6.排序总结和优化
排序算法总结
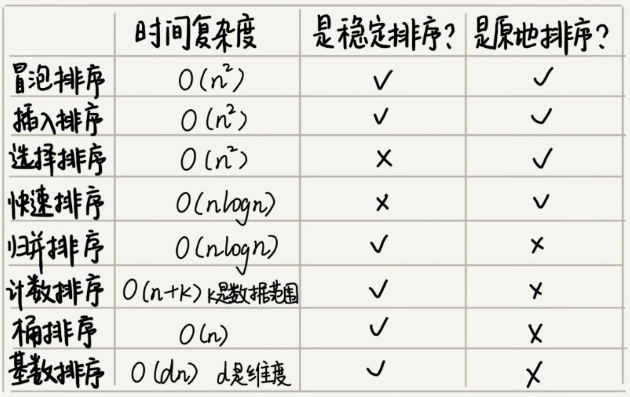
如何实现一个通用的排序算法
-
要知道时间复杂度只是描述一个增长趋势,复杂度为
O(n**2)的排序算法执行时间不一定比复杂度为O(nlongn)长,因为在计算O时省略了系数、常数、低阶。实际上,在对小规模数据进行排序时,n**2的值实际比knlogn+c还要小。 -
可优化的点
-
小数据规模时,可以优先使用归并排序,在小规模时占用的额外空间并不影响
-
数据量较大时,可以使用快排,快排在最坏情况下会退化为
O(n**2),主要原因是因为分区点的选择,分区点选择优化思路如下- 三数取中:从区间的头、尾、中分别取一个数,将其中间值作为分区点。数据很多时可以“五数取中”、“十数取中”等等
- 随机选择:即从排序区间中随机选择一个数作为分区点。
-
数据量过多可以使用Timsort甚至计数排序
-
-
jdk1.8中Arrays.sort()实现
- n < 47 插入排序
- n < 286 双轴快排
- 其他Timsort

 浙公网安备 33010602011771号
浙公网安备 33010602011771号