TCP/IP协议栈在Linux内核中的运行时序分析
一、Linux内核任务调度机制
Linux采用的是抢占式多任务模式,在Linux中进程对CPU的占用时间由操作系统决定的,具体为操作系统中的调度器。调度器决定了什么时候停止一个进程以便让其他进程有机会运行,同时挑选出一个其他的进程开始运行。
1.1 中断处理
中断是指在CPU正常运行期间,由于内外部事件或由程序预先安排的事件引起的 CPU 暂时停止正在运行的程序,转而为该内部或外部事件或预先安排的事件服务的程序中去,服务完毕后再返回去继续运行被暂时中断的程序。Linux中通常分为外部中断(又叫硬件中断)和内部中断(又叫异常)。
软件对硬件进行配置后,软件期望等待硬件的某种状态,这里有两种方式,一种是轮询(polling): CPU 不断的去读硬件状态。另一种是当硬件完成某种事件后,给 CPU 一个中断,让 CPU 停下手上的事情,去处理这个中断。很显然,中断的交互方式提高了系统的吞吐。
当 CPU 收到一个中断 (IRQ)的时候,会去执行该中断对应的处理函数(ISR)。普通情况下,会有一个中断向量表,向量表中定义了 CPU 对应的每一个外设资源的中断处理程序的入口,当发生对应的中断的时候, CPU 直接跳转到这个入口执行程序。也就是中断上下文。
1.2 软中断(softirg)
软中断是随着SMP(share memory processor)的出现应运而生的,它也是tasklet实现的基础(tasklet实际上只是在软中断的基础上添加了一定的机制)。软中断一般是“可延迟函数”的总称,有时候也包括了tasklet。它的出现就是因为要满足上面所提出的上半部和下半部的区别,使得对时间不敏感的任务延后执行,而且可以在多个CPU上并行执行,使得总的系统效率可以更高。它的特性包括:
-
产生后并不是马上可以执行,必须要等待内核的调度才能执行。软中断不能被自己打断,只能被硬件中断打断(上半部)。
-
可以并发运行在多个CPU上(即使同一类型的也可以)。所以软中断必须设计为可重入的函数(允许多个CPU同时操作),因此也需要使用自旋锁来保护其数据结构。
1.3 tasklet
由于软中断必须使用可重入函数,这就导致设计上的复杂度变高,作为设备驱动程序的开发者来说,增加了负担。而如果某种应用并不需要在多个CPU上并行执行,那么软中断其实是没有必要的。因此诞生了弥补以上两个要求的tasklet。它具有以下特性:
-
一种特定类型的tasklet只能运行在一个CPU上,不能并行,只能串行执行。
-
多个不同类型的tasklet可以并行在多个CPU上。
-
软中断是静态分配的,在内核编译好之后,就不能改变。但tasklet就灵活许多,可以在运行时改变(比如添加模块时)。
tasklet是在两种软中断类型的基础上实现的,因此如果不需要软中断的并行特性,tasklet就是最好的选择。
1.4 工作队列(wq)
可延迟函数运行在中断上下文中(软中断的一个检查点就是do_IRQ退出的时候),于是导致了一些问题:软中断不能睡眠、不能阻塞。由于中断上下文出于内核态,没有进程切换,所以如果软中断一旦睡眠或者阻塞,将无法退出这种状态,导致内核会整个僵死。 于是出现了在内核态运行的工作队列。它也具有一些可延迟函数的特点(需要被激活和延后执行),但是能够能够在不同的进程间切换,以完成不同的工作。
二、TCP/IP协议栈
TCP/IP协议指的是使用 IP 进行通信时所必须用到的协议群的统称。具体来说,IP 或 ICMP、TCP 或 UDP、TELNET 或 FTP、以及 HTTP 等都属于 TCP/IP 协议。他们与 TCP 或 IP 的关系紧密,是互联网必不可少的组成部分。
TCP/IP 协议采用4层结构,分别是应用层、传输层、网络层和网络接口层,其中网络接口层对应OSI模型的数据链路层和物理层,在TCP/IP模型中,每一层都会调用下一层所提供的服务来完成特定的任务,同时也向上一层提供调用自己的接口。
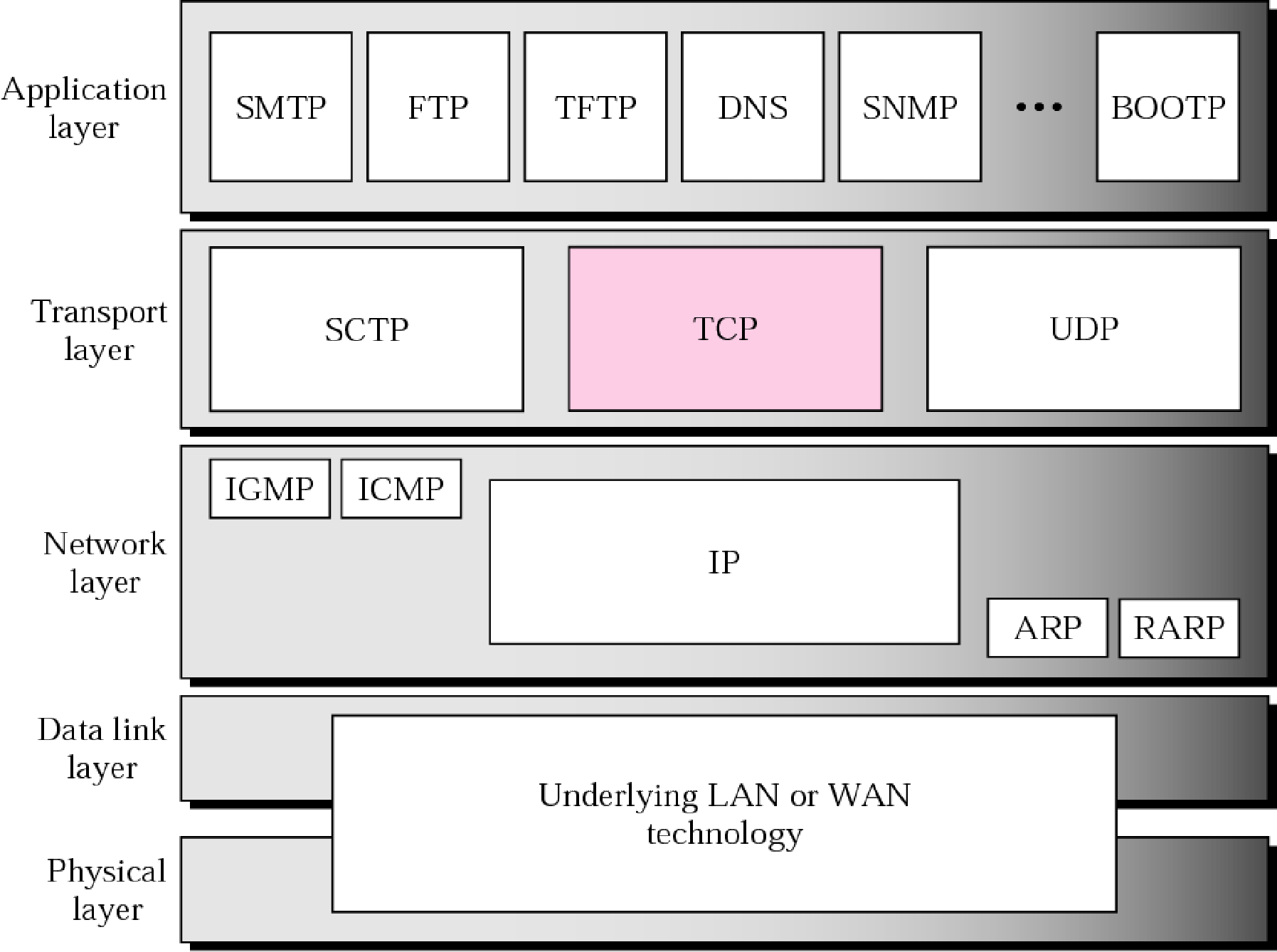
三、Socket
3.1 Socket简介
socket的中文名称叫做套接字。socket起源于Unix,都可以用“打开open –> 读写write/read –> 关闭close”模式来操作。Socket就是该模式的一个实现,socket即是一种特殊的文件,一些socket函数就是对其进行的操作(读/写IO、打开、关闭)。
Socket API里有个函数socket,它就是用来创建一个套接字。套接字设计的总体思路是,单个系统调用就可以创建任何套接字,因为套接字是相当笼统的。一旦套接字创建后,应用程序还需要调用其他函数来指定具体细节,例如调用socket将创建一个新的描述符条目。
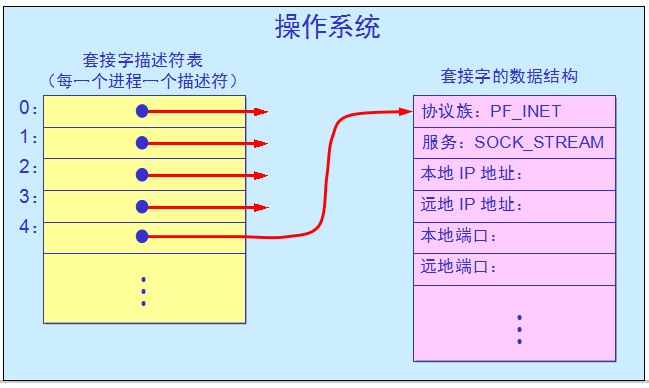
虽然套接字的内部数据结构包含很多字段,但是系统创建套接字后,大多数字段没有填写。应用程序创建套接字后在该套接字可以使用之前,必须调用其他的过程来填充这些字段。
3.2 基本的Socket接口函数
服务器端先初始化/创建Socket,然后与端口绑定/绑定地址(bind),对端口进行监听(listen),调用accept阻塞/等待连续,等待客户端连接。在这时如果有个客户端初始化一个Socket,然后连接服务器(connect),如果连接成功,这时客户端与服务器端的连接就建立了。客户端发送数据请求,服务器端接收请求并处理请求,然后把回应数据发送给客户端,客户端读取数据,最后关闭连接,一次交互结束。
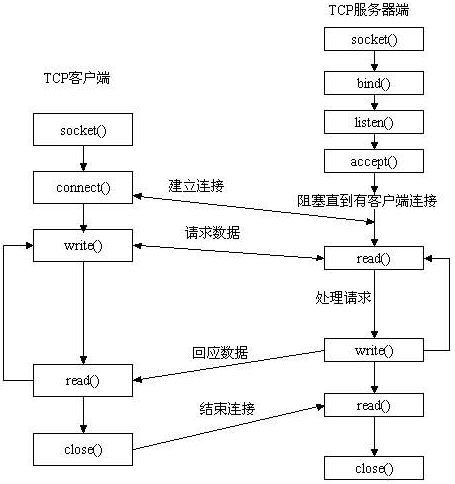
3.2.1 Socket函数
int socket(int protofamily, int type, int protocol);
socket函数对应于普通文件的打开操作。普通文件的打开操作返回一个文件描述字,而socket()用于创建一个socket描述符(socket descriptor),它唯一标识一个socket。这个socket描述字跟文件描述字一样,后续的操作都有用到它,把它作为参数,通过它来进行一些读写操作。
3.2.2 bind函数
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
bind()函数把一个地址族中的特定地址赋给socket,也可以说是绑定ip端口和socket。例如对应AF_INET、AF_INET6就是把一个ipv4或ipv6地址和端口号组合赋给socket。
通常服务器在启动的时候都会绑定一个众所周知的地址(如ip地址+端口号),用于提供服务,客户就可以通过它来接连服务器;而客户端就不用指定,有系统自动分配一个端口号和自身的ip地址组合。这就是为什么通常服务器端在listen之前会调用bind(),而客户端就不会调用,而是在connect()时由系统随机生成一个。
3.2.3 listen函数,connect函数
int listen(int sockfd, int backlog);
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
如果作为一个服务器,在调用socket()、bind()之后就会调用listen()来监听这个socket,如果客户端这时调用connect()发出连接请求,服务器端就会接收到这个请求。
listen函数的第一个参数即为要监听的socket描述字,第二个参数为相应socket可以排队的最大连接个数。socket()函数创建的socket默认是一个主动类型的,listen函数将socket变为被动类型的,等待客户的连接请求。
connect函数的第一个参数即为客户端的socket描述字,第二参数为服务器的socket地址,第三个参数为socket地址的长度。客户端通过调用connect函数来建立与TCP服务器的连接。成功返回0,若连接失败则返回-1。
3.2.4 accept函数
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
TCP服务器端依次调用socket()、bind()、listen()之后,就会监听指定的socket地址了。TCP客户端依次调用socket()、connect()之后就向TCP服务器发送了一个连接请求。TCP服务器监听到这个请求之后,就会调用accept()函数取接收请求,这样连接就建立好了。之后就可以开始网络I/O操作了,即类同于普通文件的读写I/O操作。
3.2.5 send函数,recv函数
ssize_t send(int sockfd, const void *buf, size_t len, int flags);
int recv(SOCKET s, char FAR *buf,int len, int flags);
不论是客户还是服务器应用程序都用send函数来向TCP连接的另一端发送数据。客户程序一般用send函数向服务器发送请求,而服务器则通常用send函数来向客户程序发送应答。
3.2.6 close函数
int close(int fd);
