Netty中的Decoder和Encoder组件
什么是编解码器
每个网络应用程序都必须定义如何解析在两个节点之间来回传输的原始字节,以及如何将其和目标应用程序的数据格式做相互转换;这种转换逻辑有编解码器处理,编解码器有编码器和解码器组成,它们每种都可以将字节流从一种格式转换为另一种格式;
编码器是将消息转换为适合传输的格式,而对应的解码器则是将网络字节流转换为应用程序的消息格式,因此,编码器操作出站数据,而解码器处理入站数据;
解码器
Netty中的解码器都是Inbound入站处理器类型,几乎都直接或者间接地实现了入站处理的顶层接口ChannelInboundHandler;
Netty所提供的解码器类覆盖了两个不同的用例:
- 将字节解码为消息,ByteToDecoder和ReplayingDecoder;
- 将一种消息类型解码为另一种格式,MessageToMessageDecoder;
什么时候会用到解码器?
每当需要为ChannelPipeline中的下一个ChannelInboundHandler转换入站数据时会用到;
ByteToMessageDecoder解码器
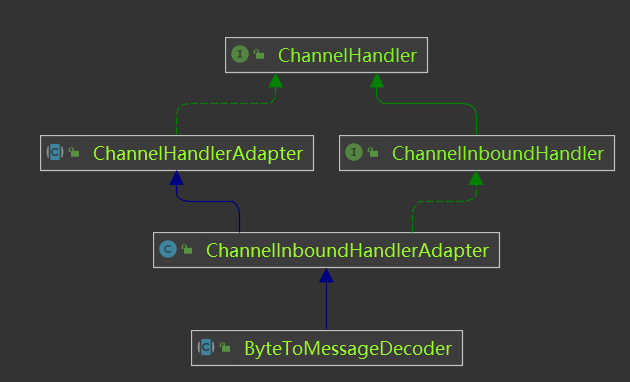
ByteToMessageDecoder是一个抽象类,它实现了解码处理的基础逻辑和流程;ByteToMessageDecoder继承自ChannelInboundHandlerAdapter适配器,它是一个入站处理器,用于完成从ByteBuf到Java对象的解码功能;
ByteToMessageDecoder是一个抽象类,它不能以实例化的方式创建对象,因此,直接通过ByteToMessageDecoder类并不能完成Bytebuf字节码到具体Java类型的解码,还需要通过ByteToMessageDecoder的具体实现完成;
其中ByteToByteToMessageDecoder中的解码方法为ByteToMessageDecoder#decode,这是一个抽象方法,ByteToByteToMessageDecoder中使用了模板方法的设计模式对调用decode方法做了整体的流程框架,那么如何将Bytebuf中的字节数据变成什么样的Object实例(包含多少个Object实例),则需要子类去完成,decode方法中的对ByteBuf的字节数据具体解码过程应由ByteToByteToMessageDecoder的子类实现,完成具体的二进制字节解码,然后会获取子类解码之后的Object结果,放入该解码器内部的结果列表List<Object>中,最终父类ByteToByteToMessageDecoder会负责将List<Object>中的元素逐个传递给下一个入站处理器;
即ByteToMessageDecoder解码的流程为:它先将上一站传过来的输入到Bytebuf中的数据进行解码,解码出一个List<Object>对象列表,然后迭代List<Object>列表,逐个将 Java对象传入下一个入站处理器;如下图:
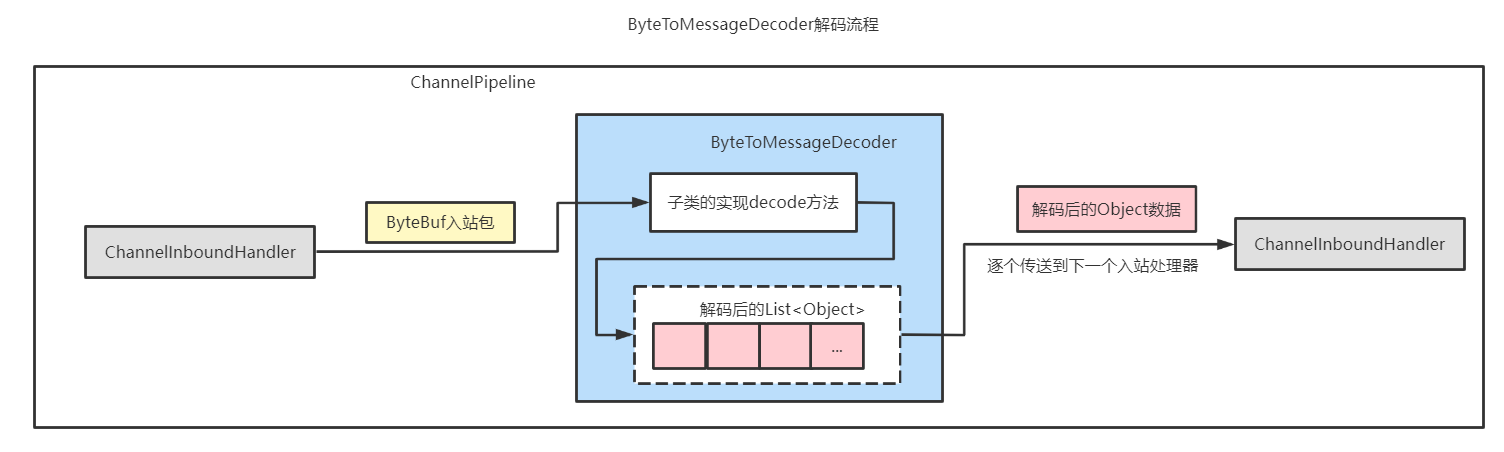
ByteToMessageDecoder的使用示例
使用实例:整数解码器,其功能是:将ByteBuf缓冲区中的字节,解码成 Integer整数类型;
使用的大致步骤如下:
- 定义一个新的整数解码器,让这个类继承ByteToMessageDecoder;
- 实现父类的decode方法,将ByteBuf缓冲区数据解码成一个个Integer对象;
- 在decode方法中,将解码后得到的Integer整数加入到父类的List<Object>实参中;
查看代码
public class Byte2IntegerDecoder extends ByteToMessageDecoder {
private final static Logger logger = LoggerFactory.getLogger(Byte2IntegerDecoder.class);
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
while (in.readableBytes() >= 4) {
int i = in.readInt();
logger.info("解码出一个整数:{}", i);
out.add(i);
}
}
}ByteToMessageDecoder的子类实现decode方法,从输入缓冲区中读取到整数,将一个个二进制数据解码成一个个整数,之后不断循环解码,将解码后的整数添加到decode方法的List<Object>参数中;
decode方法处理完成后,ByteToMessageDecoder会继续向后传递,将List<Object>结果中的数据一个一个传递到下一个入站处理器;
编写一个简单的配套处理器IntegerProcessHandler,用于处理Byte2IntegerDecoder解码之后的数据,即读取上一站的入站数据,把它转换成整数,并且输出;
查看代码
public class IntegerProcessHandler extends ChannelInboundHandlerAdapter {
private final static Logger logger = LoggerFactory.getLogger(IntegerProcessHandler.class);
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
Integer i = (Integer) msg;
logger.info("打印出一个整数:{}", i);
super.channelRead(ctx, msg);
}
}
测试这两个入站处理器,如下:
查看代码
public class Byte2IntegerDecoderTest {
@Test
public void testByte2IntegerDecoder() throws InterruptedException {
ChannelInitializer i = new ChannelInitializer<EmbeddedChannel>() {
protected void initChannel(EmbeddedChannel ch) {
ch.pipeline().addLast(new Byte2IntegerDecoder());
ch.pipeline().addLast(new IntegerProcessHandler());
}
};
EmbeddedChannel channel = new EmbeddedChannel(i);
for (int j = 0; j < 100; j++) {
ByteBuf buf = Unpooled.buffer();
buf.writeInt(j);
channel.writeInbound(buf);
}
channel.close().sync();
}
}调用writeInbound方法,模拟入站数据的写入,向嵌入式通道EmbeddedChannel写入100次ByteBuf入站缓冲区,每一次写入仅仅包含一个整数,模拟入站数据会被流水线上的两个入站处理器所接收和处理,这些入站的二进制字节被解码成一个个的整数,然后逐个输出;
