使用Sharding-JDBC 分库分表
当mysql单表数据量比较大时往往需要分库分表,Sharding-JDBC是当当网开源的数据库分库分表中间件。Sharding-JDBC定位为轻量级java框架,使用客户端直连数据库,以jar包形式提供服务,无proxy代理层,无需额外部署,无其他依赖,DBA也无需改变原有的运维方式。本文主要讲述该框架与spring+mybatis的整合使用。
1.准备工作
由于是分库分表,所以需要在不同的数据库建立相同的表。分别在sharding_0,sharding_1两个数据库中建立t_user0,t_user1,t_user2三张表,需要用到的SQL语句如下:
SET FOREIGN_KEY_CHECKS=0;
DROP TABLE IF EXISTS `t_user_0`;
CREATE TABLE `t_user_0` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` int(11) NOT NULL,
`name` varchar(255) NOT NULL,
`age` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
DROP TABLE IF EXISTS `t_user_1`;
CREATE TABLE `t_user_1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` int(11) NOT NULL,
`name` varchar(255) NOT NULL,
`age` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
DROP TABLE IF EXISTS `t_user_2`;
CREATE TABLE `t_user_2` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` int(11) NOT NULL,
`name` varchar(255) NOT NULL,
`age` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
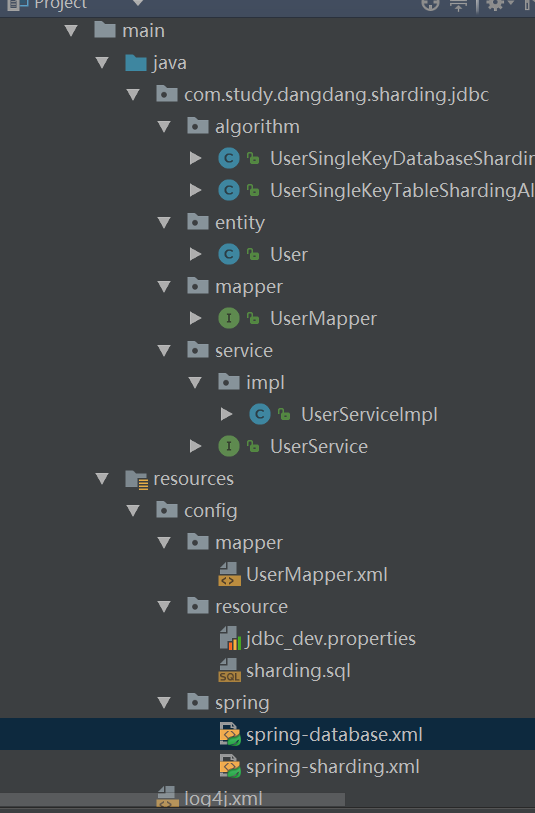
项目的整体结构如下图所示:
<dependency>
<groupId>io.shardingjdbc</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>${latest.release.version}</version>
</dependency>
2.代码详解
代码结构如上图所示,Mapper,Service层和普通的SSM项目一样,无需做改变,主要是增加了algorithm下面的两个文件,一个是分库策略,一个是分表策略。然后spring的配置文件稍稍做了修改,spring-database.xml设置的是数据库的连接信息。spring-sharding.xml设置的是具体的分库分表信息。
spring-database.xml配置如下所示:
<bean class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer">
<property name="locations">
<list>
<value>classpath:config/resource/jdbc_dev.properties</value>
</list>
</property>
</bean>
<bean name="sharding_0" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
<property name="url" value="${jdbc_url0}" />
<property name="username" value="${jdbc_username0}" />
<property name="password" value="${jdbc_password0}" />
<!-- <property name="driverClass" value="${jdbc_driver0}" /> -->
<!-- 初始化连接大小 -->
<property name="initialSize" value="0" />
<!-- 连接池最大使用连接数量 -->
<property name="maxActive" value="20" />
<!-- 连接池最小空闲 -->
<property name="minIdle" value="0" />
<!-- 获取连接最大等待时间 -->
<property name="maxWait" value="60000" />
<property name="validationQuery" value="${validationQuery}" />
<property name="testOnBorrow" value="false" />
<property name="testOnReturn" value="false" />
<property name="testWhileIdle" value="true" />
<!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 -->
<property name="timeBetweenEvictionRunsMillis" value="60000" />
<!-- 配置一个连接在池中最小生存的时间,单位是毫秒 -->
<property name="minEvictableIdleTimeMillis" value="25200000" />
<!-- 打开removeAbandoned功能 -->
<property name="removeAbandoned" value="true" />
<!-- 1800秒,也就是30分钟 -->
<property name="removeAbandonedTimeout" value="1800" />
<!-- 关闭abanded连接时输出错误日志 -->
<property name="logAbandoned" value="true" />
<property name="filters" value="stat" />
</bean>
<bean name="sharding_1" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
<property name="url" value="${jdbc_url1}" />
<property name="username" value="${jdbc_username1}" />
<property name="password" value="${jdbc_password1}" />
<!-- <property name="driverClass" value="${jdbc_driver1}" /> -->
<!-- 初始化连接大小 -->
<property name="initialSize" value="0" />
<!-- 连接池最大使用连接数量 -->
