访问文件
VFS层调用流程:
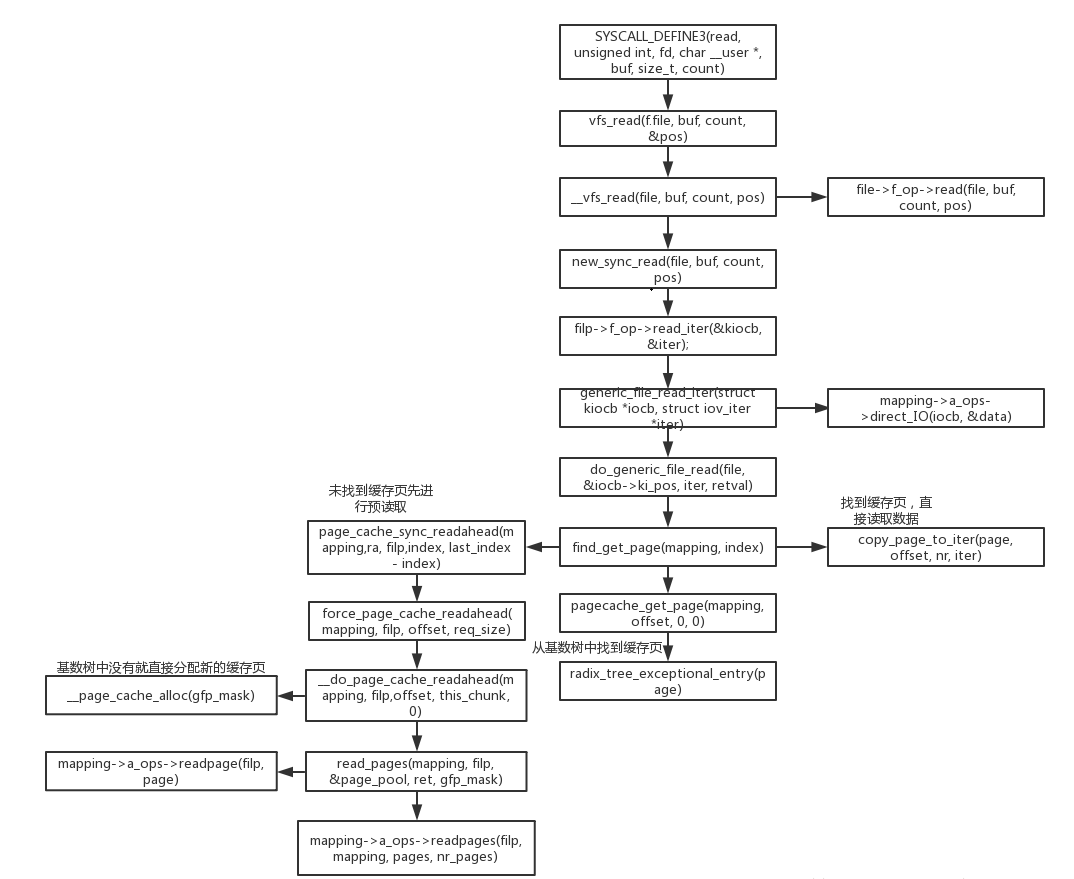
系统调用sys_read会调用到vfs层的__vfs_read接口如下,在vfs层接口会调用大具体的文件系统的
ssize_t __vfs_read(struct file *file, char __user *buf, size_t count, loff_t *pos) { if (file->f_op->read)//新内核都不使用了 return file->f_op->read(file, buf, count, pos); else if (file->f_op->read_iter) return new_sync_read(file, buf, count, pos); else return -EINVAL; }
以 sock 的file为例
/* * Socket files have a set of 'special' operations as well as the generic file ones. These don't appear * in the operation structures but are done directly via the socketcall() multiplexor. */ static const struct file_operations socket_file_ops = { .owner = THIS_MODULE, .llseek = no_llseek, .read_iter = sock_read_iter, .write_iter = sock_write_iter, .poll = sock_poll, .unlocked_ioctl = sock_ioctl, #ifdef CONFIG_COMPAT .compat_ioctl = compat_sock_ioctl, #endif .mmap = sock_mmap, .release = sock_close, .fasync = sock_fasync, .sendpage = sock_sendpage, .splice_write = generic_splice_sendpage, .splice_read = sock_splice_read, };
在new_sync_read中会调用到具体的文件系统的读写接口generic_file_read_iter:
static ssize_t new_sync_read(struct file *filp, char __user *buf, size_t len, loff_t *ppos) { struct iovec iov = { .iov_base = buf, .iov_len = len }; struct kiocb kiocb; struct iov_iter iter; ssize_t ret; init_sync_kiocb(&kiocb, filp); kiocb.ki_pos = *ppos; iov_iter_init(&iter, READ, &iov, 1, len); ret = filp->f_op->read_iter(&kiocb, &iter); BUG_ON(ret == -EIOCBQUEUED); *ppos = kiocb.ki_pos; return ret; }
filp->f_op->read_iter会调用到generic_file_read_iter,generic_file_read_iter这个是所有文件系统通用接口;对于ext4文件系统来说;
//kernel-4.9/fs/ext4/file.c const struct file_operations ext4_file_operations = { .llseek = ext4_llseek, .read_iter = generic_file_read_iter, .write_iter = ext4_file_write_iter, //...... }
generic_file_read_iter是读文件的核心函数:
在generic_file_read_iter针对数据的读取方式是IOCB_DIRECT还是其他类型进行区别操作,对于没有添加IOCB_DIRECT标志的read会调用到do_generic_file_read:
/** * generic_file_read_iter - generic filesystem read routine * @iocb: kernel I/O control block * @iter: destination for the data read * * This is the "read_iter()" routine for all filesystems * that can use the page cache directly. */ ssize_t generic_file_read_iter(struct kiocb *iocb, struct iov_iter *iter) { struct file *file = iocb->ki_filp; ssize_t retval = 0; loff_t *ppos = &iocb->ki_pos; loff_t pos = *ppos; if (iocb->ki_flags & IOCB_DIRECT) { struct address_space *mapping = file->f_mapping; struct inode *inode = mapping->host; size_t count = iov_iter_count(iter); loff_t size; if (!count) goto out; /* skip atime */ size = i_size_read(inode); retval = filemap_write_and_wait_range(mapping, pos, pos + count - 1); if (!retval) { struct iov_iter data = *iter; retval = mapping->a_ops->direct_IO(iocb, &data, pos); } if (retval > 0) { *ppos = pos + retval; iov_iter_advance(iter, retval); } /* * Btrfs can have a short DIO read if we encounter * compressed extents, so if there was an error, or if * we've already read everything we wanted to, or if * there was a short read because we hit EOF, go ahead * and return. Otherwise fallthrough to buffered io for * the rest of the read. Buffered reads will not work for * DAX files, so don't bother trying. */ if (retval < 0 || !iov_iter_count(iter) || *ppos >= size || IS_DAX(inode)) { file_accessed(file);SIGRTMIN goto out; } } retval = do_generic_file_read(file, ppos, iter, retval); out: return retval; }
generic_file_read_iter是一个通用读取函数。这个函数是do_generic_file_read的一个包装。后者会从页缓存中获取数据,如果页缓存中没有,就去块设备中取。
从块设备中取数据是异步的,但在没有获取到数据前,task会进入睡眠,出让CPU。数据读取完毕后,会唤醒task,将数据拷贝到用户态的buffer;
do_generic_file_read在一个大的循环中,将线性的文件读转换为page读。
- 1).将文件的读写位置和读取长度转化为page tree的index。
- 2).根据index,使用find_get_page找到对应的page。
- 2.1).如果page不存在,就进行同步预读。同步预读成功后,再次使用find_get_page得到page。
- 2.2).如果预读关闭或者block拥塞,导致同步预读失败,那么会转向使用mapping->a_ops->readpage进行单页读取。
- 3).如果page设置了PG_readahead标记,则启动一个异步预读。
- 4).如果page是在同步预读中分配的,那么会锁住page,并阻塞在和page关联的waitqueue上(page_wait_table的一个bucket)。
- 异步的块层IO结束后,IO完成处理函数会解锁该page,并唤醒之前在waitqueue上睡眠的task。
- 但这里可能会唤醒多个task(thundering herd)。因为多个page(PageLocked pages and PageWriteback pages)可以在一个waitqueue上等待。
- 5).如果page是之前已经读取过的,那么判断page是否是最新的。如果不是,则使用mapping->a_ops->readpage再次读取。
- 6).拷贝page数据到用户空间。如果拷贝了足够的字节数,或者发生错误,或者收到kill signal,这里就不再循环,而是返回已经拷贝到用户空间的字节数。
- 7).循环读取page,回到第1)步继续执行。
/** * do_generic_file_read - generic file read routine * @filp: the file to read * @ppos: current file position * @iter: data destination * @written: already copied * * This is a generic file read routine, and uses the * mapping->a_ops->readpage() function for the actual low-level stuff. * * This is really ugly. But the goto's actually try to clarify some * of the logic when it comes to error handling etc. */ static ssize_t do_generic_file_read(struct file *filp, loff_t *ppos, struct iov_iter *iter, ssize_t written) { struct address_space *mapping = filp->f_mapping; struct inode *inode = mapping->host; struct file_ra_state *ra = &filp->f_ra; pgoff_t index; pgoff_t last_index; pgoff_t prev_index; unsigned long offset; /* offset into pagecache page */ unsigned int prev_offset; int error = 0; index = *ppos >> PAGE_CACHE_SHIFT; /*计算本次读取的是文件中的第几个page, 读文件的话是通过 文件pos为启动地址开始读取*/ prev_index = ra->prev_pos >> PAGE_CACHE_SHIFT; /*上次读取的是第几个page以及 对page的相对偏移地址*/ prev_offset = ra->prev_pos & (PAGE_CACHE_SIZE-1); /*本次要读取的最后一个page*/ last_index = (*ppos + iter->count + PAGE_CACHE_SIZE-1) >> PAGE_CACHE_SHIFT; offset = *ppos & ~PAGE_CACHE_MASK;/*本次开始读的时候,*/ for (;;) { struct page *page; pgoff_t end_index; loff_t isize; unsigned long nr, ret; cond_resched(); find_page: if (fatal_signal_pending(current)) {//有收到sigkill信号退出 error = -EINTR; goto out; } /* 从cache中找到index 对应的 page */ page = find_get_page(mapping, index); if (!page) {//也就是当前要读取内容pos 不在cache /* 如果page不在当前cache中,进行预读操作*/ page_cache_sync_readahead(mapping, ra, filp, index, last_index - index);// 进行同步预读 page = find_get_page(mapping, index);// 预读以后再获取一次 if (unlikely(page == NULL)) goto no_cached_page; } if (PageReadahead(page)) {// 如果读取出来的page包含Readahead的特殊标志 page_cache_async_readahead(mapping, ra, filp, page, index, last_index - index);// 进行一次异步预读 } //同步预读以及异步预读都会调用同一个函数ondemand_readahead,只是输入参数不一样;第四个参数不一样,一个是False一个是True if (!PageUptodate(page)) { if (inode->i_blkbits == PAGE_CACHE_SHIFT || !mapping->a_ops->is_partially_uptodate) goto page_not_up_to_date; if (!trylock_page(page)) goto page_not_up_to_date; /* Did it get truncated before we got the lock? */ if (!page->mapping) goto page_not_up_to_date_locked; if (!mapping->a_ops->is_partially_uptodate(page, offset, iter->count)) goto page_not_up_to_date_locked; unlock_page(page); } //page读取OK,copy 数据返回到用户空间 page_ok: /* * i_size must be checked after we know the page is Uptodate. * * Checking i_size after the check allows us to calculate * the correct value for "nr", which means the zero-filled * part of the page is not copied back to userspace (unless * another truncate extends the file - this is desired though). */ isize = i_size_read(inode); end_index = (isize - 1) >> PAGE_CACHE_SHIFT; if (unlikely(!isize || index > end_index)) { page_cache_release(page); goto out; } /* nr is the maximum number of bytes to copy from this page */ nr = PAGE_CACHE_SIZE; if (index == end_index) { nr = ((isize - 1) & ~PAGE_CACHE_MASK) + 1; if (nr <= offset) { page_cache_release(page); goto out; } } nr = nr - offset; /* If users can be writing to this page using arbitrary * virtual addresses, take care about potential aliasing * before reading the page on the kernel side. */ if (mapping_writably_mapped(mapping)) flush_dcache_page(page); /* * When a sequential read accesses a page several times, * only mark it as accessed the first time. */ if (prev_index != index || offset != prev_offset) mark_page_accessed(page); prev_index = index; /* * Ok, we have the page, and it's up-to-date, so * now we can copy it to user space... */ ret = copy_page_to_iter(page, offset, nr, iter); offset += ret; index += offset >> PAGE_CACHE_SHIFT; offset &= ~PAGE_CACHE_MASK; prev_offset = offset; page_cache_release(page); written += ret; if (!iov_iter_count(iter)) goto