
集合
经典面试题:介绍java集合类
★★为什么要用集合★★
当我们想要保存多个数据时,可能第一时间就是想到用数组,数组固然好用,但也有以下的缺点
(1)数组的长度在初始化时就必须定好,而且不能更改,所以扩容和删减非常麻烦,要自己写一大堆代码
(2)所有元素必须同样类型
所以,针对这些问题,java提供了一个机制-----------集合
集合的特点
1.集合的元素可以不是相同类型
2.集合的元素没有顺序
3.没有限制大小
★★简版集合体系(只列出几个最常见的类)★★
单列集合
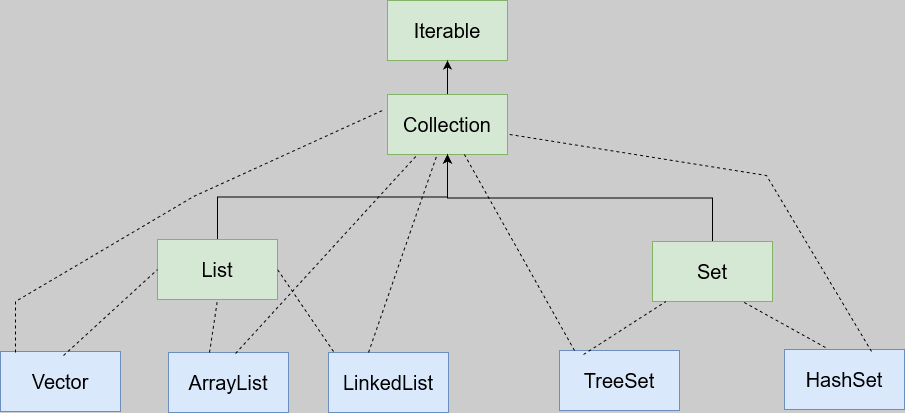
①什么是单列集合?
单列集合就是集合的元素一个一个的如下
public static void main(String[] args) { ArrayList arrayList = new ArrayList<>(); arrayList.add("java"); arrayList.add("cpp"); System.out.println(arrayList); } 运行结果 [java, cpp]
②实现Collection的集合可以存放多个元素,每个元素可以是Object及其子类
③实现Collection的集合,有些可以放重复元素,有些不可以,有些是有序的(存放的顺序和取出的顺序一致),比如说List,有些则无序(存放的顺序和取出的顺序并不完全一样),比如说Set
④Collection默认是没有被任何类实现,默认是通过它的两个子接口List和Set来实现的
⑤Iterable对象里面有一个抽象方法iterator,这个方法返回值是一个实现了iterator的对象,被称为迭代器(这里提一嘴:我们平时用到foreach(增强for循环)通过调试会看到,其实底层就是使用迭代器来运作的,foreach遍历数组也是用的hasNext()和next()方法,可以说foreach就像是迭代器的封装),迭代器只用来实现方法(一般是用来遍历集合),本身不存放对象,因为Collection继承了Iterable,所以所有实现了Collection的集合都有一个Iterator()方法,用于返回一个迭代器。
注意:这个iterator()方法也用于重新初始化迭代器。
List接口,Collection的子接口之一
①List集合中元素顺序(取出和放入的顺序一致),并且元素可以重复
②List集合类的每个元素都有下标索引,可以根据具体的索引来取得相应的元素的值(用get方法)
