String s = new String("xyz")创建了几个实例你真的能答对吗?
从面试题说起
String s = new String("xyz"); 创建了几个实例?
这是一道很经典的面试题,在一本所谓的Java宝典上,我看到的“标准答案”是这样的:
两个,一个堆区的“xyz”,一个栈区指向“xyz”的s。
这个所谓的“标准答案”槽点太多,后面我们慢慢分析。
但是我觉得这个问题本身不具有什么意义,因为他没有既定义“创建”的具体含义,又没有指定“创建”的时间,是运行时吗?包不包括类加载的时候?有没有上下文代码语境?也没有定义实例是指什么实例,是指Java实例吗?还是单指String实例?包不包括JVM中的C++实例?
显然,这是一个“有问题的问题”。也是一个“有问题的答案”。
String结构
在分析之前,为了方便后面画内存图,我们需要对Java中的String结构有一个大致了解:
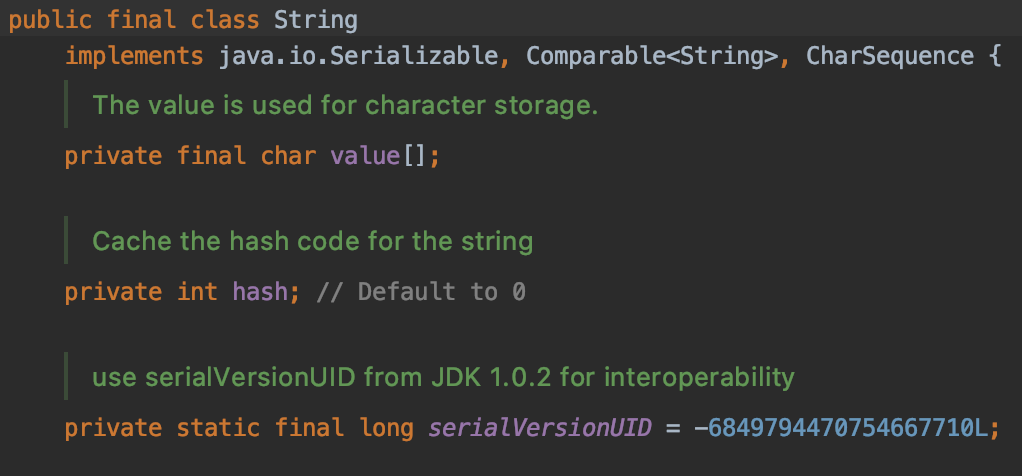
从上图可以看出,String类有三个属性:
value:char数组,用于用于存储字符。
hash:缓存字符串的哈希码,默认为0(String的hash值在真正调用hashCode方法的时候才会去计算)。
serialVersionUID:序列化用的。
正常的问题与合理的解释
在上面的题干上加上一些限定词,可以得到一个新的问题:
String s = new String("xyz");创建几个String实例?
对于这个问题,在网上能找到一些比较高赞的答案:
两个,一个是字符串字面量"xyz"所对应的、存在于全局共享的常量池中的实例,另一个是通过new String(String)创建并初始化的、内容(字符)与"xyz"相同的实例。考虑到如果常量池中如果有这个字符串,就只会创建一个。同时在栈区还会有一个对new出来的String实例的s。
能提到常量池,我认为这已经达到大部分面试官对这个题目答案的期许了,或许这也是面试官考察的点。
但这个答案也仅是比较合理,并不完全正确。为什么呢?
我认为这个答案并不严谨,甚至是有一些错误理解在其中的。
首先,我不理解的是为什么很多答主总是用“常量池”来代替“字符串常量池”,在Java体系中,其实是有三个常量池的,三个常量池的概念和用处都不相同,我认为是不应该混淆的。
其次,就算答主说的“常量池”就是“字符串常量池”,可“字符串常量池”中存的是String实例的引用,而不是字符串,这是有很大区别的。
而且这个答案是没有考虑代码执行的环境。
这些我们后面都会一一分析。
分清变量和实例
首先我们要分清变量和实例的区别。
先回到开头的问题与“标准答案” 。
问题:String s = new String("xyz"); 创建了几个实例?
