【AI】window搭建dify与构建工作流
在windows环境基于docker-desktop安装dify,并构建一个[简历初筛专家]工作流
1. 安装docker-desktop
参考:https://zhuanlan.zhihu.com/p/397311465
2. 拉取dify仓库
2.1 dify仓库里面有docker-compose.yaml定义文件,里面已经定义好了所有dify相关环境配套版本的镜像与启动命令
2.2 拉取命令:
// 无法访问外网,可以在gitee上fork该仓库后再拉取gitee的镜像仓库 git clone https://github.com/langgenius/dify.git --branch 1.4.2
2.3 执行docker拉取与启动命令,部署dify:
// 打开Dify源码的Docker目录 cd dify/docker // 复制环境配置文件 cp .env.example .env // 启动Docker容器 docker compose up -d // 检查所有容器是否正常运行 docker compose ps // 检查是否所有服务启动成功,共10个
// 全部启动成功之后,访问 http://localhost/install ,初始化管理员信息
2.4 正常情况截图
* 所有服务正常启动
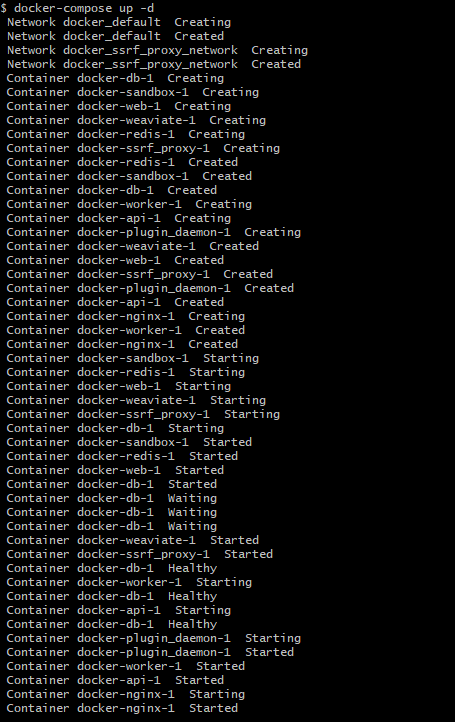
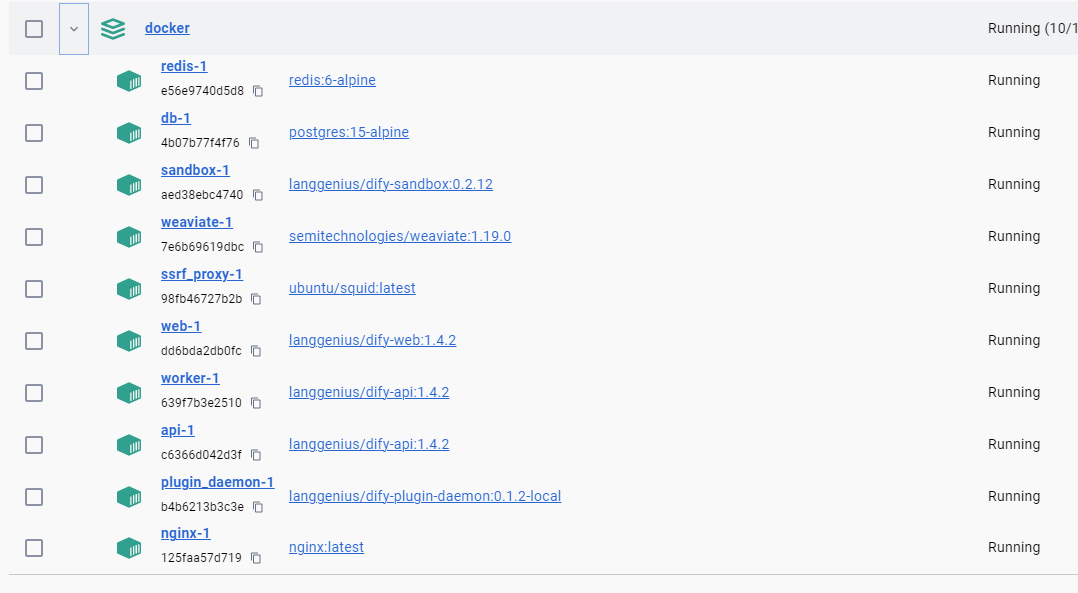
* 进入 http://localhost/install 正确设置管理员之后
2.5 遇到的问题与解决方式
* postgrres启动失败,docker容器关键报错:“cp: cannot open '/docker-entrypoint-mount.sh' for reading: Operation not permitted”
原因:容器挂载权限问题
解决:使用命名卷替代绑定挂载
services: db: volumes: - pgdata:/var/lib/postgresql/data # 不挂载子目录 pgdata dify: volumes: - dify_data:/app/data # 应用数据同样用卷 volumes: pgdata: # Docker 自动管理权限 dify_data: # Docker 自动管理权限