在服务器与客户端建立连接之后,会进行一些读写操作,完成了读写操作就要关闭相应的socket描述字,好比操作完打开的文件要调用fclose关闭打开的文件。
close一个TCP socket时,该socket标记设置为关闭,然后立即返回到调用进程。该描述字不能再由调用进程使用,也就是说不能再作为read或write的第一个参数。close操作只是使相应socket描述字的引用计数-1,只有当引用计数为0的时候,才会触发TCP客户端向服务器发送终止连接请求。
3.3 socket通信源代码
服务器端代码如下:
#include <stdio.h> /* perror */ #include <stdlib.h> /* exit */ #include <sys/types.h> /* WNOHANG */ #include <sys/wait.h> /* waitpid */ #include <string.h> /* memset */ #include <sys/time.h> #include <sys/types.h> #include <unistd.h> #include <fcntl.h> #include <sys/socket.h> #include <errno.h> #include <arpa/inet.h> #include <netdb.h> /* gethostbyname */ #define true 1 #define false 0 #define MYPORT 3490 /* 监听的端口 */ #define BACKLOG 10 /* listen的请求接收队列长度 */ int main() { int sockfd, new_fd; /* 监听端口,数据端口 */ struct sockaddr_in sa; /* 自身的地址信息 */ struct sockaddr_in their_addr; /* 连接对方的地址信息 */ unsigned int sin_size; if ((sockfd = socket(PF_INET, SOCK_STREAM, 0)) == -1) { perror("socket"); exit(1); } sa.sin_family = AF_INET; sa.sin_port = htons(MYPORT); /* 网络字节顺序 */ sa.sin_addr.s_addr = INADDR_ANY; /* 自动填本机IP */ memset(&(sa.sin_zero), 0, 8); /* 其余部分置0 */ if (bind(sockfd, (struct sockaddr *)&sa, sizeof(sa)) == -1) { perror("bind"); exit(1); } if (listen(sockfd, BACKLOG) == -1) { perror("listen"); exit(1); } /* 主循环 */ while (1) { sin_size = sizeof(struct sockaddr_in); new_fd = accept(sockfd, (struct sockaddr *)&their_addr, &sin_size); if (new_fd == -1) { perror("accept"); continue; } printf("Got connection from %s\n", inet_ntoa(their_addr.sin_addr)); if (fork() == 0) { /* 子进程 */ if (send(new_fd, "Hello, world!\n", 14, 0) == -1) perror("send"); close(new_fd); exit(0); } close(new_fd); /*清除所有子进程 */ while (waitpid(-1, NULL, WNOHANG) > 0); } close(sockfd); return true; }
客户端代码如下:
#include <stdio.h> /* perror */ #include <stdlib.h> /* exit */ #include <sys/types.h> /* WNOHANG */ #include <sys/wait.h> /* waitpid */ #include <string.h> /* memset */ #include <sys/time.h> #include <sys/types.h> #include <unistd.h> #include <fcntl.h> #include <sys/socket.h> #include <errno.h> #include <arpa/inet.h> #include <netdb.h> /* gethostbyname */ #define true 1 #define false 0 #define PORT 3490 /* Server的端口 */ #define MAXDATASIZE 100 /* 一次可以读的最大字节数 */ int main(int argc, char *argv[]) { int sockfd, numbytes; char buf[MAXDATASIZE]; struct hostent *he; /* 主机信息 */ struct sockaddr_in server_addr; /* 对方地址信息 */ if (argc != 2) { fprintf(stderr, "usage: client hostname\n"); exit(1); } /* get the host info */ if ((he = gethostbyname(argv[1])) == NULL) { /* 注意:获取DNS信息时,显示出错需要用herror而不是perror */ /* herror 在新的版本中会出现警告,已经建议不要使用了 */ perror("gethostbyname"); exit(1); } if ((sockfd = socket(PF_INET, SOCK_STREAM, 0)) == -1) { perror("socket"); exit(1); } server_addr.sin_family = AF_INET; server_addr.sin_port = htons(PORT); /* short, NBO */ server_addr.sin_addr = *((struct in_addr *)he->h_addr_list[0]); memset(&(server_addr.sin_zero), 0, 8); /* 其余部分设成0 */ if (connect(sockfd, (struct sockaddr *)&server_addr, sizeof(struct sockaddr)) == -1) { perror("connect"); exit(1); } if ((numbytes = recv(sockfd, buf, MAXDATASIZE, 0)) == -1) { perror("recv"); exit(1); } buf[numbytes] = '\0'; printf("Received: %s", buf); close(sockfd); return true; }
四、send过程
对于send函数,由于TCP是面向连接的,因此会有三次握手来建立TCP连接,即代表两个进程可以用send和recv通信。作为发送端,一定接收到了从用户程序发送数据的请求。接收到数据请求后,如果数据的大小超过一定长度,首先要对数据分段,将数据分成一个个的代码段,其次,TCP协议位于传输层,有响应的头部字段,在传输时肯定要加在数据前。TCP是没有能力直接通过物理链路发送出去的,所以它会把数据传递给网络层,网络层再封装,然后链路层、物理层,最后被发送出去。通过以上分析,send过程大致可以分为三个步骤,即数据分段、封装头部、传递给下一层。
4.1 应用层
建立socket连接之后,应用程序会使用send进行数据的发送。在内核中,send()被封装为sendto()。send()其实就是sendto()的一种特殊情况,而sendto()在内核的系统调用服务程序为sys_sendto。
SYSCALL_DEFINE6(sendto, int, fd, void __user *, buff, size_t, len, unsigned int, flags, struct sockaddr __user *, addr, int, addr_len) { return __sys_sendto(fd, buff, len, flags, addr, addr_len); } /* * Send a datagram down a socket. */ SYSCALL_DEFINE4(send, int, fd, void __user *, buff, size_t, len, unsigned int, flags) { return __sys_sendto(fd, buff, len, flags, NULL, 0); }