注:对于编码器和解码器来说,一旦消息被编码或者解码,它就会被ReferenceCountUtil.release(message)方法,将之前的ByteBuf缓冲区的引用数减1,当引用数减至0,ByteBuf将自动释放;如果开发人员需要保留引用以便稍后使用,那么他可以调用ReferenceCountUtil.retain(message)方法,这将会增加该引用计数,从而防止该消息被释放;
ReplayingDecoder解码器
ReplayingDecoder扩展了ByteToMessageDecoder类使得开发人员不必调用readableBytes方法,它通过使用一个自定义的ByteBuf实现,ReplayingDecoderByteBuf,包装传入的ByteBuf实现了这一点,其将在内部执行该调用;
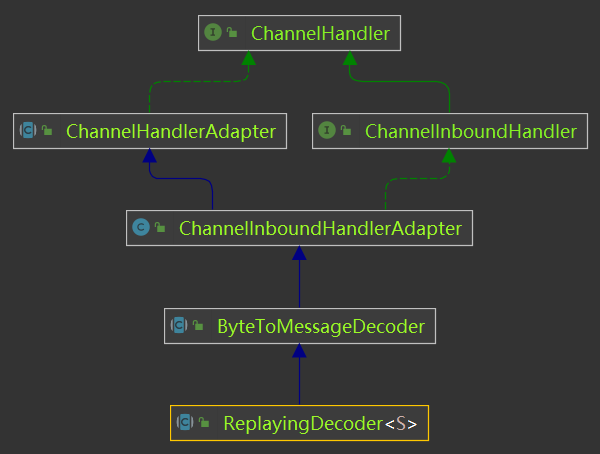
io.netty.handler.codec.ReplayingDecoder
![]()
类型参数S指定了用于状态管理的类型,其中Void代表不需要状态管理;
ReplayingDecoder的作用:
- 在读取 ByteBuf缓冲区的数据之前,需要检查缓冲区是否有足够的字节;
- 若 ByteBuf中有足够的字节,则会正常读取;反之,如果没有足够的字节,则会停止解码;
改写上一个的整数解码器,使用ReplayingDecoder基类编写整数解码器,则可以不用进行长度检测,示例如下:
查看代码
public class Byte2IntegerReplayDecoder extends ReplayingDecoder {
private final static Logger logger = LoggerFactory.getLogger(Byte2IntegerReplayDecoder.class);
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
int i = in.readInt();
logger.info("解码出一个整数", i);
out.add(i);
}
}
ReplayingDecoder内部定义了一个新的二进制缓冲区类ReplayingDecoderBuffer,对ByteBuf缓冲区进行了装饰,该装饰器在缓冲区真正读数据之前,首先会进行长度的判断,如果长度合格,则读取数据,否则抛出ReplayError,ReplayingDecoder捕获到ReplayError后,ReplayingDecoderBuffer会留着数据,等待下一次I/O事件到来时再读取;
public abstract class ReplayingDecoder<S> extends ByteToMessageDecoder {
static final Signal REPLAY = Signal.valueOf(ReplayingDecoder.class, "REPLAY");
// 缓冲区装饰器
private final ReplayingDecoderByteBuf replayable = new ReplayingDecoderByteBuf();
// 表示解码过程中的所处阶段,类型为泛型,默认为Object
private S state;
// 读指针检查点,默认为-1
private int checkpoint = -1;
// 默认的构造器,state值为空,没有用到该属性
protected ReplayingDecoder() {
this(null);
}
// 重载的构造器
protected ReplayingDecoder(S initialState) {
// 状态state的默认值为null
state = initialState;
}
// ...省略
}
io.netty.handler.codec.ReplayingDecoderByteBuf

ReplayingDecoderBuffer类继承了ByteBuf类型,包装了 ByteBuf类型的大部分读取方法,ReplayingDecoderBuffer对 ByteBuf类型的读取方法做了功能增强,主要是进行二进制数据长度的判断,如果长度不足,则抛出异常,这个异常会反过来被ReplayingDecoder基类所捕获,将解码工作停掉;
由于IP数据包会存在IP分片的可能,那么接收端收到的包和发送端所发送的包可能不是一样的,如下图:
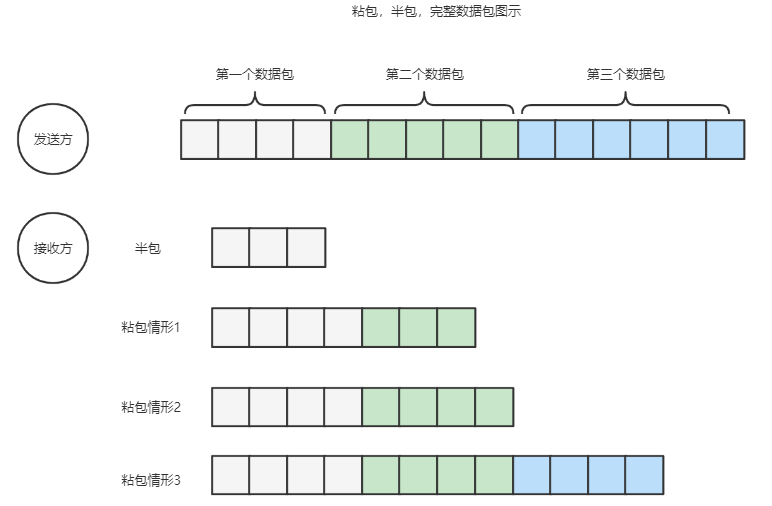
理论上可以使用ReplayingDecoder来解决,在进行数据解析时,如果发现当前ByteBuf中所有可读的数据不够,ReplayingDecoder会一直等待,直到可读数据是足够的,这都是ReplayingDecoder内部进行,通过与缓冲区装饰器ReplayingDecoderBuffer相互配合完成的;
举个例子,整数序列解码,并且将它们两两一组进行相加,而要完成这个例子,需要用到ReplayingDecoder的成员属性state;
因为这里整数序列的解码工作不可能通过一次完成,要完成两个整数的提取并相加就需要解码两次,每一次解码只能解码出一个整数,只有在第二个整数提取之后,然后才能求和,整个解码的工作才算完成,这里存在了两个阶段,具体的阶段需要使用state来记录;
整数的分包解码器示例
示例如下:
查看代码
public class IntegerAddDecoder extends ReplayingDecoder<IntegerAddDecoder.Status> {
enum Status {
PARSE_1, PARSE_2
}
private int first;
private int second;
public IntegerAddDecoder() {
//构造函数中,需要初始化父类的state属性,表示当前阶段
super(Status.PARSE_1);
}
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in,
List<Object> out) throws Exception {
switch (state()) {
case PARSE_1:
//从装饰器ByteBuf 中读取数据
first = in.readInt();
//第一步解析成功,
// 进入第二步,并且设置“读指针断点”为当前的读取位置
checkpoint(Status.PARSE_2);
break;
case PARSE_2:
second = in.readInt();
Integer sum = first + second;
out.add(sum);
checkpoint(Status.PARSE_1);
break;
default:
break;
}
}
}
查看代码
public class IntegerProcessHandler extends ChannelInboundHandlerAdapter {
private final static Logger logger = LoggerFactory.getLogger(IntegerProcessHandler.class);
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
Integer i = (Integer) msg;
logger.info("打印出一个整数:{}", i);
super.channelRead(ctx, msg);
}
}
查看代码
