第5章网络层:控制平面
第5章网络层:控制平面
5.1 导论 笔记
5.1.1 本章目标

- 核心目标:理解网络层控制平面的工作原理
- 涵盖内容:
- 传统路由选择算法
- SDN 控制器
- ICMP(Internet Control Message Protocol,因特网控制消息协议)
- 网络管理(略讲)
- 实例与实现:OSPF、BGP、OpenFlow、ODL 和 ONOS 控制器、ICMP、SNMP
5.1.2 提纲

- 5.1 导论
- 5.2 路由选择算法(link state、distance vector)
- 5.3 因特网自治系统内的路由选择(RIP、OSPF)
- 5.4 ISP 之间的路由选择(BGP)
- 5.5 SDN 控制平面
- 5.6 ICMP:因特网控制报文协议
- 5.7 网络管理和 SNMP(略)
5.1.3 网络层功能与控制平面构建方法

- 网络层两大功能回顾:
- 转发:将分组从路由器的一个输入端口移到合适的输出端口(对应数据平面)
- 路由:确定分组从源到目标的路径(对应控制平面)
- 控制平面的 2 种构建方法:
- 传统方法:每个路由器独立实现控制功能
- SDN 方法:逻辑上集中的控制功能实现(软件定义网络)
5.1.4 传统方式:每一路由器控制平面
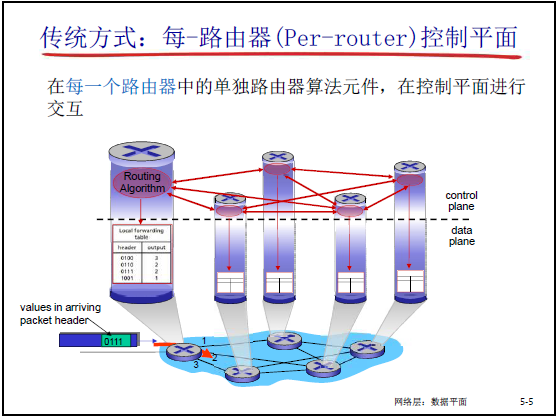
- 工作方式:垂直集成的分布式实现,每个路由器内置独立的路由算法元件,控制平面中各路由器的路由算法交互,生成路由表
- 存在问题:易被设备厂商绑定,网络工作方式僵化,部署后难以修改(因大规模路由器按现有协议工作,修改成本极高)
5.1.5 SDN 方式:逻辑上集中的控制平面
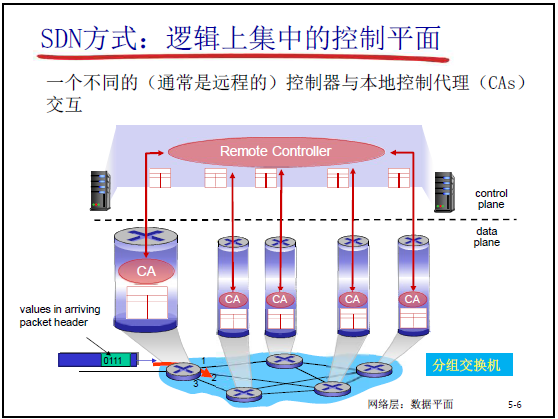
- 工作方式:控制平面与数据平面分离,由远程控制器和本地控制代理(CAs)交互;分组交换机通过控制代理向控制器上报状态,同时接收控制器下发的流表
- 优势:解决了传统方式的僵化问题,网络运作更灵活
5.2 路由选择算法
5.2.1 路由的基本概念


(1)路由的核心定义
- 路由是网络层控制平面的核心功能,需按照特 定指标(传输延迟、跳数、费用、队列长度等)找到从源子网(对应源路由器)到目标子网(对应目标路由器)的 “较好路径”(指标较小的路径)。
- 指标选择反映网络需求:如选 “跳数” 表示追求路径简洁,选 “延迟” 表示追求传输速度,选 “拥塞程度倒数” 表示追求路径通畅。
- 路由的本质是 “网络到网络的路由”,等价于 “路由器到路由器的路由”:
- 原因:主机到子网出口路由器、目标子网路由器到主机的通信由链路层(交换机、AP)解决,无需网络层路由;仅需确定 “源子网路由器→目标子网路由器” 的路径,即可实现主机间通信。
- 优势:以网络为单位计算路由,可减少路由信息传输、计算和匹配的代价(同一子网地址前缀相同、物理聚集)。
(2)路由选择算法的角色
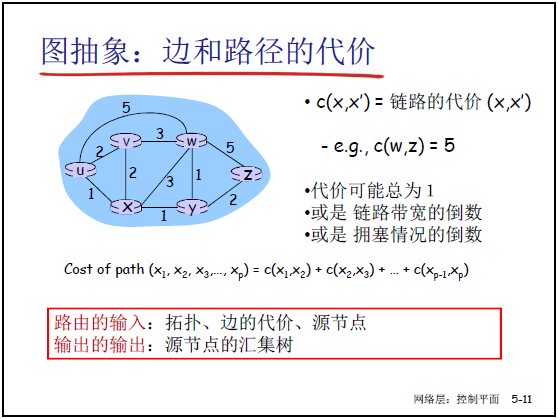
- 路由选择算法是网络层软件的一部分,核心输入为 “网络拓扑、边的代价、源节点”,输出为 “源节点到所有其他节点的最优路径集合(汇集树)”,最终生成路由表用于数据平面转发。
5.2.2 网络的图抽象与最优化原则
(1)图抽象模型
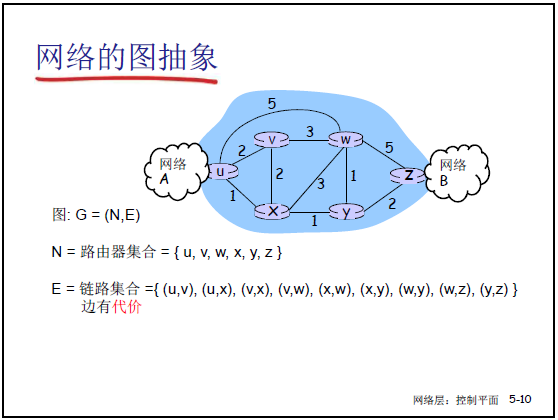
- 网络可抽象为无向图 G=(N,E):
- N(节点集合):代表路由器(或其所属子网),如课件 5-10 中 N={u,v,w,x,y,z};
- E(链路集合):代表路由器间的物理链路或子网,如课件 5-10 中 E={(u,v),(u,x),(v,x),...,(y,z)};
- 边的代价 c(x,x′):表示从节点 x 到 x′ 穿过链路 / 子网的代价,课件 5-11 举例 c(w,z)=5,代价可设为 1(跳数)、带宽倒数(带宽优先)、拥塞程度倒数(通畅优先)。
- 路径代价计算:路径 (x1,x2,...,xp) 的总代价为各段链路代价之和,即:Cost (x1,x2,...,xp) =c(x1,x2)+c(x2,x3)+...+c(xp−1,xp)
(2)最优化原则与汇集树
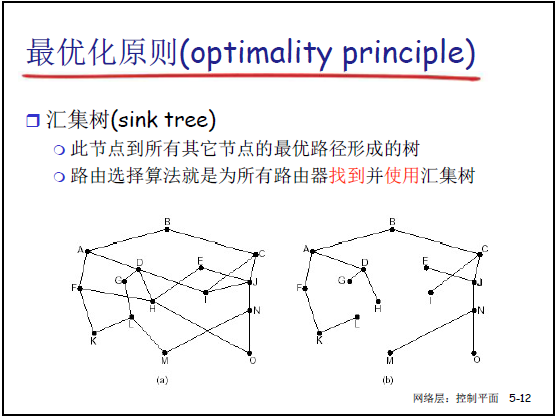
- 最优化原则:若路径 x→y→z 是 x 到 z 的最优路径,则 y→z 必为 y 到 z 的最优路径。
- 汇集树(Sink Tree):源节点到所有其他节点的最优路径构成的树,路由选择算法的核心目标是为每个路由器计算并维护其汇集树(确保转发时遵循最优路径)。
5.2.3 路由算法的分类

路由算法按 “路由信息范围” 和 “适应性” 分为两类,具体分类及特点如下表:
| 分类维度 | 算法类型 | 核心特点(对应课件 5-15 + 讲解) | 典型算法 |
|---|---|---|---|
| 路由信息范围 | 全局路由(Link State) | - 全局信息:每个路由器拥有完整的网络拓扑和边代价信息(“上帝视角”);- 计算方式:独立计算自身到所有节点的最优路径。 | 链路状态(LS) |
| 分布式路由(Distance Vector) | - 局部信息:仅知道直接邻居的存在及到邻居的代价;- 计算方式:迭代交换邻居的路由信息,逐步更新自身路由表。 | 距离矢量(DV) | |
| 适应性 | 静态路由(非自适应) | - 路由表预先计算,随时间变化缓慢;- 无法适应拓扑 / 拥塞变化,仅适用于小规模固定网络。 | 手动配置路由 |
| 动态路由(自适应) | - 路由表动态更新:1. 周期性交换路由信息;2. 链路代价 / 拓扑变化时触发更新;- 可适应网络动态变化。 | LS、DV |
路由选择算法的核心原则


- 正确性:确保分组能正确接力到目标,路由表包含所有目标地址表项(无未处理地址);
- 简单性:算法计算开销小,避免因传输路由信息占用过多带宽;
- 健壮性(鲁棒性):能快速适应拓扑变化(如链路断裂)和拥塞变化(如避开拥挤链路);
- 稳定性:路由结果不 “摇摆”(避免频繁切换路径);
- 公平性:对所有站点一视同仁,符合 IP “尽力而为” 的服务模型;
- 最优性:追求特定指标的最优(或次优,避免过度计算代价)。
5.2.4 链路状态(LS)路由选择算法