public static void main(String[] args) { ArrayList<Object> objects = new ArrayList<>(); objects.add("哈哈哈"); objects.add("呵呵呵"); System.out.println(objects.get(1)); } 运行结果 呵呵呵
ArrayList注意事项
①ArrayList可存放所有元素,包括null,并且可以放多个null
②ArrayList是由数组来实现存储的,ArrayList里面维护了一个Object类型的数组elementData
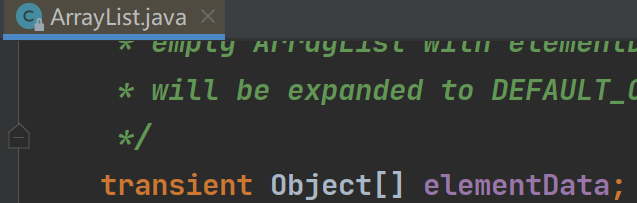
transient关键字表示这个elementData不会被序列化
当ArrayList创建对象时,如果使用的无参构造器,那么elementData初始容量为0


然后当第一次扩容时,elementData的容量变为10,在此之后,每次进行扩容,elementData的容量都会变为本次扩容前的容量的1.5倍
如果是使用的指定大小的构造器,那么elementData初始容量就是指定的大小,然后每次扩容,elementData的容量都会变为本次扩容前的容量的1.5倍
为什么会是这样的扩容机制呢?扒出底层的扩容机制其实就一目了然了
我们来简单过一下调用add时的执行流程
(1)
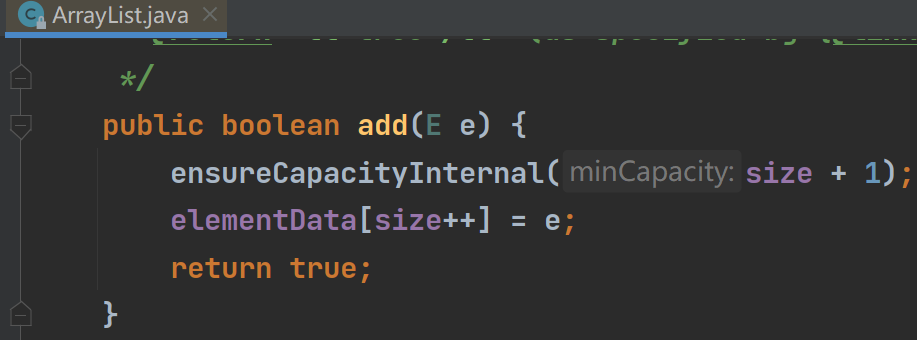
可以看到add方法里面是先确保当前elemenData的容量足够才决定真正扩容,我们进去ensureCapacityInternal里面看看
(2)

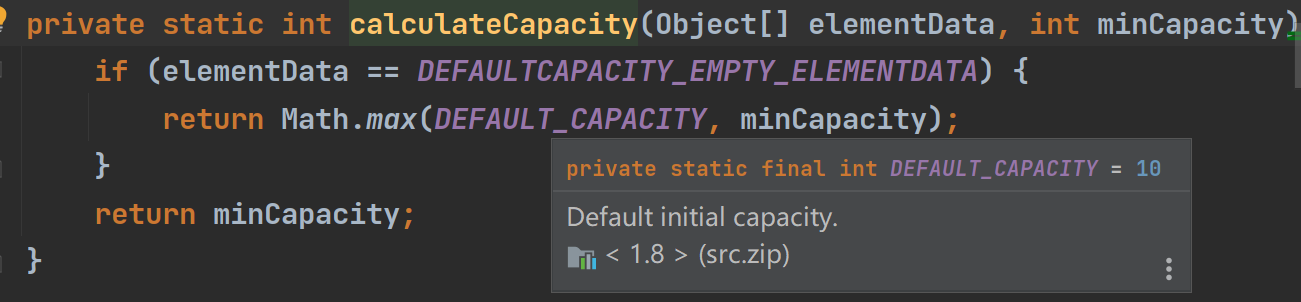
可以看到这个ensureCapacityInternal其实是对ensureExplicitCapacity的一层封装,在调用ensureExplicitCapacity时,会用这个calculateCapacity的返回值传递给形参,在这个calculateCapacity里面,可以看到如果elementData容量是0,那么返回DEFAULT_CAPACITY(因为这里minCapacity为1,而DEFAULT_CAPACITY值为10)
(3)
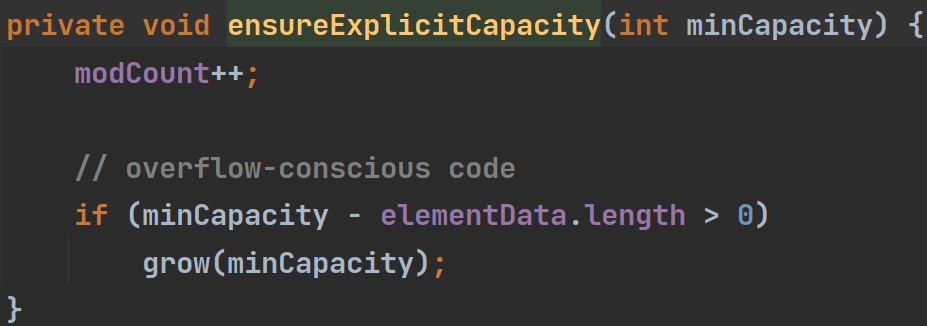
然后就进到了ensureExplicitCapacity,首先映入眼帘的这个modCount是用来记录当前集合被修改的次数的,如果用多个线程同时修改它的话会抛出一个异常,所以这个主要是进行线程的安全防护。然后下面看到,当形参minCapacity大于elemntData.length时,就调用grow,那么这grow是什么呢?
