spark基础概念
分布式系统
通过网络进行通信,为了完成共同的任务而协调工作的节点组成的系统
- 计算
- Online(每条记录实时处理):Flink,Spark Streaming
- Offline(开始前已知所有数据):MapReduce,Spark
- 存储
- Kafka,HDFS,Hive
- 调度
- Yarn,K8s
Spark
什么是Spark?
- 一个分布式数据计算的通用框架
Spark解决了什么问题?
- 对于单机无法解决的大数据量问题,提供了横向扩展的解决方案
- 开发者无需关心分布式系统的各种协同问题,只需专注于核心计算逻辑的实现
- 并行计算,提高效率
为什么是Spark
- 多个作业之间数据通信是基于内存,运行速度更快
- 支持多种语言(Scala,Java,Python等)
- 通用性:支持批处理(Batch)、流式处理(Stream)、Spark SQL(结构化数据处理)
RDD:Resilient Distributed Datasets
什么是RDD?
- A list of partitions:RDD分布于多个节点上,每个节点上的数据称作一个Partition,Partition决定了计算的粒度,可以在创建RDD时指定RDD的Partition个数
- A function for computing each split:RDD有两种类型的API:
- Transformation:根据一个RDD创建另外一个RDD,只是记录下对RDD的转换操作,不会立即触发任务的运行,是延迟加载的
- 不需要shuffle:map,filter,union
- 需要shuffle:groupByKey,reduceByKey,repartition
- Actions:对RDD进行计算,会触发整个任务真正运行,导致Lineage(血统)中断
- count,collect,saveAsTestFile
- foreach
- 持久化:默认情况下,每次调用 action 算子的时候,每个由 transformation 转换得到的RDD都会被重新计算。你也可以通过调用persist()与cache()操作来持久化RDD, Spark 会把 RDD 的元素都保存在集群中,下一次访问这些元素的速度将大大提高。同时,Spark 还支持将RDD元素持久化到内存或者磁盘上,甚至可以支持跨节点多副本。
- Transformation:根据一个RDD创建另外一个RDD,只是记录下对RDD的转换操作,不会立即触发任务的运行,是延迟加载的
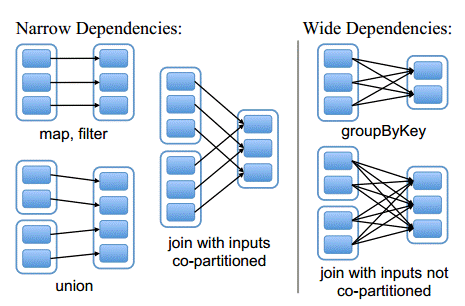
- A list of dependencies on other RDDs:RDD每次转换会形成新的RDD,RDD之间存在类似流水线的前后依赖,部分分区数据丢失时,可以针对性恢复而不需要恢复全部分区,是容错机制的体现。
![]()
- NarrowDependency: 父RDD的每个Partition至多被子RDD的一个Partition依赖(即与数据规模无关),允许在一个集群节点上以流水线的方式(pipeline)计算所有父Partition。当某个Partition丢失时,只需要重新计算丢失Partition的父RDD Partition的结果
- OneToOneDependency:
- RangeDependency:
- WideDependency:子RDD的每个Partition依赖于所有父RDD Partition,单个Partition丢失需要重新计算父RDD的所有Partition
- ShuffleDependency:将各节点上的同一类数据汇集到某一节点进行计算,把这些分布在不同节点的数据按照一定的规则汇集到一起的过程称为 Shuffle
- NarrowDependency: 父RDD的每个Partition至多被子RDD的一个Partition依赖(即与数据规模无关),允许在一个集群节点上以流水线的方式(pipeline)计算所有父Partition。当某个Partition丢失时,只需要重新计算丢失Partition的父RDD Partition的结果
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned):只有 key-value 类型的RDD,才可能有Partitioner。Partitioner函数决定了RDD的分片数量。Spark 实现了两种类型的分片函数:
- 基于哈希的HashPartitioner
- 基于范围的RangePartitioner
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file):根据输入数据源的不同,RDD 可能具有不同的优先位置,比如内存、磁盘、HDFS

 浙公网安备 33010602011771号
浙公网安备 33010602011771号