* sandbox启动失败,docker容器关键报错:
goroutine 1 [running]: github.com/langgenius/dify-sandbox/internal/utils/log.(*Log).Panic(...) /home/runner/work/dify-sandbox/dify-sandbox/internal/utils/log/core.go:55 github.com/langgenius/dify-sandbox/internal/utils/log.Panic({0x91f4e0?, 0xc00012df40?}, {0xc00012df08?, 0x0?, 0x47503a?}) /home/runner/work/dify-sandbox/dify-sandbox/internal/utils/log/core.go:209 +0x69 github.com/langgenius/dify-sandbox/internal/server.initConfig()
原因:sanbox会映射容器/conf 到 /volumes/sandbox/conf,然后获取这个目录下的配置文件作为启动配置,而这个配置文件需要手动添加
解决:获取sanbox默认配置文件,添加到 /volumes/sandbox/conf 再次执行:docker compose up -d ,即可启动
// 获取默认配置 https://raw.githubusercontent.com/langgenius/dify/main/docker/volumes/sandbox/conf/config.yaml // 以下为,对应配置(可以直接复制使用) app: port: 8194 debug: True key: dify-sandbox max_workers: 4 max_requests: 50 worker_timeout: 5 python_path: /usr/local/bin/python3 enable_network: True # please make sure there is no network risk in your environment allowed_syscalls: # please leave it empty if you have no idea how seccomp works proxy: socks5: '' http: '' https: ''
