ip ss 网络相关命令
从系统cache中查看 tcp_metrics item
ip tcp_metrics show
cp_metrics会记录下之前已关闭TCP连接的状态,包括发送端CWND和ssthresh,如果之前网络有一段时间比较差或者丢包比较严重,就会导致TCP的ssthresh降低到一个很低的值,这个值在连接结束后会被tcp_metrics cache 住,在新连接建立时,即使网络状况已经恢复,依然会继承 tcp_metrics 中cache 的一个很低的ssthresh 值,对于rt很高的网络环境,新连接经历短暂的“慢启动”后(ssthresh太小),随即进入缓慢的拥塞控制阶段(rt太高,CWND增长太慢),导致连接速度很难在短时间内上去。而后面的连接,需要很特殊的场景之下(比如,传输一个很大的文件)才能将ssthresh 再次推到一个比较高的值更新掉之前的缓存值,因此很有很能在接下来的很长一段时间,连接的速度都会处于一个很低的水平。
确认运行中每个连接 CWND/ssthresh(slow start threshold)
ss -itn dst 11.163.187.32 |grep -v "Address:Port"
ss -tin sport = :22
接收窗口和SO_RCVBUF的关系
ss 查看socket buffer大小
初始接收窗口一般是 mss乘以初始cwnd(为了和慢启动逻辑兼容,不想一下子冲击到网络),如果没有设置SO_RCVBUF,那么会根据 net.ipv4.tcp_rmem 动态变化,如果设置了SO_RCVBUF,那么接收窗口要向下面描述的值靠拢。
初始cwnd可以大致通过查看到:
ss -itmpn dst "10.81.212.8"
State Recv-Q Send-Q Local Address:Port Peer Address:Port
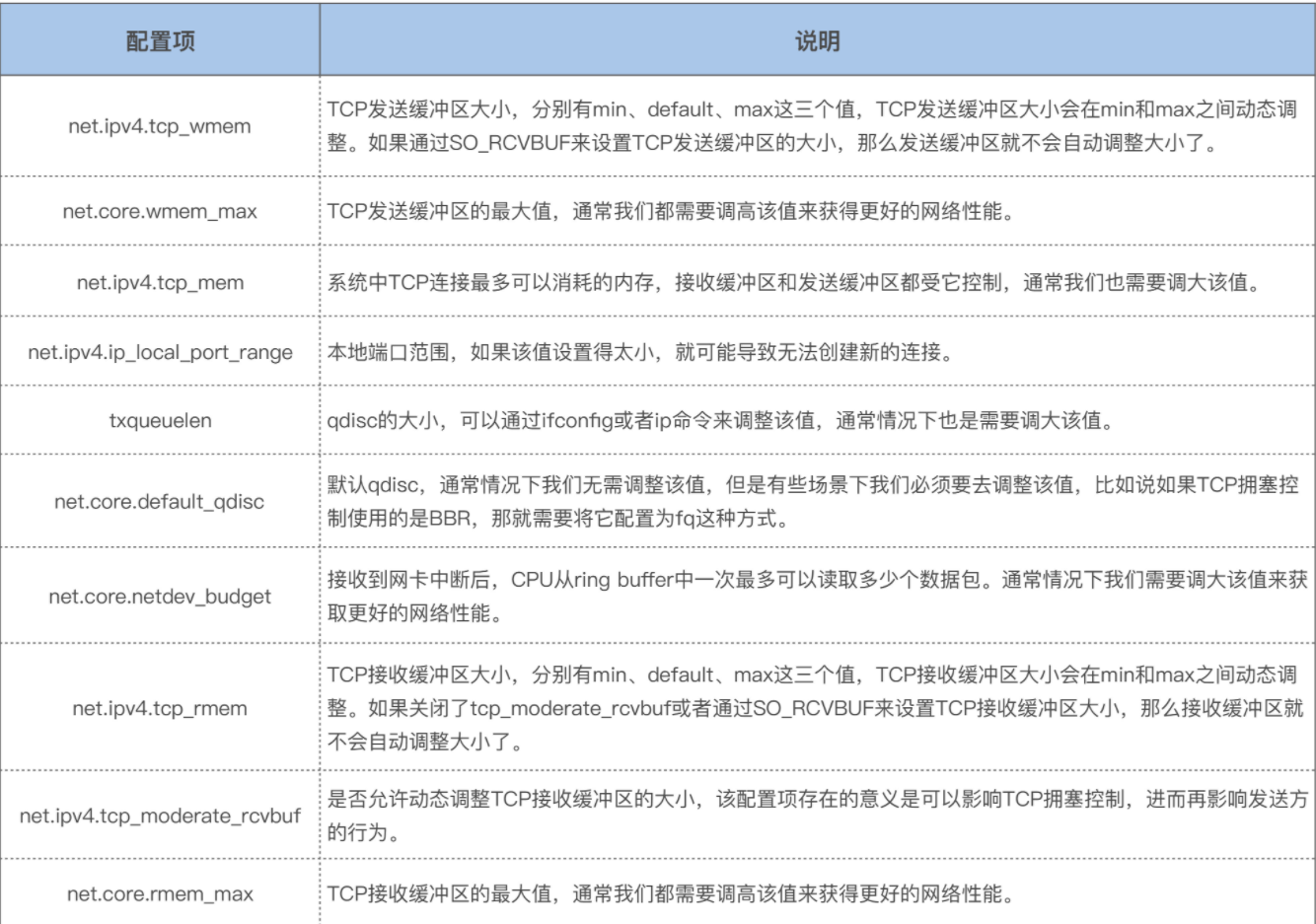
如下是tcp_sendmsg流程,sk_stream_wait_memory就是tcp_wmem不够的时候触发等待
如果sendbuffer不够就会卡在上图中的第一步 sk_stream_wait_memory, 通过systemtap脚本可以验证:
#!/usr/bin/stap
# Simple probe to detect when a process is waiting for more socket send
# buffer memory. Usually means the process is doing writes larger than the
# socket send buffer size or there is a slow receiver at the other side.
# Increasing the socket's send buffer size might help decrease application
# latencies, but it might also make it worse, so buyer beware.
probe kernel.function("sk_stream_wait_memory")
{
printf("%u: %s(%d) blocked on full send buffern",
gettimeofday_us(), execname(), pid())
}
probe kernel.function("sk_stream_wait_memory").return
{
printf("%u: %s(%d) recovered from full send buffern",
gettimeofday_us(), execname(), pid())
}
netstat -tn 看到的 Recv-Q 跟全连接半连接没有关系,这里特意拿出来说一下是因为容易跟 ss -lnt 的 Recv-Q 搞混淆。
Recv-Q 和 Send-Q 的说明:
- Recv-Q就是指收到的数据还在缓存中,还没被进程读取,这个值就是还没被进程读取的 bytes;而 Send 则是发送队列中没有被远程主机确认的 bytes 数
Recv-Q
Established: The count of bytes not copied by the user program connected to this socket.
Listening: Since Kernel 2.6.18 this column contains the current syn backlog.
Send-Q
Established: The count of bytes not acknowledged by the remote host.
Listening: Since Kernel 2.6.18 this column contains the maximum size of the syn backlog.
TCP 缓冲调参
首先计算管道容量:已知专线带宽为 1Gb,通过 ping 查看专线 RTT 约为 210ms,据此 计算专线 BDP 约为 25MB。
做过 TCP 开发的同学应该都熟悉 SO_RECVBUF 和 SO_SENDBUF 这两个 socekt 选项,我们可以通过这两个参数来设置接收与发送缓冲区的大小。如果我们在建立连接 TCP 时指定了这两个参数,那么操作系统就会使用一个固定的缓冲区大小,而不再会根据网络进行动态调整,因此这两个选项要慎用。
然而当指定参数过后,会发现实际的 TCP 缓冲区大小与参数有所出入。这是什么原因造成的呢?首先来看几个重要的内核参数:
[lhop@localhost ~]$ sysctl -a 2>&1 | egrep 'core.wmem_max|core.rmem_max|ipv4.tcp_wmem|ipv4.tcp_rmem|tcp_adv_win_scale|tcp_moderate_rcvbuf'
net.core.wmem_max = 124928
net.core.rmem_max = 124928
net.ipv4.tcp_wmem = 4096 16384 4194304
net.ipv4.tcp_rmem = 4096 87380 4194304
net.ipv4.tcp_adv_win_scale = 2
net.ipv4.tcp_moderate_rcvbuf = 1
-
net.ipv4.tcp_wmem 与 net.ipv4.tcp_rmem 是单个 tcp socket 缓冲区的最小值min、默认值default、最大值max,单位为字节。
-