out; if (ret < nr) { error = -EFAULT; goto out; } continue; page_not_up_to_date: /* Get exclusive access to the page ... */ error = lock_page_killable(page); if (unlikely(error)) goto readpage_error; page_not_up_to_date_locked: /* Did it get truncated before we got the lock? */ if (!page->mapping) { unlock_page(page); page_cache_release(page); continue; } /* Did somebody else fill it already? */ if (PageUptodate(page)) { unlock_page(page); goto page_ok; } //读取page readpage: /* * A previous I/O error may have been due to temporary * failures, eg. multipath errors. * PG_error will be set again if readpage fails. */ ClearPageError(page); /* Start the actual read. The read will unlock the page. read_pages会调用blk_start_plug和blk_finish_plug进行bio的请求,start plug不会立马去调用到 bio驱动的queue中,而是加入到对应的plug list中,等到finish_plug是会通过submit_io去刷新plug队列上 的请求到驱动的queue进行处理 */ error = mapping->a_ops->readpage(filp, page); if (unlikely(error)) { if (error == AOP_TRUNCATED_PAGE) { page_cache_release(page); error = 0; goto find_page; } goto readpage_error; } if (!PageUptodate(page)) { error = lock_page_killable(page); if (unlikely(error)) goto readpage_error; if (!PageUptodate(page)) { if (page->mapping == NULL) { /* * invalidate_mapping_pages got it */ unlock_page(page); page_cache_release(page); goto find_page; } unlock_page(page); shrink_readahead_size_eio(filp, ra); error = -EIO; goto readpage_error; } unlock_page(page); } goto page_ok; readpage_error: /* UHHUH! A synchronous read error occurred. Report it */ page_cache_release(page); goto out; no_cached_page: /* * Ok, it wasn't cached, so we need to create a new * page.. */ page = page_cache_alloc_cold(mapping); if (!page) { error = -ENOMEM; goto out; } error = add_to_page_cache_lru(page, mapping, index, mapping_gfp_constraint(mapping, GFP_KERNEL)); if (error) { page_cache_release(page); if (error == -EEXIST) { error = 0; goto find_page; } goto out; } goto readpage; } out: ra->prev_pos = prev_index; ra->prev_pos <<= PAGE_CACHE_SHIFT; ra->prev_pos |= prev_offset; *ppos = ((loff_t)index << PAGE_CACHE_SHIFT) + offset; file_accessed(filp); return written ? written : error;aio_read }
3.文件预读
文件预读机制,是假设文件会被顺序读取。
如果程序打开文件读入第一页,那么它接下来会有很大概率会继续读取后面的页。而且文件系统也会为相邻的数据尽量分配相邻的块儿。
所以顺序读能从中受益。大量的顺序读,通过预读,只产生少量的和底层硬件的交互,从而降低延迟。
但对于随机读,事情就变得不确定了。这时候预读可能就没什么帮助,甚至会引发性能下降。因为都进来的数据可能根本就用不到,还占内存。
内核在这里提供了一个参数,/sys/block/<devname>/queue/read_ahead_kb,用来控制设备预读的最大KB数。在顺序读场景中可以调大,在随机读的场景调小一些,然后根据反馈来做进一步的优化。
用户态的文件读和mmap映射文件导致的缺页处理中,都要调用预读函数。预读函数最终会汇总到ondemand_readahead上。
文件进行预读时,会形成一个预读窗口{start, size, asyn_size}。