答案:两个,一个堆区的“xyz”,一个栈区指向“xyz”的s
很明显给答案的人是没有把变量和实例分清楚。Java里变量就是变量,类型的变量只是对某个对象实例或者null的,不是实例本身。声明变量的个数跟创建实例的个数没有必然关系。
举个例子:
String s1 = "xyz";
String s2 = s1.concat("");
String s3 = null;
new String(s1);
这段代码会涉及3个String类型的变量:
- s1,指向下面String实例的1
- s2,指向与s1相同
- s3,值为null,不指向任何实例
以及3个String实例:
- "xyz"字面量对应的驻留的字符串常量的String实例
- ""字面量对应的驻留的字符串常量的String实例 (String.concat()是个有趣的方法,当发现传入的参数是空字符串时会返回this,所以这里不会额外创建新的String实例)
- 通过new String(String)创建的新String实例,没有任何变量指向它。
类加载
对于String s = new String("xyz");创建几个String实例?这个问题。
似乎网上的所有答案都把类加载过程和实际执行过程合在一起分析的。
看起来好像是没有什么问题的,因为想要执行某个代码片段,其所在的类必然要被加载,而且对于同一个类加载器,最多加载一次。
但是我们看一下这段代码的字节码:
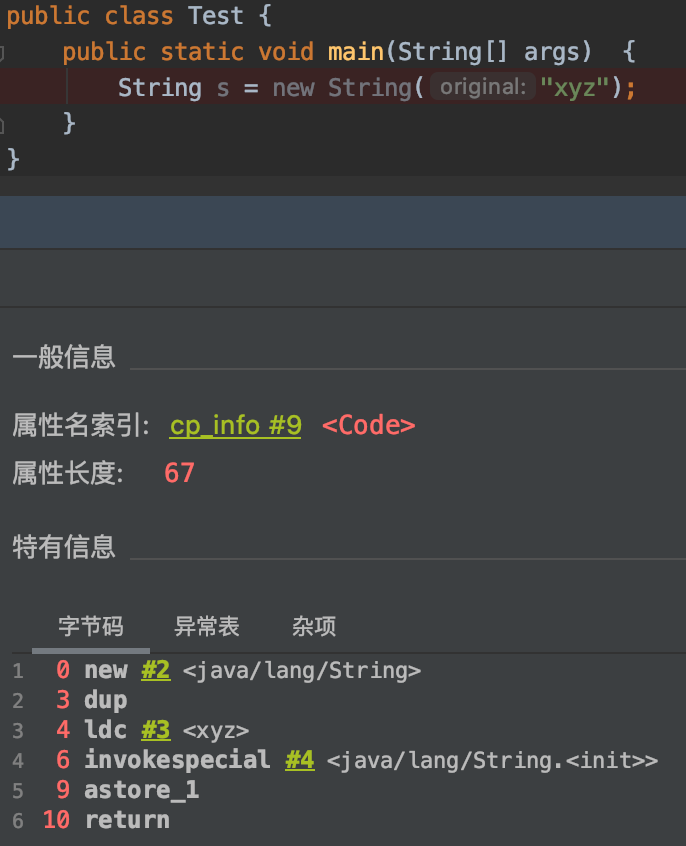
似乎只出现了一次new java/lang/String,也就是只创建了一个String实例。也就是说原问题中的代码在每执行一次只会新创建一个String实例。 这里的ldc指令只是把先前在类加载过程中已经创建好的一个String实例("xyz")的一个引用压到操作数栈顶而已,并没有创建新的String实例。
不是应该有两个实例吗?还有一个String实例是在什么时候创建的呢?
我们都知道类加载的解析阶段是Java虚拟机将常量池内的符号引用替换为直接引用的过程,根据JVM规范,符合规范的JVM实现应该在类加载的过程中创建并驻留一个String实例作为常量来对应"xyz"字面量,具体是在类加载的解析阶段进行的。这个常量是全局共享的,只在先前尚未有内容相同的字符串驻留过的前提下才需要创建新的String实例。
所以你可以理解成,在类加载的解析阶段,其实已经创建了一个String实例,执行代码的时候,又new了一个String实例。当然,你把两者放在一起讨论并不会有什么问题。
JVM优化
