转载Cubic拥塞控制算法进行简单分析
BIC是binary increase congestion contrl的缩写。不同拥塞控制算法的核心差异其实都体现在拥塞避免阶段。过去reno拥塞控制算法的主要缺点是增cwnd采用的方式是累加的线性增窗(AI,additive increase)。线性增窗主要缺点是:
- 每经过一个RTO,cwnd才加1,如果RTO很长的话,需要很久才可以恢复到比较大的cwnd值,这样性能就不好了
BIC采binary increase的方式主要是在拥塞避免阶段采用二分查找的搜索来增加cwnd而不是像reno一样固定增加1
BIC原理
BIC相比reno的核心差别就是拥塞避免阶段增加cwnd的方式不同。BIC可以让cwnd尽快恢复到比较大的值。为了理解BIC,以下两个定义我们先需要理解:
- Wmax: 发现丢包时(认为网络产生拥堵),此时我们的拥塞窗口定义成Wmax
- Wmin: 乘法减小后的cwnd值
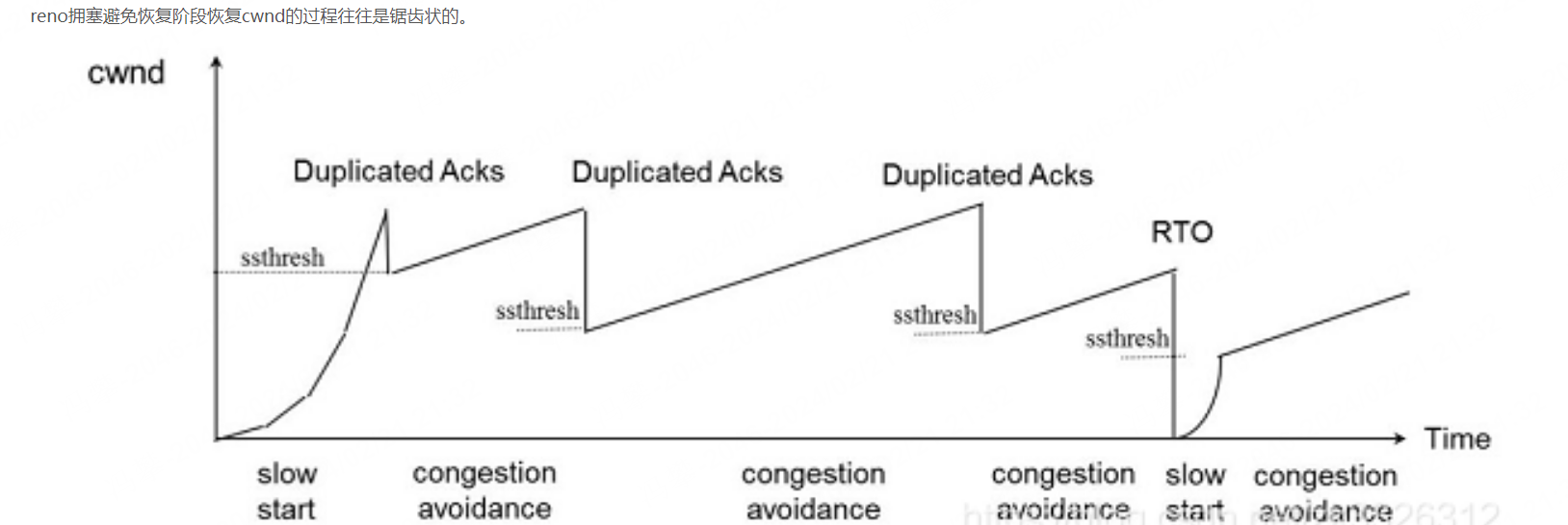
bic拥塞避免恢复cwnd的过程也是加法增加的,只不过每次不是增加1,而是采用二分查找的探测手段决定到底需要加多少。其cwnd的恢复过程如下。cwnd能以较快的方式接近Wmax并且尽量维持多的时间。BIC相比reno主要带来以下好处:Wmax收敛快,相比reno可以更快的收敛到Wmax。
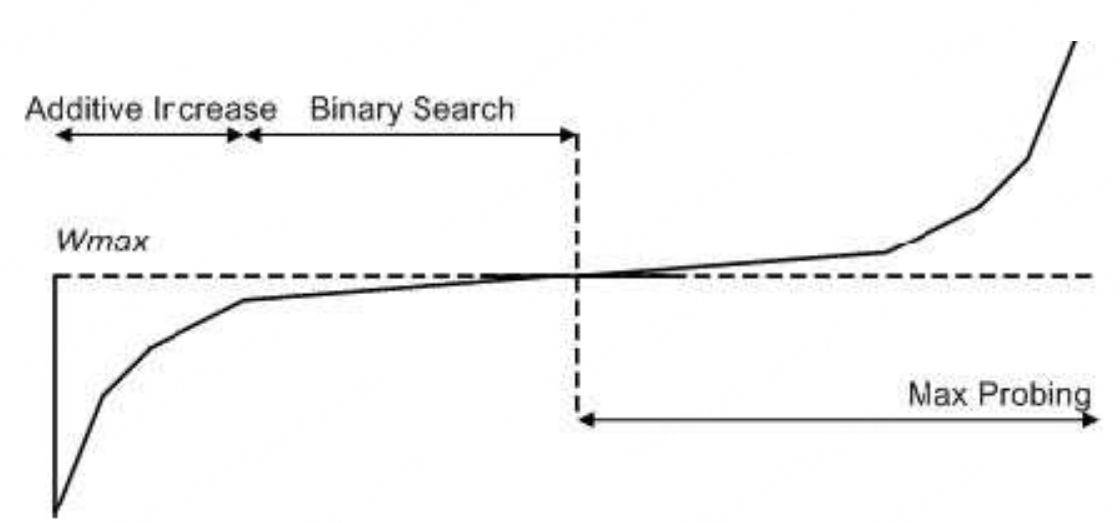
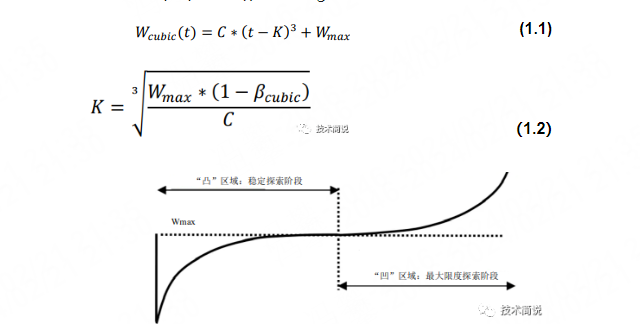
上图曲线右侧的过程是max cwnd的探测过程。BIC在cwnd超过Wmax以后,如果长时间未发生丢包,认为网络情况良好,则会慢慢增加cwnd的窗口取抢占更多带宽资源。
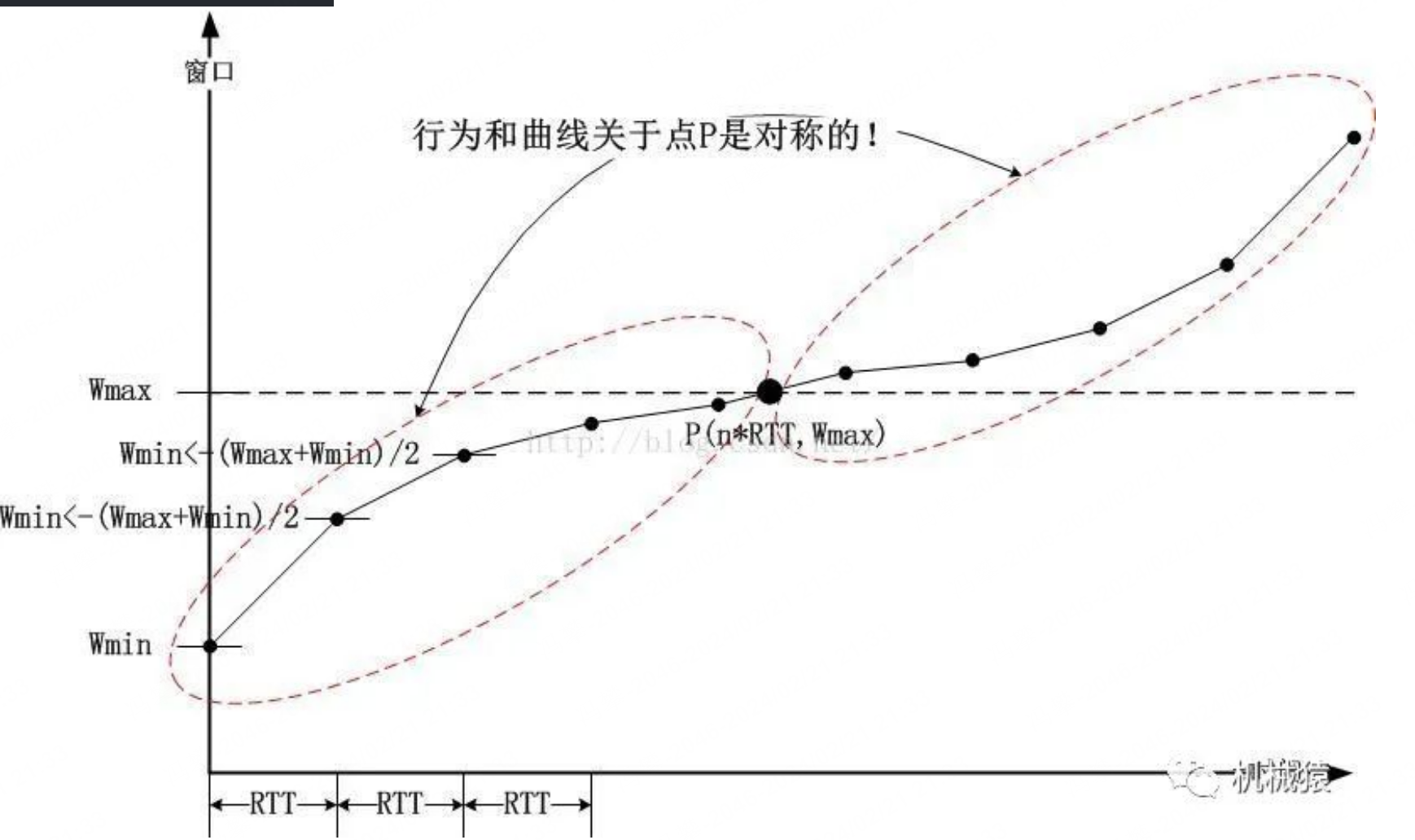
如何通过二分查找确定cwnd增加的值
就是不断递归 newWmin =(Wmax+Wmin)/2的过程即可:
BIC的缺点
正所谓,成也萧何败也萧何。快速收敛到Wmax在长RTT的情况下,是比较适合的,但是在短RTT的劣网环境下,激进的增窗会引发带宽的争抢,使得拥塞控制不具备公平性。公平性指的是新链路也可以像老链路一样公平的去获取带宽资源。显然BIC在短RTT劣网环境下会破坏这个公平性。
因为为了改进短RTT劣网环境下BIC公平性的问题,就引入了CUBIC
CUBIC的论文可以参考:CUBIC: A New TCPFriendly HighSpeed TCP Variant
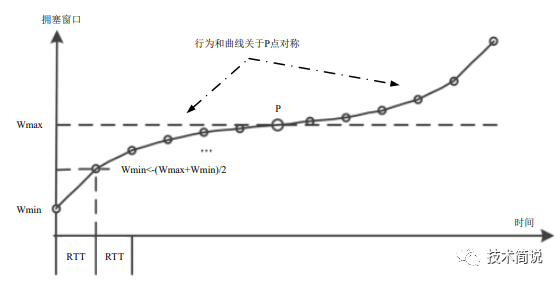
为缓解BIC的RTT不公平性问题,提出Cubic拥塞控制算法,Cubic的解决方法比较直接,将类似二分法的拥塞窗口函数设计成了如下1.1的三次函数 。
函数大致图像如下图所示,需要值得关注的是,函数的横坐标是时间T,而不是RTT。具体地,函数表达式如1.1所示。函数中的C是一个常数,作为调节因子,t是最近一次检测到丢包后经过的时间(如果假设丢包后进入一个新的拥塞窗口探索轮次,那么t就是当前轮次的持续时间,也是自上次窗口减少到当前的时间)。
K的取值如1.2所示,其中𝛽是乘法减少因子,𝑊𝑚𝑎𝑥是最近一次发生网络拥塞时的拥塞窗口值,K代表1.1函数在没有丢包的条件下,从当前拥塞窗口增长到𝑊𝑚𝑎𝑥所要花费的时间。从1.1公式里也可以看出来,拥塞窗口的变化不再是由RTT强相关。
在拥塞避免阶段接收到ACK时,Cubic在下一个RTT使用公式1.1计算拥塞窗口(W(t+RTT))作为Target。
CUBIC和BIC是类似的,同样也是乘法减小的过程,那么也就意味着t=0时刻,窗口是我们的Wmin,也就是β*Wmax,把t=0,W(0)=β*Wmax带入,解出来
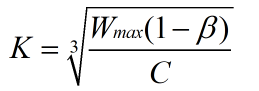
以上,将BIC到Cubic的基本原理进行了概览,下面将切入到Linux内核源码中看Cubic拥塞控制算法的相关实现。在分析代码流程前,这里先把Cubic拥塞控制算法涉及的核心变量贴出来:
struct bictcp {
u32 cnt; /* increase cwnd by 1 after ACKs */
u32 last_max_cwnd; /* last maximum snd_cwnd */
u32 last_cwnd; /* the last snd_cwnd */
u32 last_time; /* time when updated last_cwnd */
u32 bic_origin_point;/* origin point of bic function */
u32 bic_K; /* time to origin point
from the beginning of the current epoch */
u32 delay_min; /* min delay (msec << 3) */
u32 epoch_start; /* beginning of an epoch */
u32 ack_cnt; /* number of acks */
u32 tcp_cwnd; /* estimated tcp cwnd */
u16 unused;
u8 sample_cnt; /* number of samples to decide curr_rtt */
u8 found; /* the exit point is found? */
u32 round_start; /* beginning of each round */
u32 end_seq; /* end_seq of the round */
u32 last_ack; /* last time when the ACK spacing is close */
u32 curr_rtt; /* the minimum rtt of current round */
}struct sock *sk;
struct tcp_sock *tp = tcp_sk(sk);
struct bictcp *ca = inet_csk_ca(sk);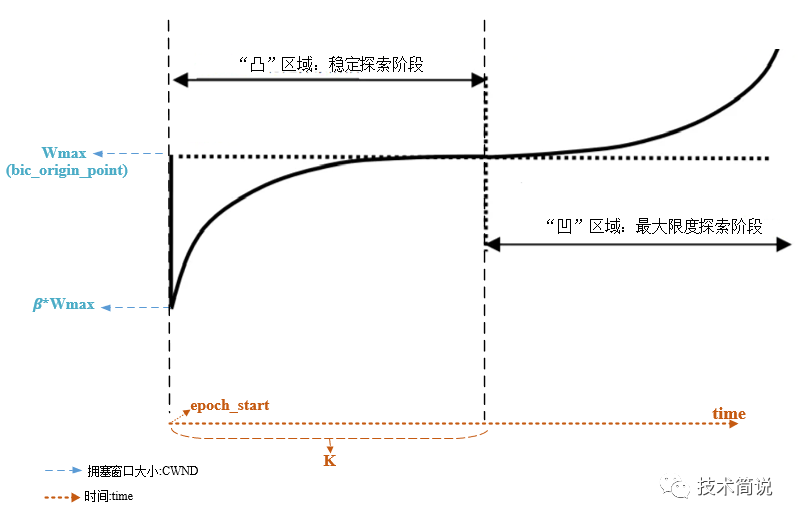
在上一篇文章[Linux内核网络-拥塞控制系列(一)]中提到了拥塞控制算法的框架,Cubic算法实现的接口如下所示:
static struct tcp_congestion_ops cubictcp __read_mostly = {
.init = bictcp_init,
.ssthresh = bictcp_recalc_ssthresh,
.cong_avoid = bictcp_cong_avoid,
.set_state = bictcp_state,
.undo_cwnd = tcp_reno_undo_cwnd,
.cwnd_event = bictcp_cwnd_event,
.pkts_acked = bictcp_acked,
.owner = THIS_MODULE,
.name = "cubic",
};先着重看一下cong_avoid接口的实现,如下所示为该接口的实现,其中参数acked代表当前新的已确认的数据包。tcp_is_cwnd_limited函数是用于判断TCP连接是否受到拥塞窗口的限制,即检查发出去,但是还、有收到ACK的包是否达到了拥塞窗口的上限,可以暂且先不关注这个函数。重点看tcp_slow_start和bictcp_update、tcp_cong_avoid_ai函数。
static void bictcp_cong_avoid(struct sock *sk, u32 ack, u32 acked)
{
struct tcp_sock *tp = tcp_sk(sk);
struct bictcp *ca = inet_csk_ca(sk);
if (!tcp_is_cwnd_limited(sk))
return;
if (tcp_in_slow_start(tp)) {
......
