pytorch Tensorboard
!!!笔记中引入的图片已丢失,请直接访问我的csdn账号观看
TensorBoard 简介
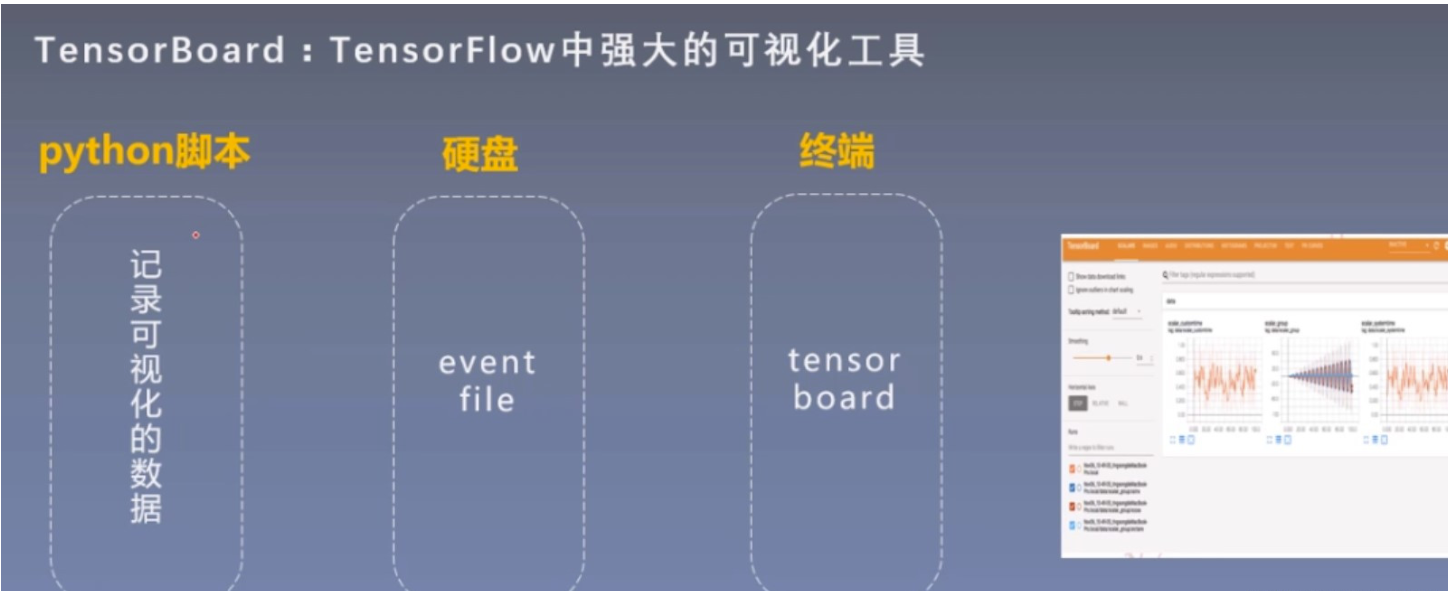
TensorBoard : 是TnsorFlow中强大的可视化工具。
支持标量、图像、文本、音频、视频和Embedding等多种数据可视化
TensorBoard的运行机制
在学习TensorBoard之前,我们要回顾一下Tensor Board的运行机制:
-
首先在Python脚本里 记录要可视化的数据(想监控的哪些数据)
-
然后把这些数据以event file的形式存储到硬盘中
-
最后在终端读取event file在tensorboard可视化,展示在web端
安装TensorBoard.
下述代码为保存event file的例子
import numpy as np
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter(comment='test_tensorboard')
for x in range(100):
writer.add_scalar('y=2x', x * 2, x)
writer.add_scalar('y=pow(2, x)', 2 ** x, x)
writer.add_scalars('data/scalar_group', {"xsinx": x * np.sin(x),
"xcosx": x * np.cos(x),
"arctanx": np.arctan(x)}, x)
writer.close()
上面具体保存的数据,我们先不关注,主要关注的是保存 event file 需要用到 SummaryWriter 类,这个类是用于保存数据的最重要的类,执行完后,会在当前文件夹生成一个runs的文件夹,里面保存的就是数据的 event file。
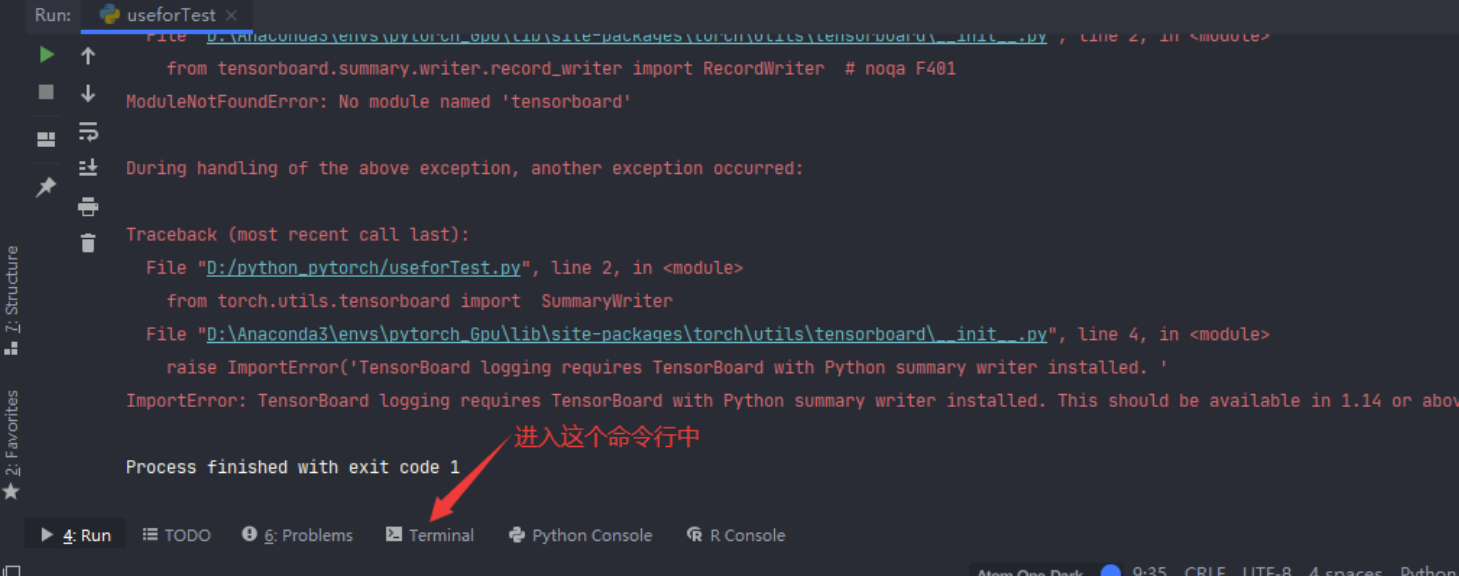
安装 tensorboard 需要在GPU这个虚拟环境里面进行安装,因此需要输入:conda activate pytorch_Gpu 来激活GPU虚拟环境
如果前面已经显示了 pytorch_gpu 类似这样的提示符,说明已经在虚拟环境中,不需要激活

接下来在命令行中输入 pip install tensorboard -i https://pypi.douban.com/simple [要安装的模块名称]
豆瓣镜像比较快
![[Pasted image 20201216142333.png]]
再次运行后发现。还是会报错
但这个时候再去安装 past 模块还会报错,应该去安装feature模块,这一点是比较坑的。