(4)
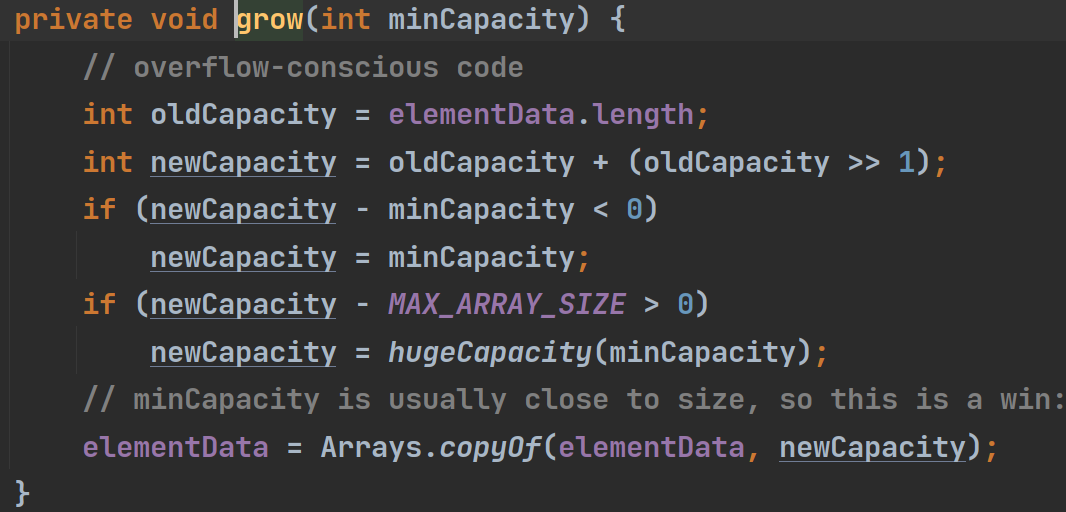
其实这个grow就是对elementData进行扩容的方法。可以看到它第一步先把当前elementData的长度赋值给oldCapacity,然后再将oldCapacity的1.5倍,那么如果elementData.length是0时,newCapacity会等于0,相当于没做扩容,于是下面那句就的针对这种情况进行处理,使得newCapacity = minCapacity, 而这时形参minCapacity的值是DEFAULT_CAPACITY传过来的,所以,newCapacity也为10
到这里我们终于知道了为什么elementData容量为0时,第一次扩容后是十了,因为初始容量为零是个特殊情况,他不能使newCapacity有实际意义,得进行特别处理
而且我们也可以看到,每次进行add的时候,不管elementData容量有多少,都会用ensureExplicitCapacity来判断容量够不够,这就导致了效率下降
ArrayList能完全代替数组吗
事实上虽然ArrayList很好用,但也一些时候还是得用数据
1.Java ArrayList 无法存储基本类型,比如 int、long,需要封装为 Integer、Long 类,而 Autoboxing、Unboxing 则有一定的性能消耗,所以如果特别关注性能,或者希望使用基本类型,就可以选用数组。
2. 如果数据大小事先已知,并且对数据的操作非常简单,用不到 ArrayList 提供的大部分方法,也可以直接使用数组。
3. 当要表示多维数组时,用数组往往会更加直观。比如 Object[][] array;而用容器的话则需要这样定义:ArrayList<ArrayList<object> > array。
总的来说,对于业务开发,直接使用容器就足够了,省时省力。毕竟损耗一丢丢性能,完全不会影响到系统整体的性能。但如果你是做一些非常底层的开发,比如开发网络框架,性能的优化需要做到极致,这个时候数组就会优于容器,成为首选。
Vector注意事项
① ArrayList和Vector基本相同,不过Vector有synchronized而ArrayList没有,但ArrayList执行效率更高,所以在多线程、需要保证线程同步安全的情况,不建议用ArrayList,而是去用Vector
②Vector也是对象数组来实现存储
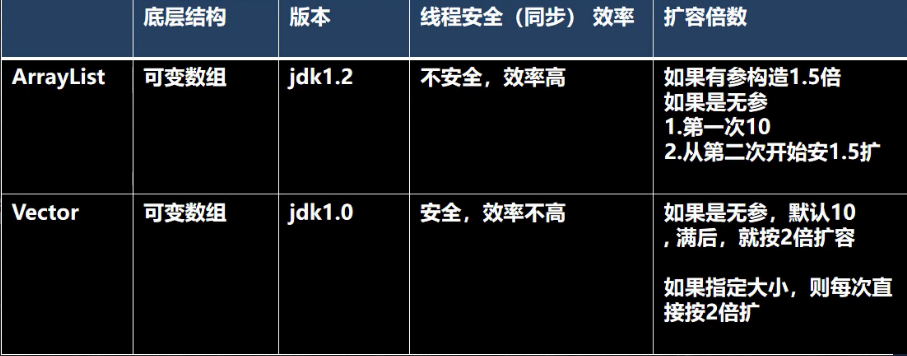
ArrayList和Vector的比较
LinkedList
①LinkedList底层实现了双向链表和双向队列特点,它底层维护了一个双向链表
②可以添加任意元素(包括null),可重复
③线程不同步,不安全
经典面试题:ArrayList和LinkedList的区别

注意,不管是ArrayList还是LinkedList都是线程不安全的!
Set接口,Collection的子接口之一
①无序(取出和存放的顺序不一定一致),不能通过索引来访问元素,而且注意取出顺序也是定好的,只不过跟存放顺序不一致罢了
②可以放任意元素,但不允许重复元素,所以最多放一个null
HashSet
①通过源码可以看到,HashSet其实是HashMap

②HashSet不保证元素有序的,每个元素索引的值是多少取决于hash
③经典面试题:为什么重写了toString后还要重写hashCode?