acked = tcp_slow_start(tp, acked);
if (!acked)
return;
}
bictcp_update(ca, tp->snd_cwnd, acked); /*计算一个ca->cnt出来 */
tcp_cong_avoid_ai(tp, ca->cnt, acked); /* 通过 计算的ca->cnt 进行拥塞控制 控制窗口cwnd的增长 */
}static inline bool tcp_in_slow_start(const struct tcp_sock *tp)
{
return tp->snd_cwnd < tp->snd_ssthresh;
}u32 tcp_slow_start(struct tcp_sock *tp, u32 acked)
{
//在慢启动阶段,cwnd最多增加到慢启动门限值
u32 cwnd = min(tp->snd_cwnd + acked, tp->snd_ssthresh);
//acked用于更新cwnd,acked已使用cwnd-tp->snd_cwnd,更新acked
acked -= cwnd - tp->snd_cwnd;
//snd_cwnd_clamp; /* Do not allow snd_cwnd to grow above this */
tp->snd_cwnd = min(cwnd, tp->snd_cwnd_clamp);
return acked;
}算法的实现过程中涉及到很多巧妙的设计,这里暂且不去关注这些细节,我们重点来看cubic三次函数的计算过程:
static inline void bictcp_update(struct bictcp *ca, u32 cwnd, u32 acked)
{
u32 delta, bic_target, max_cnt;
u64 offs, t;
ca->ack_cnt += acked; /* count the number of ACKed packets */
......
ca->last_cwnd = cwnd; /* 更新上一次的拥塞窗口值 */
ca->last_time = tcp_jiffies32; /* 最后一次更新last_cwnd的时间 */
if (ca->epoch_start == 0) { /*开始一个新的epoch */
ca->epoch_start = tcp_jiffies32; /* record beginning */
ca->ack_cnt = acked; /* start counting */
ca->tcp_cwnd = cwnd; /* syn with cubic */
if (ca->last_max_cwnd <= cwnd) {
ca->bic_K = 0;
ca->bic_origin_point = cwnd;
} else {
/* Compute new K based on
* (wmax-cwnd) * (srtt>>3 / HZ) / c * 2^(3*bictcp_HZ)
*/
ca->bic_K = cubic_root(cube_factor
* (ca->last_max_cwnd - cwnd));
ca->bic_origin_point = ca->last_max_cwnd;
}
}
t = (s32)(tcp_jiffies32 - ca->epoch_start); /*当前时间到epoch_start的时间*/
t += msecs_to_jiffies(ca->delay_min >> 3); /* + ca->delay_min 预测下一个rtt时间内的cwnd */
/* change the unit from HZ to bictcp_HZ */
t <<= BICTCP_HZ;
do_div(t, HZ);
if (t < ca->bic_K) /* t - K */
offs = ca->bic_K - t;
else
offs = t - ca->bic_K;
/* c/rtt * (t-K)^3 */
delta = (cube_rtt_scale * offs * offs * offs) >> (10+3*BICTCP_HZ);
if (t < ca->bic_K) /* below origin */
bic_target = ca->bic_origin_point - delta;
else /* above origin*/
bic_target = ca->bic_origin_point + delta;
/* cubic function - calc bictcp_cnt*/
if (bic_target > cwnd) {
ca->cnt = cwnd / (bic_target - cwnd);
} else {
ca->cnt = 100 * cwnd; /* very small increment
如果 bic_target 小于等于当前拥塞窗口大小 cwnd,说明目标拥塞窗口大小已经小于或等于当前拥塞窗口大小,网络可能出现拥塞或者拥塞窗口已经很大了,
此时不宜进一步增大拥塞窗口,因此需要减小增长速率。
ca->cnt = 100 * cwnd; 这一行计算了一个较小的增量值,用于控制拥塞窗口的增长速率,防止过度增长造成网络拥塞。
bictcp_cnt 的值,该值用于调整拥塞窗口的增长速率,值越大增长速率越小*/
}
/*
* The initial growth of cubic function may be too conservative
* when the available bandwidth is still unknown.