net.core.wmem_max 与 net.core.rmem_max 是单个 socket 所能使用的缓冲区大小上限,单位为字节。该参数的优先级高于 tcp_wmem 与 tcp_rmem 的最大值,调整参数时需要注意两者的对应关系。
net.ipv4.tcp_moderate_rcvbuf 是否允许操作系统动态调整 tcp 缓冲。开启后,系统会根据当前可用资源对接收缓冲进行动态调整,此时接收缓冲的大小会在 tcp_rmem 最大与最小值之间浮动。当 tcp socket 连接较多时,可以系统会酌情减少每个连接的缓存内存,避免资源耗尽。
net.ipv4.tcp_adv_win_scale 是单个 tcp socket 接收缓冲预留给应用的比例。tcp 的接收缓冲可以分为两部分,一部分是用作接收窗口保存未确认报文,另一部分则是缓存未被应用程序读取的已确认报文,因此需要预留 1/2tcp_adv_win_scale 内存空间给未读报文。这也是 tcp_rmem 的初始默认值比 tcp_wmem 大的原因。
根据 sysctl 给出的结果,我们需要调整有:
net.core.wmem_max = BDP = 26214400
net.core.rmem_max = BDP/(1-1/2tcp_adv_win_scale) = 34952000
Bufferbloat 现象
随着内存越来越便宜,TCP 链路上的网络设备的 Buffer 倾向于配置的特别大。但这一做法对于基于丢包反馈的 TCP 拥塞算法相当不友好:
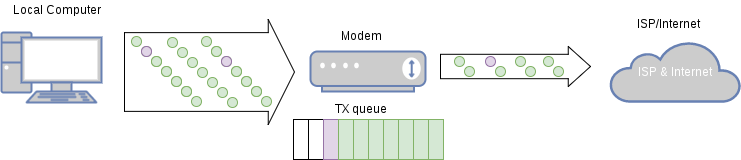
发送方无法及时感知到拥塞:当数据开始在队列排队时,链路已经出现拥塞,但因为 Buffer 很大,数据包不会被丢弃,发送端根本无法感知到拥塞的发生。
无效的数据包占用网络资源:等真的出现丢包时候,重传的包放在链路上还得等之前积压在 Buffer 的数据包都送达接收端后才能被处理,对网络网络资源造成了浪费。
接收方队头阻塞并丢弃数据:接收端在等待重传的过程中,如果 Buffer 不足够大,大量数据送达接收端后都会被丢弃,无形中增加了重传率,极大增加传输延迟。
Bufferbloat 造成的高重传率,无形中增加了网络传输的延迟,并且还会导致网络传输不稳定,有时候延迟很小,有的时候延迟又很大。
基于传输时延
下图是 TCP 传输链路上某个缓存队列,根据网络状况变化,队列可能处于以下 3 种状态之一:
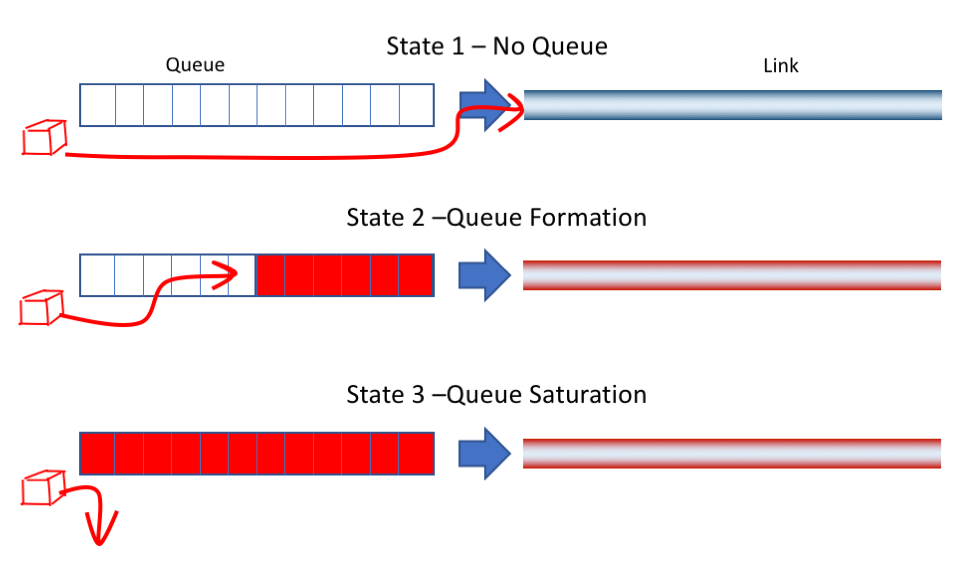
State 1: 网络空闲,没有排队的数据。网络延迟最低
State 2: 网络占满,数据开始排队,网络延迟开始增大
State 3: 队列溢出,网络出现丢包
cubic 的拥塞避免策略是让拥塞窗口尽可能保持在上一个 Wmax 附近,即 State 2 与 State 3 之间的状态。相当于尽可能把链路资源(线路带宽+中继Buffer)占满,也因此造成了较高的网络延迟。
而理想状态是维持在 State 1 和 State 2 之间,即没有出现排队导致延迟升高,又能完全占满链路带宽发送数据,高效且低延迟。为了实现这一点,需要使用 基于传输时延 的拥塞避免算法:
监控每个数据包的 RTT,先尽力增大 CWND 提高发送率:
速率提高后 RTT 不变(无需排队),则此时链路处于 State 1,可以继续提高发送速率
速率提高后 RTT 升高(开始排队),说明此时链路从 State 1 切换到了 State 2,需要降低发送效率,使其恢复到 State 1
- 一般来说绝对不要在程序中手工设置SO_SNDBUF和SO_RCVBUF,内核自动调整比你做的要好;
- SO_SNDBUF一般会比发送滑动窗口要大,因为发送出去并且ack了的才能从SO_SNDBUF中释放;
- 代码中设置的SO_SNDBUF和SO_RCVBUF在内核中会翻倍分配;
- TCP接收窗口跟SO_RCVBUF关系很复杂;
- SO_RCVBUF太小并且rtt很大的时候会严重影响性能;
- 接收窗口比发送窗口复杂多了;
- 发送窗口/SO_SNDBUF–发送仓库,带宽/拥塞窗口–马路通畅程度,接收窗口/SO_RCVBUF–接收仓库;
- 发送仓库、马路宽度、长度(rt)、接收仓库一起决定了传输速度–类比一下快递过程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号