![[Pasted image 20201216142340.png]]
安装模块future
![[Pasted image 20201216142349.png]]
这个时候就可以正确运行了。
![[Pasted image 20201216142356.png]]
然后在命令行中输入tensorboard --logdir=lesson5/runs启动 tensorboard 服务,其中lesson5/runs是runs文件夹的路径。然后命令行会显示 tensorboard 的访问地址:
![[Pasted image 20201216142405.png]]
![[Pasted image 20201216142410.png]]
![[Pasted image 20201216142417.png]]
最上面的一栏显示的是数据类型,由于我们在代码中只记录了 scalar 类型的数据,因此只显示SCALARS。
右上角有一些功能设置
![[Pasted image 20201216142427.png]]
点击INACTIVE显示我们没有记录的数据类型。设置里可以设置刷新 tensorboard 的间隔,在模型训练时可以实时监控数据的变化。
左边的菜单栏如下,点击Show data download links可以展示每个图的下载按钮,如果一个图中有多个数据,需要选中需要下载的曲线,然后下载,格式有 csv和json可选。
![[Pasted image 20201216142435.png]]
第二个选项Ignore outliers in chart scaling可以设置是否忽略离群点,在y_pow_2_x中,数据的尺度达到了 \(10^{18}\),勾选Ignore outliers in chart scaling后\(y\)轴的尺度下降到\(10^{17}\)。
Soothing 是对图像进行平滑,下图中,颜色较淡的阴影部分才是真正的曲线数据,Smoothing 设置为了 0.6,进行了平滑才展示为颜色较深的线。
![[Pasted image 20201216142442.png]]
Horizontal Axis表示横轴:STEP表示原始数据作为横轴,RELATIVE和WALL都是以时间作为横轴,单位是小时,RELATIVE是相对时间,WALL是绝对时间。
runs显示所有的 event file,可以选择展示某些 event file 的图像,其中正方形按钮是多选,圆形按钮是单选。
![[Pasted image 20201216142448.png]]
上面的搜索框可以根据 tags 来搜索数据对应的图像
![[Pasted image 20201216142455.png]]
SummaryWriter
在python脚本里 怎样记录想要可视化的数据?