以上讨论都只是针对规范所定义的Java语言与Java虚拟机而言。概念上是如此,但实际的JVM实现可以做得更优化,原问题中的代码片段有可能在实际执行的时候一个String实例也不会完整创建(没有分配空间)。
不结合上下文代码来看就直接说是“标准答案”就是耍流氓。
我们看下这段代码:
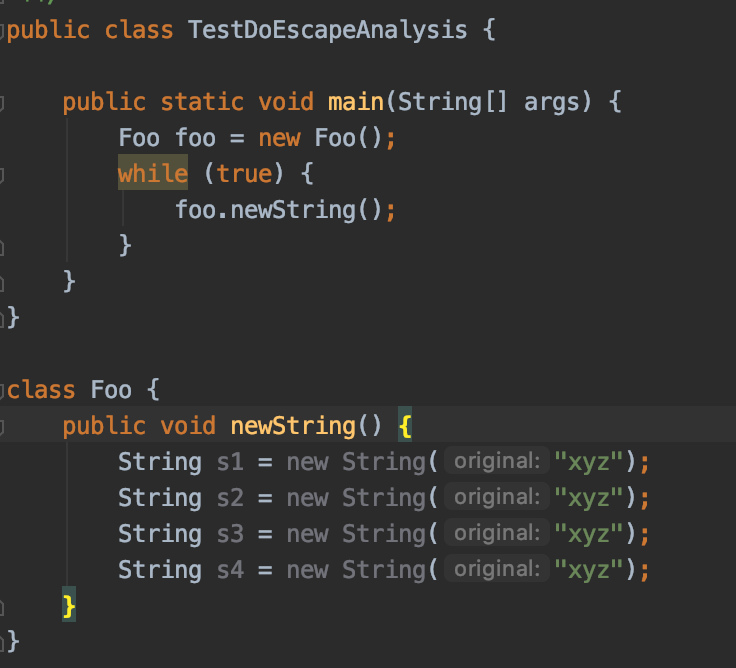
运行这段代码,会不断的创建String对象吃内存,然后频繁的造成GC。
对于这个结论相信大家都没有意见,我们加上-XX:+PrintGC -XX:-DoEscapeAnalysis打印日志,关闭逃逸分析(JDK8默认开启此优化,我们先关闭)运行一下看看。
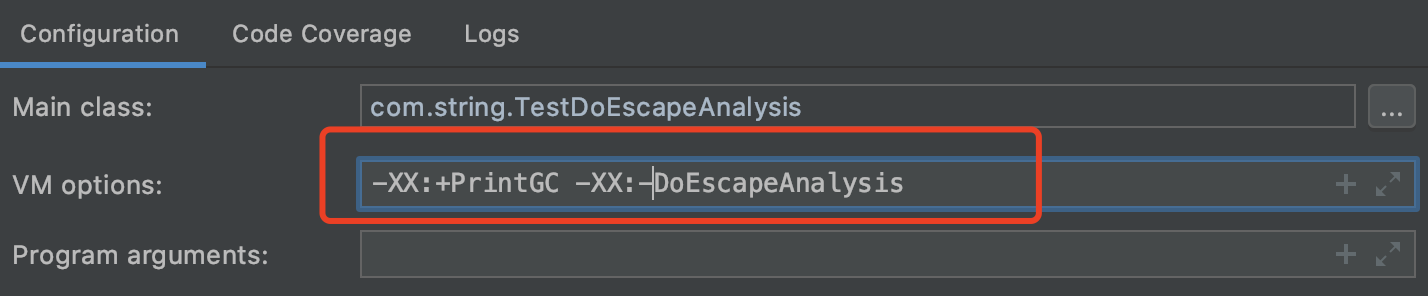
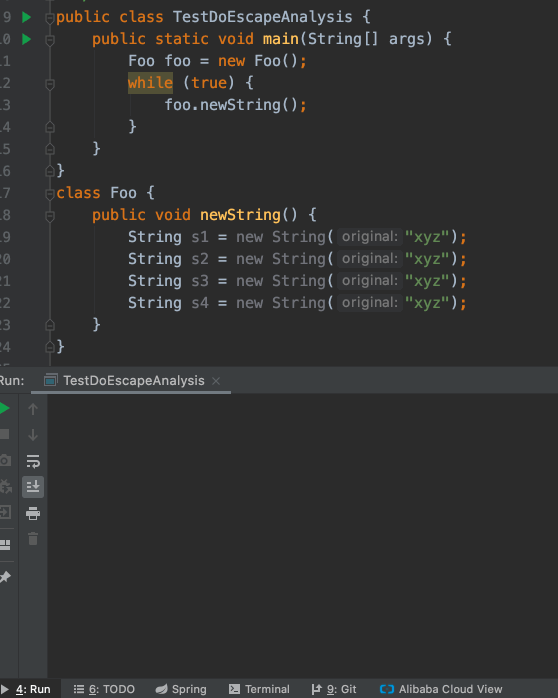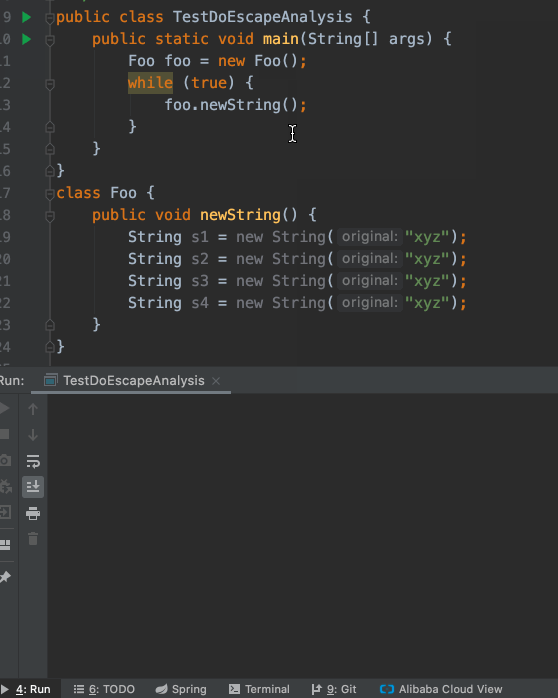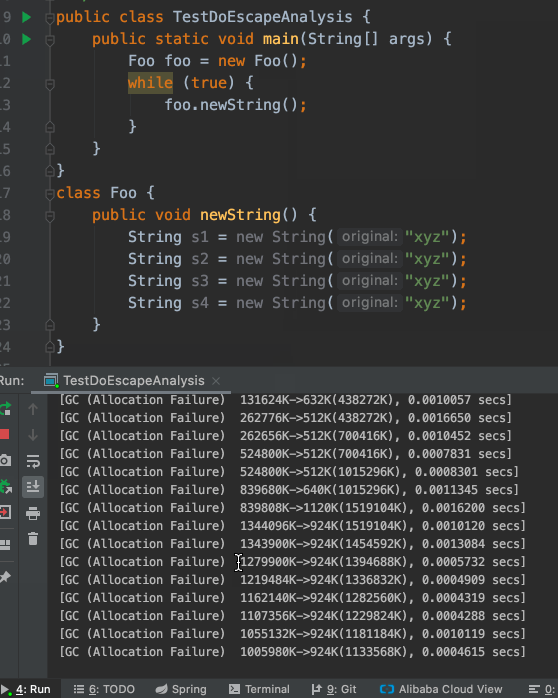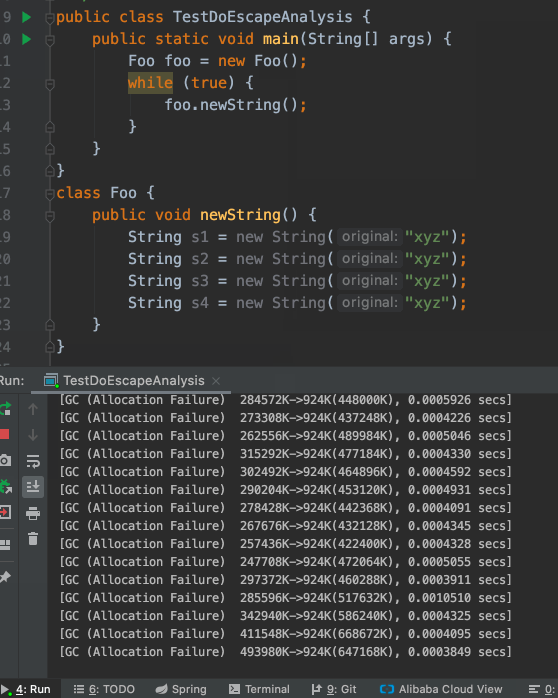
结果确实如我们所料,不断的创建String对象吃内存导致频繁GC。
我们现在将-XX:-DoEscapeAnalysis改成-XX:+DoEscapeAnalysis,重新跑一下这段代码:
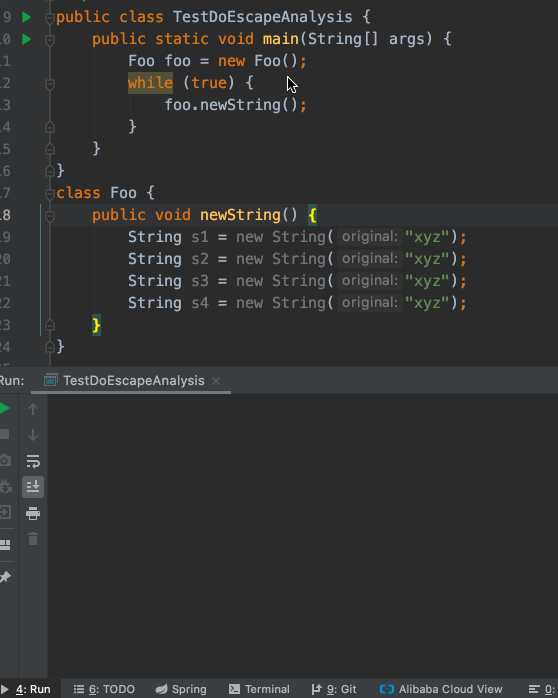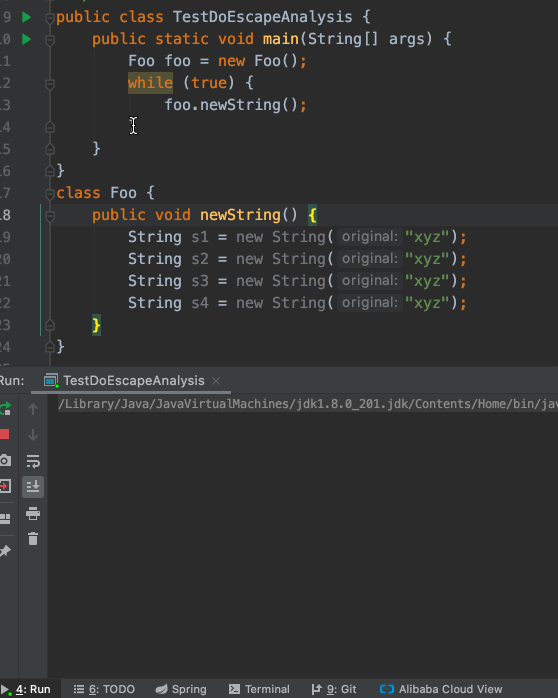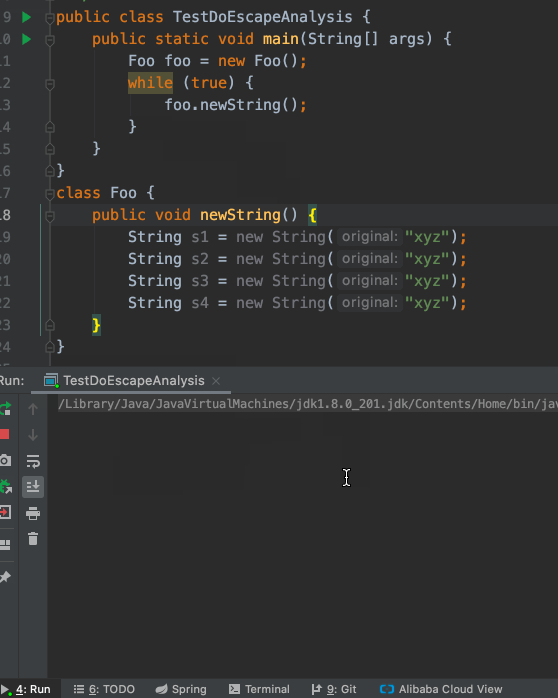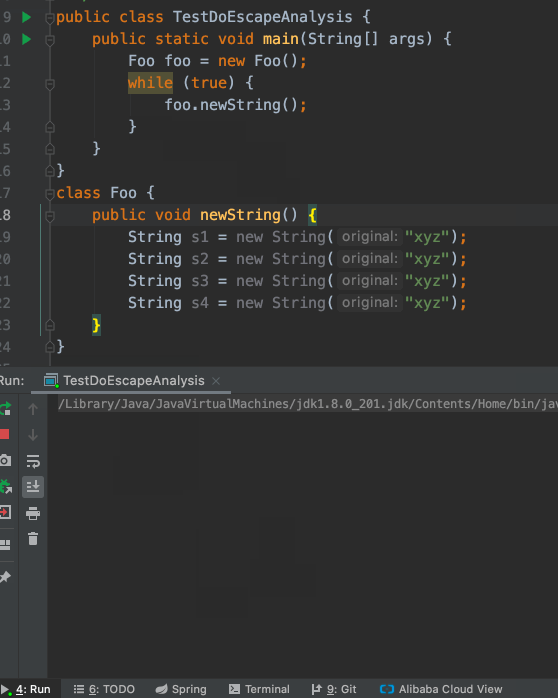
神奇的事情发生了,继续跑下去也没有再打出GC日志了。难道新创建String对象都不吃内存了么?
实际情况是:经过HotSpot VM的的优化后,newString()方法不会新创建String实例了。这样自然不吃内存,也就不再触发GC了。
现在再来看开篇的那个问题,不结合具体情况,还能简单的说String s = new String("xyz");会创建两个String实例吗?
我只是举了一个逃逸分析的例子,HotSpot VM还有很多像这样的优化,比如方法内联、标量替换和无用代码削除。
klass-oop
如果题干上没有加上“Java”实例的定语,那JVM中的oop实例我们也不应该忽略。
为了后面能更好的说清楚这一点,需要补充一下klass-opp模型的知识。
为了保持严谨,先做一个约定,全文只要涉及JVM具体实现的内容都是基于Jdk8中HotSpot VM展开的。