/* * Send a datagram to a given address. We move the address into kernel * space and check the user space data area is readable before invoking * the protocol. */ int __sys_sendto(int fd, void __user *buff, size_t len, unsigned int flags, struct sockaddr __user *addr, int addr_len) { struct socket *sock; struct sockaddr_storage address; int err; struct msghdr msg; struct iovec iov; int fput_needed; err = import_single_range(WRITE, buff, len, &iov, &msg.msg_iter); if (unlikely(err)) return err; sock = sockfd_lookup_light(fd, &err, &fput_needed); if (!sock) goto out; msg.msg_name = NULL; msg.msg_control = NULL; msg.msg_controllen = 0; msg.msg_namelen = 0; if (addr) { err = move_addr_to_kernel(addr, addr_len, &address); if (err < 0) goto out_put; msg.msg_name = (struct sockaddr *)&address; msg.msg_namelen = addr_len; } if (sock->file->f_flags & O_NONBLOCK) flags |= MSG_DONTWAIT; msg.msg_flags = flags; err = sock_sendmsg(sock, &msg); out_put: fput_light(sock->file, fput_needed); out: return err; }
__sys_sendto函数具体完成了一下三件事情:
-
通过fd获取了对应的
struct socket。 -
创建了用来描述要发送的数据的结构体
struct msghdr。
-
最后调用
sock_sendmsg来执行实际的发送。
int sock_sendmsg(struct socket *sock, struct msghdr *msg) { int err = security_socket_sendmsg(sock, msg, msg_data_left(msg)); return err ?: sock_sendmsg_nosec(sock, msg); } EXPORT_SYMBOL(sock_sendmsg);
4.2 传输层
继续追踪这个函数,会看到最终调用的是tcp_sendmsg,数据从应用层传递到了传输层。tcp_sendmsg实际调用了tcp_sendmsg_locked。在tcp_sendmsg_locked中,完成的是将所有的数据组织成发送队列,这个发送队列是struct sock结构中的一个域sk_write_queue,这个队列的每一个元素是一个skb,里面存放的就是待发送的数据。然后调用了tcp_push()函数。
int tcp_sendmsg(struct sock *sk, struct msghdr *msg, size_t size) { int ret; lock_sock(sk); ret = tcp_sendmsg_locked(sk, msg, size); release_sock(sk); return ret; } EXPORT_SYMBOL(tcp_sendmsg);
int tcp_sendmsg_locked(struct sock *sk, struct msghdr *msg, size_t size) { struct tcp_sock *tp = tcp_sk(sk); struct ubuf_info *uarg = NULL; struct sk_buff *skb; struct sockcm_cookie sockc; int flags, err, copied = 0; int mss_now = 0, size_goal, copied_syn = 0; int process_backlog = 0; bool zc = false; long timeo; flags = msg->msg_flags; if (flags & MSG_ZEROCOPY && size && sock_flag(sk, SOCK_ZEROCOPY)) { skb = tcp_write_queue_tail(sk); uarg = sock_zerocopy_realloc(sk, size, skb_zcopy(skb)); if (!uarg) { err = -ENOBUFS; goto out_err; } zc = sk->sk_route_caps & NETIF_F_SG; if (!zc) uarg->zerocopy = 0; } if (unlikely(flags & MSG_FASTOPEN || inet_sk(sk)->defer_connect) && !tp->repair) { err = tcp_sendmsg_fastopen(sk, msg, &copied_syn, size, uarg); if (err == -EINPROGRESS && copied_syn > 0) goto out; else if (err) goto out_err; } timeo = sock_sndtimeo(sk, flags & MSG_DONTWAIT); tcp_rate_check_app_limited(sk); /* is sending application-limited? */ /* Wait for a connection to finish. One exception is TCP Fast Open * (passive side) where data is allowed to be sent before a connection * is fully established. */ if (((1 << sk->sk_state) & ~(TCPF_ESTABLISHED | TCPF_CLOSE_WAIT)) && !tcp_passive_fastopen(sk)) { err = sk_stream_wait_connect(sk, &timeo); if (err != 0) goto do_error; } if (unlikely(tp->repair)) { if (tp->repair_queue == TCP_RECV_QUEUE) { copied = tcp_send_rcvq(sk, msg, size); goto out_nopush; } err = -EINVAL; if (tp->repair_queue == TCP_NO_QUEUE) goto out_err; /* 'common' sending to sendq */ } sockcm_init(&sockc, sk); if (msg->msg_controllen) { err = sock_cmsg_send(sk, msg, &sockc); if (unlikely(err)) { err = -EINVAL; goto out_err; } } /* This should be in poll */ sk_clear_bit(SOCKWQ_ASYNC_NOSPACE, sk); /* Ok commence sending. */ copied = 0; restart: mss_now = tcp_send_mss(sk, &size_goal, flags); err = -EPIPE; if (sk->sk_err || (sk->sk_shutdown & SEND_SHUTDOWN)) goto do_error; while (msg_data_left(msg)) { int copy = 0; skb = tcp_write_queue_tail(sk); if (skb) copy = size_goal - skb->len; if (copy <= 0 || !tcp_skb_can_collapse_to(skb)) { bool