LS 算法是 “全局自适应路由算法”,核心是 “先获取全网拓扑,再用 Dijkstra 算法算最优路径”,分 5 步执行。
(1)LS 算法的 5 步工作过程

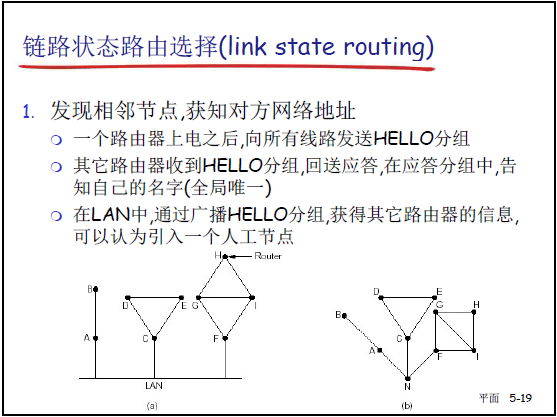



| 步骤 | 核心操作(对应课件内容) | 老师补充讲解 |
|---|---|---|
| 1 | 发现相邻节点,获知对方网络地址(课件 5-19): - 路由器上电后向所有端口发送 HELLO 分组; - 邻居路由器回送应答,告知自身全局唯一标识(如路由器 ID)。 |
LAN 中通过广播 HELLO 分组发现邻居,可抽象为 “人工节点” 简化交互。 |
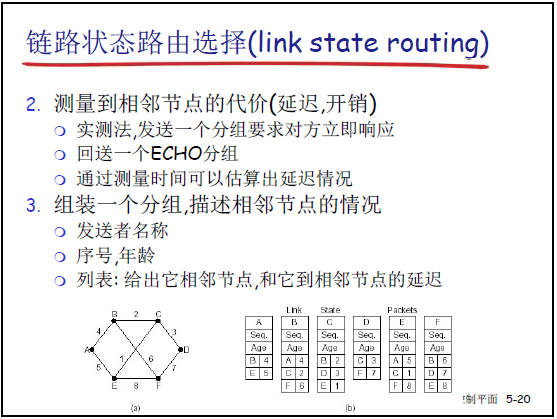
| 2 | 测量到相邻节点的代价(课件 5-20): - 发送 ECHO 分组,要求邻居立即响应; - 通过往返时间估算延迟(或直接测带宽、费用),作为边代价 c(x,x′)。 |
代价测量为 “实测法”,确保与实际链路状态一致(如延迟随拥塞变化时需重新测量)。 |
| 3 | 组装 LS 分组(课件 5-20): - 包含发送者 ID、序号、年龄、邻居列表(邻居 ID + 到邻居的代价)。 |
序号用于标识 LS 分组版本,年龄用于避免旧分组泛洪(见步骤 4)。 |
| 4 | 泛洪 LS 分组到全网(课件 5-21、5-22): - 每个路由器收到 LS 分组后,转发给所有非接收端口的邻居; - 用 “序号 + 年龄” 控制泛洪: - 记录(源路由器,序号),丢弃重复 / 旧分组; - 年龄字段每段时间减 1,为 0 时丢弃(避免环路泛洪)。 |
课件 5-22 用表格展示节点 B 的 LS 分组转发状态(Source、序号、年龄、发送 / 确认标记),确保泛洪可靠(需邻居确认接收)。 |
| 5 | 用 Dijkstra 算法计算最优路径(课件 5-23、5-24 至 5-28): - 基于全网 LS 分组构建拓扑和代价矩阵; - 独立计算自身到所有节点的最优路径(汇集树),生成路由表。 |
这是 LS 算法的 “核心计算步骤”,Dijkstra 算法的输入为 “源节点、拓扑、边代价”,输出为 “汇集树”。 |
(2)Dijkstra 算法详解
①符号定义
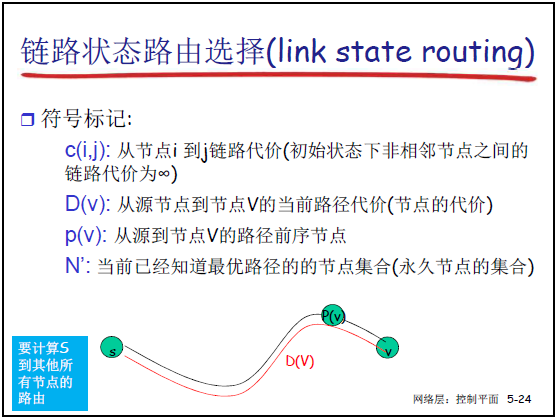
- c(i,j):节点 i 到 j 的链路代价(非邻居节点初始为 ∞);
- D(v):源节点到节点 v 的当前路径代价(初始时非邻居节点为 ∞);
- p(v):源节点到 v 的路径前序节点(用于构建路径);
- N′:已确定最优路径的 “永久节点集合”(初始仅含源节点);
- T:未确定最优路径的 “临时节点集合”(初始含除源节点外的所有节点)。
②算法步骤初始化:

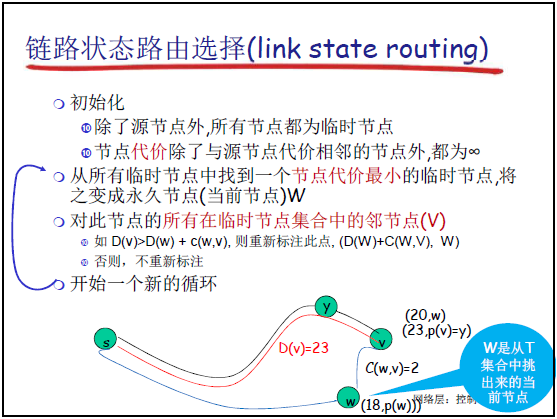
-
- N′={S}(S 为源节点),D(S)=0,p(S)=无;
- 对所有 v∈/N′,D(v)=c(S,v)(邻居节点为实际代价,非邻居为 ∞),p(v)=S(邻居节点)或 “无”(非邻居)。
- 迭代计算:
- 从 T 中选 D(v) 最小的节点 W,将 W 加入 N′;
- 对 W 的所有邻居 v∈T,若 D(v)>D(W)+c(W,v),则更新:D(v)=D(W)+c(W,v),p(v)=W;
- 重复步骤 2,直到 T=∅(所有节点均为永久节点)。
③算法示例
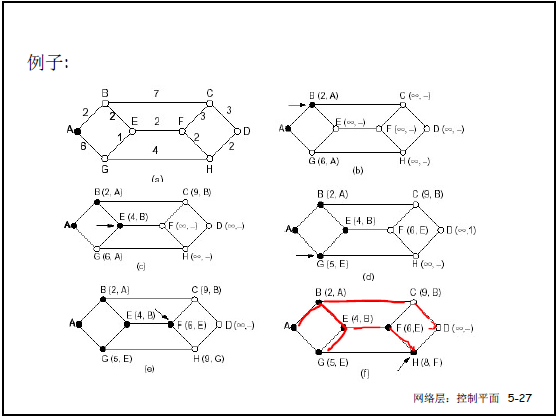
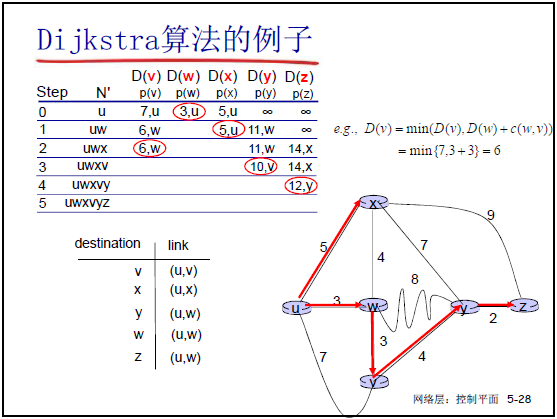
以源节点 u 为例,课件 5-28 用表格展示迭代过程,核心步骤如下:
| 步骤 | 永久节点集合 N′ | D(v)(p(v)) | D(w)(p(w)) | D(x)(p(x)) | D(y)(p(y)) | D(z)(p(z)) |
|---|---|---|---|---|---|---|
| 0 | {u} | 7(u) | 3(u) | 5(u) | ∞ | ∞ |
| 1 | {u,w} | 6(w)(min(7,3+3)) | - | 5(u) | 11(w) | ∞ |
| 2 | {u,w,x} | 6(w) | - | - | 11(w) | 14(x) |
| 3 | {u,w,x,v} | - | - | - | 10(v) | 14(x) |
| 4 | {u,w,x,v,y} | - | - | - | - | 12(y) |
| 5 | {u,w,x,v,y,z} | - | - | - | - | - |
- 最终生成 u 的路由表(课件 5-28):目标子网对应输出接口,如到 v 从 (u,v) 转发,到 w/y/z 从 (u,w) 转发。
(3)LS 算法的特点
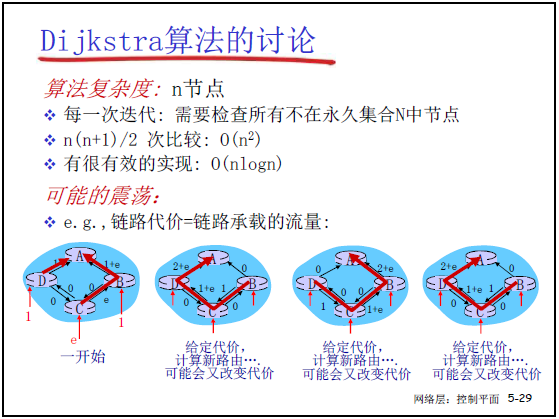
- 复杂度:n 节点时,Dijkstra 算法时间复杂度为 O(n2),优化实现(如堆排序)可降至 O(nlogn);
- 潜在问题:链路代价若设为 “链路承载流量”,可能导致路径震荡(如所有路由器同时切换到 “低代价路径”,导致该路径拥塞、代价升高,再切换回原路径);
- 应用:OSPF 协议(自治系统内路由)、IS-IS 协议(互联网主干路由)。
5.2.5 距离矢量(DV)路由选择算法
DV 算法是 “分布式自适应路由算法”,核心是 “基于 Bellman-Ford 方程,迭代交换邻居的距离矢量,逐步收敛到最优路径”,广泛应用于 RIP 等协议(课件 5-31)。
(1)DV 算法的核心概念