HotSpot VM是基于C++实现,而C++是一门面向对象的语言,本身是具备面向对象基本特征的,所以Java中的对象表示,最简单的做法是为每个Java类生成一个C++类与之对应。但HotSpot VM并没有这么做,而是设计了一套klass-oop模型。
klass,它是Java类的元信息在JVM中的存在形式。一个Java类被JVM类加载器加载之后,就是以klass的形式存在于JVM之中。
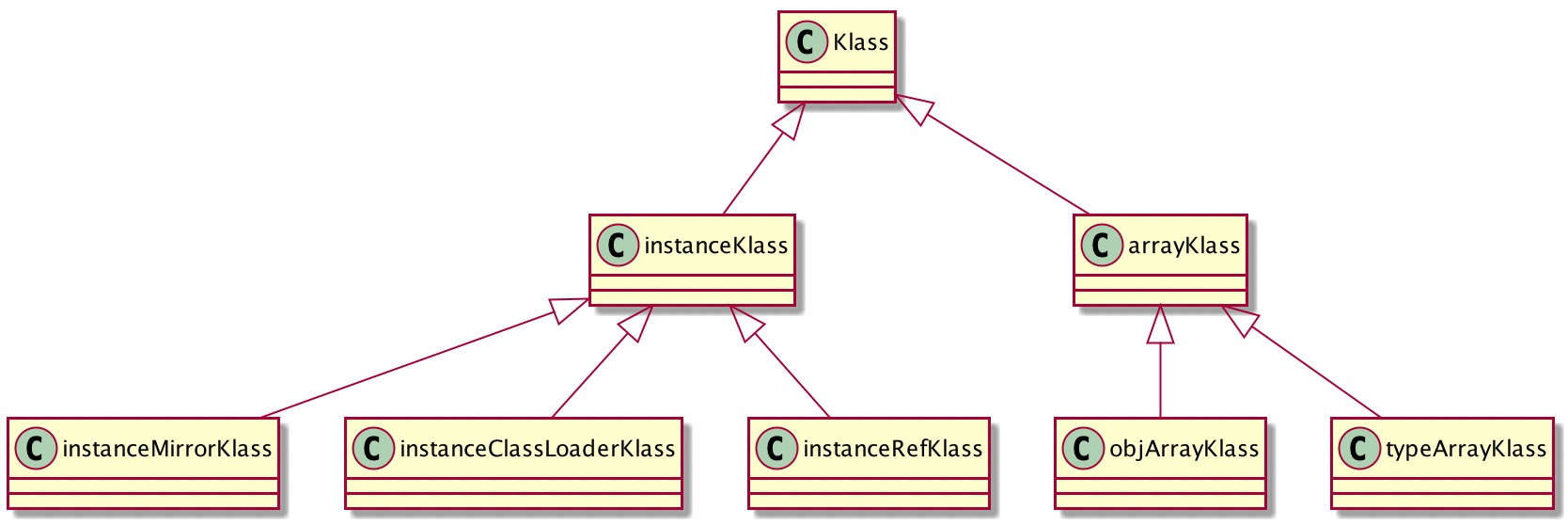
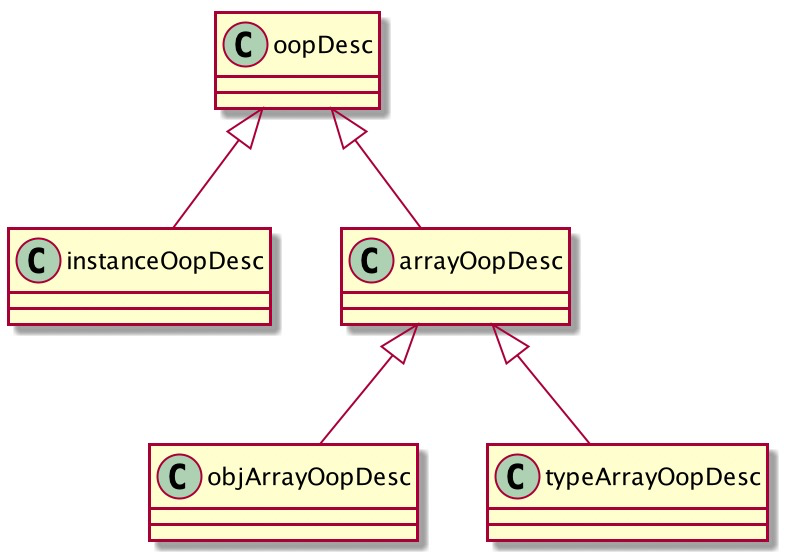
oop,它是Java对象在JVM中的存在形式。每创建一个新的对象,在JVM内部就会相应地创建一个对应类型的OOP对象。
其中instanceOopDesc表示非数组对象,arrayOopDesc表示数组对象;
而objArrayOopDesc表示引用类型数组对象,typeArrayOopDesc表示基本类型数组对象。
举个例子:Java中String类的一个实例,在JVM中会有一个对应的instanceOopDesc实例。
字符串常量池
在Java体系中,有三种常量池:
- class字节码中的常量池:存在于硬盘上。主要存放两大类常量:字面量、符号引用。
