决策树算法-理论篇-如何计算信息纯度
微信公众号:码农充电站pro
个人主页:https://codeshellme.github.io
1,什么是决策树?
决策树是一种机器学习算法,我们可以使用决策树来处理分类问题。决策树的决策(分类)过程可以用一个倒着的树形结构来形象的表达出来,因此得名决策树。
比如我们根据天气是否晴朗和是否刮风来决定是否去踢球?当天气晴朗并且不刮风的时候,我们才去踢球。
此时,就可以将这个决策过程用一个树形结构来表示,如下:
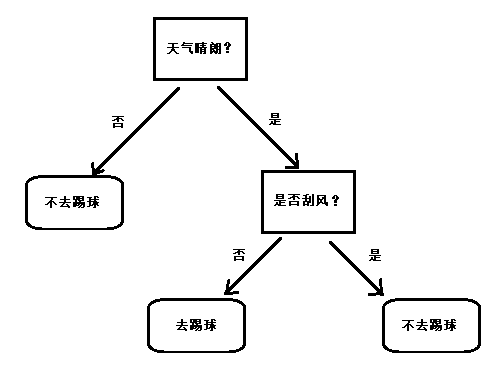
这就是一颗最简单的决策树,我们可以用它来判断是否要去踢球。最上方是树的根节点,最下方是树的叶子节点。方框里是判断的过程,椭圆形中是决策的结果。
当然,实际的使用过程中,判断条件并不会这么简单,也不会让我们自己手动画图。实际应用中,我们会让程序自动的,从一堆样本数据集中构造出这颗决策树,这个程序自动构建决策树的过程就是机器学习的过程。
最终构造出来的这棵决策树就是机器学习的结果,叫做模型。最后,我们可以向模型中输入一些属性条件,让模型给出我们判断结果。

2,如何构建决策树?
比如我们有如下数据集:
| 序号 | 条件:天气晴朗? | 条件:是否刮风? | 结果:去踢球吗? |
|---|---|---|---|
| 1 | 是 | 否 | 去 |
| 2 | 是 | 是 | 不去 |
| 3 | 否 | 是 | 不去 |
| 4 | 否 | 否 | 不去 |
可以看到这个表格中有4 行(第一行表头不算),4 列数据。
一般在机器学习中,最后一列称为目标(target),前边的列都称为特征(features)。
我们要根据这个数据集,来构建一颗决策树,那如何构建呢?
首先,需要确定使用哪个属性作为第一个判断条件,是先判断天气晴朗,还是先判断是否刮风?也就是,让天气晴朗作为树的根节点,还是让是否刮风作为树的根节点?
解决这个问题需要用到信息熵和信息纯度的概念,我们先来看什么是信息熵。
3,什么是信息熵?
1948 年,克劳德·香浓在他的论文“通信的数学原理”中提到了信息熵(一般用H 表示),度量信息熵的单位是比特。
就是说,信息量的多少是可以量化的。一条信息量的多少与信息的不确定性有关,可以认为,信息量就等于不确定性的多少(信息的不确定度)。
信息熵的计算公式如下:
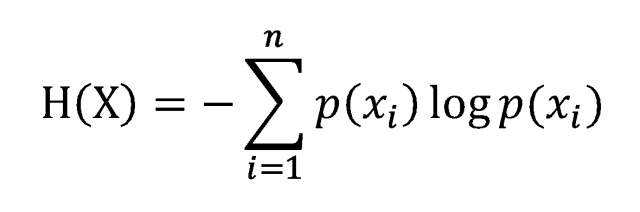
该公式的含义是:
- 待分类的事物可以分在多个分类中,这里的
n就是分类的数目。 H(X)表示熵,数学含义是,所有类别包含的信息期望值。-㏒p(Xì)表示符号的信息值,p(Xì)是选择该分类的概率。- 公式中的
log一般以2 为底。
总之,就是要知道,信息量的多少是可以用数学公式计算出来的,用信息论中的专业术语就叫做信息熵。信息熵越大,信息量也就越大。
3.1,计算信息熵
那么我们就来计算一下上面表格数据的信息熵。我们只关注“结果”那一列:
| 结果:去踢球吗? |
|---|
| 去 |
| 不去 |
| 不去 |
| 不去 |
根据表格,我们可以知道,所有的分类共有2 种,也就是“去” 和“不去”,“去”出现了1 次,“不去”出现了3 次。
分别计算“去” 和“不去” 出现的概率:
P(去) = 1 / 4 = 0.25P(不去) = 3 / 4 = 0.75