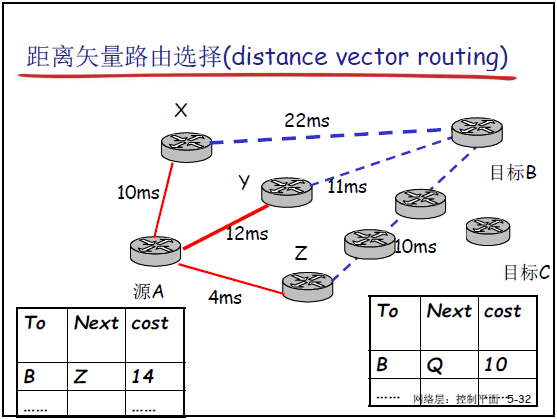

- 距离矢量:每个路由器维护 “距离矢量 D**x=[D**x(y)∣y∈N]”,其中 D**x(y) 是节点 x 到 y 的当前代价估计;
- 路由表结构:包含 “目标子网(To)、下一跳(Next)、代价(Cost)”,如到目标 A 的下一跳为 Z,代价 14;
- 代价获取:邻居间代价通过 “实测法”(如延迟测量)获得,目标代价通过 “邻居通告的距离矢量” 计算。
(2)DV 算法的工作过程
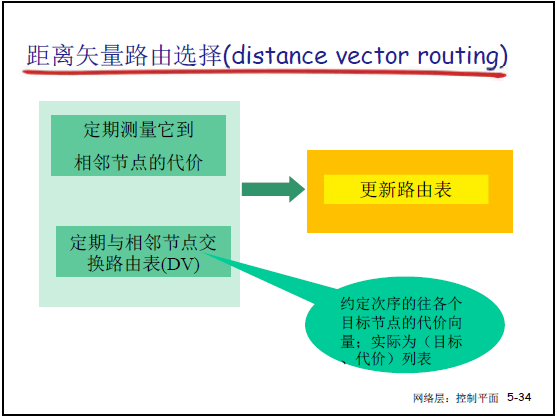
| 核心操作 | 对应课件内容 | 老师补充示例 |
|---|---|---|
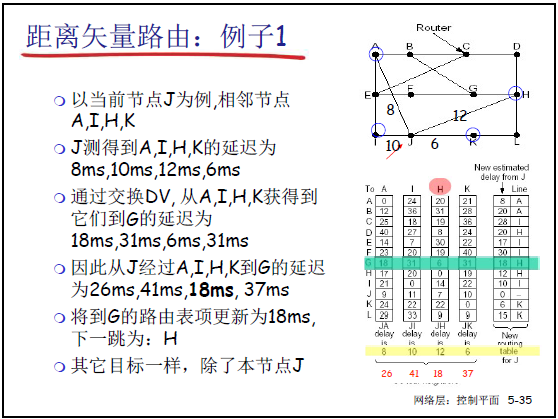
| 1. 测量邻居代价 | 定期测量到相邻节点的代价(跳数、延迟、队列长度),如课件 5-33 中 “实测延迟”。 | 路由器 J 测到邻居 A/I/H/K 的延迟为 8/10/12/6ms(课件 5-35)。 |
| 2. 交换距离矢量 | 定期(如 RIP 每 30 秒)与邻居交换距离矢量(目标 + 代价),或路由变化时触发更新(课件 5-34)。 | J 从 A/I/H/K 获取到 G 的延迟为 18/31/6/31ms(课件 5-35)。 |
| 3. 更新路由表 | 按 Bellman-Ford 方程计算最优代价:D**x(y)=minv{c(x,v)+D**v(y)}(课件 5-36) | J 计算经 A/I/H/K 到 G 的延迟:26/41/18/37ms,选最小 18ms,下一跳设为 H(课件 5-35)。 |
(3)Bellman-Ford 方程(对应课件 5-36、5-52、5-53)

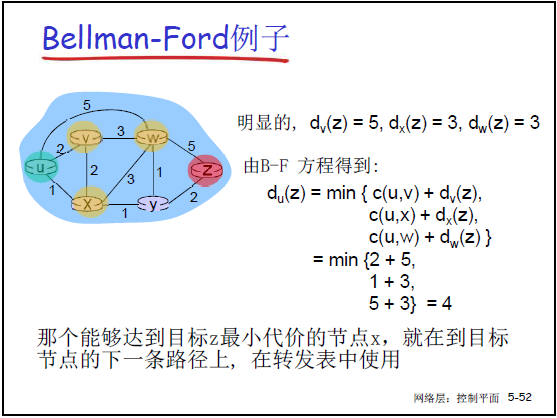

- 定义:设 dx(y) 为节点 x 到 y 的最小路径代价,则 dx(y)=minv{c(x,v)+dv(y)}(v 为 x 的邻居);
- 示例(课件 5-52):源节点 u 到目标 z,邻居为 v/x/w,已知 c(u,v)=2、dv(z)=5;c(u,x)=1、dx(z)=3;c(u,w)=5、dw(z)=3,则:du(z)=min{2+5,1+3,5+3}=4,下一跳为 x(对应最小代价的邻居)。
(4)DV 算法的关键特性

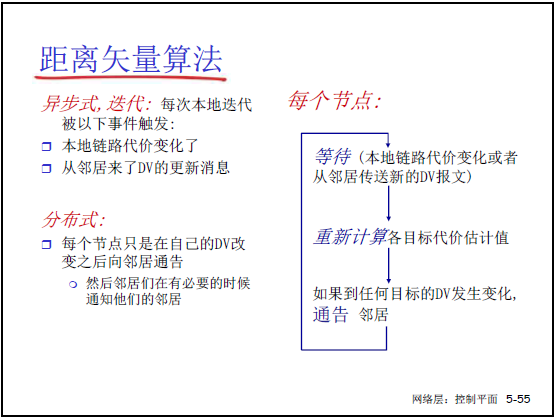
- 异步迭代:触发迭代的事件:
- 本地链路代价变化(如延迟升高);
- 收到邻居的距离矢量更新;
- 分布式收敛:仅当自身距离矢量变化时,才向邻居通告,邻居再根据更新迭代,最终 D**x(y) 收敛到实际最小代价 d**x(y)。
(5)DV 算法的 “无穷计算” 问题及解决
①问题本质:好消息传得快,坏消息传得慢


- 好消息(如链路通、代价降低):每迭代一次传播一个路由器,如课件 5-41 中 A 接入后,B/C/D/E 依次获知可达,3 次迭代收敛;
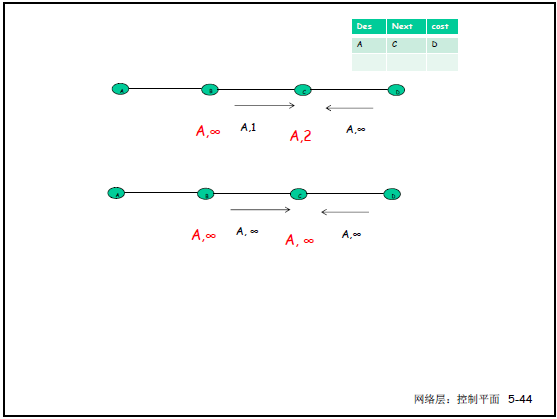
- 坏消息(如链路断、代价升高):易形成环路,导致 “无穷计算”,如课件 5-42 中 A-B 链路断裂后:
- B 从 C 获知 “C 到 A 代价 2”(实际 C 需经 B 到 A),B 更新到 A 代价 3;
- C 从 B 获知 “B 到 A 代价 3”,C 更新到 A 代价 4;
- 迭代至代价为 16(RIP 中 “无穷大”),才确认 A 不可达。
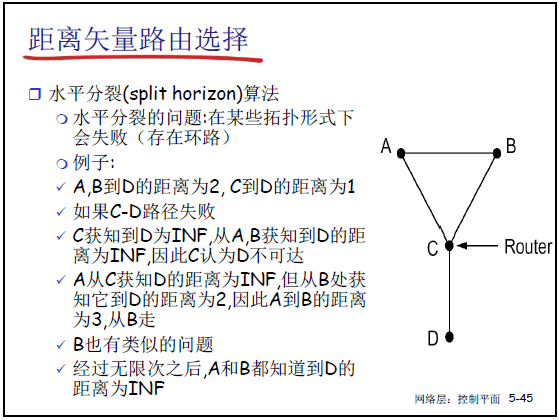
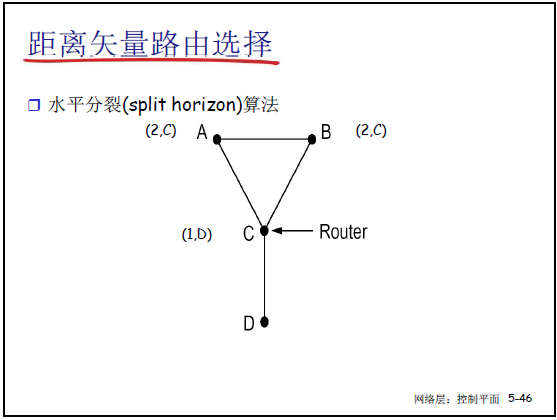
②解决方法:水平分裂(Split Horizon)