*/
if (ca->last_max_cwnd == 0 && ca->cnt > 20)
ca->cnt = 20; /* increase cwnd 5% per RTT */
......
/* The maximum rate of cwnd increase CUBIC allows is 1 packet per
* 2 packets ACKed, meaning cwnd grows at 1.5x per RTT.
*/
ca->cnt = max(ca->cnt, 2U);
}
/* In theory this is tp->snd_cwnd += 1 / tp->snd_cwnd (or alternative w),
* for every packet that was ACKed.
*/
void tcp_cong_avoid_ai(struct tcp_sock *tp, u32 w, u32 acked)
{
/* If credits accumulated at a higher w, apply them gently now. */
if (tp->snd_cwnd_cnt >= w) {
tp->snd_cwnd_cnt = 0;
tp->snd_cwnd++;
}
tp->snd_cwnd_cnt += acked;
if (tp->snd_cwnd_cnt >= w) {
u32 delta = tp->snd_cwnd_cnt / w;
tp->snd_cwnd_cnt -= delta * w;
tp->snd_cwnd += delta;
}
tp->snd_cwnd = min(tp->snd_cwnd, tp->snd_cwnd_clamp);
}if (ca->last_max_cwnd <= cwnd) {
ca->bic_K = 0;
ca->bic_origin_point = cwnd;
} else {
/* Compute new K based on
* (wmax-cwnd) * (srtt>>3 / HZ) / c * 2^(3*bictcp_HZ)
*/
ca->bic_K = cubic_root(cube_factor
* (ca->last_max_cwnd - cwnd));
ca->bic_origin_point = ca->last_max_cwnd;
}
}
/*
* behave like Reno until low_window is reached,
* then increase congestion window slowly
*/
static u32 bictcp_recalc_ssthresh(struct sock *sk)
{
const struct tcp_sock *tp = tcp_sk(sk);
struct bictcp *ca = inet_csk_ca(sk);
ca->epoch_start = 0; /* end of epoch */
/* Wmax and fast convergence */
if (tp->snd_cwnd < ca->last_max_cwnd && fast_convergence)
ca->last_max_cwnd = (tp->snd_cwnd * (BICTCP_BETA_SCALE + beta))
/ (2 * BICTCP_BETA_SCALE);
else
ca->last_max_cwnd = tp->snd_cwnd;
if (tp->snd_cwnd <= low_window)
return max(tp->snd_cwnd >> 1U, 2U);
else
return max((tp->snd_cwnd * beta) / BICTCP_BETA_SCALE, 2U);