然后,根据熵的计算公式来计算“去”和“不去” 的信息熵,其中log 以2 为底:
H(去) = 0.25 * log 0.25 = -0.5H(不去) = 0.74 * log 0.75 = -0.31127812445913283
所以,整个表格含有的信息量就是:
H(表格) = -(H(去) + H(不去)) = 0.81127812445913283
3.2,用代码实现信息熵的计算
将计算信息熵的过程用Python 代码实现,如下:
import math
# 本函数用于计算一组数据的信息熵
# data_set 是一个列表,代表一组数据
# data_set 的元素data 也是一个列表
def calc_ent(data_set):
labels = {} # 用于统计每个label 的数量
for data in data_set:
label = data[-1] # 只用最后一个元素做计算
if label not in labels:
labels[label] = 0
labels[label] += 1
ent = 0 # 熵
n = len(data_set) # 数据条数
# 计算信息熵
for label in labels:
prob = float(labels[label]) / n # label 的概率
ent -= prob * math.log(prob, 2) # 根据信息熵公式计算
return ent
下面用该函数来计算表格的信息熵:
# 将表格转化为 python 列表
# "yes" 表示"去"
# "no" 表示"不去"
data_set = [['yes'], ['no'], ['no'], ['no']]
ent = calc_ent(data_set)
print(ent) # 0.811278124459
可见,用代码计算出来的结果是 0.811278124459,跟我们手算的结果 0.81127812445913283 是一样的(保留的小数位数不同)。
4,什么是信息纯度?
信息的纯度与信息熵成反比:
- 信息熵越大,信息量越大,信息越杂乱,纯度越低。
- 信息熵越小,信息量越小,信息越规整,纯度越高。
经典的“不纯度”算法有三种,分别是:
- 信息增益,即
ID3 算法,Information Divergence,该算法由Ross Quinlan于1975 年提出,可用于生成二叉树或多叉树。- ID3 算法会选择信息增益最大的属性来作为属性的划分。
- 信息增益率,即
C4.5 算法,是Ross Quinlan在ID3 算法的基础上改进而来,可用于生成二叉树或多叉树。 - 基尼不纯度,即
CART 算法,Classification and Regression Trees,中文为分类回归树。- 即可用于分类数,又可用于回归树。分类树用基尼系数做判断,回归树用偏差做判断。
- 基尼系数本身反应了样本的不确定度。
- 当基尼系数越小的时候,样本之间的差异性越小,不确定程度越低。
CART 算法会选择基尼系数最小的属性作为属性的划分。
信息增益是其中最简单的一种算法,后两者都是由它衍生而来。本篇文章中,我们只详细介绍信息增益。
基尼系数是经济学中用来衡量一个国家收入差距的常用指标。当基尼系数大于
0.4的时候,说明财富差异较大。基尼系数在0.2-0.4之间说明分配合理,财富差距不大。
5,什么是信息增益?