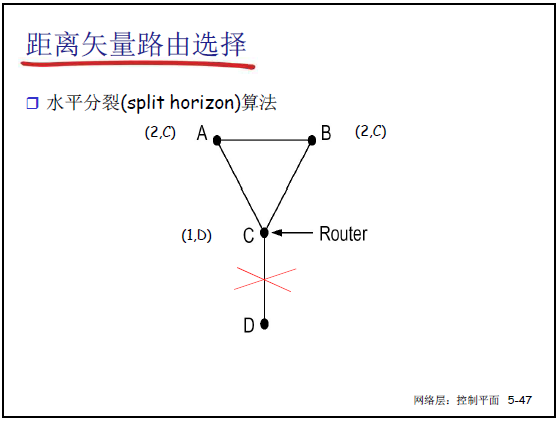
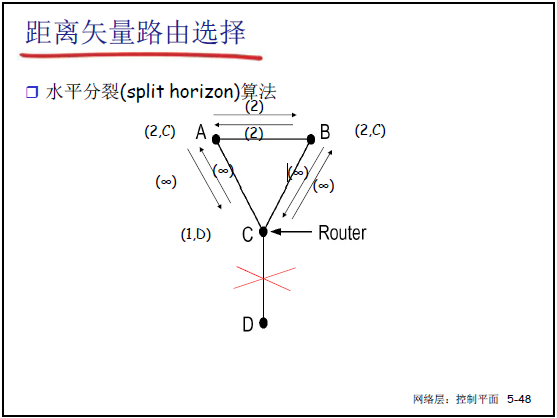
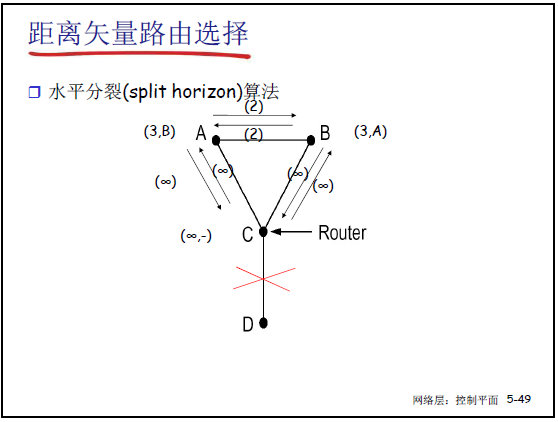
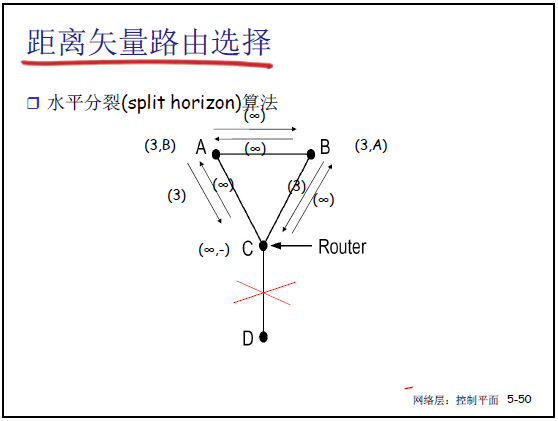
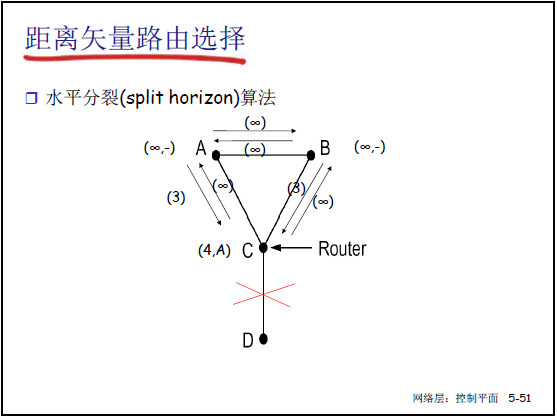
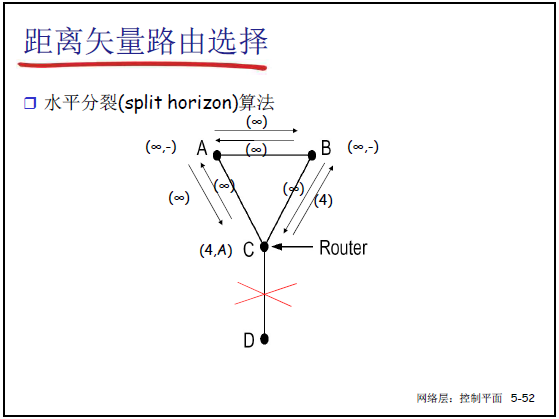
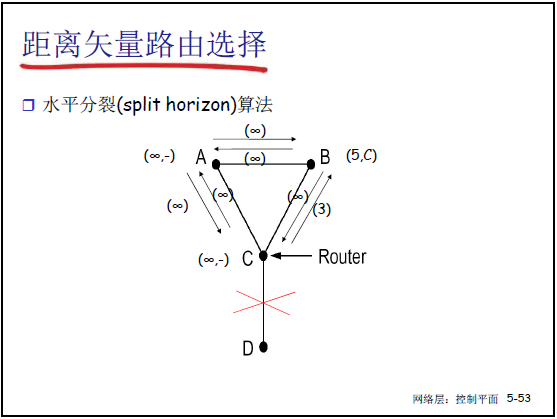
- 核心思想:若路由器 C 经 B 到达 A,则 C 向 B 通告 “到 A 的代价为 ∞”(不向 “下一跳方向” 传播可达信息),避免环路;
- 示例(课件 5-43):A-B 链路断裂后:
- B 测量到 A 不可达,C 向 B 通告 “到 A 代价 ∞”,B 立即确认 A 不可达;
- C 再从 D 获知 “到 A 代价 ∞”,C 确认 A 不可达;
- 坏消息按 “一次迭代传播一个路由器” 收敛,避免无穷计算。
- 局限:环状拓扑中可能失效(如课件 5-45 中 A-B-C-D 环路,C-D 链路断裂后,A 和 B 仍会互传可达信息,需多次迭代收敛)。
(6)DV 算法的迭代示例
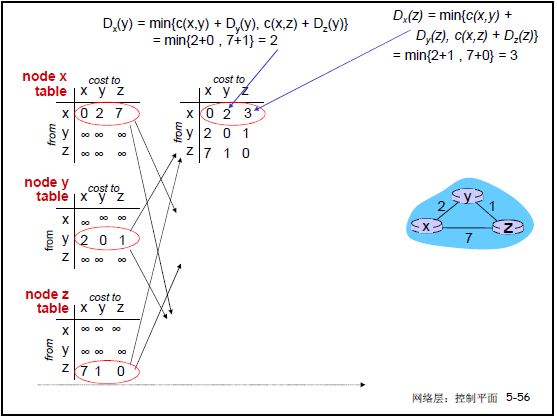
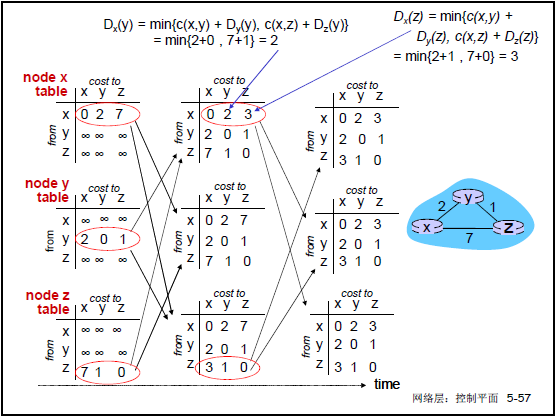
以节点 x、y、z 构成的网络为例(课件 5-56):
- 初始状态:x 到 y 代价 2,x 到 z 代价 7;y 到 z 代价 1;
- 迭代 1:y 向 x 通告 D**y(z)=1,z 向 x 通告 D**z(y)=1;
- 迭代 2:x 计算 D**x(z)=min{2+1,7+0}=3,D**x(y)=min{2+0,7+1}=2;
- 收敛结果:x 到 y 代价 2(下一跳 y),x 到 z 代价 3(下一跳 y)。
5.2.6 LS 与 DV 算法的对比

| 对比维度 | 链路状态(LS)算法 | 距离矢量(DV)算法 | 结论(对应课件 + 老师讲解) |
|---|---|---|---|
| 消息复杂度 | 高:n 节点、E 链路时,需泛洪 O(n**E) 个 LS 分组(全网传播局部信息) | 低:仅与邻居交换距离矢量(局部传播全局信息) | DV 胜出,LS 因泛洪占用更多带宽 |
| 收敛时间 | 快:O(n2)(Dijkstra 算法),无环路风险(仅潜在震荡) | 慢:需多次迭代,坏消息可能 “无穷计算”,有环路风险 | LS 胜出,DV 收敛效率低 |
| 健壮性(鲁棒性) | 高:节点仅通告自身链路代价,错误信息影响局部(如某节点发虚假代价,仅影响经该节点的路径) | 低:节点通告全网目标代价,错误信息扩散全网(如某节点发虚假 “到所有目标代价 0”,导致全网分组涌向该节点) | LS 胜出,DV 抗故障能力弱 |
| 应用场景 | 大规模网络(如自治系统内核心路由,OSPF) | 中小规模网络(如企业网边缘路由,RIP) | 各有适用,互联网中均有部署 |
5.3 因特网中自治系统内部的路由选择
自治系统(AS)内部的路由选择通过 内部网关协议(IGP) 实现,互联网中常用的 IGP 包括两类:基于距离矢量算法的 RIP、基于链路状态算法的 OSPF。
5.3.1 RIP(Routing Information Protocol)
(1)RIP 基本信息
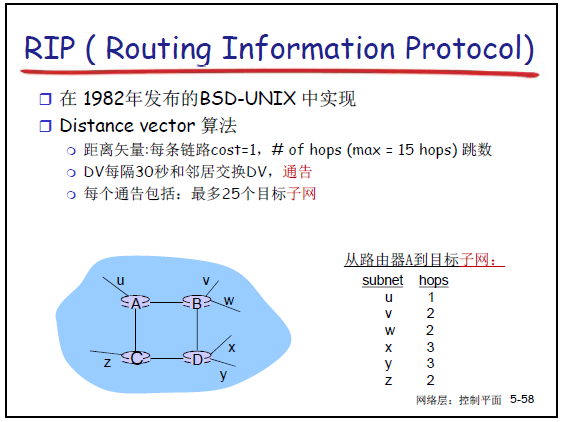
- 实现与算法:1982 年在 BSD-UNIX 系统中实现,基于距离矢量算法。
- 代价度量:以 “跳数” 为代价(每条链路 cost=1),最大跳数为 15(跳数 = 16 时标记目标不可达)。
- 路由通告:相邻路由器每 30 秒交换距离矢量(DV)报文(称为 “路由通告 /advertisement”);每个通告最多包含 25 个目标子网的 DV 信息(需同时携带 “目标子网” 和 “对应跳数”)。
(2)RIP 通告规则