我们扒出HashSet的add方法的源码,可以看见,若要确定一个元素和集合中某个元素相同。必要条件之一是hash码也要相同,否则哪怕用了==或equals确认这两者相同也是当作不重复的元素

所以我们有必要把同类对象都赋予一个相同的hashcode,以便让集合更智能,更正确地判断出哪些是重复的元素,而且注意,这里是比较将要添加的元素和已有的元素的哈希码,也就是说这不是比较这两个元素的属性里面的哈希码,属性是否相等还是要看元素的属性对应的equals方法和==。
LinkedHashSet,HashSet的一个子类
①LinkedHashSet底层是一个LinkedHashMap,底层维护了一个数组 + 双向链表
②LinkedHashList的存储是根据HashCode来决定元素位置,同时使双向链表维护元素的次序,导致看上去取出顺序和放入顺序是一致的
链表维护元素的次序的步骤大致是这样的:
双向链表是指hash表的每一条链表都是双向链表,当添加一个元素时,用的HashMap的add方法,判断能不能添加,能添加的话新添加的元素的加入到双向链表里,双向链表中各个元素用before和after来连接
tail.after = new element; element.before = tail; tail = element;
然后哈希表的每个槽的链表都会在每个双向链表结点的next后面再加一个hnext,用来维护当前槽的链表顺序
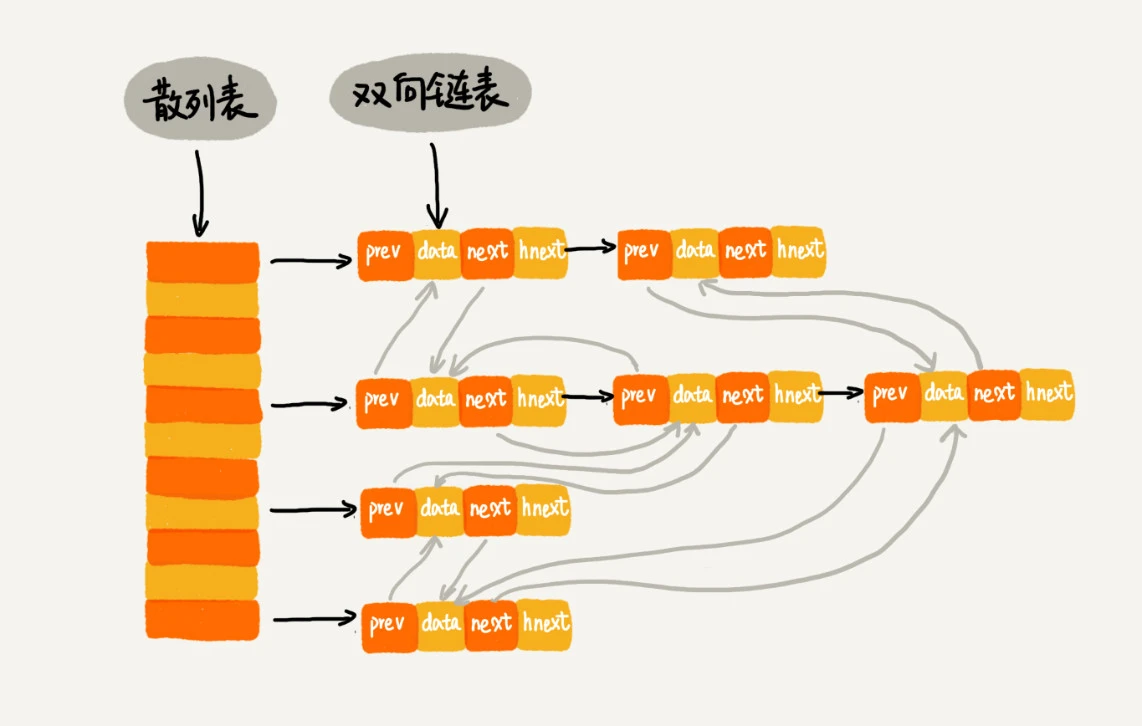
注意,LinkedHashSet里面,只有第threshold个元素的next不为空,当add到第threshold个元素时,触发扩容,在扩容后,threshold的next用来指向扩容前的空间的最后一个
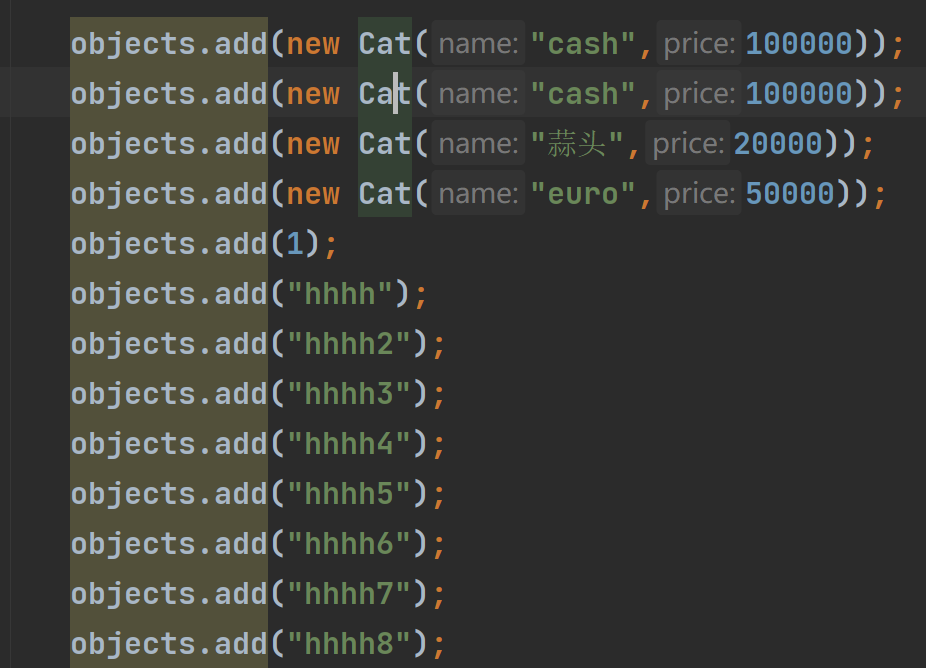
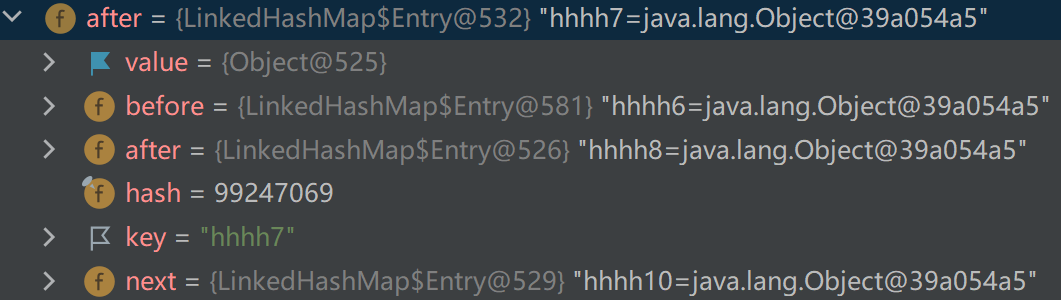
这里前两个add的元素按我设置的equals是当作不重复的,所以hhhh7是第十二个,达到了threshold,于是开始扩容,然后hhhh7的next指向第十六个,也就是hhh10,即扩容前空间的最后一个
③同样,不允许重复元素
TreeSet注意事项
①底层是TreeMap
②如果使用无参构造器,元素还是大概率是打乱的,我们可以使用参数为比较器的构造器,来进行我们想要的排序
public static void main(String[] args) { TreeSet treeSet = new TreeSet(new Comparator() { @Override public int compare(Object o1, Object o2) { return ((String)o1).compareTo(((String) o2));
