
链表
链表和数组不同,数组是必须要连续内存空间,链表是通过指针将零碎的内存空间串联起来
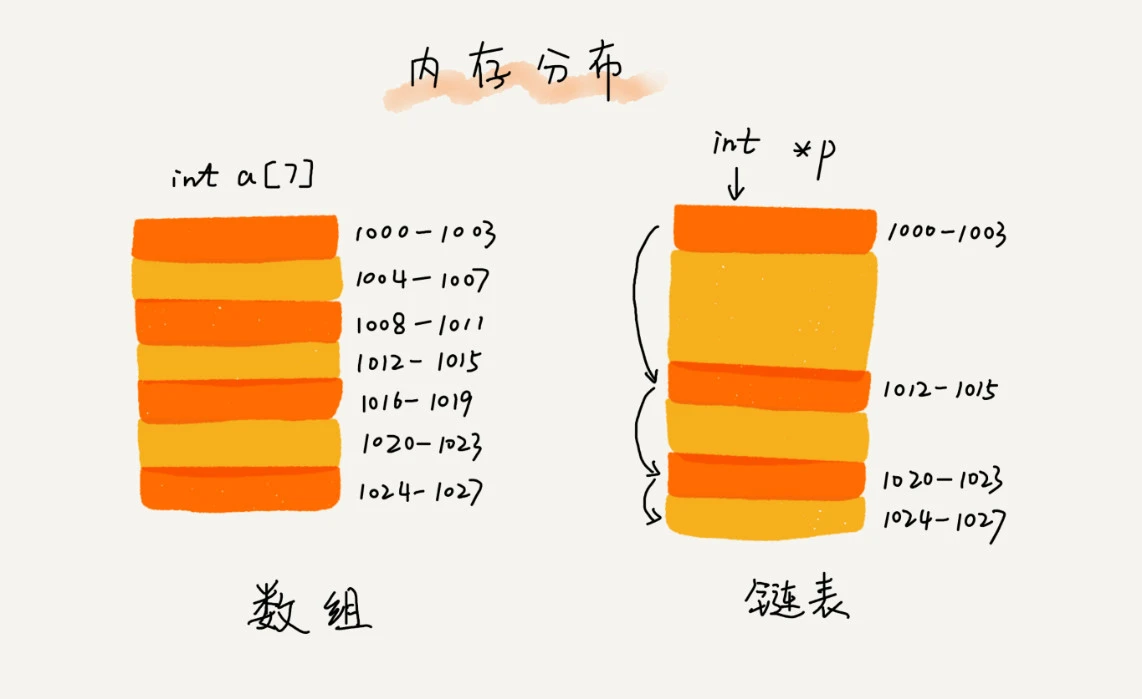
常见的链表有单链表,双向链表,循环链表
单向链表
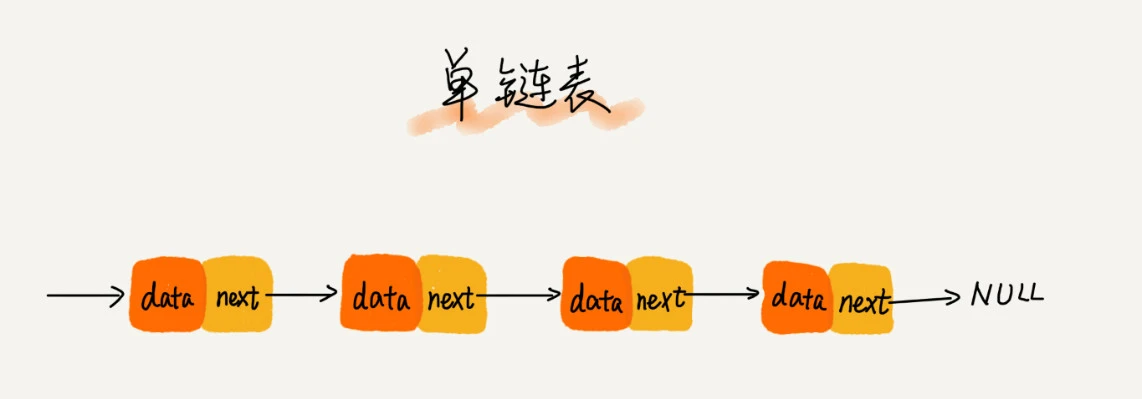
单向链表每个数据后面都会有一个叫next的结点,头结点是记录链表的基地址,也就是链表第一个元素,尾结点指向null,代表链表结束,其他元素的结点均是指向下个元素。
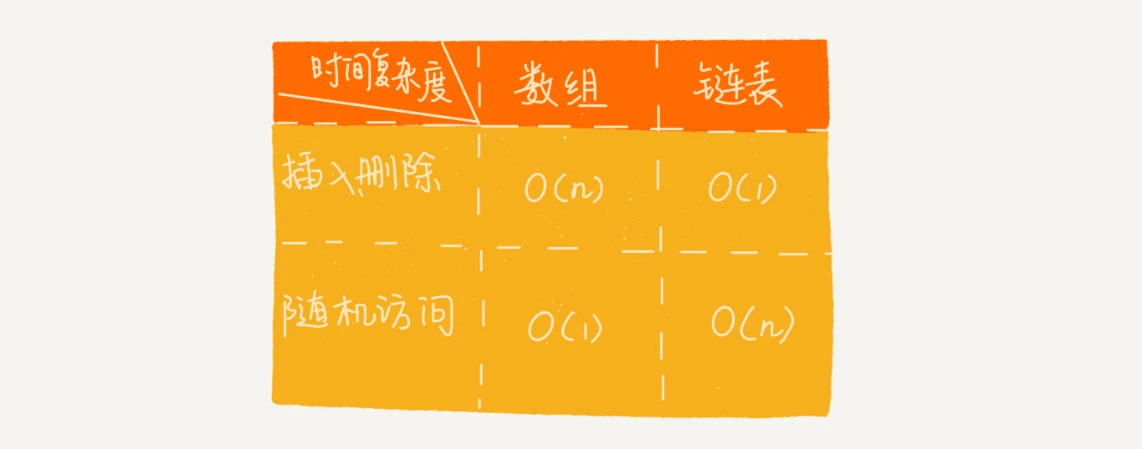
所以,链表在查询的时候是要一个个遍历元素,直到找到目标元素,而数组访问是通过偏移公式,直接算出地址,于是数组的查询效率就会比链表快,而数组增删会比链表复杂,因为要挪移内存空间
循环链表
循环链表其实就是尾结点指向头结点,形成循环
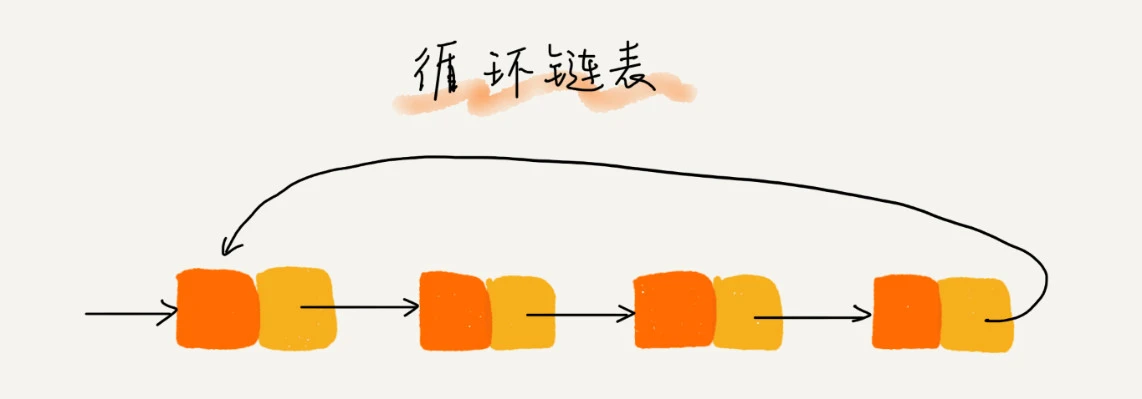
循环链表从链尾到链头会比单向链表更方便,所以一般处理具有循环结构的数据时就是用循环链表,比如约瑟夫环
双向链表
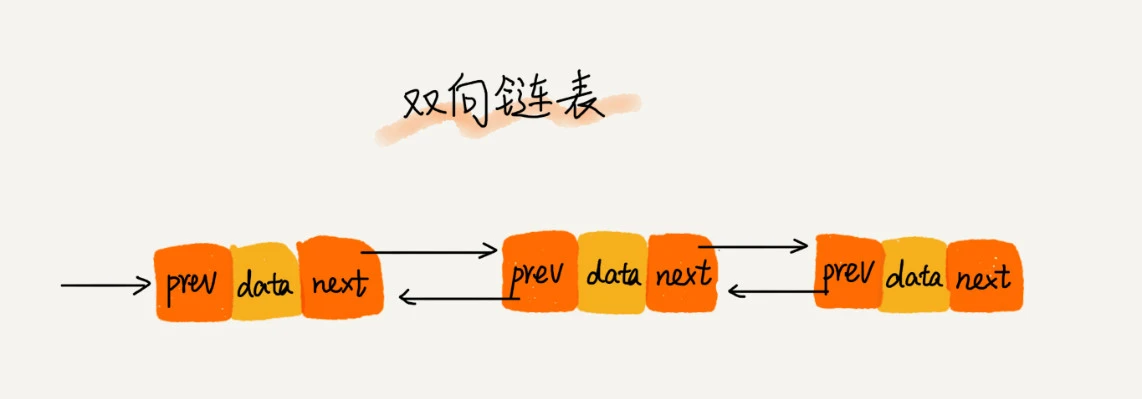
整个链表的两端由first和last两个节点类型指向,每个对象都有pre,next两个节点,分别用来指向前一个对象和后一个对象,item是该对象的有效信息,举个简单的例子来模拟双向链表