} t = (s32)(tcp_jiffies32 - ca->epoch_start); /*当前时间到epoch_start的时间*/
t += msecs_to_jiffies(ca->delay_min >> 3); /* + ca->delay_min 如下图所示,是时间t在cubic三次函数中的描述,蓝色括号代表当前轮次已经经过的时间,红色的是下一个rtt的时间。
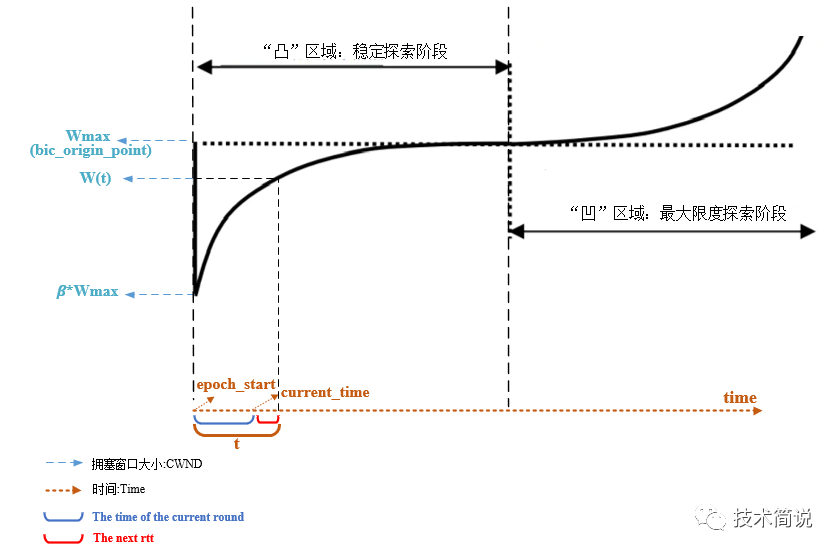
上文提到的cubic计算公式,如下所示,t、K、Wmax、C均已知。
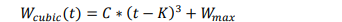
if (t < ca->bic_K) /* t - K */
offs = ca->bic_K - t;
else
offs = t - ca->bic_K;
/* c/rtt * (t-K)^3 */
delta = (cube_rtt_scale * offs * offs * offs) >> (10+3*BICTCP_HZ);
if (t < ca->bic_K) /* below origin */
bic_target = ca->bic_origin_point - delta;
else /* above origin* /
bic_target = ca->bic_origin_point + delta; /* cubic function - calc bictcp_cnt*/
if (bic_target > cwnd) {
ca->cnt = cwnd / (bic_target - cwnd);
} else {
ca->cnt = 100 * cwnd; /* very small increment*/
}/* In theory this is tp->snd_cwnd += 1 / tp->snd_cwnd (or alternative w),
* for every packet that was ACKed.
*/
void tcp_cong_avoid_ai(struct tcp_sock *tp, u32 w, u32 acked)
{
/*
tp->snd_cwnd_cnt 表示在当前的拥塞窗口中已经发送(经过对方ack包确认)的数据段个数.
ca->cnt = w :它是cubic拥塞算法的核心,主要用来控制拥塞避免状态的时候,什么时候才能增大拥塞窗口
具体实现是通过比较cnt和snd_cwnd_cnt,来决定是否增大拥塞窗口
*/
/* If credits accumulated at a higher w, apply them gently now. */
/*当被确认的包的数量大于w时,将snd_cwnd_cnt清0,继续加大拥塞窗口值,继续probe Wmax*/
if (tp->snd_cwnd_cnt >= w) {
tp->snd_cwnd_cnt = 0;
tp->snd_cwnd++;
}
tp->snd_cwnd_cnt += acked; //累计被确认的包
if (tp->snd_cwnd_cnt >= w) {
/*按比例增加拥塞窗口,并减少snd_cwnd_cnt*/
u32 delta = tp->snd_cwnd_cnt / w;
tp->snd_cwnd_cnt -= delta * w;
tp->snd_cwnd += delta;
}
tp->snd_cwnd = min(tp->snd_cwnd, tp->snd_cwnd_clamp);
}Algorithm 1: Linux CUBIC algorithm (v2.2)

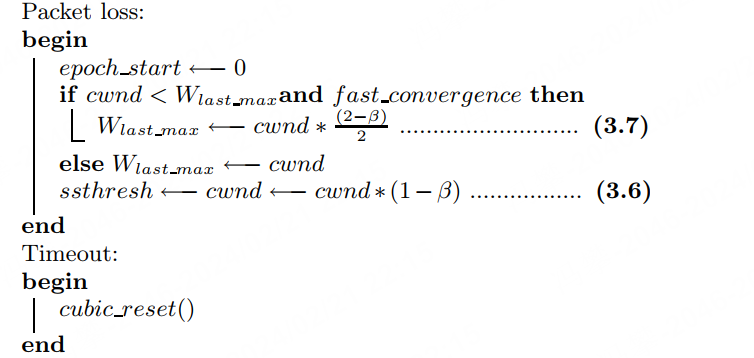




 浙公网安备 33010602011771号
浙公网安备 33010602011771号