public class IntegerAddDecoderTester {
/**
* 整数解码器的使用实例
*/
@Test
public void testByteToIntegerDecoder() throws InterruptedException {
ChannelInitializer i = new ChannelInitializer<EmbeddedChannel>() {
protected void initChannel(EmbeddedChannel ch) {
ch.pipeline().addLast(new IntegerAddDecoder());
ch.pipeline().addLast(new IntegerProcessHandler());
}
};
EmbeddedChannel channel = new EmbeddedChannel(i);
for (int j = 0; j < 100; j++) {
ByteBuf buf = Unpooled.buffer();
buf.writeInt(j);
channel.writeInbound(buf);
}
channel.close().sync();
}
}IntegerAddDecoder类继承了ReplayingDecoder<IntegerAddDecoder.PHASE>,其后面的泛型实参为IntegerAddDecoder.PHASE自定义的状态类型是一个 enum枚举类型,用来作为泛型变量state的实际类型,该枚举值的有两个常量:
- PHASE_1:表示第一个阶段,在此阶段将读取第一个整数;
- PHASE_2:表示第二个阶段,在此阶段将读取后面的第二个整数,然后相加;
父类的成员变量state的值,可能为PHASE_1或者PHASE_2,代表当前的阶段,state值需要在构造函数中进行初始化,在这里的子类构造函数中将state初始化为第一个阶段;
每一个阶段一完成就通过checkpoint方法,把当前的state状态设置为新的PHASE枚举值,checkpoint方法类似于state属性的setter方法,checkpoint方法有两个作用:
- 设置state属性的值,更新一下当前的状态;
- 设置读指针检查点,即ReplayingDecoder提取二进制数据的ByteBuf缓冲区的readerIndex读指针;
读指针检查点是ReplayingDecoder类的成员属性checkpoint,它用于暂存内部ReplayingDecoderBuffer装饰器缓冲区的readerIndex读指针,有点类似于mark标记;当读数据时,一旦缓冲区可读的二进制数据不够,缓冲区装饰器ReplayingDecoderBuffer在抛出ReplayError异常之前,它会把readerIndex读指针的值还原到之前通过checkpoint设置的读指针检查点,在ReplayingDecoder下一次重新读取时,还会从读指针检查点的位置开始读取;
对于上面示例的IntegerAddDecoder的decode方法,该方法的逻辑大致如下:
- 判断当前解码器的state阶段是 Status.PARSE_1还是 Status.PARSE_2,根据对应的阶段进行读取处理;
- 每一次读取完成之后,还要切换阶段和保持当前读指针检查点,便于在可读数据不足之后帮助进行读指针恢复;
字符串的分包解码器的示例
在原理上,字符串分包解码和整数分包解码是一样的,不同的是整数的长度是固定的,目前在Java中是4个字节;而字符串的长度不是固定的,是可变长度的;
在Netty中进行字符串的传输,可以采用普通的Header-Content内容(即包头+包体格式)传输协议,处理如下:
- 在协议的Head部分放置字符串的字节长度,Head部分可以用一个整型int来描述;
- 在协议的Content部分,放置的则是字符串的字节数组;
示例如下:
查看代码
public class StringProcessHandler extends ChannelInboundHandlerAdapter {
private final static Logger logger = LoggerFactory.getLogger(StringProcessHandler.class);
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
if(msg instanceof String) {
String s = (String) msg;
logger.info("打印字符串:{}", s);
}else {
super.channelRead(ctx,msg);
}
}
}
查看代码
public class StringReplayDecoder
extends ReplayingDecoder<StringReplayDecoder.Status> {
private final static Logger logger = LoggerFactory.getLogger(StringReplayDecoder.class);
enum Status {
PARSE_1, PARSE_2
}
private int length;
private byte[] inBytes;
public StringReplayDecoder() {
//构造函数中,需要初始化父类的state属性,表示当前阶段
super(Status.PARSE_1);
}
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in,
List<Object> out) throws Exception {
switch (state()) {
case PARSE_1:
//第一步,从装饰器ByteBuf 中读取长度
length = in.readInt();
inBytes = new byte[length];
// 进入第二步,读取内容
// 并且设置“读指针断点”为当前的读取位置
checkpoint(Status.PARSE_2);
break;
case PARSE_2:
//第二步,从装饰器ByteBuf 中读取内容数组
in.readBytes(inBytes, 0, length);
out.add(new String(inBytes, StandardCharsets.UTF_8));
// 第二步解析成功,
// 进入第一步,读取下一个字符串的长度
// 并且设置“读指针断点”为当前的读取位置
checkpoint(Status.PARSE_1);
break;
default:
break;
}
}
}通过ReplayingDecoder解码器,可以正确地解码分包后的 ByteBuf数据包,但在实际的开发中,不太建议继承这个类,原因如下:
- 不是所有的ByteBuf操作都被ReplayingDecoderBuffer装饰类所支持,可能有些ByteBuf方法在ReplayingDecoder的decode实现方法中被使用时就会抛出ReplayError异常;
- 在数据解码逻辑复杂的应用场景,ReplayingDecoder在解码速度上相对较差,因为在ByteBuf中长度不够时, ReplayingDecoder会捕获一个 ReplayError异常,这时会把ByteBuf中的读指针还原到之前的读指针检查点(checkpoint),然后结束这次解析操作,等待下一次I/O读事件;在网络条件比较糟糕时,一个数据包的解析逻辑会被反复执行多次,此时解析过程是一个消耗 CPU的操作,所以解码速度上相对较差,ReplayingDecoder更多的是应用于数据解析逻辑简单的场景;