<property name="maxActive" value="20" />
<!-- 连接池最小空闲 -->
<property name="minIdle" value="0" />
<!-- 获取连接最大等待时间 -->
<property name="maxWait" value="60000" />
<property name="validationQuery" value="${validationQuery}" />
<property name="testOnBorrow" value="false" />
<property name="testOnReturn" value="false" />
<property name="testWhileIdle" value="true" />
<!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 -->
<property name="timeBetweenEvictionRunsMillis" value="60000" />
<!-- 配置一个连接在池中最小生存的时间,单位是毫秒 -->
<property name="minEvictableIdleTimeMillis" value="25200000" />
<!-- 打开removeAbandoned功能 -->
<property name="removeAbandoned" value="true" />
<!-- 1800秒,也就是30分钟 -->
<property name="removeAbandonedTimeout" value="1800" />
<!-- 关闭abanded连接时输出错误日志 -->
<property name="logAbandoned" value="true" />
<property name="filters" value="stat" />
</bean>
spring-sharding.xml配置如下所示,从下图中可以看到主要是指定了需要分表的策略和分库的策略,然后进行了封装,具体的分库分表策略需要自己编写。
<!-- 配置好dataSourceRulue,即对数据源进行管理 -->
<bean id="dataSourceRule" class="com.dangdang.ddframe.rdb.sharding.api.rule.DataSourceRule">
<constructor-arg>
<map>
<entry key="sharding_0" value-ref="sharding_0"/>
<entry key="sharding_1" value-ref="sharding_1"/>
</map>
</constructor-arg>
</bean>
<!-- 对t_user表的配置,进行分库配置,逻辑表名为t_user,每个库有实际的三张表 -->
<bean id="userTableRule" class="com.dangdang.ddframe.rdb.sharding.api.rule.TableRule">
<constructor-arg value="t_user" index="0"/>
<constructor-arg index="1">
<list>
<value>t_user_0</value>
<value>t_user_1</value>
<value>t_user_2</value>
</list>
</constructor-arg>
<constructor-arg index="2" ref="dataSourceRule"/>
<constructor-arg index="3" ref="userDatabaseShardingStrategy"/>
<constructor-arg index="4" ref="userTableShardingStrategy"/>
</bean>
<!-- t_user分库策略 -->
<bean id="userDatabaseShardingStrategy" class="com.dangdang.ddframe.rdb.sharding.api.strategy.database.DatabaseShardingStrategy">
<constructor-arg index="0" value="user_id"/>
<constructor-arg index="1">
<bean class="com.study.dangdang.sharding.jdbc.algorithm.UserSingleKeyDatabaseShardingAlgorithm" />
</constructor-arg>
</bean>
<!-- t_user 分表策略 -->
<bean id="userTableShardingStrategy" class="com.dangdang.ddframe.rdb.sharding.api.strategy.table.TableShardingStrategy">
<constructor-arg index="0" value="user_id"/>
<constructor-arg index="1">
<bean class="com.study.dangdang.sharding.jdbc.algorithm.UserSingleKeyTableShardingAlgorithm" />
</constructor-arg>
</bean>
<!-- 构成分库分表的规则 传入数据源集合和每个表的分库分表的具体规则 -->
<bean id="shardingRule" class="com.dangdang.ddframe.rdb.sharding.api.rule.ShardingRule">
<constructor-arg index="0" ref="dataSourceRule"/>
<constructor-arg index="1">
<list>
<ref bean="userTableRule"/>
</list>
</constructor-arg>
</bean>
<!-- 对datasource进行封装 -->
<bean id="shardingDataSource" class="com.dangdang.ddframe.rdb.sharding.api.ShardingDataSource">
<constructor-arg ref="shardingRule"/>
</bean>
接下来看一下具体的分库文件和分表文件:
分表的文件UserSingleKeyTableShardingAlgorithm代码如下所示:
public class UserSingleKeyTableShardingAlgorithm implements SingleKeyTableShardingAlgorithm<Integer>{
/**
* sql 中 = 操作时,table的映射
*/
public String doEqualSharding(Collection<String> tableNames, ShardingValue<Integer> shardingValue) {
for (String each : tableNames) {