信息增益就是,在根据某个属性划分数据集的前后,信息量发生的变化。
信息增益的计算公式如下:
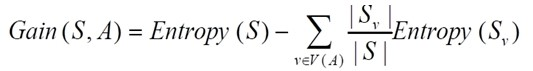
该公式的含义:
- 简写就是:
G = H(父节点) - H(所有子节点) - 也就是:父节点的信息熵减去所有子节点的信息熵。
- 所有子节点的信息熵会按照子节点在父节点中的出现的概率来计算,这叫做归一化信息熵。
信息增益的目的在于,将数据集划分之后带来的纯度提升,也就是信息熵的下降。如果数据集在根据某个属性划分之后,能够获得最大的信息增益,那么这个属性就是最好的选择。
所以,我们想要找到根节点,就需要计算每个属性作为根节点时的信息增益,那么获得信息增益最大的那个属性,就是根节点。
5.1,计算信息增益
为了方便看,我将上面那个表格放在这里:
| 序号 | 条件:天气晴朗? | 条件:是否刮风? | 结果:去踢球吗? |
|---|---|---|---|
| 1 | 是 | 否 | 去 |
| 2 | 是 | 是 | 不去 |
| 3 | 否 | 是 | 不去 |
| 4 | 否 | 否 | 不去 |
我们已经知道了,信息增益等于按照某个属性划分前后的信息熵之差。
这个表格划分之前的信息熵我们已经知道了,就是我们在上面计算的结果:
H(表格) = 0.81127812445913283。
接下来,我们计算按照“天气晴朗”划分的信息增益。按照“天气晴朗”划分后有两个表格。
表格1,“天气晴朗”的值为“是”:
| 序号 | 条件:天气晴朗? | 条件:是否刮风? | 结果:去踢球吗? |
|---|---|---|---|
| 1 | 是 | 否 | 去 |
| 2 | 是 | 是 | 不去 |
分类共有2 种,也就是“去” 和“不去”,“去”出现了1 次,“不去”出现了1 次。
所以,“去” 和“不去” 出现的概率均为0.5:
P(去) = P(不去) = 1 / 2 = 0.5
然后,“去”和“不去” 的信息熵,其中log 以2 为底:
H(去) = H(不去) = 0.5 * log 0.5 = -0.5
所以,表格1 含有的信息量就是:
H(表格1) = -(H(去) + H(不去)) = 1
表格2,“天气晴朗”的值为“否”:
| 序号 | 条件:天气晴朗? | 条件:是否刮风? | 结果:去踢球吗? |
|---|---|---|---|
| 3 | 否 | 是 | 不去 |
| 4 | 否 | 否 | 不去 |
所有的分类只有1 种,是“不去”。所以:
P(不去) = 1
然后,“不去” 的信息熵,其中log 以2 为底:
H(不去) = 1 * log 1 = 0
所以,表格2 含有的信息量就是:
H(表格2) = 0
总数据共有4 份:
- 表格1 中有2 份,概率为 2/4 = 0.5
- 表格2 中有2 份,概率为 2/4 = 0.5
所以,最终按照“天气晴朗”划分的信息增益为:
G(天气晴朗) = H(表格) - (0.5*H(表格1) + 0.5*H(表格2)) = H(表格) - 0.5 = 0.31127812445913283。
5.2,ID3 算法的缺点
当我们计算的信息增益多了,你会发现,ID3 算法倾向于选择取值比较多的属性作为(根)节点。
但是有的时候,某些属性并不会影响结果(或者对结果的影响不大),那此时使用ID3 选择的属性就不恰当了。
为了改进ID3 算法的这种缺点,C4.5 算法应运而生。
C4.5 算法对ID3 算法的改进点包括:
- 采用信息增益率,而不是信息增益,避免ID3 算法有倾向于选择取值多的属性的缺点。
- 加入了剪枝技术,防止ID3 算法中过拟合情况的出现。
- 对连续的属性进行离散化的处理,使得C4.5 算法可以处理连续属性的情况,而ID3 只能处理离散型数据。
- 处理缺失值,C4.5 也可以针对数据集不完整的情况进行处理。
当然C4.5 算法也并不是没有缺点,由于 C4.5算法需要对数据集进行多次扫描,所以算法效率相对较低。这里不再展开讨论C4.5 算法。
下篇会介绍如何用决策树来解决实际问题。
欢迎关注作者公众号,获取更多技术干货。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号