public class Test { public static void main(String[] args) { Node liuBei = new Node("刘备"); Node guanYu = new Node("关羽"); Node zhangFei = new Node("张飞"); Node zhuGeliang = new Node("诸葛亮"); liuBei.next = zhuGeliang; zhuGeliang.next = guanYu; guanYu.next = zhangFei; guanYu.pre = zhuGeliang; zhangFei.pre = guanYu; Node temp = liuBei; while (temp != null){ System.out.println(temp.name); temp = temp.next; } } } class Node { public String name; public Node pre; public Node next; public Node(String name) { this.name = name; } }
双向链表由于多了个pre结点,所以内存空间比单链表要多,但是也正因为这样,双向链表能双向遍历,这样链表的插入,删除操作能更快,更简单
这其中涉及到一个重要的设计思想:空间换时间,时间换空间
当我们空间充足时,可以选择空间复杂度较高,时间复杂度较低的数据结构和算法,比如缓存技术,而如果内存紧缺,比如代码跑在手机上或单片机这些时,可以选择和前面相反的策略
链表和数组的性能比较
注意,数据简单易用,在内存上是连续的空间,这对cpu的缓存机制很友好,可以有效预读数据,提高访问效率,但是链表是分开的,所以不能进行有效预读。
而且,链表容易造成内存碎片,对于java来说,会造成频繁的GC
数组的缺点是大小固定,一经声明就要占用整块连续内存空间。如果声明的数组过大,系统可能没有足够的连续内存空间分配给它,导致“内存不足(out of memory)”。如果声明的数组过小,则可能出现不够用的情况。这时只能再申请一个更大的内存空间,把原数组拷贝进去,非常费时。链表本身没有大小的限制,天然地支持动态扩容,我觉得这也是它与数组最大的区别
链表注意事项
①经常用来检查链表代码是否正确的边界条件有这样几个:
检查链表代码是否正确的边界条件有这样几个:如果链表为空时,代码是否能正常工作?
如果链表只包含一个结点时,代码是否能正常工作?
如果链表只包含两个结点时,代码是否能正常工作?
代码逻辑在处理头结点和尾结点的时候,是否能正常工作?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号