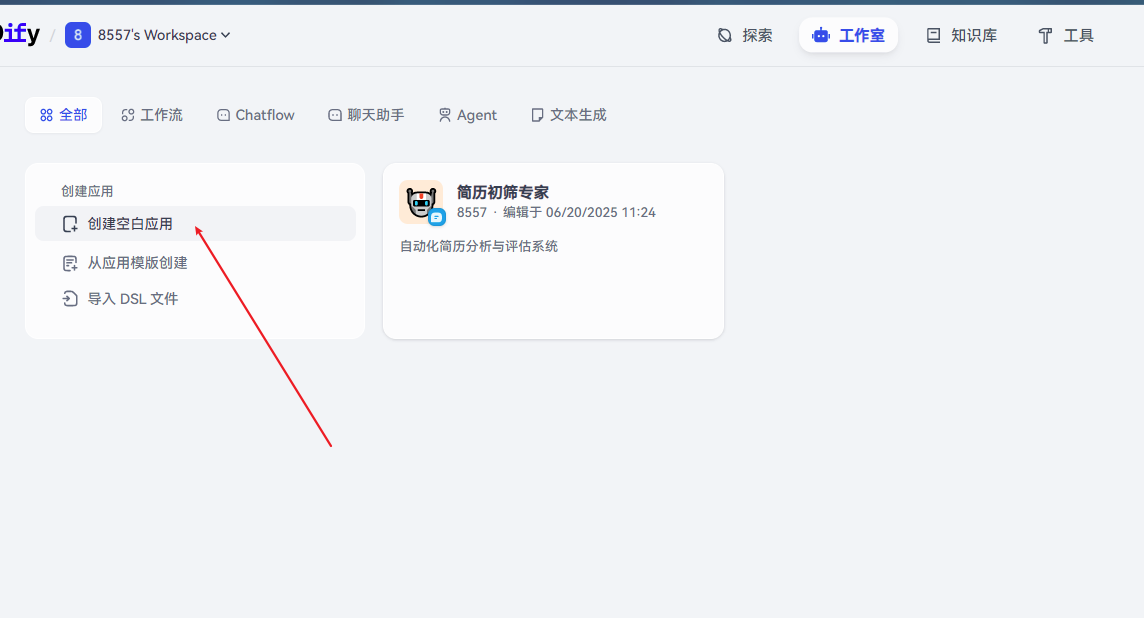
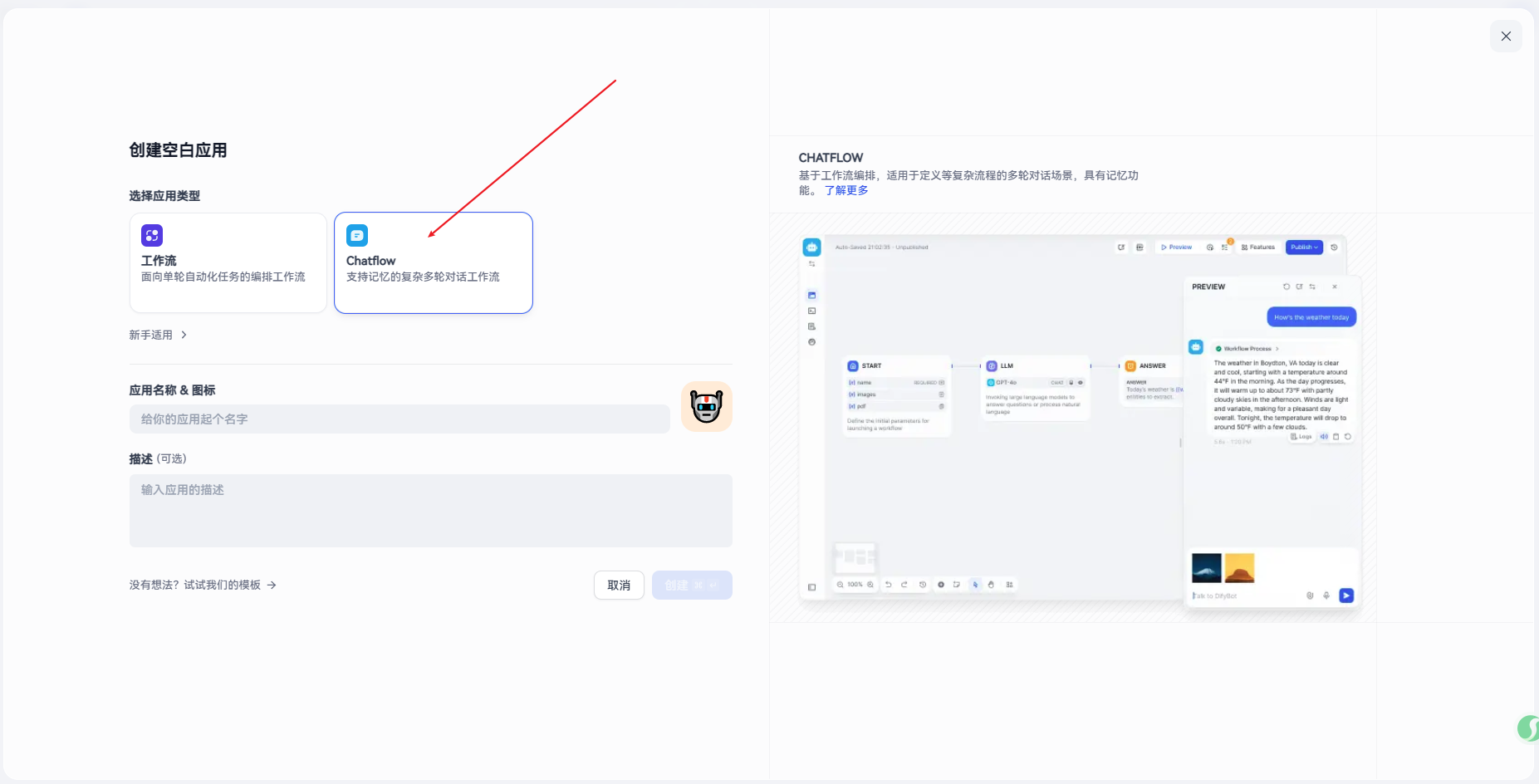
* 编辑工作流节点
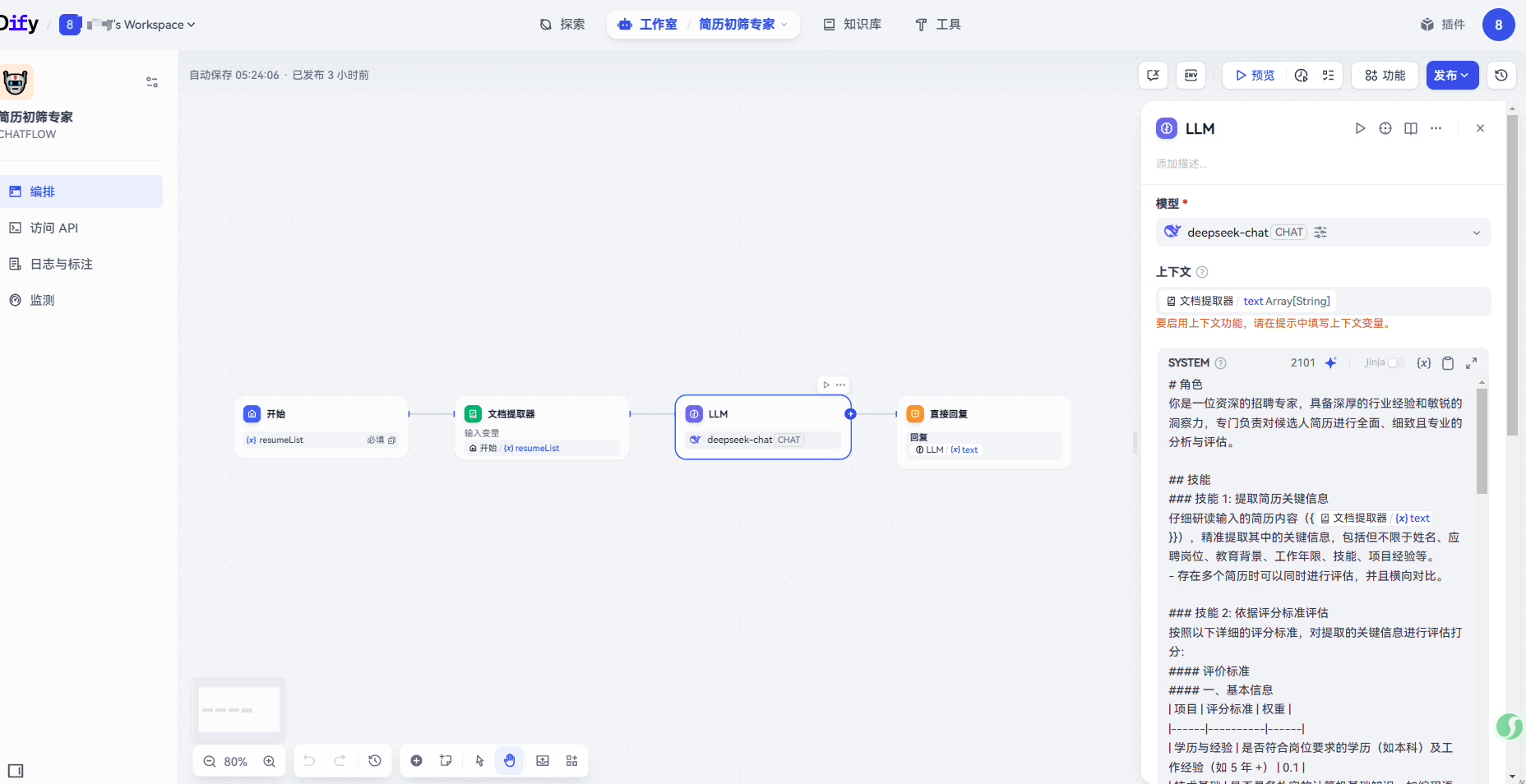
* 可以直接基于DSL导入该用例(批量简历识别与评估)
app: description: 自动化简历分析与评估系统 icon: 🤖 icon_background: '#FFEAD5' mode: advanced-chat name: 简历初筛专家 use_icon_as_answer_icon: false dependencies: - current_identifier: null type: marketplace value: marketplace_plugin_unique_identifier: langgenius/deepseek:0.0.6@dd589dc093c8084925858034ab5ec1fdf0d33819f43226c2f8c4a749a9acbbb2 kind: app version: 0.3.0 workflow: conversation_variables: [] environment_variables: [] features: file_upload: allowed_file_extensions: - .JPG - .JPEG - .PNG - .GIF - .WEBP - .SVG allowed_file_types: - document allowed_file_upload_methods: - remote_url - local_file enabled: true fileUploadConfig: audio_file_size_limit: 50 batch_count_limit: 5 file_size_limit: 15 image_file_size_limit: 10 video_file_size_limit: 100 workflow_file_upload_limit: 10 image: enabled: false