work within a VRF need to bind their socket to the VRF device: setsockopt(sd, SOL_SOCKET, SO_BINDTODEVICE, dev, strlen(dev)+1); or to specify the output device using cmsg and IP_PKTINFO. By default the scope of the port bindings for unbound sockets is limited to the default VRF. That is, it will not be matched by packets arriving on interfaces enslaved to an l3mdev and processes may bind to the same port if they bind to an l3mdev. TCP & UDP services running in the default VRF context (ie., not bound to any VRF device) can work across all VRF domains by enabling the tcp_l3mdev_accept and udp_l3mdev_accept sysctl options: sysctl -w net.ipv4.tcp_l3mdev_accept=1 sysctl -w net.ipv4.udp_l3mdev_accept=1 These options are disabled by default so that a socket in a VRF is only selected for packets in that VRF. There is a similar option for RAW sockets, which is enabled by default for reasons of backwards compatibility. This is so as to specify the output device with cmsg and IP_PKTINFO, but using a socket not bound to the corresponding VRF. This allows e.g. older ping implementations to be run with specifying the device but without executing it in the VRF. This option can be disabled so that packets received in a VRF context are only handled by a raw socket bound to the VRF, and packets in the default VRF are only handled by a socket not bound to any VRF: sysctl -w net.ipv4.raw_l3mdev_accept=0 netfilter rules on the VRF device can be used to limit access to services running in the default VRF context as well.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号