first_skb; new_segment: if (!sk_stream_memory_free(sk)) goto wait_for_sndbuf; if (unlikely(process_backlog >= 16)) { process_backlog = 0; if (sk_flush_backlog(sk)) goto restart; } first_skb = tcp_rtx_and_write_queues_empty(sk); skb = sk_stream_alloc_skb(sk, 0, sk->sk_allocation, first_skb); if (!skb) goto wait_for_memory; process_backlog++; skb->ip_summed = CHECKSUM_PARTIAL; skb_entail(sk, skb); copy = size_goal; /* All packets are restored as if they have * already been sent. skb_mstamp_ns isn't set to * avoid wrong rtt estimation. */ if (tp->repair) TCP_SKB_CB(skb)->sacked |= TCPCB_REPAIRED; } /* Try to append data to the end of skb. */ if (copy > msg_data_left(msg)) copy = msg_data_left(msg); /* Where to copy to? */ if (skb_availroom(skb) > 0 && !zc) { /* We have some space in skb head. Superb! */ copy = min_t(int, copy, skb_availroom(skb)); err = skb_add_data_nocache(sk, skb, &msg->msg_iter, copy); if (err) goto do_fault; } else if (!zc) { bool merge = true; int i = skb_shinfo(skb)->nr_frags; struct page_frag *pfrag = sk_page_frag(sk); if (!sk_page_frag_refill(sk, pfrag)) goto wait_for_memory; if (!skb_can_coalesce(skb, i, pfrag->page, pfrag->offset)) { if (i >= sysctl_max_skb_frags) { tcp_mark_push(tp, skb); goto new_segment; } merge = false; } copy = min_t(int, copy, pfrag->size - pfrag->offset); if (!sk_wmem_schedule(sk, copy)) goto wait_for_memory; err = skb_copy_to_page_nocache(sk, &msg->msg_iter, skb, pfrag->page, pfrag->offset, copy); if (err) goto do_error; /* Update the skb. */ if (merge) { skb_frag_size_add(&skb_shinfo(skb)->frags[i - 1], copy); } else { skb_fill_page_desc(skb, i, pfrag->page, pfrag->offset, copy); page_ref_inc(pfrag->page); } pfrag->offset += copy; } else { err = skb_zerocopy_iter_stream(sk, skb, msg, copy, uarg); if (err == -EMSGSIZE || err == -EEXIST) { tcp_mark_push(tp, skb); goto new_segment; } if (err < 0) goto do_error; copy = err; } if (!copied) TCP_SKB_CB(skb)->tcp_flags &= ~TCPHDR_PSH; WRITE_ONCE(tp->write_seq, tp->write_seq + copy); TCP_SKB_CB(skb)->end_seq += copy; tcp_skb_pcount_set(skb, 0); copied += copy; if (!msg_data_left(msg)) { if (unlikely(flags & MSG_EOR)) TCP_SKB_CB(skb)->eor = 1; goto out; } if (skb->len < size_goal || (flags & MSG_OOB) || unlikely(tp->repair)) continue; if (forced_push(tp)) { tcp_mark_push(tp, skb); __tcp_push_pending_frames(sk, mss_now, TCP_NAGLE_PUSH); } else if (skb == tcp_send_head(sk)) tcp_push_one(sk, mss_now); continue; wait_for_sndbuf: set_bit(SOCK_NOSPACE, &sk->sk_socket->flags); wait_for_memory: if (copied) tcp_push(sk, flags & ~MSG_MORE, mss_now, TCP_NAGLE_PUSH, size_goal); err = sk_stream_wait_memory(sk, &timeo); if (err != 0) goto do_error; mss_now = tcp_send_mss(sk, &size_goal, flags); } out: if (copied) { tcp_tx_timestamp(sk, sockc.tsflags); tcp_push(sk, flags, mss_now, tp->nonagle, size_goal); } out_nopush: sock_zerocopy_put(uarg); return copied + copied_syn; do_error: skb = tcp_write_queue_tail(sk); do_fault: tcp_remove_empty_skb(sk, skb); if (copied + copied_syn) goto out; out_err: sock_zerocopy_put_abort(uarg, true); err = sk_stream_error(sk, flags, err); /* make sure we wake any epoll edge trigger waiter */ if (unlikely(tcp_rtx_and_write_queues_empty(sk) && err == -EAGAIN)) { sk->sk_write_space(sk); tcp_chrono_stop(sk, TCP_CHRONO_SNDBUF_LIMITED); } return err; } EXPORT_SYMBOL_GPL(tcp_sendmsg_locked);
在tcp协议的头部有几个标志字段:URG、ACK、RSH、RST、SYN、FIN,tcp_push中会判断这个skb的元素是否需要push,如果需要就将tcp头部字段的push位置为一。
static void tcp_push(struct sock *sk, int flags, int mss_now, int nonagle, int size_goal) { struct tcp_sock *tp = tcp_sk(sk); struct sk_buff *skb; skb = tcp_write_queue_tail(sk); if (!skb) return; if (!(flags & MSG_MORE) || forced_push(tp)) tcp_mark_push(tp, skb); tcp_mark_urg(tp, flags); if (tcp_should_autocork(sk, skb, size_goal)) { /* avoid atomic op if TSQ_THROTTLED bit is already set */ if (!test_bit(TSQ_THROTTLED, &sk->sk_tsq_flags)) { NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPAUTOCORKING); set_bit(TSQ_THROTTLED, &sk->sk_tsq_flags); } /* It is possible TX completion already happened * before we set TSQ_THROTTLED. */ if (refcount_read(&sk->sk_wmem_alloc) > skb->truesize) return; } if (flags & MSG_MORE) nonagle = TCP_NAGLE_CORK; __tcp_push_pending_frames(sk, mss_now, nonagle); }