//用来判断是否相等的条件,具体去看TreeMap的put方法,TreeSet的add是调用它的 } }); treeSet.add("son"); treeSet.add("dad"); treeSet.add("mom"); treeSet.add("mom"); for (Object obj: treeSet) { System.out.println(obj); } }
运行结果
dad
mom
son
双列集合
同理,双列集合就是每个元素是一对一对的,传进去的第一个形参是key,第二个形参是value,每个元素的形式为:key=value
HashMap hashMap = new HashMap(); hashMap.put(1,1); hashMap.put(2,2); hashMap.put(3,3); System.out.println(hashMap); 运行结果 {1=1, 2=2, 3=3}
JDK8的Map接口的实现类的特点
①Map用于保存有映射关系的数据:key - value,这两个数据存在单向的一对一关系,即可以通过get方法指定的key找到value,但没有提供方法通过value来找key,同时因为是映射关系,所以常用String类作为key,因为很多时候是表示名字或标识符,代码如下
public static void main(String[] args) { Map map = new HashMap(); map.put("x",1); System.out.println(map.get("x")); }
②Map中的key可以为null但不能重复,value也可以为null并且可以重复
为什么会这样呢?
拿HashMap来讲


一目了然,HashMap中的比较是不是相同元素是用key和key的hashcode来做比较标准的,所以value相不相同根本没有什么关系,其实也很容易理解,比如现在有两个男孩,一个叫小明,一个叫小亮,他们都是男孩(value),但是你能说这是同一个人吗?这要看你的评判标准是什么(equals方法),按我们生活中的默认比较方法,显然不是同一个人。
其实这也体现出了一些面对对象编程的味道,规划时面向的是一个个对象,操作的也是一个个对象,调用时也是一个个对象,比较的也是一个个对象,对象之间可能有相同的地方,你可以以此为据判断他们是相同的,这取决你的equals方法,你可以说一个人的性别名字出生日期相同就是一个人,可以说只要有耳朵就是同一个人,还可以说只要是中国人就是同一个人等等,只是有些比较标准会很荒唐而已
说回正题,这里简单来说就是只比较key,因为它的比较标准是自变量不能重复,所以value值重不重复无关,于是就被允许value重复了
③Map怎么存放key-value?