在数据解析复杂的应用场景,建议ByteToMessageDecoder或者其子类,它们会更加合适;这里继承ByteToMessageDecoder基类,实现一个定制的Header-Content协议字符串内容解码器,示例如下:
查看代码
public class StringIntegerHeaderDecoder extends ByteToMessageDecoder {
private final static Logger logger = LoggerFactory.getLogger(StringIntegerHeaderDecoder.class);
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
// 可读字节小于4,消息头还没读满,则返回
if (in.readableBytes() < 4) {
return;
}
// 消息头已经完整
// 在真正开始从缓冲区读取数据之前,调用markReaderIndex方法设置mark标记
in.markReaderIndex();
int length = in.readInt();
// 从缓冲区中读出消息头的大小,这会导致readIndex读指针变化
// 如果剩余长度不够消息体,还需要reset读指针,下一次从相同的位置处理
if (in.readableBytes() < length) {
// 读指针reset到消息头的readIndex位置处
in.resetReaderIndex();
}
// 读取数据,编码成字符串
byte[] inBytes = new byte[length];
in.readBytes(inBytes, 0, length);
out.add(new String(inBytes, StandardCharsets.UTF_8));
}
}示例中,在读取数据之前,需要调用markReaderIndex方法标记当前的位置指针,当可读内容不够,即readableBytes() < length时,需要调用resetReaderIndex方法将readerIndex读指针恢复到标记位置;
注:ByteToMessageDecoder内部有一个属性二进制字节累积器cumulation,用来保存没有解析完的二进制内容,因此ByteToMessageDecoder及其子类都是有状态,其实例不能在通道之间共享,在每次初始化通道的流水线时,都要重新创建一个ByteToMessageDecoder或者它的子类的实例;
MessageToMessageDecoder解码器
MessageToMessageDecoder抽象基类在两个消息格式之间进行转换,如将一种Java象解码成另外一种Java对象;
![]()
类型参数I指定了decode方法的输入参数msg的类型;
对于,ByteToMessageDecoder的入站消息类型固定就是二进制缓冲区ByteBuf类型的;而MessageToMessageDecoder的入站消息的类型是不固定的,入站消息的类型可以是任何的,因此需要指定泛型;
常用的内置解码器
Netty提供了不少开箱即用的Decoder解码器,在一般情况下能满足很多编解码应用场景的需求,这省去了开发Decoder的时间;
固定长度数据包解码器FixedLengthFrameDecoder
适用场景:每个接收到的数据包的长度,都是固定的;
如固定100个字节的数据包,在这种场景下,只需要把这个解码器加到流水线中,它会把入站ByteBuf数据包拆分成一个个长度为100字节的数据包,然后发往下一个入站处理器;
行分割数据包解码器LineBasedFrameDecoder
LineBasedFrameDecoder是使用换行符分割字符串的解码器,它依次遍历 ByteBuf数据包中的可读字节,判断在二进制字节流中是否存在换行符"\n"或"\r\n",如果存在,则以此位置为结束位置,把从可读索引到结束位置之间的字节作为解码成功后的 ByteBuf数据包;
LineBasedFrameDecoder支持配置一个最大长度值,表示解码出来的ByteBuf最大能包含的字节数,如果连续读取到最大长度后,仍然没有发现换行符,就会抛出异常;
使用示例如下:
查看代码
/**
* LineBasedFrameDecoder 使用实例
*/
@Test
public void testLineBasedFrameDecoder() throws InterruptedException {
ChannelInitializer i = new ChannelInitializer<EmbeddedChannel>() {
protected void initChannel(EmbeddedChannel ch) {
ch.pipeline().addLast(new LineBasedFrameDecoder(1024));
ch.pipeline().addLast(new StringDecoder());
ch.pipeline().addLast(new StringProcessHandler());
}
};
EmbeddedChannel channel = new EmbeddedChannel(i);
final String content = "netty demo.";
for (int j = 0; j < 100; j++) {
ByteBuf buf = Unpooled.buffer();
buf.writeBytes(content.getBytes(StandardCharsets.UTF_8));
buf.writeBytes("\r\n".getBytes(StandardCharsets.UTF_8));
channel.writeInbound(buf);
}
channel.close().sync();
}
自定义分隔符数据包解码器DelimiterBasedFrameDecode
DelimiterBasedFrameDecoder解码器不仅可以使用换行符,还可以将其他的特殊字符作为数据包的分隔符,如制表符"\t";
构造方法如下:

其中int maxFrameLength为解码的数据包的最大长度,stripDelimiter为解码后的数据包是否去掉分隔符,delimiter为分隔符;
使用实例如下:
查看代码
/**
* DelimiterBasedFrameDecoder 使用实例
*/
@Test
public void testDelimiterBasedFrameDecoder() throws InterruptedException, UnsupportedEncodingException {
final ByteBuf delimiter = Unpooled.copiedBuffer("\t".getBytes(StandardCharsets.UTF_8));
final String content = "netty demo!";
ChannelInitializer i = new ChannelInitializer<EmbeddedChannel>() {