tcp_push调用了__tcp_push_pending_frames函数发送数据,而__tcp_push_pending_frames又调用了tcp_write_xmit来发送数据。
static bool tcp_write_xmit(struct sock *sk, unsigned int mss_now, int nonagle, int push_one, gfp_t gfp) { struct tcp_sock *tp = tcp_sk(sk); struct sk_buff *skb; unsigned int tso_segs, sent_pkts; int cwnd_quota; int result; bool is_cwnd_limited = false, is_rwnd_limited = false; u32 max_segs; sent_pkts = 0; tcp_mstamp_refresh(tp); if (!push_one) { /* Do MTU probing. */ result = tcp_mtu_probe(sk); if (!result) { return false; } else if (result > 0) { sent_pkts = 1; } } max_segs = tcp_tso_segs(sk, mss_now); while ((skb = tcp_send_head(sk))) { unsigned int limit; if (unlikely(tp->repair) && tp->repair_queue == TCP_SEND_QUEUE) { /* "skb_mstamp_ns" is used as a start point for the retransmit timer */ skb->skb_mstamp_ns = tp->tcp_wstamp_ns = tp->tcp_clock_cache; list_move_tail(&skb->tcp_tsorted_anchor, &tp->tsorted_sent_queue); tcp_init_tso_segs(skb, mss_now); goto repair; /* Skip network transmission */ } if (tcp_pacing_check(sk)) break; tso_segs = tcp_init_tso_segs(skb, mss_now); BUG_ON(!tso_segs); cwnd_quota = tcp_cwnd_test(tp, skb); if (!cwnd_quota) { if (push_one == 2) /* Force out a loss probe pkt. */ cwnd_quota = 1; else break; } if (unlikely(!tcp_snd_wnd_test(tp, skb, mss_now))) { is_rwnd_limited = true; break; } if (tso_segs == 1) { if (unlikely(!tcp_nagle_test(tp, skb, mss_now, (tcp_skb_is_last(sk, skb) ? nonagle : TCP_NAGLE_PUSH)))) break; } else { if (!push_one && tcp_tso_should_defer(sk, skb, &is_cwnd_limited, &is_rwnd_limited, max_segs)) break; } limit = mss_now; if (tso_segs > 1 && !tcp_urg_mode(tp)) limit = tcp_mss_split_point(sk, skb, mss_now, min_t(unsigned int, cwnd_quota, max_segs), nonagle); if (skb->len > limit && unlikely(tso_fragment(sk, skb, limit, mss_now, gfp))) break; if (tcp_small_queue_check(sk, skb, 0)) break; /* Argh, we hit an empty skb(), presumably a thread * is sleeping in sendmsg()/sk_stream_wait_memory(). * We do not want to send a pure-ack packet and have * a strange looking rtx queue with empty packet(s). */ if (TCP_SKB_CB(skb)->end_seq == TCP_SKB_CB(skb)->seq) break; if (unlikely(tcp_transmit_skb(sk, skb, 1, gfp))) break; repair: /* Advance the send_head. This one is sent out. * This call will increment packets_out. */ tcp_event_new_data_sent(sk, skb); tcp_minshall_update(tp, mss_now, skb); sent_pkts += tcp_skb_pcount(skb); if (push_one) break; } if (is_rwnd_limited) tcp_chrono_start(sk, TCP_CHRONO_RWND_LIMITED); else tcp_chrono_stop(sk, TCP_CHRONO_RWND_LIMITED); if (likely(sent_pkts)) { if (tcp_in_cwnd_reduction(sk)) tp->prr_out += sent_pkts; /* Send one loss probe per tail loss episode. */ if (push_one != 2) tcp_schedule_loss_probe(sk, false); is_cwnd_limited |= (tcp_packets_in_flight(tp) >= tp->snd_cwnd); tcp_cwnd_validate(sk, is_cwnd_limited); return false; } return !tp->packets_out && !tcp_write_queue_empty(sk); }
tcp_transmit_skb传输层发送数据的最后一个步骤,主要完成了两个工作,一是对TCP数据段的头部进行了处理,二是调用了网络层提供的发送接口queue_xmit,实现了数据的发送,然后数据从传输层传递到网络层。
4.3 网络层
ip_queue_xmit是ip层提供给tcp层发送回调,大多数tcp发送都会使用这个回调,tcp层使用tcp_transmit_skb封装了tcp头之后,调用该函数。
static inline int ip_queue_xmit(struct sock *sk, struct sk_buff *skb, struct flowi *fl) { return __ip_queue_xmit(sk, skb, fl, inet_sk(sk)->tos); }
ip_queue_xmit实际调用的是__ip_queue_xmit,网络层最后调用dev_queue_xmit向链路层发送数据包。
