一文终结String各种问题

下面来抽丝剥茧的慢慢来 ,先看一下代码
1 public class StringTableStudy { 2 public static void main(String[] args) { 3 String a = "a"; 4 String b = "b"; 5 String ab = "ab"; 6 } 7 }
0: ldc #2 // String a 2: astore_1 3: ldc #3 // String b 5: astore_2 6: ldc #4 // String ab 8: astore_3 9: return
下面说一下,String 在什么情况下才将字符串放入串池中:
- 直接使用双引号声明出来的
String对象会直接存储在常量池中。String str1 = "abc"; // 在常量池中
-
new String("abc");当JVM遇到上述代码时,会先检索常量池中是否存在“abc”,如果不存在“abc”这个字符串,则会先在常量池中创建这个一个字符串。然后再执行new操作,会在堆内存中创建一个存储“abc”的String对象,对象的引用赋值给str2。此过程创建了2个对象。
当然,如果检索常量池时发现已经存在了对应的字符串,那么只会在堆内创建一个新的String对象,此过程只创建了1个对象。
在上述过程中检查常量池是否有相同Unicode的字符串常量时,使用的方法便是String中的intern()方法。我们假设在串池中已经存在“abc”了,那么过程如下:
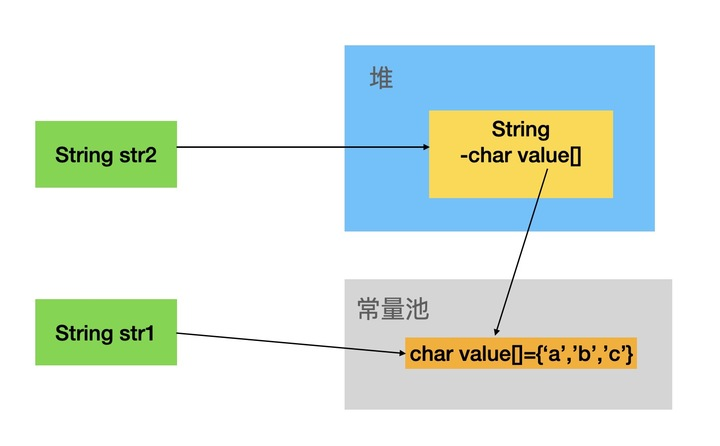 上面的示意图我们可以看到在堆内创建的String对象的char value[]属性指向了常量池中的char value[]。
上面的示意图我们可以看到在堆内创建的String对象的char value[]属性指向了常量池中的char value[]。 - 如果不是用双引号声明的
String对象,使用String提供的intern()方法也有同样的效果。String.intern()是一个 Native 方法,它的作用是:如果字符串常量池中已经包含一个等于此 String 对象内容的字符串,则返回常量池中该字符串的引用;如果没有,JDK1.7 之前(不包含 1.7)的处理方式是在常量池中创建与此String内容相同的字符串,并返回常量池中创建的字符串的引用,JDK1.7 以及之后,字符串常量池被从方法区拿到了堆中,jvm 不会在常量池中创建该对象,而是将堆中这个对象的引用直接放到常量池中,减少不必要的内存开销。
String 类型的变量和常量做“+”运算时发生了什么?
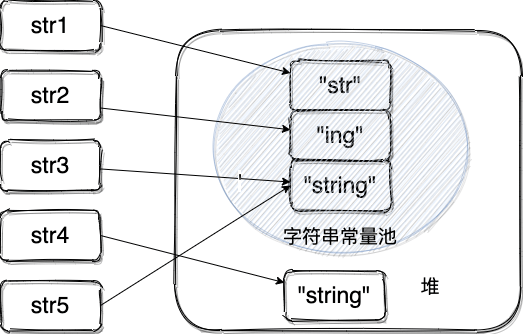
String str1 = "str"; String str2 = "ing"; String str3 = "str" + "ing";//常量池中的对象 String str4 = str1 + str2; //在堆上创建的新的对象 只要是出先一个变量,就是返回堆上的String对象,没有往常量池中放 String str5 = "string";//常量池中的对象 System.out.println(str3 == str4);//false System.out.println(str3 == str5);//true System.out.println(str4 == str5);//false
注意 :比较 String 字符串的值是否相等,可以使用
equals()方法。String中的equals方法是被重写过的。Object的equals方法是比较的对象的内存地址,而String的equals方法比较的是字符串的值是否相等。如果你使用==比较两个字符串是否相等的话,IDEA 还是提示你使用equals()方法替换。
对于编译期可以确定值的字符串,也就是常量字符串 ,jvm 会将其存入字符串常量池。
字符串常量池 是 JVM 为了提升性能和减少内存消耗针对字符串(String 类)专门开辟的一块区域,主要目的是为了避免字符串的重复创建。
String aa = "ab"; // 放在常量池中 String bb = "ab"; // 从常量池中查找 System.out.println(aa==bb);// tru
JDK1.7 之前运行时常量池逻辑包含字符串常量池存放在方法区。JDK1.7 的时候,字符串常量池被从方法区拿到了堆中。
常量折叠会把常量表达式的值求出来作为常量嵌在最终生成的代码中,这是 Javac 编译器会对源代码做的极少量优化措施之一(代码优化几乎都在即时编译器中进行)。
对于 String str3 = "str" + "ing"; 编译器会给你优化成 String str3 = "string"; 。
上面的问题涉及到字符串常量重载“+”的问题,当一个字符串由多个字符串常量拼接成一个字符串时,它自己也肯定是字符串常量。字符串常量的“+”号连接Java虚拟机会在程序编译期将其优化为连接后的值。