以下面代码为例子
public static void main(String[] args) { Map map = new HashMap(); map.put("x",1); map.put("y",2); map.put("z",3); map.put(new A(),new B()); //这两个内部类里面有迭代器,可以用迭代器分别只取出key或者values Set set = map.keySet(); Collection values = map.values();
}
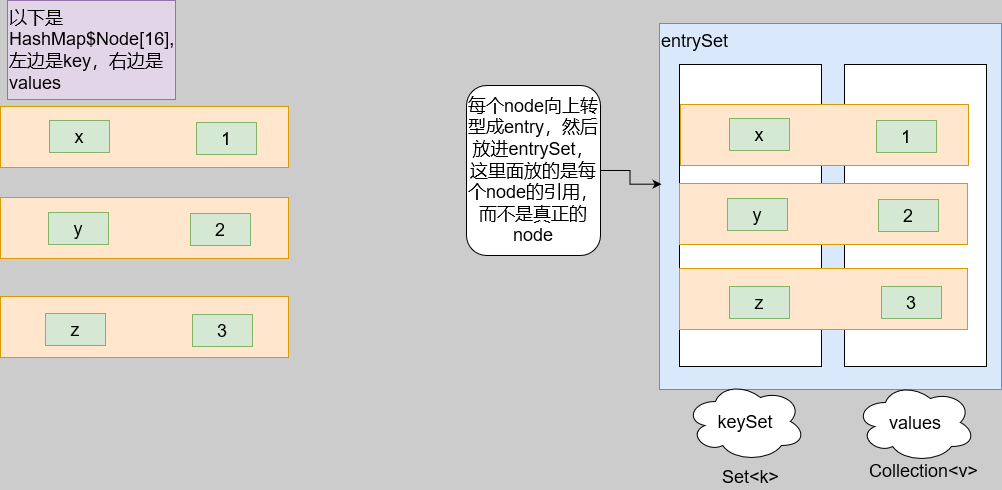
首先第一条语句,建立了一个新HashMap对象后,它会顺带建立了一个entrySet
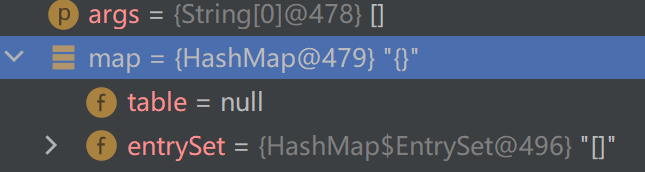
这个entrySet是什么呢,我们跳到他的源码看看

可以看到,这个entrySet是Set类型的,里面存放Map.Entry<k,v>及其子类的对象,可是这也只是知道放的是什么类型,还是不知道放了什么,我们继续执行代码
当把四个put方法都执行完后,情况如下

也就是说entrySet里面放的是HashMap的table里面的元素的引用,而且作者也解释了它的作用

可是又有一个问题:这都是Node类型啊,能符合entrySet的存放类型要求吗?没关系,我们来看Node源代码
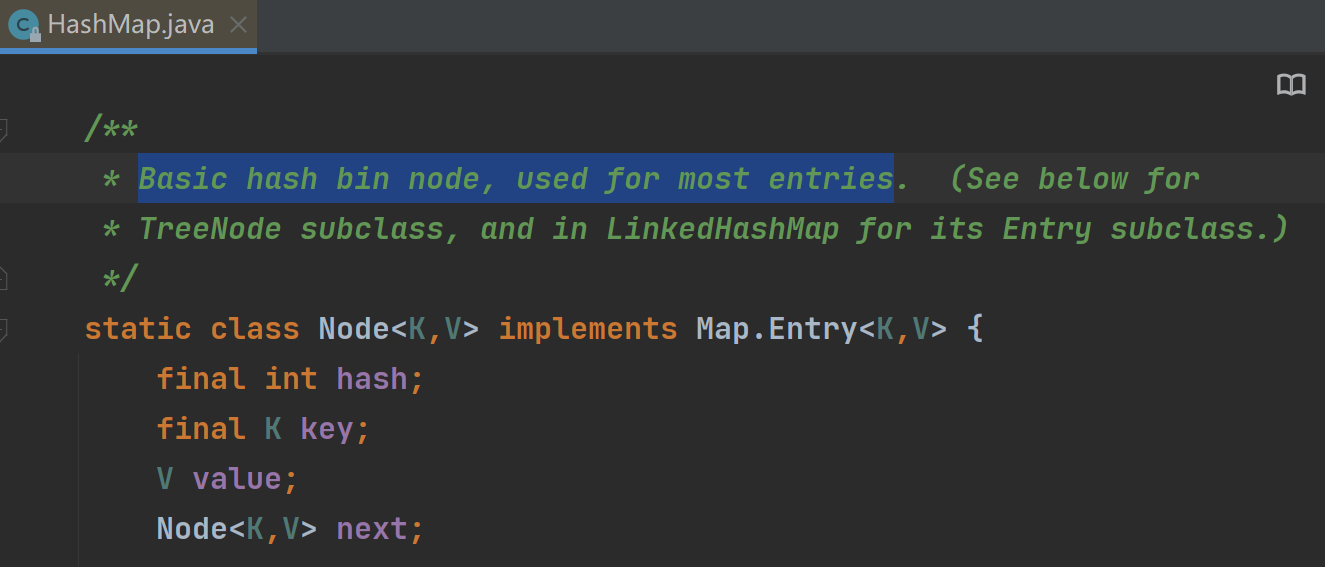
Node看来是实现了Entry的,这个Entry是Map接口的一个内部接口
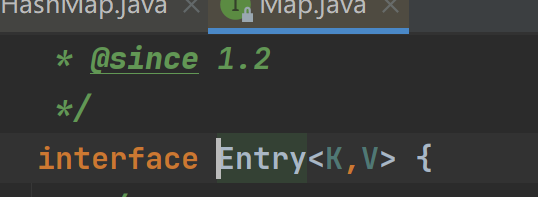
所以Node类型可以向上转型成Entry,然后存放进entrySet里面
那么为什么要特意把HashMap里面的node放进entrySet呢?