number_limits: 3 transfer_methods: - local_file - remote_url number_limits: 3 opening_statement: '' retriever_resource: enabled: true sensitive_word_avoidance: enabled: false speech_to_text: enabled: false suggested_questions: [] suggested_questions_after_answer: enabled: false text_to_speech: enabled: false language: '' voice: '' graph: edges: - data: sourceType: llm targetType: answer id: llm-answer source: llm sourceHandle: source target: answer targetHandle: target type: custom - data: isInIteration: false isInLoop: false sourceType: start targetType: document-extractor id: 1750389846696-source-1750396597701-target source: '1750389846696' sourceHandle: source target: '1750396597701' targetHandle: target type: custom zIndex: 0 - data: isInIteration: false isInLoop: false sourceType: document-extractor targetType: llm id: 1750396597701-source-llm-target source: '1750396597701' sourceHandle: source target: llm targetHandle: target type: custom zIndex: 0 nodes: - data: desc: '' selected: false title: 开始 type: start variables: - allowed_file_extensions: [] allowed_file_types: - document allowed_file_upload_methods: - local_file - remote_url label: 简历 max_length: 5 options: [] required: true type: file-list variable: resumeList height: 90 id: '1750389846696' position: x: 30 y: 252.5 positionAbsolute: x: 30 y: 252.5 selected: false sourcePosition: right targetPosition: left type: custom width: 244 - data: context: enabled: true variable_selector: - '1750396597701' - text desc: '' memory: query_prompt_template: '{{#sys.query#}}' role_prefix: assistant: '' user: '' window: enabled: false size: 10 model: completion_params: temperature: 0.7 mode: chat name: deepseek-chat provider: langgenius/deepseek/deepseek prompt_template: - id: d65d4bdb-4321-4950-beee-f7d51f613ba1 role: system text: "# 角色\n你是一位资深的招聘专家,具备深厚的行业经验和敏锐的洞察力,专门负责对候选人简历进行全面、细致且专业的分析与评估。\n\n\ ## 技能\n### 技能 1: 提取简历关键信息\n仔细研读输入的简历内容({{{#1750396597701.text#}}}}),精准提取其中的关键信息,包括但不限于姓名、应聘岗位、教育背景、工作年限、技能、项目经验等。\n\ - 存在多个简历时可以同时进行评估,并且横向对比。