/* * Track a single file's readahead state */ struct file_ra_state { pgoff_t start; /* where readahead started */ unsigned int size; /* # of readahead pages */ unsigned int async_size; /* do asynchronous readahead when there are only # of pages ahead */ unsigned int ra_pages; /* Maximum readahead window */ unsigned int mmap_miss; /* Cache miss stat for mmap accesses */ loff_t prev_pos; /* Cache last read() position */ };
|<----- async_size ---------| |------------------- size -------------------->| |==================#===========================| ^start ^page marked with PG_readahead
start指定窗口中开始预读的位置。size指定预读页数。async_size指定一个阈值,预读窗口剩余这么多页时,就开始异步预读。
ra_pages是窗口可能的最大值,和/sys/block/<devname>/queue/read_ahead_kb的值对应。如果后者是4096,那么ra_pages就是1024。
如果程序从0开始顺序读文件,每次4k。那么在ondemand_readahead中,首先会调用get_init_ra_size初始化一个小的窗口,读入一定量的数据。
后续的顺序4k读会慢慢的扩大窗口,读入更多的数据,直到窗口达到最大值。
如果程序是随机读,导致窗口失效,那么就要重新初始化。如果遇到预读标记,但和之前的预读窗口不符,那么也要重新设置,以适应并发的随机读取。
举个例子,程序从0开始顺序读文件,一共读5次,每次读4k:
1).第1次读4k,page不在cache中,进行同步预读,预读窗口初始化为 {0, 4, 3},读4页(0-3),第1页设置readahead标志
2).第2次读4k,page在cache中,命中readahead,进行异步预读,预读窗口扩大为 {4, 8, 8},读8页(4-11),第4页设置readahead标志
3).第3/4次读4k,page在cache中,不命中readahead
4).第5次读4k,page在cache中, 命中readahead,进行异步预读,预读窗口扩大为 {12, 16, 16},读16页(12-27),第12页设置readahead标志
以上转自:https://zhuanlan.zhihu.com/p/268375848
同步预读以及异步预读都会调用同一个函数ondemand_readahead
/* * A minimal readahead algorithm for trivial sequential/random reads. */ static unsigned long ondemand_readahead(struct address_space *mapping, struct file_ra_state *ra, struct file *filp, bool hit_readahead_marker, pgoff_t offset, unsigned long req_size) { struct backing_dev_info *bdi = inode_to_bdi(mapping->host); unsigned long max_pages = ra->ra_pages; pgoff_t prev_offset; /* * If the request exceeds the readahead window, allow the read to * be up to the optimal hardware IO size */ /* * 根据条件,计算本次预读最大预读取多少个页,一般情况下是max_pages=32个页 */ if (req_size > max_pages && bdi->io_pages > max_pages) max_pages = min(req_size, bdi->io_pages); /* * start of file *//* * offset即page index,如果page index=0,表示这是文件第一个页,跳转到initial_readahead进行处理 */ if (!offset) goto initial_readahead; /* * It's the expected callback offset, assume sequential access. * Ramp up sizes, and push forward the readahead window. /* * 默认情况下是 ra->start=0, ra->size=0, ra->async_size=0 ra->prev_pos=0 * 但是经过第一次预读后,上面三个值会出现变化 */ if ((offset == (ra->start + ra->size - ra->async_size) || offset == (ra->start + ra->size))) { ra->start += ra->size; ra->size = get_next_ra_size(ra, max_pages); ra->async_size = ra->size; goto readit; } /* * Hit a marked page without valid readahead state. * E.g. interleaved reads. * Query the pagecache for async_size, which normally equals to * readahead size. Ramp it up and use it as the new readahead size. 