/* Note: skb->sk can be different from sk, in case of tunnels */ int __ip_queue_xmit(struct sock *sk, struct sk_buff *skb, struct flowi *fl, __u8 tos) { struct inet_sock *inet = inet_sk(sk); struct net *net = sock_net(sk); struct ip_options_rcu *inet_opt; struct flowi4 *fl4; struct rtable *rt; struct iphdr *iph; int res; /* Skip all of this if the packet is already routed, * f.e. by something like SCTP. */ rcu_read_lock(); inet_opt = rcu_dereference(inet->inet_opt); fl4 = &fl->u.ip4; rt = skb_rtable(skb); if (rt) goto packet_routed; /* Make sure we can route this packet. */ rt = (struct rtable *)__sk_dst_check(sk, 0); if (!rt) { __be32 daddr; /* Use correct destination address if we have options. */ daddr = inet->inet_daddr; if (inet_opt && inet_opt->opt.srr) daddr = inet_opt->opt.faddr; /* If this fails, retransmit mechanism of transport layer will * keep trying until route appears or the connection times * itself out. */ rt = ip_route_output_ports(net, fl4, sk, daddr, inet->inet_saddr, inet->inet_dport, inet->inet_sport, sk->sk_protocol, RT_CONN_FLAGS_TOS(sk, tos), sk->sk_bound_dev_if); if (IS_ERR(rt)) goto no_route; sk_setup_caps(sk, &rt->dst); } skb_dst_set_noref(skb, &rt->dst); packet_routed: if (inet_opt && inet_opt->opt.is_strictroute && rt->rt_uses_gateway) goto no_route; /* OK, we know where to send it, allocate and build IP header. */ skb_push(skb, sizeof(struct iphdr) + (inet_opt ? inet_opt->opt.optlen : 0)); skb_reset_network_header(skb); iph = ip_hdr(skb); *((__be16 *)iph) = htons((4 << 12) | (5 << 8) | (tos & 0xff)); if (ip_dont_fragment(sk, &rt->dst) && !skb->ignore_df) iph->frag_off = htons(IP_DF); else iph->frag_off = 0; iph->ttl = ip_select_ttl(inet, &rt->dst); iph->protocol = sk->sk_protocol; ip_copy_addrs(iph, fl4); /* Transport layer set skb->h.foo itself. */ if (inet_opt && inet_opt->opt.optlen) { iph->ihl += inet_opt->opt.optlen >> 2; ip_options_build(skb, &inet_opt->opt, inet->inet_daddr, rt, 0); } ip_select_ident_segs(net, skb, sk, skb_shinfo(skb)->gso_segs ?: 1); /* TODO : should we use skb->sk here instead of sk ? */ skb->priority = sk->sk_priority; skb->mark = sk->sk_mark; res = ip_local_out(net, sk, skb); rcu_read_unlock(); return res; no_route: rcu_read_unlock(); IP_INC_STATS(net, IPSTATS_MIB_OUTNOROUTES); kfree_skb(skb); return -EHOSTUNREACH; } EXPORT_SYMBOL(__ip_queue_xmit);
4.4 数据链路层
网络层调用dev_queue_xmit进入数据链路层的处理流程,但是实际上调用的是__dev_queue_xmit。
int dev_queue_xmit(struct sk_buff *skb) { return __dev_queue_xmit(skb, NULL); } EXPORT_SYMBOL(dev_queue_xmit);
static int xmit_one(struct sk_buff *skb, struct net_device *dev, struct netdev_queue *txq, bool more) { unsigned int len; int rc; if (dev_nit_active(dev)) dev_queue_xmit_nit(skb, dev); len = skb->len; trace_net_dev_start_xmit(skb, dev); rc = netdev_start_xmit(skb, dev, txq, more); trace_net_dev_xmit(skb, rc, dev, len); return rc; }
static int __dev_queue_xmit(struct sk_buff *skb, struct net_device *sb_dev) { struct net_device *dev = skb->dev; struct netdev_queue *txq; struct Qdisc *q; int rc = -ENOMEM; bool again = false; skb_reset_mac_header(skb); if (unlikely(skb_shinfo(skb)->tx_flags & SKBTX_SCHED_TSTAMP)) __skb_tstamp_tx(skb, NULL, skb->sk, SCM_TSTAMP_SCHED); /* Disable soft irqs for various locks below. Also * stops preemption for RCU. */ rcu_read_lock_bh(); skb_update_prio(skb); qdisc_pkt_len_init(skb); #ifdef CONFIG_NET_CLS_ACT skb->tc_at_ingress = 0; # ifdef CONFIG_NET_EGRESS if (static_branch_unlikely(&egress_needed_key)) { skb = sch_handle_egress(skb, &rc, dev); if (!skb) goto out; } # endif #endif /* If device/qdisc don't need skb->dst, release it right now while * its hot in this cpu cache. */ if (dev->priv_flags & IFF_XMIT_DST_RELEASE) skb_dst_drop(skb); else skb_dst_force(skb); txq = netdev_core_pick_tx(dev, skb, sb_dev); q = rcu_dereference_bh(txq->qdisc); trace_net_dev_queue(skb); if (q->enqueue) { rc = __dev_xmit_skb(skb, q, dev, txq); goto out; } /* The device has no queue. Common case for software devices: * loopback, all the sorts of tunnels... * Really, it is unlikely that netif_tx_lock protection is necessary * here. (f.e. loopback and IP tunnels are clean ignoring statistics * counters.) * However, it is possible, that they rely on protection * made by us here. * Check this and shot the lock. It is not prone from deadlocks. *Either shot noqueue qdisc, it is even simpler 8) */ if (dev->flags & IFF_UP) { int cpu = smp_processor_id(); /* ok because BHs are off */ if (txq->xmit_lock_owner != cpu) { if (dev_xmit_recursion()) goto recursion_alert; skb = validate_xmit_skb(skb, dev, &again); if (!skb) goto out; HARD_TX_LOCK(dev, txq, cpu); if (!netif_xmit_stopped(txq)) { dev_xmit_recursion_inc(); skb = dev_hard_start_xmit(skb, dev, txq, &rc); dev_xmit_recursion_dec(); if (dev_xmit_complete(rc)) { HARD_TX_UNLOCK(dev, txq); goto out; } } HARD_TX_UNLOCK(dev, txq); net_crit_ratelimited("Virtual device %s asks to queue packet!\n", dev->name); } else { /* Recursion is detected! It is possible, * unfortunately */ recursion_alert: net_crit_ratelimited("Dead loop on virtual device %s, fix it urgently!\n", dev->name); } } rc = -ENETDOWN; rcu_read_unlock_bh(); atomic_long_inc(&dev->tx_dropped); kfree_skb_list(skb); return rc; out: rcu_read_unlock_bh(); return rc; }
五、recv过程
5.1 应用层
recv函数是recvfrom的特殊情况,调用的也就是__sys_recvfrom,整个函数的调用路径与send非常类似。
/* * Receive a frame from the socket and optionally record the address of the * sender. We verify the buffers are writable and if needed move the * sender address from kernel to user space. */ int __sys_recvfrom(int fd, void __user *ubuf, size_t size, unsigned int flags, struct sockaddr __user *addr, int __user *addr_len) { struct socket *sock; struct iovec iov; struct msghdr msg; struct sockaddr_storage address; int err, err2; int fput_needed; err = import_single_range(READ, ubuf, size, &iov, &msg.msg_iter); if (unlikely(err)) return err; sock = sockfd_lookup_light(fd, &err, &fput_needed); if (!sock) goto out; msg.msg_control = NULL; msg.msg_controllen = 0; /* Save some cycles and don't copy the address if not needed */ msg.msg_name = addr ? (struct sockaddr *)&address : NULL; /* We assume all kernel code knows the size of sockaddr_storage */ msg.msg_namelen = 0; msg.msg_iocb = NULL; msg.msg_flags = 0; if (sock->file->f_flags & O_NONBLOCK) flags |= MSG_DONTWAIT; err = sock_recvmsg(sock, &msg, flags); if (err >= 0 && addr != NULL) { err2 = move_addr_to_user(&address, msg.msg_namelen, addr, addr_len); if (err2 < 0) err = err2; } fput_light(sock->file, fput_needed); out: return err; }
__sys_recvfrom调用了sock_recvmsg来接收数据,整个函数实际调用的是sock->ops->recvmsg(sock, msg, msg_data_left(msg), flags);,同样,根据tcp_prot结构的初始化,调用的其实是tcp_rcvmsg。
5.2 传输层
int tcp_recvmsg(struct sock *sk, struct msghdr *msg, size_t len, int nonblock, int flags, int *addr_len) { struct tcp_sock *tp = tcp_sk(sk); int copied = 0; u32 peek_seq; u32 *seq; unsigned long used; int err, inq; int target; /* Read at least this many bytes */ long timeo; struct sk_buff *skb, *last; u32 urg_hole = 0; struct scm_timestamping_internal tss; int cmsg_flags; if (unlikely(flags & MSG_ERRQUEUE)) return inet_recv_error(sk, msg, len, addr_len); if (sk_can_busy_loop(sk) && skb_queue_empty_lockless(&sk->sk_receive_queue) && (sk->sk_state == TCP_ESTABLISHED)) sk_busy_loop(sk, nonblock); lock_sock(sk); err = -ENOTCONN; if (sk->sk_state == TCP_LISTEN) goto out; cmsg_flags = tp->recvmsg_inq ? 1 : 0; timeo = sock_rcvtimeo(sk, nonblock); /* Urgent data needs to be handled specially. */ if (flags & MSG_OOB) goto recv_urg; if (unlikely(tp->repair)) { err = -EPERM; if (!