- 运行时常量池:方法区的一部分。我们常说的常量池,就是指这一块区域:方法区中的运行时常量池。
- 字符串常量池:存在于堆区。这个常量池在JVM层面就是一个StringTable,只存储对java.lang.String实例的引用,而不存储String对象的内容。一般我们说一个字符串进入了字符串常量池其实是说在这个StringTable中保存了对它的引用,反之,如果说没有在其中就是说StringTable中没有对它的引用。
今天,我们重点说的是字符串常量池,即String Pool,在JVM中对应的类是StringTable,底层实现是一个Hashtable。也是利用的哈希思想。

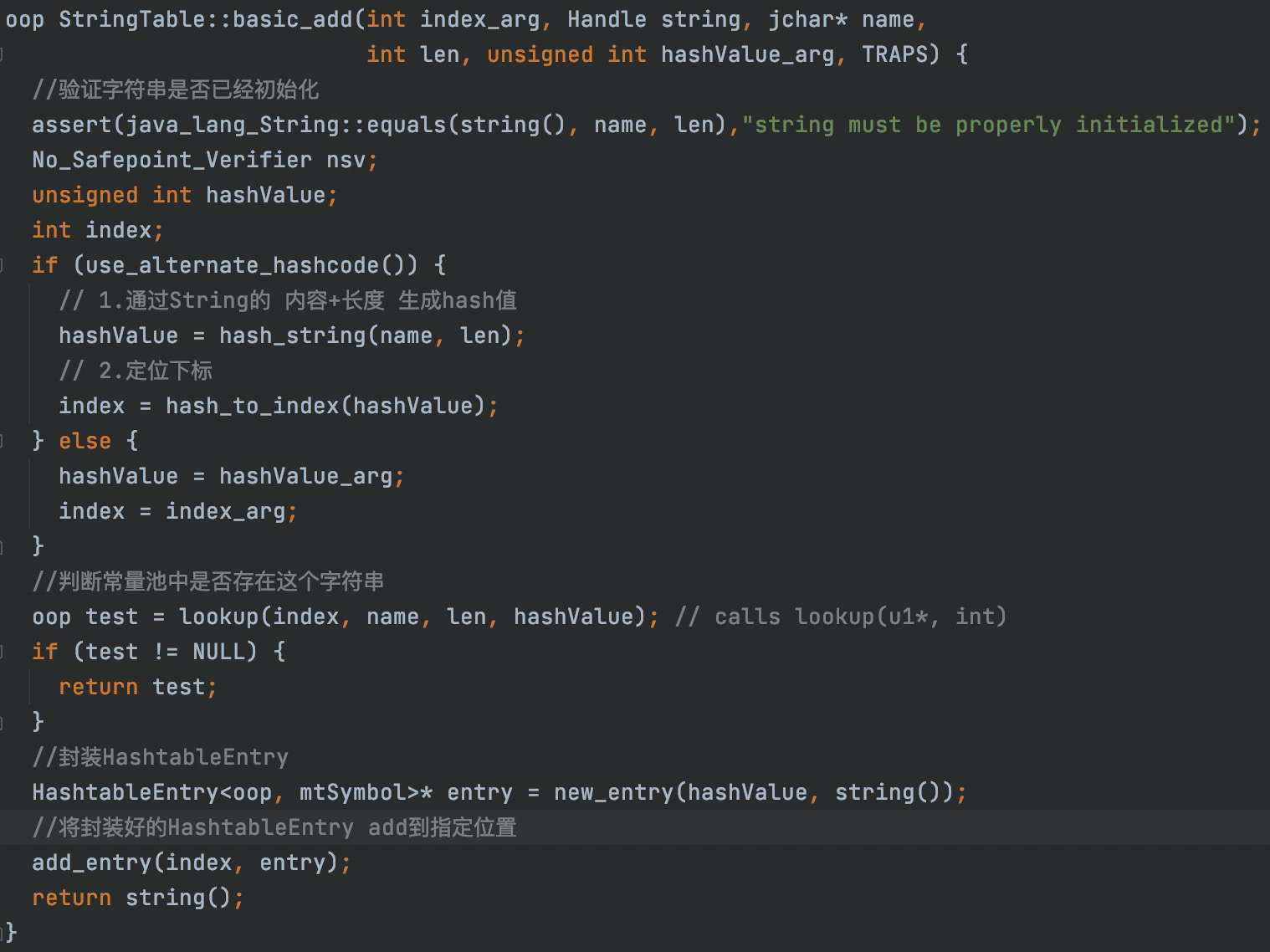
下面这段代码,是往字符串常量池添加字符串方法。虽然是C++代码,但我相信学过Java的人都能看懂,至少也能明白这段代码干了什么事情。会通过String的内容+长度生成的hash值定位下标index,然后将Java的String类的实例对应的instanceOopDesc封装成HashtableEntry作为存储结构存储到常量池。
补充完字符串常量池的知识之后,我们再回到文章开头的那一题:
String s = new String("xyz");创建了几个实例?