- 通告触发时机:
- 定期触发:每 30 秒主动向邻居发送 DV 报文;
- 事件触发:自身路由表发生变化时,主动发送新的 DV 报文;
- 按需触发:响应邻居的 DV 请求时发送报文。
- 通告限制:
- 单个通告最多包含 25 个目标子网的 DV;
- 目标不可达时,跳数标记为 16。
(3)RIP 路由表更新示例
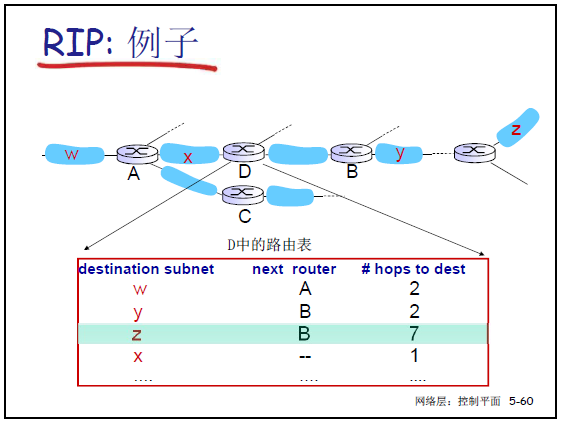
- 课件 5-60:路由器 D 的初始路由表包含 “目标子网、下一跳路由器、跳数”3 项,例如:
- 到子网 W:下一跳是 A,跳数 2;
- 到子网 Z:下一跳是 B,跳数 7;
- 到子网 X:本地直连,跳数 1。
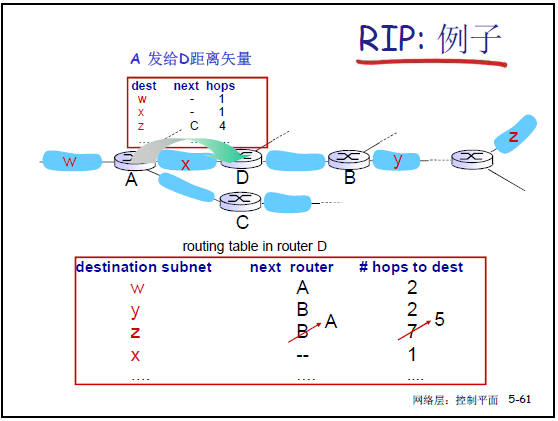
- 课件 5-61:路由表更新过程A 向 D 发送距离矢量(A 到 Z 的跳数为 4),D 计算 “自身到 A 的跳数(1)+ A 到 Z 的跳数(4)= 5”,因 5 < 原跳数 7,故更新 Z 的路由:下一跳改为 A,跳数更新为 5。
(4)RIP 链路失效与恢复

- 失效判定:若 180 秒(6 个 30 秒周期)未收到某邻居的通告,判定该邻居或对应链路失效。
- 失效传播:自身路由表更新后,向邻居发送新通告,路由变化信息通过 “一跳传一跳” 的方式传遍全网。
- 防环路措施:采用毒性逆转 + 水平分裂机制;将不可达目标的跳数标记为 16(表示不可达)。
(5)RIP 进程处理
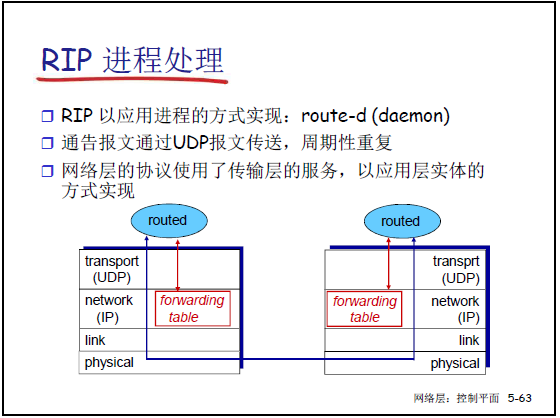
- 实现方式:以应用层守护进程(route-d)的形式运行。
- 通告传输:通过 UDP 报文周期性传输距离矢量。
- 特殊特点:网络层的路由功能,以应用层进程的形式实现,且借助传输层的 UDP 协议传输路由信息。
5.3.2 OSPF(Open Shortest Path First)
(1)OSPF 基本信息

- 协议特性:“Open” 表示标准公开,不同厂商的路由器可互操作;基于链路状态算法。
- 算法逻辑:
- 链路状态(LS)分组在 AS 内(或区域内)泛洪;
- 每个节点获取全网(或区域内)的拓扑与链路代价;
- 用 Dijkstra 算法计算到所有目标的最短路径,生成并装载路由表。
- 通告内容:LS 分组携带 “自身标识、分组版本、TTL、邻居列表及对应链路代价”。
- 传输方式:直接通过 IP 数据报传输(不借助 UDP/TCP)。
- 类似协议:IS-IS(功能与 OSPF 几乎一致)。
(2)OSPF 高级特性

- 安全认证:所有 OSPF 报文经过认证,防止恶意伪造或攻击。
- 多等价路径:允许多条代价相同的路径共存,支持负载均衡。
- 多重代价矩阵:对同一条链路,可按不同服务类型(TOS)设置代价(如按延迟、跳数、拥塞程度计算最优路径),方便网络管理员灵活配置。
- 单播 / 多播支持:Multicast OSPF(MOSPF)利用同一拓扑数据库,构建优化的多播树。
- 层次化支持:大型网络中可划分区域,限制 LS 分组的泛洪范围。
(3)层次化的 OSPF 路由
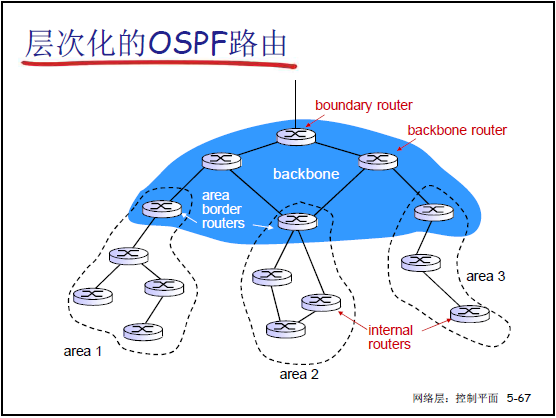

- 区域划分:将 AS 分为 “骨干区域(area 0)” 和多个 “本地区域(area 1、area 2…)”。
- 区域内路由:
- LS 分组仅在本区域内泛洪;
- 节点仅维护本区域的拓扑信息,计算区域内的最短路径。
- 区域间路由:
- 需通过区域边界路由器:将本区域的路由汇总后,通告到骨干区域;
- 骨干区域(area 0)负责转发不同区域间的路由;
- 目标区域的边界路由器将路由转发到目标子网。
- 路由器角色:
- 区域边界路由器:同时参与 “本区域” 和 “骨干区域” 的 LS 泛洪与路由计算(“一人分饰两角”);
- 骨干路由器:仅在骨干区域内运行 OSPF;
- 自治系统边界路由器:连接其他 AS,负责转发跨 AS 的路由。
- 划分好处:限制 LS 分组的泛洪范围,降低大型网络的路由计算开销。
5.4 ISP 之间的路由选择:BGP
5.4.1平面路由的局限性

(1)规模问题:计算与传输代价不可承受
老师讲课中明确提到,互联网若采用 “平面路由”(所有路由器地位平等,用单一协议解决全网路由),无论距离矢量(DV)还是链路状态(LS)算法都无法应对:
- 链路状态(LS)算法困境:若全球有 100 万个网络(未来 IPv6 规模更大),每个路由器需生成 “链路状态分组(LSP)” 并向其他 99.9999 万个节点泛洪。仅存储所有节点的 LSP 就需 “百万级” 数据量,再用 Dijkstra 算法计算最短路径时,复杂度达 “节点数平方”(即 10¹² 量级),当前计算机无法承载,且 LSP 泛洪的带宽消耗也会拖垮网络。
- 距离矢量(DV)算法困境:DV 需通过 “邻居 - 邻居” 逐跳扩散距离矢量(到所有目标的代价)。在百万级节点规模下,扩散需无数次迭代才能收敛,且可能出现 “未收敛就已拓扑变化” 的情况,导致路由永久震荡,无法形成有效转发表。
(2)管理问题:自主管理与拓扑隐私需求无法满足
老师以 “科大校园网” 和 “其他单位网络” 为例,指出不同机构的核心诉求:
-
希望按自身规则管理网络(如选择私有路由协议),而非全网统一协议;
-
需隐藏内部网络拓扑(如校园网的楼宇子网结构),仅对外暴露 “整体可达” 的信息,避免安全风险(如拓扑泄露导致的攻击)。
平面路由要求全网统一协议且拓扑透明,完全无法满足这类管理与安全诉求。
5.4.2层次路由的解决方案

(1)自治系统(AS)的定义与标识
为解决平面路由的问题,互联网被划分为多个自治系统(AS,Autonomous System),老师对 AS 的核心解读如下:
- AS 本质:某一机构(如 ISP、高校、企业)管理的路由器与子网集合,拥有独立的路由管理权限;
- AS 标识:每个 AS 分配唯一的AS 号(ASN),由 IANA 统一分配(如科大校园网对应一个 AS 号);
- ISP 与 AS 的关系:一个 ISP 可能包含 1 个或多个 AS(若 ISP 规模大,可拆分为多个 AS 便于管理)。
(2)两层路由架构:AS 内与 AS 间
互联网路由被拆分为两个独立但协同的层面,老师用 “分层解决问题” 的逻辑讲解:
| 路由层面 | 解决问题 | 协议类型 | 核心特点 |
|---|---|---|---|
| AS 内路由(Intra-AS) | AS 内部子网 / 路由器的可达性 | 内部网关协议(IGP) | 各 AS 自主选择协议(如 RIP、OSPF、思科私有 IGRP),规模可控 |
| AS 间路由(Inter-AS) | 不同 AS 之间的互联互通 | 外部网关协议(BGP) | 全网统一协议,每个 AS 视为 “一个点”,简化规模 |
老师强调:AS 内路由因 “子网 / 路由器数量有限”(如校园网仅几十台核心路由器),无论 DV 还是 LS 算法都能高效运行;若 AS 规模过大,可进一步拆分 AS,确保内部规模始终可控。
5.4.3层次路由的核心优势