(flags & MSG_PEEK)) goto out; if (tp->repair_queue == TCP_SEND_QUEUE) goto recv_sndq; err = -EINVAL; if (tp->repair_queue == TCP_NO_QUEUE) goto out; /* 'common' recv queue MSG_PEEK-ing */ } seq = &tp->copied_seq; if (flags & MSG_PEEK) { peek_seq = tp->copied_seq; seq = &peek_seq; } target = sock_rcvlowat(sk, flags & MSG_WAITALL, len); do { u32 offset; /* Are we at urgent data? Stop if we have read anything or have SIGURG pending. */ if (tp->urg_data && tp->urg_seq == *seq) { if (copied) break; if (signal_pending(current)) { copied = timeo ? sock_intr_errno(timeo) : -EAGAIN; break; } } /* Next get a buffer. */ last = skb_peek_tail(&sk->sk_receive_queue); skb_queue_walk(&sk->sk_receive_queue, skb) { last = skb; /* Now that we have two receive queues this * shouldn't happen. */ if (WARN(before(*seq, TCP_SKB_CB(skb)->seq), "TCP recvmsg seq # bug: copied %X, seq %X, rcvnxt %X, fl %X\n", *seq, TCP_SKB_CB(skb)->seq, tp->rcv_nxt, flags)) break; offset = *seq - TCP_SKB_CB(skb)->seq; if (unlikely(TCP_SKB_CB(skb)->tcp_flags & TCPHDR_SYN)) { pr_err_once("%s: found a SYN, please report !\n", __func__); offset--; } if (offset < skb->len) goto found_ok_skb; if (TCP_SKB_CB(skb)->tcp_flags & TCPHDR_FIN) goto found_fin_ok; WARN(!(flags & MSG_PEEK), "TCP recvmsg seq # bug 2: copied %X, seq %X, rcvnxt %X, fl %X\n", *seq, TCP_SKB_CB(skb)->seq, tp->rcv_nxt, flags); } /* Well, if we have backlog, try to process it now yet. */ if (copied >= target && !sk->sk_backlog.tail) break; if (copied) { if (sk->sk_err || sk->sk_state == TCP_CLOSE || (sk->sk_shutdown & RCV_SHUTDOWN) || !timeo || signal_pending(current)) break; } else { if (sock_flag(sk, SOCK_DONE)) break; if (sk->sk_err) { copied = sock_error(sk); break; } if (sk->sk_shutdown & RCV_SHUTDOWN) break; if (sk->sk_state == TCP_CLOSE) { /* This occurs when user tries to read * from never connected socket. */ copied = -ENOTCONN; break; } if (!timeo) { copied = -EAGAIN; break; } if (signal_pending(current)) { copied = sock_intr_errno(timeo); break; } } tcp_cleanup_rbuf(sk, copied); if (copied >= target) { /* Do not sleep, just process backlog. */ release_sock(sk); lock_sock(sk); } else { sk_wait_data(sk, &timeo, last); } if ((flags & MSG_PEEK) && (peek_seq - copied - urg_hole != tp->copied_seq)) { net_dbg_ratelimited("TCP(%s:%d): Application bug, race in MSG_PEEK\n", current->comm, task_pid_nr(current)); peek_seq = tp->copied_seq; } continue; found_ok_skb: /* Ok so how much can we use? */ used = skb->len - offset; if (len < used) used = len; /* Do we have urgent data here? */ if (tp->urg_data) { u32 urg_offset = tp->urg_seq - *seq; if (urg_offset < used) { if (!urg_offset) { if (!sock_flag(sk, SOCK_URGINLINE)) { WRITE_ONCE(*seq, *seq + 1); urg_hole++; offset++; used--; if (!used) goto skip_copy; } } else used = urg_offset; } } if (!(flags & MSG_TRUNC)) { err = skb_copy_datagram_msg(skb, offset, msg, used); if (err) { /* Exception. Bailout! */ if (!copied) copied = -EFAULT; break; } } WRITE_ONCE(*seq, *seq + used); copied += used; len -= used; tcp_rcv_space_adjust(sk); skip_copy: if (tp->urg_data && after(tp->copied_seq, tp->urg_seq)) { tp->urg_data = 0; tcp_fast_path_check(sk); } if (used + offset < skb->len) continue; if (TCP_SKB_CB(skb)->has_rxtstamp) { tcp_update_recv_tstamps(skb, &tss); cmsg_flags |= 2; } if (TCP_SKB_CB(skb)->tcp_flags & TCPHDR_FIN) goto found_fin_ok; if (!(flags & MSG_PEEK)) sk_eat_skb(sk, skb); continue; found_fin_ok: /* Process the FIN. */ WRITE_ONCE(*seq, *seq + 1); if (!(flags & MSG_PEEK)) sk_eat_skb(sk, skb); break; } while (len > 0); /* According to UNIX98, msg_name/msg_namelen are ignored * on connected socket. I was just happy when found this 8) --ANK */ /* Clean up data we have read: This will do ACK frames. */ tcp_cleanup_rbuf(sk, copied); release_sock(sk); if (cmsg_flags) { if (cmsg_flags & 2) tcp_recv_timestamp(msg, sk, &tss); if (cmsg_flags & 1) { inq = tcp_inq_hint(sk); put_cmsg(msg, SOL_TCP, TCP_CM_INQ, sizeof(inq), &inq); } } return copied; out: release_sock(sk); return err; recv_urg: err = tcp_recv_urg(sk, msg, len, flags); goto out; recv_sndq: err = tcp_peek_sndq(sk, msg, len); goto out; } EXPORT_SYMBOL(tcp_recvmsg);
在连接建立后,若没有数据到来,接收队列为空,进程会在sk_busy_loop函数内循环等待。若有数据需要接收,则调用函数skb_copy_datagram_msg将接收到的数据拷贝到用户态,实际调用的是__skb_datagram_iter函数。
五、时序图
根据上述分析可以得出系统时序图如下图所示:
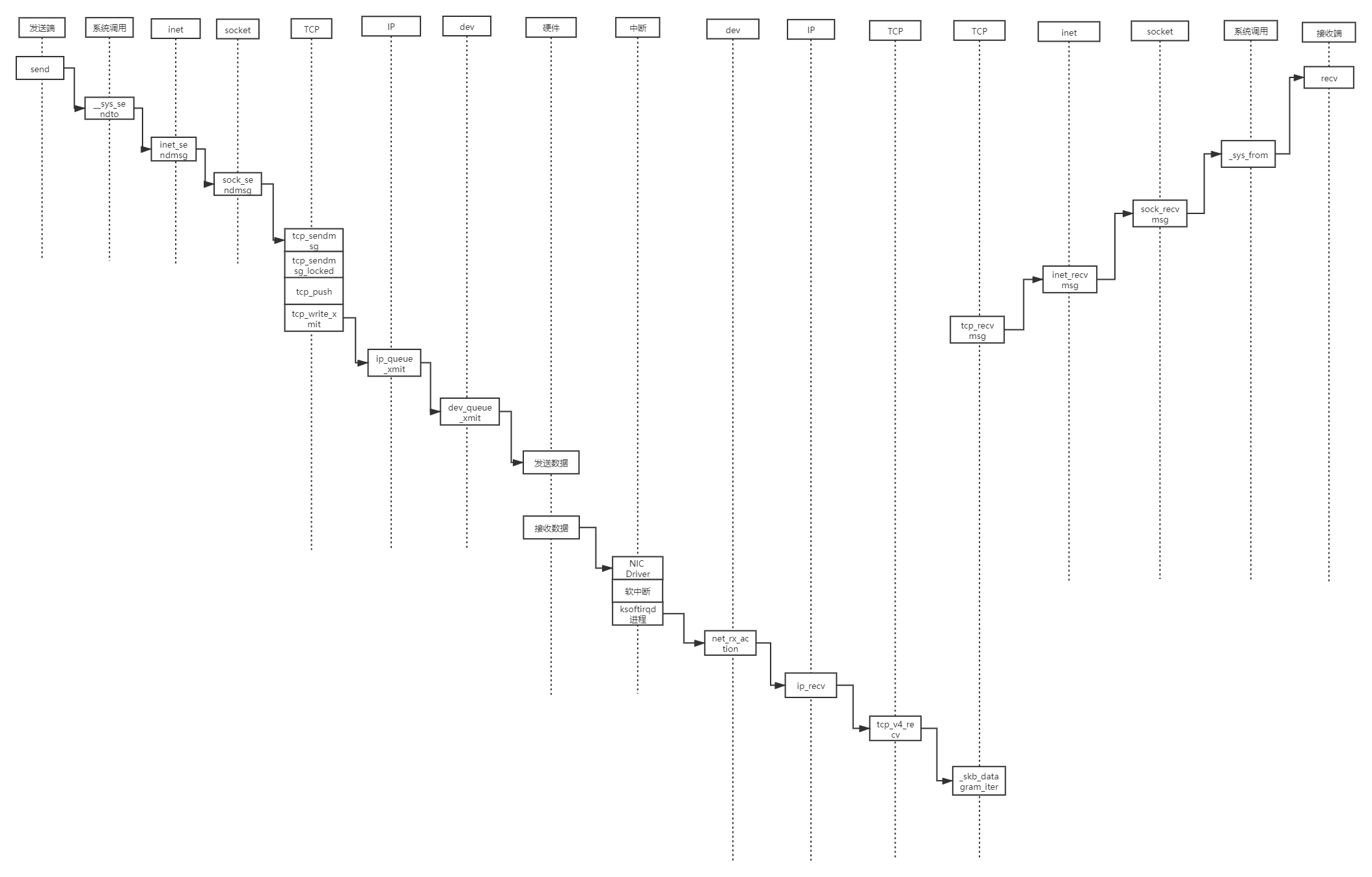

 浙公网安备 33010602011771号
浙公网安备 33010602011771号