我们画一个内存图,图中省略了两个String对应的instanceOopDesc实例。
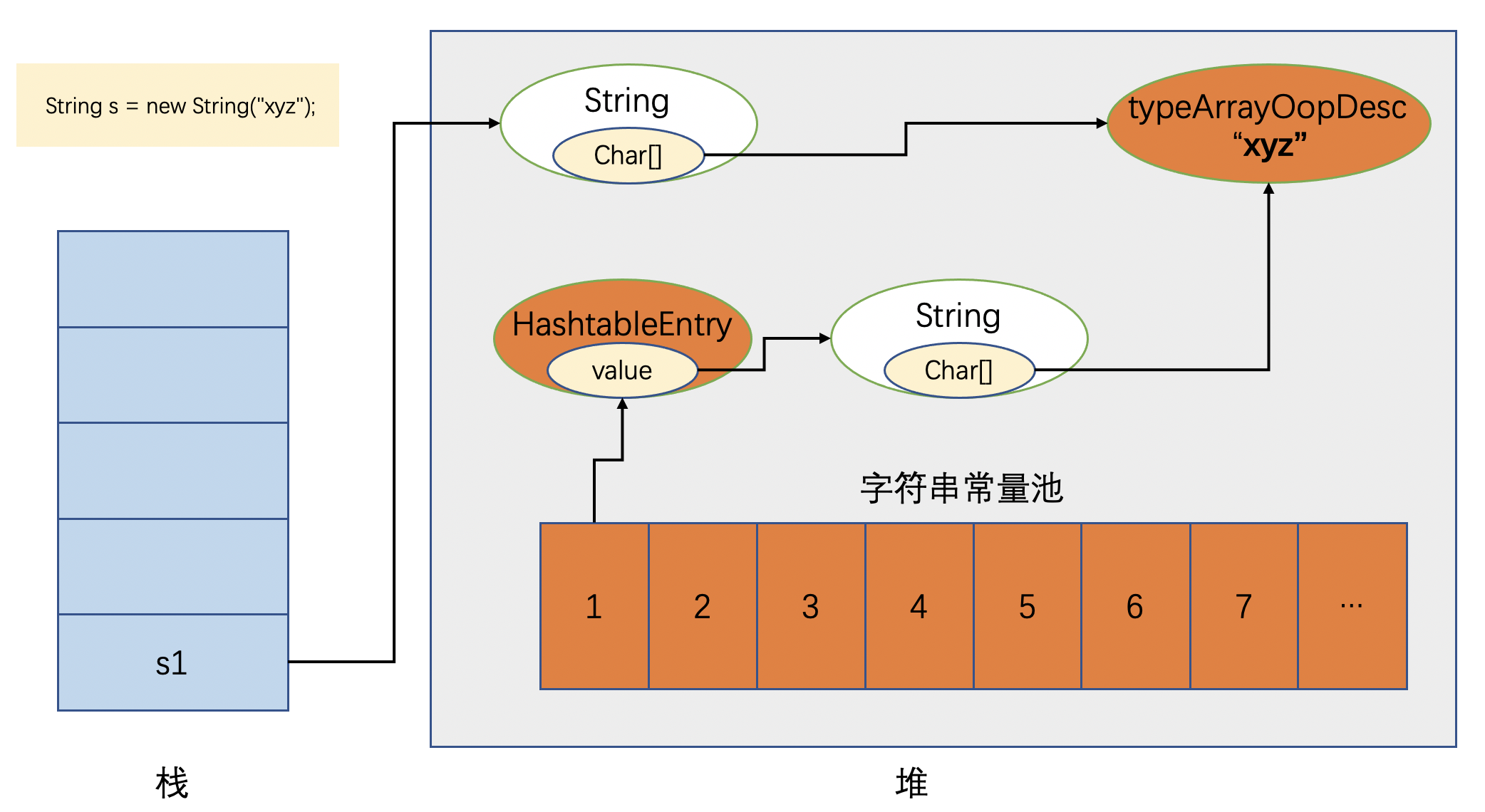
不难得出答案,如果包括JVM中的C++实例的话,有两个Java的String实例,两个String实例对应的instanceOopDesc实例,还有一个char[]数组对应的typeArrayOopDesc实例。加一起一共是5个,也可以说2个String实例加上3个oop实例。
总结
String s = new String("xyz"); 创建了几个实例?
通过以上的分析,我们会发现,每在这道题目的题干上每加一个定语,这道题目就会有不同的答案。
是否考虑类加载过程,是否考虑JVM优化,是否包括对应的oop实例等等等等,每个点都值得聊一聊的。
下次有人问你,你不妨把这篇的文章分享给他。
写在最后
为了写这一篇文章,我翻看了很多@RednaxelaFX前辈和周志明前辈的博客,过程中收益良多。在这里感谢前辈们为国内JVM的科普与发展做出的贡献!
还有一个很有趣的故事,我在查找“如何通过HSDB来了解String”相关资料的时候,看到一篇写的很好的文章,惊呼国内还有这么多低调的大神,后来添加了文章旁边的公众号,发现这个大神原来是PerfMa的创始人“寒泉子”李嘉鹏前辈,冒犯了冒犯了!
最后的最后
本着对每一篇发出去的文章负责的原则,文中涉及知识理论,我都会尽量在官方文档和权威书籍找到并加以验证。但即使这样,我也不能保证文中每个点都是正确的,如果你发现错误之处,欢迎指出,我会对其修正。
创作不易,你的正反馈对我来说非常重要!点个赞,点个再看,点个关注甚至评论区发送一条666都是对我最大的支持!
我是CoderW,一个普通的程序员。
谢谢你的阅读,我们下期再见
文中涉及代码:https://github.com/xiaoyingzhi/blog
JVM Spec Java SE 8Edition:https://docs.oracle.com/javase/specs/jvms/se8/jvms8.pdf
参考文章:http://isfeasible.cn/posts/view/5b84b6ab3957bb300a5bca94

 浙公网安备 33010602011771号
浙公网安备 33010602011771号