(1)解决规模问题:从 “全网规模” 到 “分层可控”
老师通过 “AS 内” 和 “AS 间” 两个维度拆解规模优势:
- AS 内规模可控:每个 AS 内部的子网 / 路由器数量有限(如企业 AS 仅 10-20 台路由器),LS 算法的 LSP 泛洪、Dijkstra 计算,或 DV 算法的迭代收敛,都能在毫秒级完成,资源消耗极低;若 AS 过大,可拆分为多个小 AS(如 “中国电信北方 AS” 和 “中国电信南方 AS”),进一步降低单 AS 规模。
- AS 间规模可扩展:AS 间路由中,每个 AS 仅视为 “一个点”。新增一个 AS 时,其他 AS 的网关路由器仅需新增 “一条到该 AS 的路由表项”,而非百万级的子网表项。老师特别解释 “可扩展性”:随着 AS 数量增加,路由计算 / 传输代价会缓慢上升(而非断崖式下降),能支撑互联网千万级 AS 的规模。
(2)解决管理问题:自主权限与拓扑隐私保障
老师明确:AS 是 “管理权限的边界”,核心优势体现在:
- 协议自主选择:AS 内可选择任意 IGP(如小规模 AS 用简单的 RIP,大规模 AS 用高效的 OSPF),甚至私有协议(如思科设备的 IGRP),无需受全网约束;
- 拓扑隐私隐藏:AS 仅对外通告 “本 AS 包含的子网前缀”(如 “10.0.0.0/8”),不暴露内部子网结构(如 “10.1.1.0/24”“10.1.2.0/24” 的具体连接),满足安全与管理需求。
5.4.4BGP 的核心定位与分类

(1)BGP 的地位:AS 间路由的 “事实标准”
将 BGP 比喻为 “互联网的泡泡糖”—— 粘合所有 AS 的核心协议:
- 事实标准定义:BGP 并非由标准化机构(如 IETF)强制制定,而是因全网广泛使用、约定俗成形成的标准,所有 ISP 的 AS 间路由均依赖 BGP;
- 核心功能:实现 AS 间的 “子网可达信息交换” 与 “路径选择”,确保分组能从一个 AS 跨越多个 AS 到达目标 AS。
(2)BGP 的两大分支:eBGP 与 iBGP
老师详细拆解了 BGP 的两个核心组成部分,明确其分工:
| BGP 类型 | 英文全称 | 作用场景 | 核心功能 |
|---|---|---|---|
| eBGP | External BGP | 不同 AS 的网关路由器之间 | 1. 收集本 AS 的子网可达信息(网关通过参与 AS 内 IGP 获取); 2. 向相邻 AS 的网关通告这些信息,承诺 “可转发到本 AS 子网” |
| iBGP | Internal BGP | 同一 AS 内部的网关路由器之间 | 1. 接收 eBGP 传来的 “其他 AS 子网可达信息”; 2. 通过 TCP 连接通告给 AS 内所有网关(及部分核心路由器),确保 AS 内所有路由器知晓外部子网路径 |
老师特别强调 “网关的双重角色”:AS 的网关路由器既要运行 eBGP(与外部 AS 交互),也要运行 IGP(参与 AS 内路由,获取内部子网信息),同时运行 iBGP(向内部其他网关传递外部信息),是 AS 间路由的 “核心枢纽”。
5.4.5 eBGP 与 iBGP 的连接关系
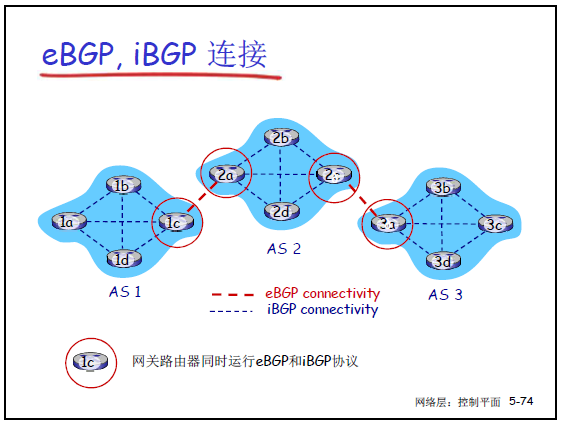
课件 5-74 用拓扑图展示了 AS1、AS2、AS3 的网关连接,老师结合图中标识(红色虚线、黑色虚边)详细讲解:
- 红色虚线(eBGP 连接):不同 AS 的网关之间的逻辑连接(非物理链路),基于 TCP 建立半永久连接。例如 AS1 的网关 1c 与 AS2 的网关 2a 之间,通过 eBGP 交换 “AS1 子网” 和 “AS2 子网” 的可达信息;
- 黑色虚边(iBGP 连接):同一 AS 内部网关之间的逻辑连接(同样基于 TCP)。例如 AS2 的网关 2a、2c、2d 之间,通过 iBGP 传递 “从 eBGP 获得的 AS1/AS3 子网信息”,确保 AS2 内所有网关都知晓外部路径;
- 数据流向示例:AS1 的网关 1c 通过 eBGP 向 AS2 的 2a 通告 “AS1 的子网可达信息”,2a 再通过 iBGP 将该信息通告给 AS2 的 2c、2d,使 AS2 内所有路由器都知道 “可通过 2a 到达 AS1 子网”。
5.4.6 BGP 的工作基础:会话与通告
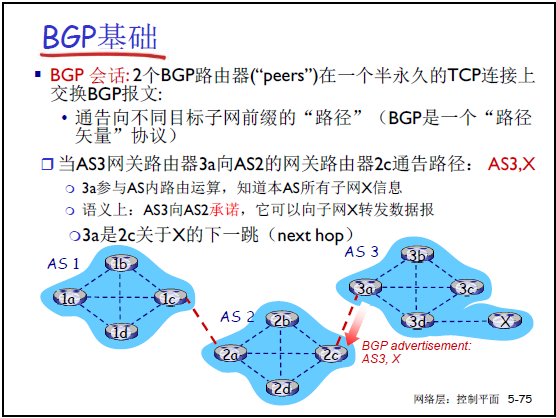
(1) BGP 会话:半永久 TCP 连接
老师明确:BGP 路由器(主要是网关)开机后,会与预设的 “BGP 邻居” 建立TCP 连接(默认端口 179),该连接为 “半永久连接”(除非链路故障或配置变更,否则持续存在),用于交换 BGP 报文。
(2) BGP 通告:子网可达信息的传递
课件 5-75 以 “AS3 的子网 X” 为例,老师讲解了通告的完整逻辑:
- 网关获取子网信息:AS3 的网关 3a 通过参与 AS3 内的 IGP(如 OSPF),知晓 AS3 内所有子网(包括 X)的可达性;
- eBGP 通告:3a 通过 eBGP 向相邻 AS2 的网关 2c 通告 “AS3.X”,语义为 “你(2c)若要发送分组到 X,可将我(3a)作为下一跳,我负责转发到 X”;
- 下一跳标识:通告中会包含 3a 的接口 IP(与 2c 连接的 IP),作为 2c 到 X 的 “下一跳地址”,确保 2c 知道将分组发给谁。
老师特别强调:BGP 通告的核心是 “承诺可达”—— 网关通过 eBGP 通告某子网,即承诺 “能转发到该子网”,是 AS 间路由的信任基础。
5.4.7 BGP 的路径属性:避免环路与辅助选择