protected void initChannel(EmbeddedChannel ch) {
ch.pipeline().addLast(
new DelimiterBasedFrameDecoder(1024, true, delimiter));
ch.pipeline().addLast(new StringDecoder());
ch.pipeline().addLast(new StringProcessHandler());
}
};
EmbeddedChannel channel = new EmbeddedChannel(i);
for (int j = 0; j < 100; j++) {
ByteBuf buf = Unpooled.buffer();
buf.writeBytes(content.getBytes(StandardCharsets.UTF_8));
buf.writeBytes("\t".getBytes(StandardCharsets.UTF_8));
channel.writeInbound(buf);
}
channel.close().sync();
}
自定义长度数据包解码器LengthFieldBasedFrameDecoder
LengthFieldBasedFrameDecoder为自定义长度数据包解码器,传输内容中的Length Field长度字段的值是指存放在数据包中要传输内容的字节数;对于普通基于Header-Content协议的内容传输,尽量用内置的LengthFieldBasedFrameDecoder来解码;
LengthFieldBasedFrameDecoder构造器如下:
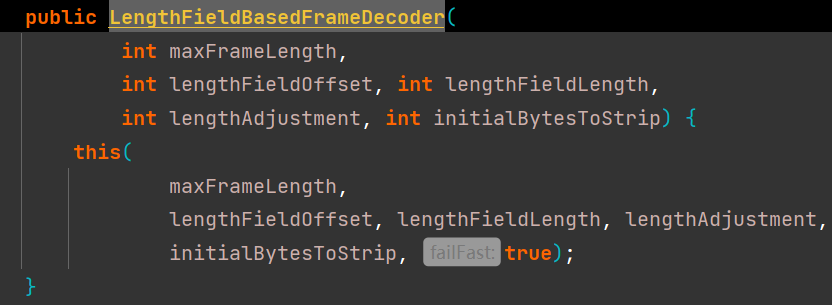
maxFrameLength:表示一个数据包最多可发送的最大长度;
lengthFieldOffset:长度字段偏移量,指的是长度字段位于整个数据包内部字节数组中的下标索引值;
lengthFieldLength:长度字段所占的字节数;如果长度字段是一个int整数,则为4,如果长度字段是一个short整数,则为2;
lengthAdjustment:长度的矫正值,在传输协议比较复杂的情况下,例如协议包含了长度字段、协议版本号、魔数等,那么解码时,就需要进行长度矫正;长度矫正值的计算公式为:(Content内容字段偏移量 – 长度字段偏移量 – 长度字段的字节数 - 长度字段中不包含Content内容长度的偏移量);
initialBytesToStrip:丢弃的起始字节数;在有效数据字段Content前面,如果还有一些其他字段的字节,作为最终的解析结果可以丢弃;
自定义长度解码器的构造参数,示例如下:
LengthFieldBasedFrameDecoder spliter = new LengthFieldBasedFrameDecoder(1024, 0, 4, 0, 4);第1个参数maxFrameLength设置为1024,表示数据包的最大长度为1024;
第2个参数lengthFieldOffset设置为0,表示长度字段的偏移量为0,即长度字段放在了最前面,处于数据包的起始位置;
第3个参数lengthFieldLength设置为4,表示长度字段的长度为4个字节,即表示内容长度的值占用数据包的4个字节;
第4个参数lengthAdjustment设置为0,长度调整值的计算公式为:Content内容字段偏移量 – 长度字段偏移量 – 长度字段的字节数 - 长度字段中不包含Content内容长度的偏移量,即实际的值为:4 – 0 – 4 - 0 = 0;
第5个参数initialBytesToStrip设置为4,表示获取最终内容Content的字节数组时,抛弃最前面的4个字节的非Content的数据;
对应的结果如下图:

Head-Content协议的数据包,除了长度和内容,在数据包中还可能包含了其他字段,如版本号;
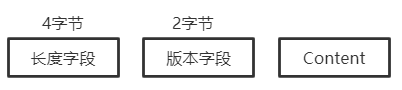
假设长度字段长度为4字节,版本字段为2字节,非Content字节长度为6字节,解析协议报文,参数配置如下:
第1个参数maxFrameLength设置为1024,表示数据包的最大长度为1024个字节;
第2个参数lengthFieldOffset设置为0,表示长度字段处于数据包的起始位置;
第3个参数lengthFieldLength设置为4,表示长度字段的长度为4个字节;
第4个参数lengthAdjustment设置为2,长度调整值的计算方法为:Content内容字段偏移量(即上图中的长度字段字节数 + 版本字段字节数) – 长度字段偏移量 – 长度字段的长度 - 长度字段中不包含Content内容长度的偏移量 = 6 – 0 – 4 - 0 = 2,即lengthAdjustment是夹在Content内容字段和长度字段中的部分,版本字段的长度;
第5个参数initialBytesToStrip设置为6,表示获取最终Content内容的字节数组时,抛弃最前面的6个字节非Content的数据;
示例如下:
查看代码
@Test
public void testLengthFieldBasedFrameDecoder() throws InterruptedException {
//定义一个 基于长度域解码器
final LengthFieldBasedFrameDecoder decoder = new LengthFieldBasedFrameDecoder(1024, 0, 4, 2, 6);
ChannelInitializer i = new ChannelInitializer<EmbeddedChannel>() {
protected void initChannel(EmbeddedChannel ch) {
ch.pipeline().addLast(decoder);
ch.pipeline().addLast(new StringDecoder(StandardCharsets.UTF_8));
ch.pipeline().addLast(new StringProcessHandler());
}
};
EmbeddedChannel channel = new EmbeddedChannel(i);
final short version = 10;
for (int j = 0; j < 100; j++) {
ByteBuf buf = Unpooled.buffer();
byte[] bytes = CONTENT.getBytes(StandardCharsets.UTF_8);
// 首先写入头部head,也就是后面的数据长度
buf.writeInt(bytes.length);
// 然后写入版本号
buf.writeShort(version);
// 然后写入content
buf.writeBytes(bytes);
channel.writeInbound(buf);
}
channel.close().sync();
}
LengthFieldBasedFrameDecoder更多使用案例
- Head-Content协议的数据包(长度为消息内容长度),解码后保留长度字段
创建带有Head-Content的16进制数据包,创建如下:
查看代码
@Test
public void test1() {