异步预读的时候会进入这个判断,更新ra的值,然后预读特定的范围的页 * 异步预读的调用表示Readahead出来的页连续命中 */ if (hit_readahead_marker) { pgoff_t start; rcu_read_lock(); // 这个函数用于找到offset + 1开始到offset + 1 + max_pages这个范围内,第一个不在page cache的页的index start = page_cache_next_hole(mapping, offset + 1, max_pages); rcu_read_unlock(); if (!start || start - offset > max_pages) return 0; ra->start = start; ra->size = start - offset; /* old async_size */ ra->size += req_size; /* * 由于连续命中,get_next_ra_size会加倍上次的预读页数 * 第一次预读了4个页 * 第二次命中以后,预读8个页 * 第三次命中以后,预读16个页 * 第四次命中以后,预读32个页,达到默认情况下最大的读取页数 * 第五次、第六次、第N次命中都是预读32个页 * */ ra->size = get_next_ra_size(ra, max_pages); ra->async_size = ra->size; goto readit; } /* * oversize read */ if (req_size > max_pages) goto initial_readahead; /* * sequential cache miss * trivial case: (offset - prev_offset) == 1 * unaligned reads: (offset - prev_offset) == 0 */ prev_offset = (unsigned long long)ra->prev_pos >> PAGE_CACHE_SHIFT; if (offset - prev_offset <= 1UL) goto initial_readahead; /* * Query the page cache and look for the traces(cached history pages) * that a sequential stream would leave behind. */ if (try_context_readahead(mapping, ra, offset, req_size, max_pages)) goto readit; /* * standalone, small random read * Read as is, and do not pollute the readahead state. 要读取的page索引和page数量,去查找相应的page; 如果没有则alloc一个新的page。然后调用read_pages继续处理--执行具体的从磁盘读取的流程 */ return __do_page_cache_readahead(mapping, filp, offset, req_size, 0); initial_readahead: ra->start = offset; /* get_init_ra_size初始化第一次预读的页的个数,一般情况下第一次预读是4个页 */ ra->size = get_init_ra_size(req_size, max_pages); ra->async_size = ra->size > req_size ? ra->size - req_size : ra->size; readit: /* * Will this read hit the readahead marker made by itself? * If so, trigger the readahead marker hit now, and merge * the resulted next readahead window into the current one. */ if (offset == ra->start && ra->size == ra->async_size) { ra->async_size = get_next_ra_size(ra, max_pages); ra->size += ra->async_size; } /* * 经过一点处理以后,会调用__do_page_cache_readahead函数,执行具体的从磁盘读取的流程 * 区别在于它是基于ra->start ra->async_size等信息进行读取*/ return ra_submit(ra, mapping, filp);
/* * Submit IO for the read-ahead request in file_ra_state. */ static inline unsigned long ra_submit(struct file_ra_state *ra, struct address_space *mapping, struct file *filp) { return __do_page_cache_readahead(mapping, filp, ra->start, ra->size, ra->async_size); }
}
当第一个页(page index=0)传入函数时,跳到initial_readahead部分,初始化ra->start、ra->size以及ra->async_size等信息,然后调用ra_submit进行读取。
当第一个页以外传入函数时,需要根据hit_readahead_marker判断同步预读还是异步预读,同步则根据offset和req_size进行预读,如果是异步则通过ra->start以及ra->async_size进行预读。
ondemand_readahead函数的核心是__do_page_cache_readahead函数,它会根据传入的参数,从磁盘读取特定范围的数据:
/* * __do_page_cache_readahead() actually reads a chunk of disk. It allocates all * the pages first, then submits them all for I/O. This avoids the very bad * behaviour which would occur if page allocations are causing VM writeback. * We really don't want to intermingle reads and writes like that. * * Returns the number of pages requested, or the maximum amount of I/O allowed. */ int __do_page_cache_readahead(struct address_space *mapping, struct file *filp, pgoff_t offset, unsigned long nr_to_read, unsigned long lookahead_size) { struct inode *inode = mapping->host; struct page *page; unsigned long end_index; /* The last page we want to read */ LIST_HEAD(page_pool);// 将要读取的页存入到这个list当中 int page_idx; int ret = 0; loff_t isize = i_size_read(inode);// 获取文件的大小 if (isize == 0) goto out; end_index = ((isize - 1) >> PAGE_CACHE_SHIFT);// 根据文件大小计算得到最后一个页的index /* * Preallocate as many pages as we will need. */ for (page_idx = 0; page_idx < nr_to_read; page_idx++) { pgoff_t page_offset = offset + page_idx;// 计算得到page index if (page_offset > end_index)// 超过了文件的尺寸就break,停止读取 break; rcu_read_lock(); // 查看是否在page cache,如果已经在了cache中,再判断是否为脏,要不要进行读取 page = radix_tree_lookup(&mapping->page_tree, page_offset); rcu_read_unlock(); if (page && !radix_tree_exceptional_entry(page)) continue; // 如果不存在,则创建一个page cache结构 page = page_cache_alloc_readahead(mapping); if (!page) break; page->index = page_offset; // 设定page cache的index list_add(&page->lru, &page_pool);// 加入到list当中 if (page_idx == nr_to_read - lookahead_size)// !!! 注意计算值,给这一个页加上Readahead的标志 SetPageReadahead(page); ret++; } /* * Now start the IO. We ignore I/O errors - if the page is not * uptodate then the caller will launch readpage again, and * will then handle the error. *//* * 如果nr_pages大于0,则表示有页要进行读取 * 执行read_pages从磁盘进行读取 */ if (ret) read_pages(mapping, filp, &page_pool, ret); BUG_ON(!list_empty(&page_pool)); out: return ret; }
4.通用块层的处理
ondemand_readahead会调用pagecache层的关键函数mapping->a_ops->readpages(在ext4中是ext4_readpages,进一步会调用到ext4_mpage_readpages)。
- read_pages相关调用流程
ndemand_readahead ra_submit __do_page_cache_readahead read_pages blk_start_plug(&plug) mapping->a_ops->readpages submit_bio(bio) blk_finish_plug(&plug)
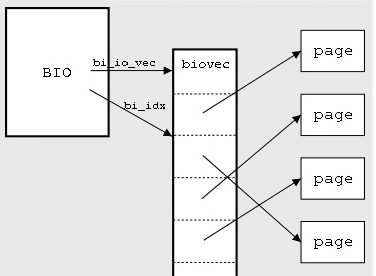
在ext4_mpage_readpages中将page读转化为文件的block读。函数通过BIO来标识IO请求的多个段(通过bi_io_vec数组)。
每个biovec的数组项包含用于IO的page(bv_page),页内偏移(bv_offset)和IO大小(bv_len)。这些pages可以是不连续的,这简化了DMA的scatter/gather操作。
submit_bio是向块层提交bio的关键,最终该函数会使用make_request_fn将bio加入块设备的请求队列上。同时,IO调度层的工作也会在这里完成,通过指定的调度算法对IO进行排序和合并。
在IO完成后,块设备通过中断通知cpu。在中断处理函数中,会进一步触发BLOCK_SOFTIRQ。在软中断处理例程中,回调最终会触发bio->bi_end_io(对ext4来说是mpage_end_io),解锁之前在锁定的页面。
这样,之前在该page的waitqueue上阻塞的task就可以继续执行了,从而是read函数返回,整个调用流程也就全部结束了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号