BGP 作为 “改进的距离矢量协议”,核心改进在于 “传递路径属性”,老师详细讲解了两个关键属性:
(1)AS-PATH(AS 路径)
- 定义:通告某子网时,附带 “到达该子网需经过的 AS 序列”(如 “AS2→AS3” 表示需先到 AS2,再到 AS3);
- 核心作用:
- 检测环路:若某 AS 收到的通告中,AS-PATH 包含自身 AS 号(如 AS2 收到 “AS2→AS3→X”),则判定为环路,直接丢弃该通告,解决 DV 算法的 “无穷计数” 问题;
- 辅助路径选择:AS-PATH 长度(AS 跳数)是路径选择的重要依据之一,通常优先选择 AS 跳数少的路径。
(2)NEXT-HOP(下一跳)
- 定义:通告某子网时,明确 “当前 AS 到该子网的下一跳网关 IP”(如 AS2 的 2c 向 2a 通告 “AS3.X” 时,NEXT-HOP 为 3a 的 IP);
- 核心作用:确保 AS 内路由器知道 “将分组发给哪个网关” 才能到达外部子网,避免路径模糊。
(3)基于策略的路由过滤
老师强调:BGP 的路径属性为 “策略控制” 提供了基础,网关收到通告后,会根据预设策略(政治、经济、安全)决定是否接受:
- 政治策略示例:AMD 的 AS 不接受 “经过英特尔 AS” 的通告,避免核心数据被竞争对手拦截;
- 经济策略示例:ISP 不接受 “非客户 AS” 的通告,避免为其他 ISP 免费承载流量(增加自身带宽消耗却无收益)。
5.4.8 BGP 路径通告的完整流程
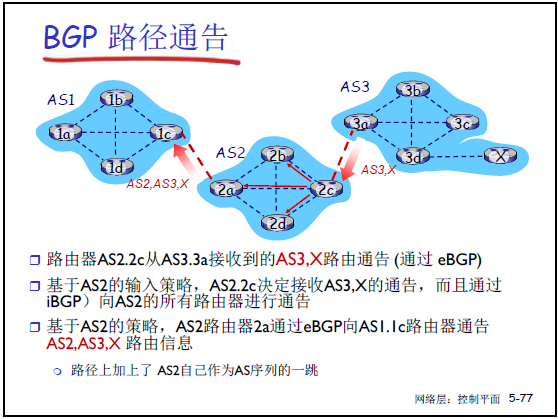
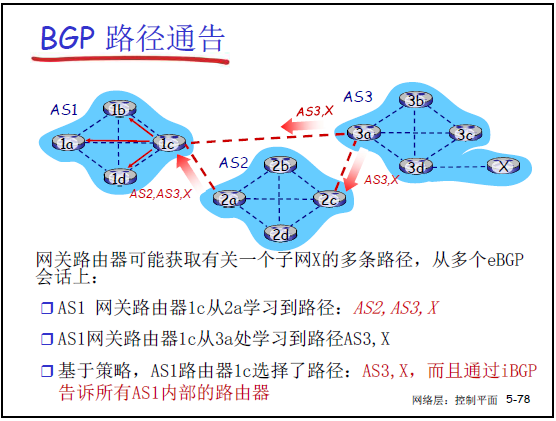
课件 5-77、5-78 以 “AS3 的子网 X” 为例,展示了通告在 AS1、AS2、AS3 之间的传递,老师分步骤讲解:
步骤 1:AS3 内部获取 X 的可达性
- AS3 的子网 X 上线后,AS3 内的 IGP(如 OSPF)将 “X 可达” 的信息扩散到所有路由器,包括网关 3a、3b、3c;
- 网关 3a 通过 IGP 知晓 X 的存在,确定 “可转发到 X”。
步骤 2:3a 通过 eBGP 向 2c 通告
- 3a 与 AS2 的网关 2c 建立 eBGP TCP 连接,通告 “AS3.X”,附带属性:AS-PATH=“AS3”,NEXT-HOP=3a 的 IP;
- 2c 根据策略(如 “接受所有相邻 AS 的通告”),接受该信息。
步骤 3:2c 通过 iBGP 向 AS2 内部通告
- 2c 通过 iBGP 将 “AS3.X” 通告给 AS2 的其他网关(2a、2d、2b),属性不变(AS-PATH 仍为 “AS3”,NEXT-HOP 仍为 3a);
- AS2 内所有网关均知晓 “可通过 2c 到达 AS3.X”。
步骤 4:2a 通过 eBGP 向 1c 通告
- AS2 的网关 2a 与 AS1 的网关 1c 建立 eBGP 连接,通告 “AS3.X”,此时需修改属性:AS-PATH=“AS2→AS3”(添加自身 AS 号),NEXT-HOP=2a 的 IP;
- 1c 接受该通告,同时可能收到 AS3 网关 3a 直接发来的 “AS3.X”(若 AS1 与 AS3 直接相连),形成两条路径。
步骤 5:1c 通过 iBGP 向 AS1 内部通告
- 1c 根据策略(如 “优先选择 AS 跳数少的路径”),选择 “AS3.X”(AS 跳数 1)而非 “AS2→AS3.X”(AS 跳数 2);
- 通过 iBGP 将 “AS3.X” 通告给 AS1 的其他网关(1a、1b、1d),确保 AS1 内所有路由器知晓 “可通过 1c 到达 X”。
5.4.9 BGP 的报文类型

老师指出,BGP 通过 4 种核心报文完成交互,所有报文均通过 TCP 连接传输:
| 报文类型 | 核心功能 |
|---|---|
| OPEN | 1. 建立 TCP 连接后,向邻居发送 “OPEN 报文”,包含自身 AS 号、BGP 版本等信息; 2. 邻居回复 OPEN 报文,完成 BGP 会话初始化 |
| UPDATE | 1. 通告新的子网可达路径(包含子网前缀、AS-PATH、NEXT-HOP 等属性); 2. 撤销已失效的路径(如某子网下线) |
| KEEPALIVE | 1. 无 UPDATE 时,每隔 30 秒发送一次,维持 TCP 连接(避免连接超时关闭); 2. 确认 OPEN 报文的接收 |
| NOTIFICATION | 1. 检测到错误(如 AS-PATH 环路、报文格式错误)时发送; 2. 发送后关闭 BGP 会话,需重新建立 |
老师补充:BGP 报文结构复杂,但本科阶段只需掌握核心功能,无需深入字段细节 —— 重点是理解 “通过报文实现路径的通告与维护”。
5.4.10 BGP 与 IGP 的协同:生成转发表
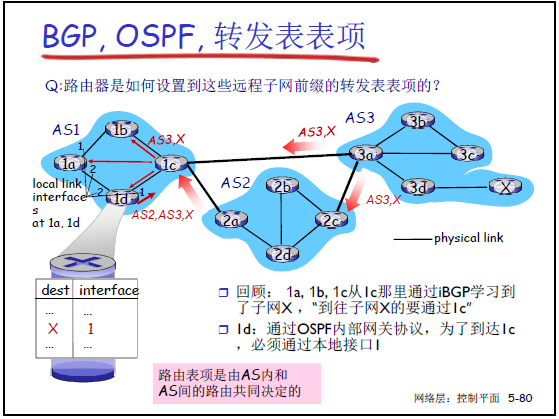
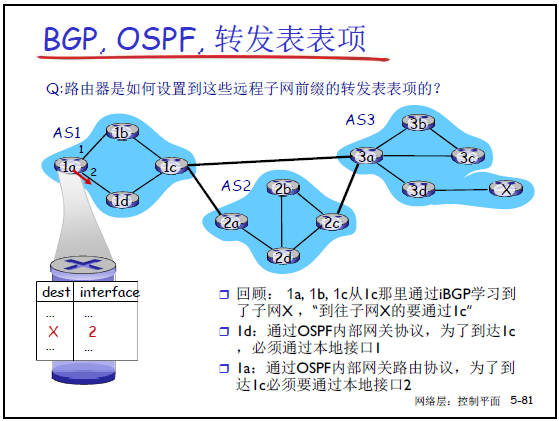
老师强调:AS 内路由器的转发表(针对外部子网)是 “BGP 与 IGP 共同作用的结果”,结合课件 5-80 的拓扑(AS1 的 1a、1d 路由器)讲解:
步骤 1:通过 iBGP 获取外部子网路径
- AS1 的普通路由器(如 1d)通过 iBGP 收到网关 1c 的通告:“到子网 X 需通过 1c(网关)”,即 “X 的下一跳是 1c”。
步骤 2:通过 IGP 获取到网关的路径
- 1d 通过 AS1 内的 IGP(如 OSPF)计算 “到 1c 的最短路径”,得知 “需通过接口 1(与 1c 直接连接的端口)发送分组”。
步骤 3:生成转发表项
- 1d 的转发表中,针对 “X” 的表项为:
目标子网X → 输出接口1 → 下一跳1c; - 同理,AS1 的路由器 1a 通过 IGP 得知 “到 1c 需通过接口 2”,转发表项为:
目标子网X → 输出接口2 → 下一跳1c。
老师总结:BGP 解决 “到外部子网该走哪个网关”,IGP 解决 “到该网关该走哪个接口”,二者协同才能完成外部子网的转发。
5.4.11 BGP 的路径选择策略

当网关收到某子网的多条路径(如 AS1 的 1c 收到 “AS3.X” 和 “AS2→AS3.X”),BGP 通过 “多维度消除规则” 选择最优路径,老师结合课件详细讲解:
(1)第一优先级:本地偏好(Local Preference)
- 定义:AS 内部预设的策略权重(如 “优先选择客户 AS 的路径”“优先选择低成本链路的路径”);
- 作用:策略优先于性能,例如某 ISP 可能为 “付费客户” 的路径设置高本地偏好,即使该路径 AS 跳数更多。
(2)第二优先级:最短 AS-PATH
- 选择 AS 跳数最少的路径,例如 “AS3.X”(1 跳)优于 “AS2→AS3.X”(2 跳),减少跨 AS 转发的不确定性。
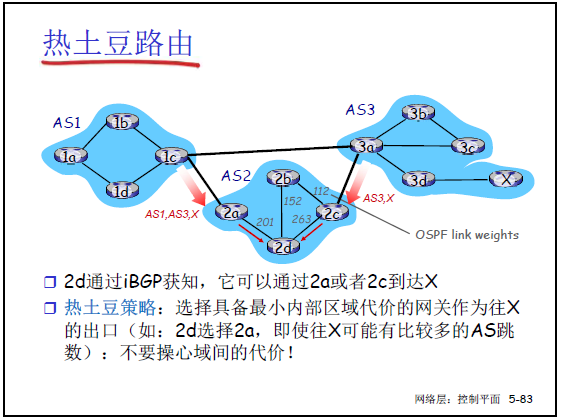
(3)第三优先级:热土豆策略(Hot Potato)
课件 5-83 展示了 AS2 的 2d 路由器选择到 X 的路径,老师用 “烫手土豆尽快甩出去” 比喻:
- 定义:选择 “AS 内到网关代价最小” 的路径,不考虑 AS 间的代价;
- 示例:AS2 的 2d 到 X 有两条路径:“2d→2a→3a”(AS 内到 2a 的代价 201)、“2d→2c→3a”(AS 内到 2c 的代价 263),2d 会选择 “2d→2a”,即使 AS 间跳数相同,因为 “尽快将分组交给网关,减少自身 AS 内的转发代价”。
(4) 后续优先级:附加判据
- 若前三项相同,依次比较 “NEXT-HOP 的 IP 地址大小”“BGP 邻居的 ID 大小”,最终保留唯一路径。
5.4.12 BGP 的策略控制场景
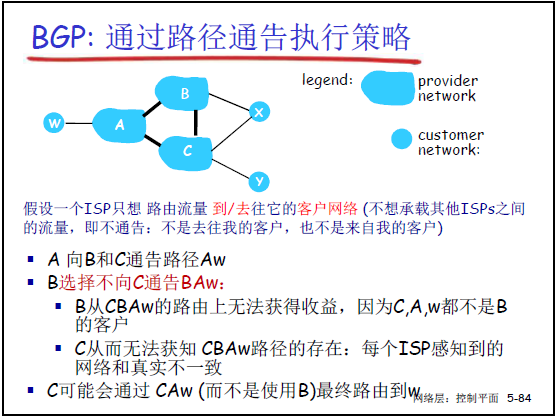
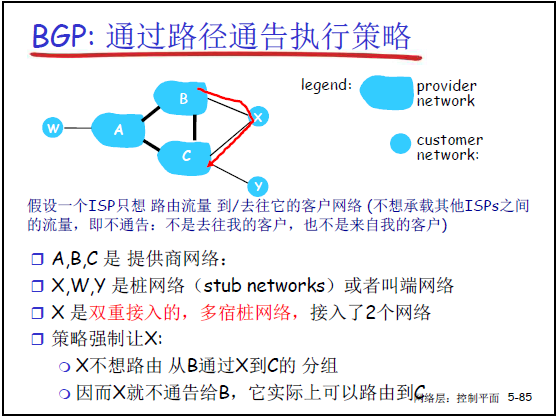
课件 5-84、5-85 用 “provider(服务商 AS)” 和 “customer(客户 AS)” 的拓扑,老师讲解了 BGP 策略的典型应用:
(1)场景 1:ISP 拒绝承载非客户流量
- 拓扑:A、B、C 为服务商 AS,W 为 A 的客户 AS;
- 策略:A 向 B、C 通告 “AW”(A 到 W 的路径),但 B 不向 C 通告 “BAW”(B 到 A 再到 W 的路径)—— 因为 C 不是 B 的客户,B 若通告,会导致 C 的流量通过 B→A→W,增加 B 的带宽消耗却无收益;
- 结果:C 只能通过 “C→A→W” 直接访问 W,无法通过 B 中转,实现 B 的 “经济策略”。
(2) 场景 2:客户 AS 避免成为 “中转节点”
- 拓扑:X 为客户 AS,同时连接 B、C 两个服务商 AS;
- 策略:X 不向 B 通告 “XC”(X 到 C 的路径),避免 B 的流量通过 X→C 中转(增加 X 的负担);
- 结果:B 的流量只能通过 B 自身的链路到 C,X 仅承载 “自身到 B/C” 的流量,符合 X 的 “安全与负载策略”。
5.4.13 内部网关协议(IGP)与 BGP 的核心差异