ByteBuf byteBuf = ByteBufAllocator.DEFAULT.heapBuffer();
final String str = "HELLO WORLD";
byteBuf.writeShort(str.length());
byteBuf.writeBytes(str.getBytes(StandardCharsets.UTF_8));
System.out.println(ByteBufUtil.hexDump(byteBuf));
}创建出的16进制为:00 0B 48 45 4C 4C 4F 20 57 4F 52 4C 44
设置lengthFieldOffset=0,lengthFieldLength=2,lengthAdjustment=0,initalBytesToStrip=0(不丢弃Head);
lengthFieldOffset=0,长度字段处于数据包的起始位置,lengthFieldLength=2,用2个字节表示消息内容长度,即长度的16进制数据包为:00 0B;字符串"HELLO WORLD"长度为11,即字符串内容的16进制数据包为:48 45 4C 4C 4F 20 57 4F 52 4C 44 ;
先读2个字节的消息内容长度,再读11个字节的消息内容长度;

把整个00 0B 48 45 4C 4C 4F 20 57 4F 52 4C 44 数据包发送到下一个处理器;
- Head-Content协议的数据包,解码后不保留保留长度字段
设置lengthFieldOffset=0,lengthFieldLength=2,lengthAdjustment=-2,initalBytesToStrip=0;
lengthFieldOffset=0,长度字段处于数据包的起始位置,lengthFieldLength=2,用2个字节表示消息内容长度,即长度的16进制数据包为:00 0B;字符串"HELLO WORLD"长度为11,即字符串内容的16进制数据包为:48 45 4C 4C 4F 20 57 4F 52 4C 44 ;initalBytesToStrip=2,丢弃前2个字节非消息内容的长度;
先读2个字节的消息内容长度,再读11个字节的消息内容长度;

把整个00 0B 48 45 4C 4C 4F 20 57 4F 52 4C 44 数据包发送到下一个处理器;
- Head-Content协议的数据包(长度为整个数据包长度),解码后保留长度字段
创建带有Head-Content的16进制数据包,其中Head部分包含的长度字段是属于整个数据包的长度,创建如下:
查看代码
@Test
public void test2() {
ByteBuf byteBuf = ByteBufAllocator.DEFAULT.heapBuffer();
final String str = "HELLO WORLD";
// short占2个字节
byteBuf.writeShort(str.length() + 2);
byteBuf.writeBytes(str.getBytes(StandardCharsets.UTF_8));
System.out.println(ByteBufUtil.hexDump(byteBuf));
}创建出的16进制为:00 0D 48 45 4C 4C 4F 20 57 4F 52 4C 44
设置lengthFieldOffset=0,lengthFieldLength=2,lengthAdjustment=-2,initalBytesToStrip=0(do not strip header);
lengthFieldOffset=0,长度字段处于数据包的起始位置,lengthFieldLength=2,用2个字节表示消息内容长度,即长度的16进制数据包为:00 0D;字符串"HELLO WORLD"长度为11,即字符串内容的16进制数据包为:48 45 4C 4C 4F 20 57 4F 52 4C 44 ;由于需要保留长度字段,此时的数据包从起始位置开始,设置lengthAdjustment=-2,其中Content内容字段偏移量 – 长度字段偏移量 – 长度字段的字节数 - 长度字段中不包含Content内容长度的偏移量(整个数据包长度是13,字符串str长度是11) = 2 - 0 - 2 - 2 = -2,如下图;
先读2个字节的消息内容长度,再读11个字节的消息内容长度;

把整个00 0D 48 45 4C 4C 4F 20 57 4F 52 4C 44 数据包发送到下一个处理器;
- Head-Content协议的数据包(Head有自定义字段,且在长度字段前面,长度为消息内容长度),解码后保留原数据包
创建带有Head-Content的16进制数据包,其中Head有自定义字段,且在长度字段前面,长度为消息内容长度,创建如下:
查看代码
@Test
public void test3() {
ByteBuf byteBuf = ByteBufAllocator.DEFAULT.heapBuffer();
final String str = "HELLO WORLD";
byteBuf.writeBytes("##".getBytes(StandardCharsets.UTF_8));
byteBuf.writeShort(str.length());
byteBuf.writeBytes(str.getBytes(StandardCharsets.UTF_8));
System.out.println(ByteBufUtil.hexDump(byteBuf));
System.out.println(byteBuf.readableBytes());
}创建出的16进制为:23 23 00 0B 48 45 4C 4C 4F 20 57 4F 52 4C 44
设置lengthFieldOffset=2,lengthFieldLength=2,lengthAdjustment=0,initalBytesToStrip=0(do not strip header);
lengthFieldOffset=2,长度字段处于自定义字段后,自定义字段为2 bytes,因此这里偏移2个字节;lengthFieldLength=2,用2个字节表示消息内容长度,即长度的16进制数据包为:00 0B;字符串"HELLO WORLD"长度为11,即字符串内容的16进制数据包为:48 45 4C 4C 4F 20 57 4F 52 4C 44 ;由于需要保留完整数据包,此时的数据包从起始位置开始,设置lengthAdjustment=0,其中Content内容字段偏移量 – 长度字段偏移量 – 长度字段的字节数 - 长度字段中不包含Content内容长度的偏移量 = 4 - 2 - 2 - 0 = 0,自定义字段+length+Actual Content为一个完整的数据包,如下图;

把整个23 23 00 0B 48 45 4C 4C 4F 20 57 4F 52 4C 44 数据包发送到下一个处理器;
- Head-Content协议的数据包(Head有自定义字段,且在长度字段后面,长度为消息内容长度),解码后保留原数据包
创建带有Head-Content的16进制数据包,其中Head有自定义字段,且在长度字段后面,长度为消息内容长度,创建如下:
查看代码
@Test
public void test4() {
ByteBuf byteBuf = ByteBufAllocator.DEFAULT.heapBuffer();