- 需要SummaryWriter类
SummaryWriter
功能: 提供创建event file的高级接口
Class SummaryWriter(object)
def _init_(
self,
log_dir=None,
comment='',
purge_step=None,
max_queue=10,
flush_secs=120,
filename_suffix=''
)
主要属性:
-
log_dir : event file 输出文件夹
-
comment : 不指定log_dir时,文件名后缀
-
filename_suffix : event file 文件名后缀
解释:
三个属性都与要创建的路径有关
log_dir : event_file 输出文件夹,通常采用默认参数即不设置
- 若不设置log_dir,会在当前 .py 文件当前文件夹下创建1个runs文件夹
- 如: runs/Aug18_16-09-46_LAPTOP-73TM5PNOtest_tensorboard/event…
试验代码如下:
import os
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.tensorboard import SummaryWriter
import sys
hello_pytorch_DIR = os.path.abspath(os.path.dirname(__file__)+os.path.sep+".."+os.path.sep+"..")
sys.path.append(hello_pytorch_DIR)
from tools.common_tools import set_seed
set_seed(1) # 设置随机种子
log_dir = "./train_log/test_log_dir"
# writer = SummaryWriter(log_dir=log_dir, comment='_scalars', filename_suffix="12345678")
writer = SummaryWriter(comment='_scalars', filename_suffix="12345678")
for x in range(100):
writer.add_scalar('y=pow_2_x', 2 ** x, x)
writer.close()
运行后会生成train_log/test_log_dir文件夹,里面的 event file 文件名后缀是12345678。
但是我们指定了log_dir,comment参数没有生效。如果想要comment参数生效,把SummaryWriter的初始化改为writer = SummaryWriter(comment='_scalars', filename_suffix="12345678"),生成的文件夹如下,runs里的子文件夹后缀是_scalars。
![[Pasted image 20201216142506.png]]
实验:
设置log_dir ,创建出来的文件有什么特点?
![[Pasted image 20201216142515.png]]
不设置Log_dir,创建出来的文件有什么特点?
![[Pasted image 20201216142523.png]]
通常不会采取默认形式,而是要设置log_dir的具体路径,保证代码和训练数据隔离开来,便于管理
add_scalar && add_scalars
学习了怎样event file 路径,接下来学习具体的方法
add_scalar
功能: 记录标量
add_scalar(
tag,
scalar_value,
global_step=None,
walltime=None
)
主要属性:
-
tag : 图像的标签名,图的唯一标识
-
scalar_value : 要记录的标量
-
global_step : x轴 (通常以1个epoch 或iteration 为周期)
该方法使用受限,只能记录一条曲线;
但是在模型训练时,想要监控训练集和测试集曲线对比情况, add_scalar方法就不能使用了,因此还提供了add_scalars方法
add_scalars()
功能: 记录标量,可以绘制多条曲线
add_scalar(
main_tag,
tag_scalar_dict,
global_step=None,
walltime=None
)
主要属性:
-
main_tag: 该图像的标签名
-
tag_scalar_dict : 利用字典的形式记录多条曲线,字典dict的key是变量的tag, value是变量的值。
实验
add_scalar
import os
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.tensorboard import SummaryWriter
import sys
hello_pytorch_DIR = os.path.abspath(os.path.dirname(__file__)+os.path.sep+".."+os.path.sep+"..")
sys.path.append(hello_pytorch_DIR)
from tools.common_tools import set_seed
set_seed(1) # 设置随机种子
max_epoch = 100
writer = SummaryWriter(comment='test_comment', filename_suffix="test_suffix")
for x in range(max_epoch):
writer.add_scalar('y=2x', x * 2, x)
writer.add_scalar('y=pow_2_x', 2 ** x, x)
writer.add_scalars('data/scalar_group', {"xsinx": x * np.sin(x),
"xcosx": x * np.cos(x)}, x)
writer.close()
![[Pasted image 20201216142534.png]]
add_scalars
![[Pasted image 20201216142541.png]]
add_histogram
观察参数的分布情况 即 统计、绘制 直方图
add_histogram(
tag,
values,
global_step=None,
bins='tensorflow',
walltime=None
)
主要属性:
-
tag: 图像的标签名
-
values: 要统计的参数(通常有权值、偏置及其对应的梯度)
-
global_step: y轴(是epoch数)
-
bins: 取直方图的bins (通常采用‘TensorFlow’)
代码:
import os
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.tensorboard import SummaryWriter
import sys
hello_pytorch_DIR = os.path.abspath(os.path.dirname(__file__)+os.path.sep+".."+os.path.sep+"..")
sys.path.append(hello_pytorch_DIR)
from tools.common_tools import set_seed
set_seed(1) # 设置随机种子
writer = SummaryWriter(comment='test_comment', filename_suffix="test_suffix")
for x in range(2):
np.random.seed(x)
data_union = np.arange(100)
data_normal = np.random.normal(size=1000)
writer.add_histogram('distribution union', data_union, x)
writer.add_histogram('distribution normal', data_normal, x)
plt.subplot(121).hist(data_union, label="union")
plt.subplot(122).hist(data_normal, label="normal")
plt.legend()
plt.show()
writer.close()
![[Pasted image 20201216142551.png]]
![[Pasted image 20201216142558.png]]
![[Pasted image 20201216142604.png]]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号