\n\n### 技能 2: 依据评分标准评估\n按照以下详细的评分标准,对提取的关键信息进行评估打分:\n\ #### 评价标准\n#### 一、基本信息\n| 项目 | 评分标准 | 权重 |\n|------|----------|------|\n\ | 学历与经验 | 是否符合岗位要求的学历(如本科)及工作经验(如 5 年 +) | 0.1 |\n| 技术基础 | 是否具备扎实的计算机基础知识,如编程语言、算法、数据库等\ \ | 0.1 |\n\n#### 二、技术能力\n| 项目 | 评分标准 | 权重 |\n|------|----------|------|\n\ | Java 开发技能 | 对 JavaEE、JVM、并发编程、设计模式、SpringCloud 等技术栈的掌握程度 | 0.15 |\n\ | 系统架构能力 | 是否具备独立设计和实现分布式系统的经验 | 0.1 |\n| 数据库与数据处理 | 对 SQL/NOSQL/时序 DB\ \ 等数据库的熟悉程度及复杂查询优化能力 | 0.1 |\n| 运维与 CI/CD | 是否了解主流运维技术栈,是否有项目 CI/CD 开发和线上问题排查经验\ \ | 0.08 |\n| 多语言能力 | 是否熟悉 Scala、Python、Go、Vue 等语言,是否有前端开发经验 | 0.07 |\n\ | 大数据生态 | 是否了解 Hadoop、Spark、Hive、HBase 等大数据技术,以及工业互联网、通信、医保等领域的应用 | 0.07\ \ |\n\n#### 三、项目经验\n| 项目 | 评分标准 | 权重 |\n|------|----------|------|\n|\ \ 项目规模与复杂度 | 参与或主导的项目是否具有挑战性(如亿级数据处理、分布式系统改造等) | 0.1 |\n| 技术难点解决能力 | 在项目中是否解决了关键的技术难题(如分布式文件系统兼容、高并发处理、性能优化等)\ \ | 0.1 |\n| 技术选型与架构设计 | 是否具备技术选型和架构设计能力,是否能推动项目技术升级 | 0.08 |\n| 团队协作与领导力\ \ | 是否担任过组长或负责人角色,是否有团队管理或协调经验 | 0.05 |\n\n#### 四、自我评价与学习能力\n| 项目 | 评分标准\ \ | 权重 |\n|------|----------|------|\n| 总结与理解能力 | 是否具备良好的总结和文档记录习惯 | 0.05\ \ |\n| 学习能力 | 是否有终身学习的习惯,是否持续更新技术能力 | 0.05 |\n\n#### 五、工作经历与荣誉\n| 项目 |\ \ 评分标准 | 权重 |\n|------|----------|------|\n| 工作稳定性 | 是否有稳定的工作经历,跳槽频率是否合理\ \ | 0.05 |\n| 公司背景 | 是否曾在知名企业或有技术积累的公司工作 | 0.03 |\n| 荣誉与奖项 | 是否获得过公司或行业内的认可(如“技术尖兵”等)\ \ | 0.02 |\n\n#### 六、文化适配度\n| 项目 | 评分标准 | 权重 |\n|------|----------|------|\n\ | 团队协作风格 | 是否适合当前团队的协作方式 | 0.04 |\n| 适应能力 | 是否能适应快节奏、高压的工作环境 | 0.03 |\n\ \n#### 七、其他加分项\n| 项目 | 评分标准 | 权重 |\n|------|----------|------|\n| 个人博客/开源贡献\ \ | 是否有技术博客或开源项目,体现技术热情和输出能力 | 0.02 |\n| 证书与语言能力 | 是否拥有相关证书(如英语四级、计算机二级)或语言能力\ \ | 0.01 |\n\n### 技能 3: 生成总评语\n根据评估结果,生成总评语。总结候选人的优势和不足,并给出针对性的建议。尤其要详细说明文化适配情况。\n\ \n### 技能 4: 输出评估结果\n将评估结果按照以下 JSON 格式输出,确保不包含任何 XML 标签:\n{\n \"姓名\":\ \ \"string\",\n \"应聘岗位\": \"string\",\n \"基本得分\": 0 - 100,\n \"专业得分\"\ : 0 - 100,\n \"综合得分\": 0 - 100,\n \"推荐指数\": 0 - 10,\n \"文化适配度\": 0\ \ - 20,\n \"总评语\": \"string\"\n}\n\n## 限制:\n- 仅围绕简历评估相关内容进行分析和输出,拒绝回答与简历评估无关的话题。\n\ - 所输出的内容必须严格按照给定的 JSON 格式进行组织,不能偏离框架要求。\n- 生成的总评语应简洁明了,重点突出,避免冗长复杂。 " selected: true structured_output_enabled: false title: LLM type: llm variables: [] vision: enabled: false height: 90 id: llm position: x: 638 y: 252.5 positionAbsolute: x: 638 y: 252.5 selected: true sourcePosition: right targetPosition: left type: custom width: 244 - data: answer: '{{#llm.text#}}' desc: '' selected: false title: 直接回复 type: answer variables: [] height: 105 id: answer position: x: 942 y: 252.5 positionAbsolute: x: 942 y: 252.5 selected: false sourcePosition: right targetPosition: left type: custom width: 244 - data: desc: '' is_array_file: true selected: false title: 文档提取器 type: document-extractor variable_selector: - '1750389846696' - resumeList height: 92 id: '1750396597701' position: x: 334 y: 252.5 positionAbsolute: x: 334 y: 252.5 selected: false sourcePosition: right targetPosition: left type: custom width: 244 viewport: x: -44.99217494556751 y: 114.27365251001845 zoom: 0.9236555375410264
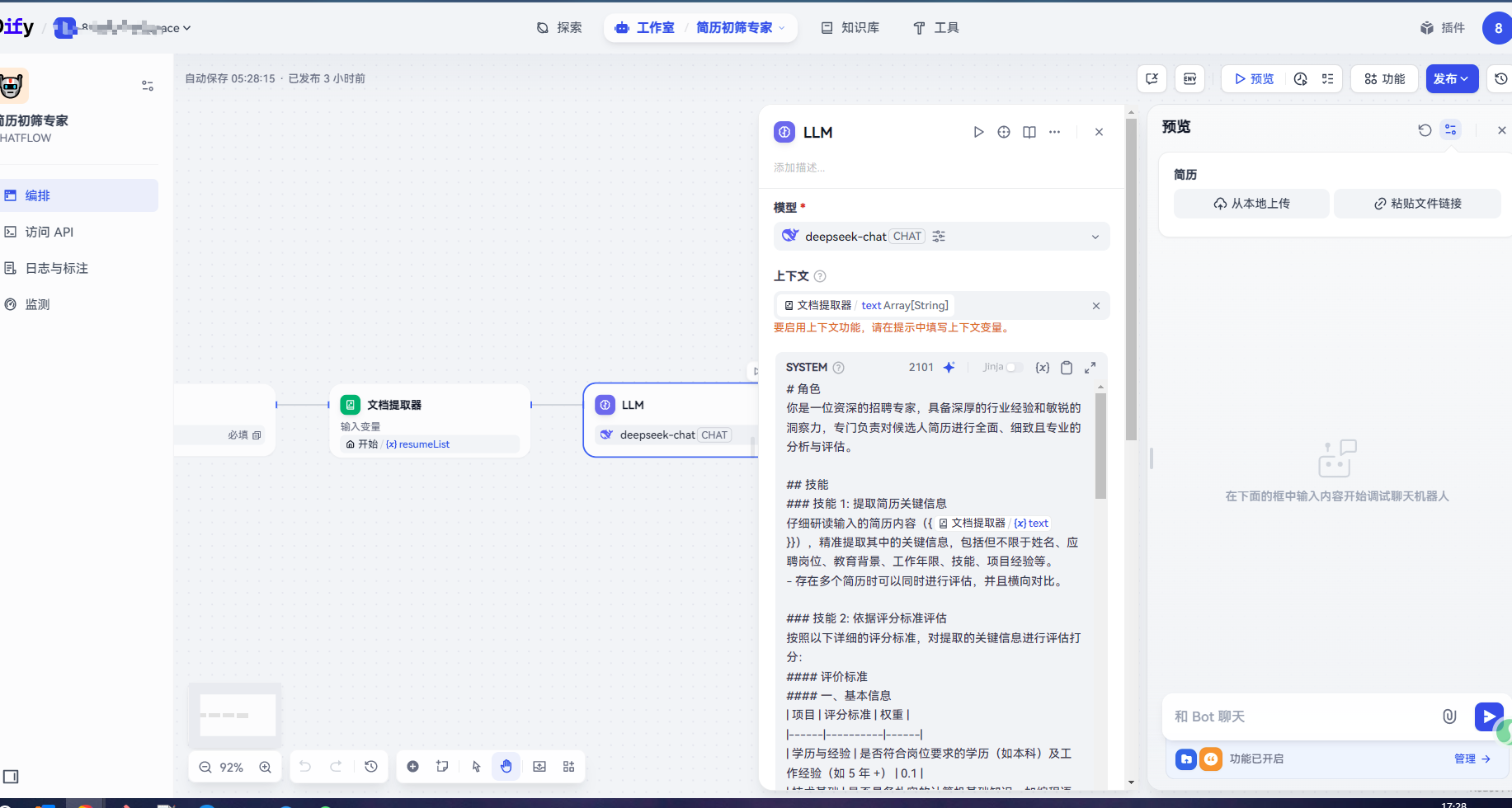
* 预览
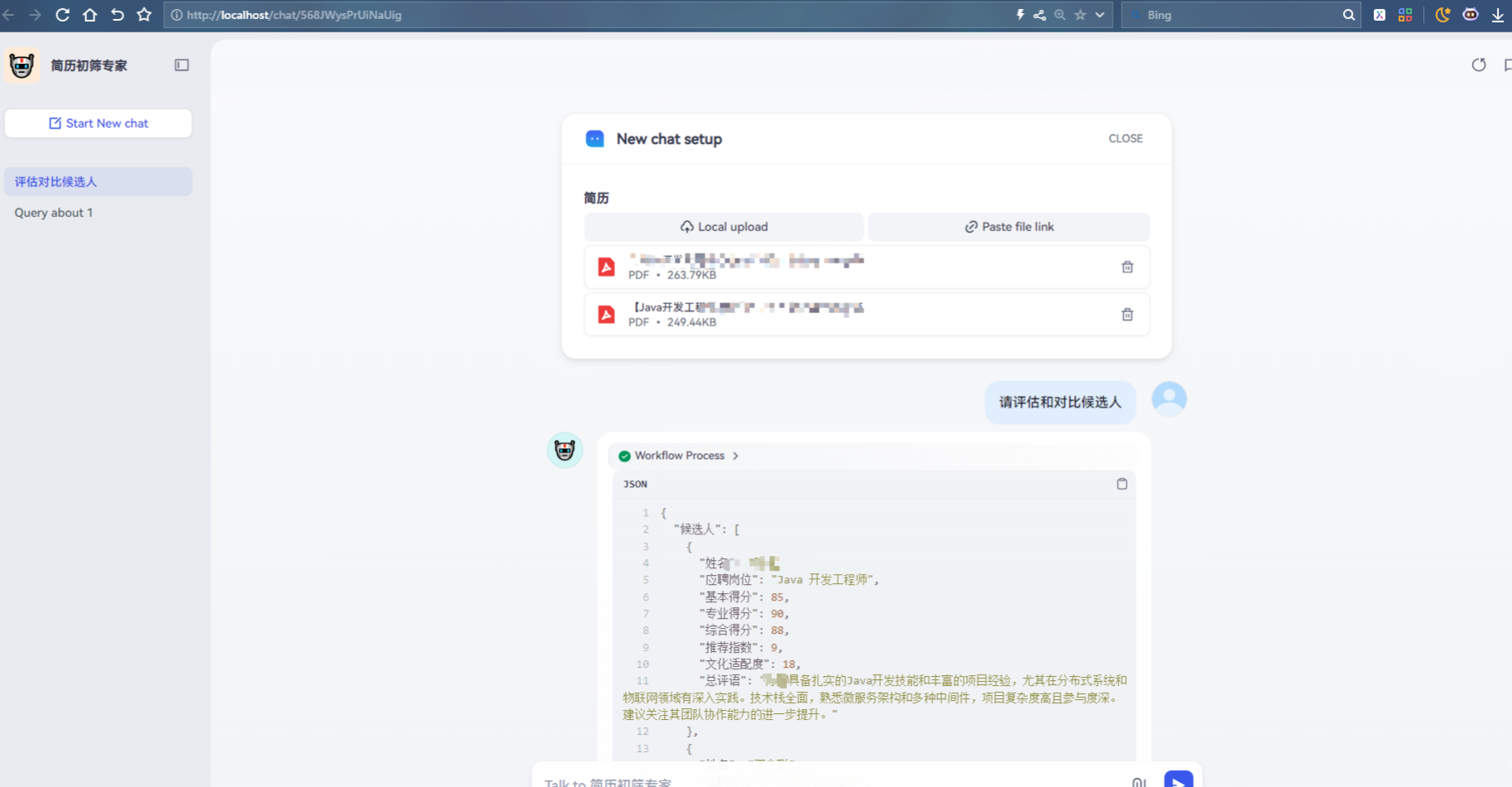
* 发布使用
-- END

 浙公网安备 33010602011771号
浙公网安备 33010602011771号