看看entrySet里面就知道了
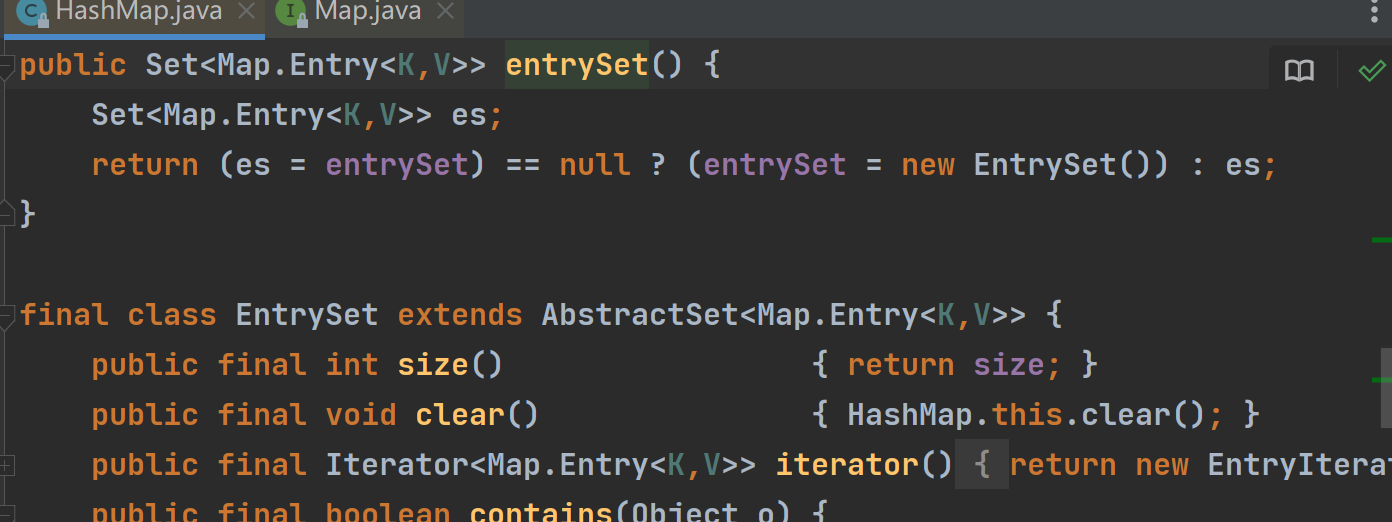
它是有一个迭代器的,这样方便我们遍历元素,也方便了Entry里面两个很重要的方法,就是下面这两个方法
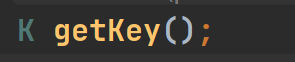
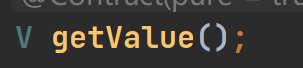
这两个方法顾名思义,就是专门单独拿出key和value
使用如下
Set set = map.entrySet(); for (Object obj: set) { Map.Entry entry = (Map.Entry)obj; System.out.println(entry.getKey() + "" + entry.getValue()); System.out.println(entry.getClass()); } 运行结果 x1 class java.util.HashMap$Node y2 class java.util.HashMap$Node z3 class java.util.HashMap$Node com.kzh.test.A@1b6d3586com.kzh.test.B@4554617c class java.util.HashMap$Node
可是entry里面单独拿key或者value似乎有点麻烦,还要进行向下转型,而且有时候条件不允许进行向下转型,那除了entry这两个方法,还有其他方法可以做到单独取出key或者value还更简单吗?答案是有,并且确实更简单




KeySet和Values两个类都有专属的迭代器,并分别是单独获取keys和values,使用如下
Set set1 = map.keySet(); Collection values = map.values(); Iterator iterator = set1.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next()); System.out.println(iterator.getClass()); } Iterator iterator1 = values.iterator(); while (iterator1.hasNext()) { System.out.println(iterator1.next()); System.out.println(iterator1.getClass()); } 运行结果 x class java.util.HashMap$KeyIterator y class java.util.HashMap$KeyIterator z class java.util.HashMap$KeyIterator com.kzh.test.A@1b6d3586 class java.util.HashMap$KeyIterator 1 class java.util.HashMap$ValueIterator 2 class java.util.HashMap$ValueIterator 3 class java.util.HashMap$ValueIterator com.kzh.test.B@4554617c class java.util.HashMap$ValueIterator
这两个类不用向下转型就能取出key或者value,而且因为它们用的迭代器来遍历,所以其实就是链表,也就是所有的key的引用在一个链表,所有的value的引用也在一个链表
到了这里,我们可以得出,Map的k-v的存放布局大致如下