if (each.endsWith(shardingValue.getValue() % 3 + "")) {
return each;
}
}
throw new IllegalArgumentException();
}
/**
* sql 中 in 操作时,table的映射
*/
public Collection<String> doInSharding(Collection<String> tableNames, ShardingValue<Integer> shardingValue) {
Collection<String> result = new LinkedHashSet<String>(tableNames.size());
for (Integer value : shardingValue.getValues()) {
for (String tableName : tableNames) {
if (tableName.endsWith(value % 3 + "")) {
result.add(tableName);
}
}
}
return result;
}
/**
* sql 中 between 操作时,table的映射
*/
public Collection<String> doBetweenSharding(Collection<String> tableNames,
ShardingValue<Integer> shardingValue) {
Collection<String> result = new LinkedHashSet<String>(tableNames.size());
Range<Integer> range = (Range<Integer>) shardingValue.getValueRange();
for (Integer i = range.lowerEndpoint(); i <= range.upperEndpoint(); i++) {
for (String each : tableNames) {
if (each.endsWith(i % 3 + "")) {
result.add(each);
}
}
}
return result;
}
}
分库的文件UserSingleKeyDatabaseShardingAlgorithm代码如下所示:
public class UserSingleKeyDatabaseShardingAlgorithm implements SingleKeyDatabaseShardingAlgorithm<Integer>{
/**
* sql 中关键字 匹配符为 =的时候,表的路由函数
*/
public String doEqualSharding(Collection<String> availableTargetNames, ShardingValue<Integer> shardingValue) {
for (String each : availableTargetNames) {
if (each.endsWith(shardingValue.getValue() % 2 + "")) {
return each;
}
}
throw new IllegalArgumentException();
}
/**
* sql 中关键字 匹配符为 in 的时候,表的路由函数
*/
public Collection<String> doInSharding(Collection<String> availableTargetNames, ShardingValue<Integer> shardingValue) {
Collection<String> result = new LinkedHashSet<String>(availableTargetNames.size());
for (Integer value : shardingValue.getValues()) {
for (String tableName : availableTargetNames) {
if (tableName.endsWith(value % 2 + "")) {
result.add(tableName);
}
}
}
return result;
}
/**
* sql 中关键字 匹配符为 between的时候,表的路由函数
*/
public Collection<String> doBetweenSharding(Collection<String> availableTargetNames,
ShardingValue<Integer> shardingValue) {
Collection<String> result = new LinkedHashSet<String>(availableTargetNames.size());
Range<Integer> range = (Range<Integer>) shardingValue.getValueRange();
for (Integer i = range.lowerEndpoint(); i <= range.upperEndpoint(); i++) {
for (String each : availableTargetNames) {
if (each.endsWith(i % 2 + "")) {
result.add(each);
}
}
}
return result;
}
}
可以看到对于不同的sql语句关键词有不同的策略,主要实现了doEqualSharding,doInSharding,doBetweenSharding三个方法,看源码可以得知针对不同的分库分表规则需要实现不同的接口。
3. 测试
测试用例代码如下:
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = { "classpath*:config/spring/spring-database.xml",
"classpath*:config/spring/spring-sharding.xml" })
public class ShardingJdbcMybatisTest {
@Resource
public UserService userService;
@Test
public void testUserInsert() {
User u = new User();
for(int i=0;i<100;i++){
u.setUserId(26+i);
u.setAge(2+i);
u.setName("war3"+i);
Assert.assertEquals(userService.insert(u), true);
}
}
}
查看数据库可以看到100个用例均匀分布到了数据库的表中。
参考文献
http://blog.csdn.net/clypm/article/details/54378523
http://shardingjdbc.io/docs/00-overview/
https://my.oschina.net/editorial-story/blog/888650
http://www.infoq.com/cn/news/2016/01/sharding-jdbc-dangdang


 浙公网安备 33010602011771号
浙公网安备 33010602011771号