final String str = "HELLO WORLD";
byteBuf.writeShort(str.length());
byteBuf.writeBytes("##".getBytes(StandardCharsets.UTF_8));
byteBuf.writeBytes(str.getBytes(StandardCharsets.UTF_8));
System.out.println(ByteBufUtil.hexDump(byteBuf));
System.out.println(byteBuf.readableBytes());
}创建出的16进制为:00 0B 23 23 48 45 4C 4C 4F 20 57 4F 52 4C 44
设置lengthFieldOffset=0,lengthFieldLength=2,lengthAdjustment=2,initalBytesToStrip=0(do not strip header);
lengthFieldOffset=0,长度字段处于数据包的起始位置;lengthFieldLength=2,用2个字节表示消息内容长度,即长度的16进制数据包为:00 0B;字符串"HELLO WORLD"长度为11,即字符串内容的16进制数据包为:48 45 4C 4C 4F 20 57 4F 52 4C 44 ;由于需要保留完整数据包,此时的数据包从起始位置开始,不丢弃,自定义字段转16进制为:23 23,设置lengthAdjustment=2,其中Content内容字段偏移量 – 长度字段偏移量 – 长度字段的字节数 - 长度字段中不包含Content内容长度的偏移量 = 4 - 0 - 2 - 0 = 2,length+自定义字段+Actual Content为一个完整的数据包,如下图;

把整个00 0B 23 23 48 45 4C 4C 4F 20 57 4F 52 4C 44 数据包发送到下一个处理器;
- Head-Content协议的数据包(在长度字段前后均有自定义字段,长度为消息内容长度),解码后不保留长度字段及其前面的字段
创建带有Head-Content的16进制数据包,在长度字段前后均有自定义字段,长度为消息内容长度,解码后不保留长度字段及其前面的字段,创建如下:
查看代码
@Test
public void test5() {
ByteBuf byteBuf = ByteBufAllocator.DEFAULT.heapBuffer();
final String str = "HELLO WORLD";
byteBuf.writeBytes("##".getBytes(StandardCharsets.UTF_8));
byteBuf.writeShort(str.length());
byteBuf.writeBytes("||".getBytes(StandardCharsets.UTF_8));
byteBuf.writeBytes(str.getBytes(StandardCharsets.UTF_8));
System.out.println(ByteBufUtil.hexDump(byteBuf));
System.out.println(byteBuf.readableBytes());
}创建出的16进制为:23 23 00 0B 7C 7C 48 45 4C 4C 4F 20 57 4F 52 4C 44
设置lengthFieldOffset=2,lengthFieldLength=2,lengthAdjustment=2,initalBytesToStrip=4;
lengthFieldOffset=2,长度字段处于自定义字段1后,自定义字段为2 bytes,因此这里偏移2 bytes;lengthFieldLength=2,用2个字节表示消息内容长度,即长度的16进制数据包为:00 0B,长度为11;字符串"HELLO WORLD"长度为11,即字符串内容的16进制数据包为:48 45 4C 4C 4F 20 57 4F 52 4C 44 ;设置lengthAdjustment=4,其中Content内容字段偏移量 – 长度字段偏移量 – 长度字段的字节数 - 长度字段中不包含Content内容长度的偏移量 = 6 - 2 - 2 - 0 = 2;由于需要保留自定义字段2+Actual Content为一个完整的数据包,在自定义字段2之前的都需要丢弃,因此initalBytesToStrip=4,如下图;

把整个7C 7C 48 45 4C 4C 4F 20 57 4F 52 4C 44数据包发送到下一个处理器;
- Head-Content协议的数据包(在长度字段前后均有自定义字段,长度为整个数据包长度),解码后不保留长度字段及其前面的字段
创建带有Head-Content的16进制数据包,在长度字段前后均有自定义字段,长度为整个数据包长度,解码后不保留长度字段及其前面的字段,创建如下:
查看代码
@Test
public void test6() {
ByteBuf byteBuf = ByteBufAllocator.DEFAULT.heapBuffer();
final String str = "HELLO WORLD";
byteBuf.writeBytes("##".getBytes(StandardCharsets.UTF_8));
byteBuf.writeShort("##".length() + str.length() + "||".length());
byteBuf.writeBytes("||".getBytes(StandardCharsets.UTF_8));
byteBuf.writeBytes(str.getBytes(StandardCharsets.UTF_8));
System.out.println(ByteBufUtil.hexDump(byteBuf));
System.out.println(byteBuf.readableBytes());
}创建出的16进制为:23 23 00 0F 7C 7C 48 45 4C 4C 4F 20 57 4F 52 4C 44
设置lengthFieldOffset=2,lengthFieldLength=2,lengthAdjustment=-2,initalBytesToStrip=4;
lengthFieldOffset=2,长度字段处于自定义字段1后,自定义字段为2 bytes,因此这里偏移2 bytes;lengthFieldLength=2,用2个字节表示整个数据包长度,即长度的16进制数据包为:00 0F,长度为15;字符串"HELLO WORLD"长度为11,即字符串内容的16进制数据包为:48 45 4C 4C 4F 20 57 4F 52 4C 44 ;设置lengthAdjustment=-2,其中Content内容字段偏移量 – 长度字段偏移量 – 长度字段的字节数 - 长度字段中不包含Content内容长度的偏移量(整个数据包长度是15,字符串str长度是11) = 6 - 2 - 2 - 4 = 2;由于需要保留自定义字段2+Actual Content为一个完整的数据包,在自定义字段2之前的都需要丢弃,因此initalBytesToStrip=4,如下图;
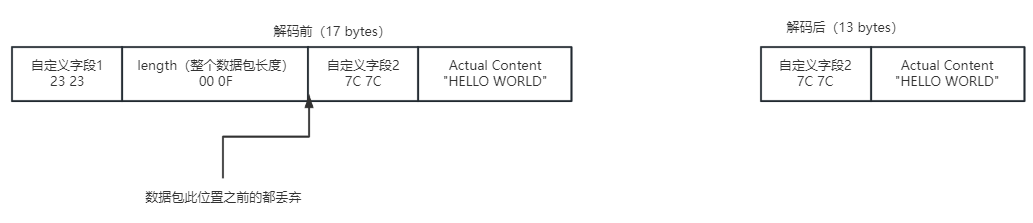