HashMap注意事项
①HashMap里面没有synchronized,所以线程不安全
②Hashmap在JDK7中底层是数组 + 单向链表,在JDK8中是数组 + 单向链表 + 红黑树(JDK8中,当一条链表的元素个数达到8个及以上,且table的大小到了64及以上,就会树化这一条链表)
③HashMap扩容用的是put,这个put方法HashSet的add方法里面调用的put,所以扩容机制和HashSet一样,
- JDK1.7 是先扩容,在添加。具体put是否扩容需要两个条件:
1、 存放新值的时候当前已有元素的个数必须大于等于阈值
2、 存放新值的时候当前存放数据发生hash碰撞(当前key计算的hash值换算出来的数组下标位置已经存在值)
扩容方法是在addEntry方法中
- JDK1.8 是先添加,在扩容。具体put是否扩容需要满足一个条件:
当table中存储值的个数大于等于threshold的时候,进行扩容。容量为原来的2倍。
④可以放null
HashTable注意事项
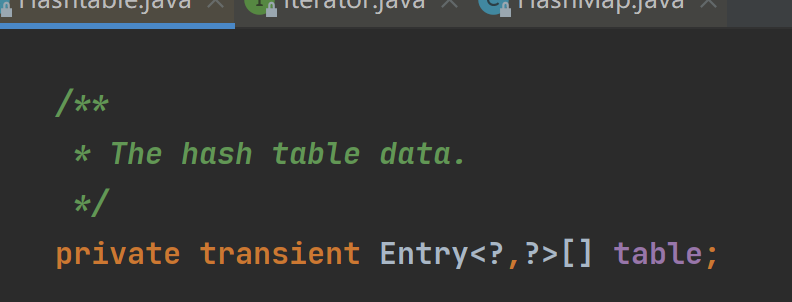
①HashTable底层的table是一个HashTable$Entry[ ] 类型的数组,调用无参构造器的话默认初始容量是11
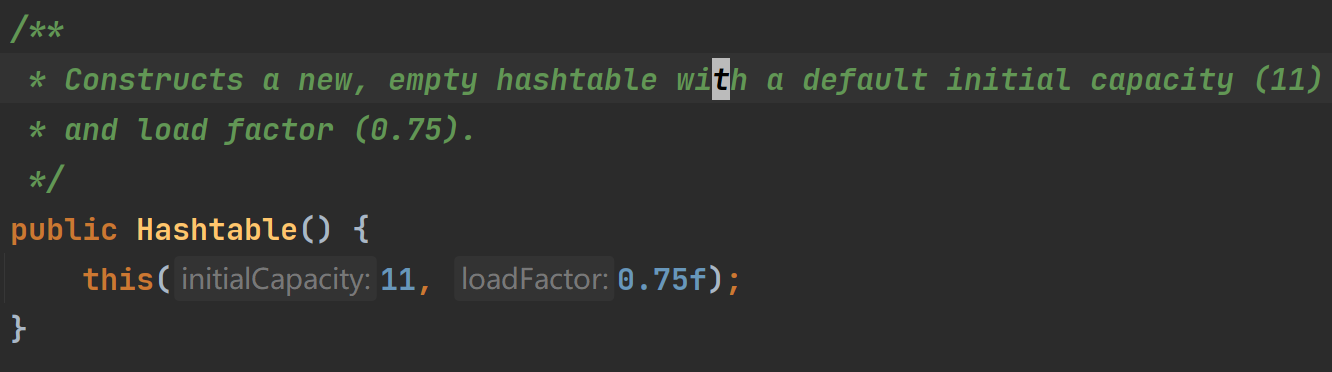
this调用的是另一个构造器
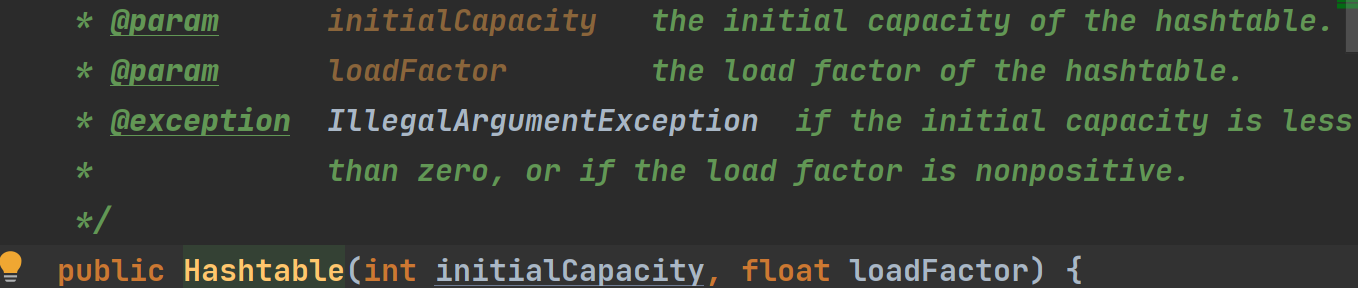
②扩容门槛和每次扩容数


③存放的是元素是key和value,key和value都不能为null
④HashTable使用方法基本和HashMap一致,并且HashTable是线程安全的
和HashMap的简单比较

Properties,HashTable的一个子类
①也是key和value的形式来保存元素,并且因为继承了HashTable,然后HashTable又实现了Map,所以也能用Map的方法
②Properties可以用于xxx.properties文件,可以将这种文件的数据加载到Properties对象中,进行读取或修改
TreeMap注意事项
①底层是TreeMap$Entry数组
②如果使用无参构造器,元素还是大概率是打乱的,我们可以使用参数为比较器的构造器,来进行我们想要的排序
★★集合的好处★★
(1)可以保存多个任意类型的对象
(2)提供了一系列操作对象的方法: add,remove,set,get等等
(3)集合要是想扩容或者删减,直接调用相应的自带方法即可
★★★开发中怎么去选择集合实现类★★★
(1)先判断存储的类型,看看它是一组对象还是一组k-v
(2)一组对象:Collection接口
允许重复:List
需要大量增删:LinekdList(底层维护一个双向链表)
需要大量改查:ArrayList(底层维护了一个Object类的可变数组)
不允许重复:Set
无序:HashSet (底层是一个HashMap,维护了一个hash表,即数组 + 链表 + 红黑树)
排序:TreeMap
放入和取出顺序一致:LinkedHashSet (维护了一个数组和一个双向链表,双向链表来维护元素的顺序)
一组键值对:Map接口
键无序:HashMap(底层是哈希表,JDK7,是数组 + 链表,JDK8,是数组 + 链表 + 红黑树)
键排序:TreeMap
键放入和取出顺序一样:LinkedHashMap
读取文件:Properties

 浙公网安备 33010602011771号
浙公网安备 33010602011771号