就上面的示例而言,在编译时已经被合并成“abcdef”字符串,因此,只会创建1个对象。并没有创建临时字符串对象str和ing,这样减轻了垃圾收集器的压力。
并不是所有的常量都会进行折叠,只有编译器在程序编译期就可以确定值的常量才可以:
- 基本数据类型(
byte、boolean、short、char、int、float、long、double)以及字符串常量。 final修饰的基本数据类型和字符串变量- 字符串通过 “+”拼接得到的字符串、基本数据类型之间算数运算(加减乘除)、基本数据类型的位运算(<<、>>、>>> )
因此,str1 、 str2 、 str3 都属于字符串常量池中的对象。
引用的值在程序编译期是无法确定的,编译器无法对其进行优化。
对象引用和“+”的字符串拼接方式,实际上是通过 StringBuilder 调用 append() 方法实现的,拼接完成之后调用 toString() 得到一个 String 对象 。
String str4 = new StringBuilder().append(str1).append(str2).toString();
注意,这个str4只是一个堆中的一个对象,并没有放入串池中;如果调用intern()的话,会将这个字符串对象放入串池中,会把串池中的对象返回
因此,str4 并不是字符串常量池中存在的对象,属于堆上的新对象。
不过,字符串使用 final 关键字声明之后,可以让编译器当做常量来处理。
final String str1 = "str"; final String str2 = "ing"; // 下面两个表达式其实是等价的 String c = "str" + "ing";// 常量池中的对象 String d = str1 + str2; // 常量池中的对象 System.out.println(c == d);// true
被 final 关键字修改之后的 String 会被编译器当做常量来处理,编译器在程序编译期就可以确定它的值,其效果就相当于访问常量。
如果 ,编译器在运行时才能知道其确切值的话,就无法对其优化。
示例代码如下(str2 在运行时才能确定其值):
final String str1 = "str"; final String str2 = getStr(); String c = "str" + "ing";// 常量池中的对象 String d = str1 + str2; // 在堆上创建的新的对象 System.out.println(c == d);// false public static String getStr() { return "ing"; }
String str1 = "abcd"; String str2 = new String("abcd"); String str3 = new String("abcd"); System.out.println(str1==str2);//false
System.out.println(str2==str3);//false
解析:
// 从字符串常量池中拿对象 String str1 = "abcd";
这种情况下,jvm 会先检查字符串常量池中有没有"abcd",如果字符串常量池中没有,则创建一个,然后 str1 指向字符串常量池中的对象,如果有,则直接将 str1 指向"abcd";
因此,str1 指向的是字符串常量池的对象。
我们再来看下面这种创建字符串对象的方式:
// 直接在堆内存空间创建一个新的对象。 String str2 = new String("abcd"); String str3 = new String("abcd");
只要使用 new 的方式创建对象,便需要创建新的对象 。
使用 new 的方式创建对象的方式如下,可以简单概括为 3 步:
- 在堆中创建一个字符串对象
- 检查字符串常量池中是否有和 new 的字符串值相等的字符串常量
- 如果没有的话需要在字符串常量池中也创建一个值相等的字符串常量,如果有的话,就直接返回堆中的字符串实例对象地址。
因此,str2 和 str3 都是在堆中新创建的对象。
问题:
针对上面的问题,我们再次升级一下,下面的代码会创建几个对象?
String str = "abc" + new String("def");
1. 创建了4个,5个,还是6个对象?
4个对象的说法:常量池中分别有“abc”和“def”,堆中对象new String("def")和“abcdef”。
String s = new String("def"); new StringBuilder().append("abc").append(s).toString();
答案应该是创建了4个字符串对象(串池中:“abc”,“def”;堆中:“def”,“abcdef”)和1个StringBuilder对象。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号