把整个7C 7C 48 45 4C 4C 4F 20 57 4F 52 4C 44数据包发送到下一个处理器;
编码器
在Netty的业务处理完成后,业务处理的结果往往是某个Java对象,需要编码成最终的ByteBuf二进制类型,通过流水线写入到底层的Java通道,这时需要用到Encoder;
编码器是ChannelOutboundHandler的具体实现类,一个编码器将出站对象编码之后,编码后数据将被传递到下一个 ChannelOutboundHandler出站处理器,进行后面出站处理;
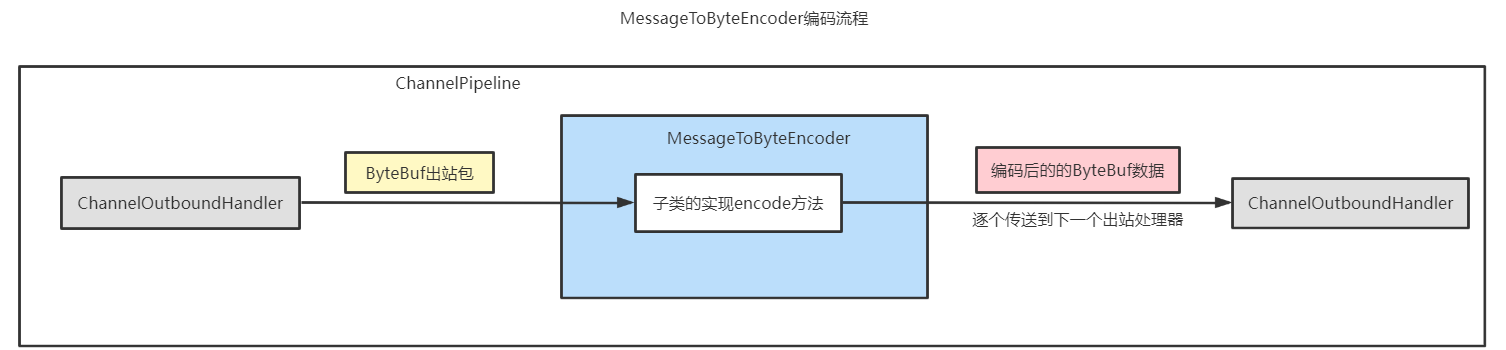
MessageToByteEncoder编码器
MessageToByteEncoder是一个编码器基类,它的功能是将一个消息格式编码成一个ByteBuf数据包;它是一个抽象类,仅仅实现了编码的基础流程,在编码过程中,通过调用encode抽象方法来完成;

不过encode编码方法是一个抽象方法,没有具体的encode编码逻辑实现,实现encode抽象方法的工作需要子类去完成,这种处理的方式与ByteToByteToMessageDecoder一样都是使用模板方法的设计模式;
![]()
encode方法的实现将入站数据泛型类型对象msg写入到ByteBuf out实参,编码完成后,基类MessageToByteEncoder会将输出的 ByteBuf数据包发送到下一站;
使用示例如下:
查看代码
public class Integer2ByteEncoder extends MessageToByteEncoder<Integer> {
private final static Logger logger = LoggerFactory.getLogger(Integer2ByteEncoder.class);
@Override
public void encode(ChannelHandlerContext ctx, Integer msg, ByteBuf out)
throws Exception {
out.writeInt(msg);
logger.info("encoder Integer = " + msg);
}
}
查看代码
@Test
public void testIntegerToByteDecoder() throws InterruptedException {
ChannelInitializer i = new ChannelInitializer<EmbeddedChannel>() {
protected void initChannel(EmbeddedChannel ch) {
ch.pipeline().addLast(new Integer2ByteEncoder());
}
};
EmbeddedChannel channel = new EmbeddedChannel(i);
for (int j = 0; j < 100; j++) {
channel.writeAndFlush(j);
}
//取得通道的出站数据帧
ByteBuf buf = channel.readOutbound();
while (null != buf) {
logger.info("o = {}", buf.readInt());
buf = channel.readOutbound();
}
channel.close().sync();
}
MessageToMessageEncoder编码器
MessageToMessageEncoder编码器,在子类的encode方法实现中,完成消息格式到目标消息格式的转换逻辑,在encode实现方法中,编码完成后,将解码后的目标对象加入到encode方法中的实参List<Object> out输出容器;
![]()
解码器和编码器的结合
在Netty中同一个类具有相互配套逻辑的编码器和解码器为Codec(编解码)类型,这些类型的类同时实现了ChannelInboundHandler和ChannelOutboundHandler接口;
ByteToMessageCodec编解码器
ByteToMessageCodec是一个抽象类,用于将ByteBuf数据包转换到消息格式的编解码器,ByteToMessageCodec同时包含了encode和decode这两个抽象方法;
![]()
ByteToMessageCodec API
| 方法名称 | 描述 |
 |
只要有字节可以被消费,这个方法就将会被调用;它将入站ByteBuf 转换为指定的消息格式, 并将其转发给ChannelPipeline 中的下一个ChannelInboundHandler; |
 |
这个方法的默认实现委托给了decode方法,它只会在Channel 的状态变为非活动时被调用一次,它可以被重写以实现特殊的处理; |
 |
对于每个将被编码并写入出站ByteBuf的类型为I的消息来说,这个方法都将会被调用; |
MessageToMessageCodec编解码器
MessageToMessageEncoder是一个抽象类,用于将一种消息格式转换为另外一种消息格式的编解码器;
![]()
MessageToMessageCodec API
| 方法名称 | 描述 |
 |
这个方法被调用时会被传入INBOUND_IN 类型的消息;它将把它们解码为OUTBOUND_IN 类型的消息,这些消息将被转发给ChannelPipeline中的下一个ChannelInboundHandler; |
 |
对于每个OUTBOUND_IN 类型的消息,这个方法都将会被调用;这些消息将会被编码为INBOUND_IN 类型的消息,然后被转发给ChannelPipeline中的下一个ChannelOutboundHandler; |
CombinedChannelDuplexHandler编解码器
前面的编码器和解码器相结合是通过继承完成的,而继承的方式有其不足在于:将编码器和解码器的逻辑强制性地放在同一个类中,在只需要编码或者解码单边操作的流水线上,逻辑上不大合适;
编码器和解码器如果要结合起来,除了继承的方式,还可以通过组合的方式实现;组合的方式与继承相比,组合会带来更大的灵活性,编码器和解码器可以捆绑使用,也可以单独使用;
Netty提供了一个新的组合器CombinedChannelDuplexHandler,这个类充当了ChannelInboundHandler和ChannelOutboundHandler(该类的类型参数I和O)的容器;

示例使用如下:
public class IntegerDuplexHandler extends CombinedChannelDuplexHandler<Byte2IntegerDecoder, Integer2ByteEncoder> {
public IntegerDuplexHandler() {
super(new Byte2IntegerDecoder(), new Integer2ByteEncoder());
}
}上面的示例IntegerDuplexHandler仅仅只需要继承CombinedChannelDuplexHandler即可,不需要像ByteToMessageCodec那样,把编码逻辑和解码逻辑都堆在同一个类中,而且能复用原来的分开的编码器和解码器实现代码;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号