老师通过 “国家内与国家间” 的比喻,总结了 IGP 与 BGP 的本质差异,课件 5-86 用表格对比,核心要点如下:
| 对比维度 | 内部网关协议(IGP,如 RIP、OSPF) | 外部网关协议(BGP) |
|---|---|---|
| 核心诉求 | 性能优先(低延迟、高带宽) | 策略优先(政治、经济、安全) |
| 路由范围 | 单 AS 内部,规模可控 | 全网 AS 间,规模巨大 |
| 拓扑透明度 | 完全透明(AS 内所有路由器知晓拓扑) | 完全不透明(仅暴露 AS 级路径,隐藏内部拓扑) |
| 路径选择依据 | 链路代价(如延迟、跳数) | 本地偏好、AS-PATH、热土豆策略等 |
| 收敛速度 | 快(毫秒级,AS 内规模小) | 慢(秒级,需跨 AS 传递,策略判断耗时) |
强调:IGP 的目标是 “在同一机构内高效转发”,BGP 的目标是 “在不同机构间安全可控地转发”,二者定位不同,设计逻辑完全不同,缺一不可。
5.5 SDN 控制平面笔记
5.5.1 SDN 控制平面概述(对应课件 5-88)

传统互联网网络层的控制平面与数据平面垂直集成,控制平面通过分布式方式实现(如路由算法分散在各路由器中),带来以下问题:
- 网络设备纷繁复杂,管理难度高;
- 分布式实现控制功能的效率低、网络行为僵化;
- 封闭的垂直集成架构不利于生态竞争与创新。
2005 年起,“软件定义网络(SDN)” 模式被提出,核心是控制平面与数据平面分离、逻辑上集中控制平面,以解决传统网络的弊端。
5.5.2 传统方式 vs SDN 方式:控制平面架构对比
(1)传统方式:每个路由器(Per-router)控制平面
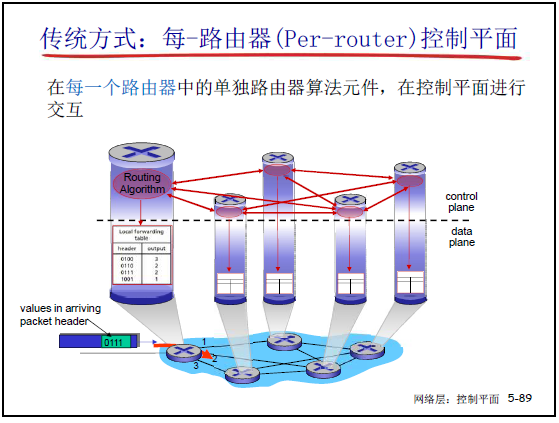
- 架构:控制平面功能(如路由算法)集成在每个路由器内部,各路由器的控制元件在本地交互。
- 问题:分布式实现效率低、网络行为固化,导致设备复杂、管理困难、生态封闭。
(2)SDN 方式:逻辑上集中的控制平面
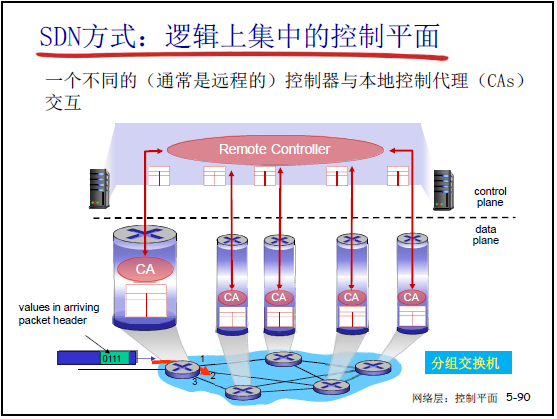
- 架构:远程控制器(逻辑集中) 通过控制代理(CA) 与分组交换机交互:
- 交换机通过 CA 向控制器上报自身状态;
- 控制器计算流表后,通过南向接口下发给交换机;
- 交换机仅执行 “流表匹配 + 动作” 的简单数据平面转发。
- 优势:控制平面集中管理,简化网络操作;交换机功能标准化,便于厂商竞争。
5.5.3 SDN 的优势:为什么需要逻辑集中的控制平面
(1)SDN 的核心优势

- 网络管理更简单:避免路由器错误配置,提升通信流的弹性;
- 网络可编程:基于流表的转发(如 OpenFlow),控制器集中计算流表并下发,比传统分布式 “编程” 更高效;
- 控制平面开放化:打破封闭架构,形成新的竞争生态(第三方可参与网络功能开发)。
(2)类比:主框架到 PC 的演变
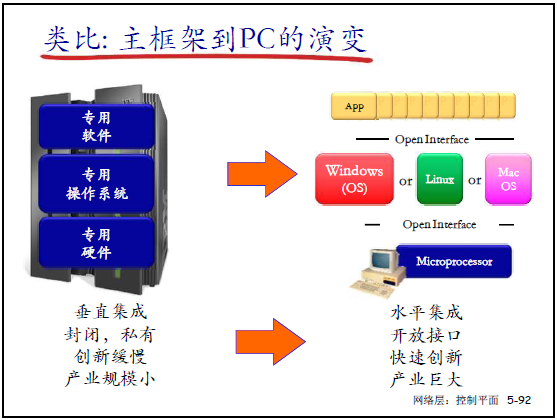
传统网络类似 “主框架” 的垂直集成(专用硬件 + 专用 OS + 专用软件):封闭、创新慢、产业规模小;
SDN 类似 “PC” 的水平集成(开放接口 + 通用 OS + 第三方应用):开放、快速创新、产业生态庞大。
5.5.4 流量工程:传统路由 vs SDN 的实现差异
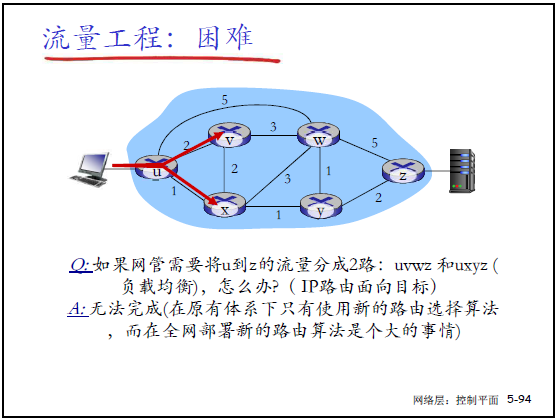
(1)传统流量工程的困难
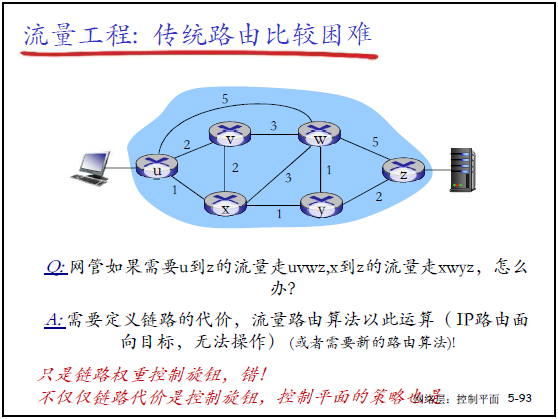
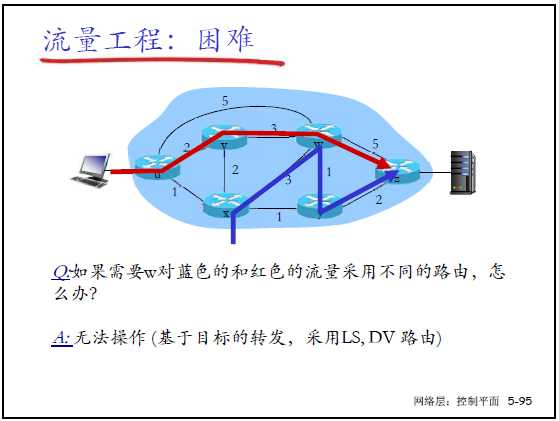
传统 IP 路由面向目标地址转发,无法灵活控制流量路径:
- 案例 1:需让 “u 到 z” 走不同路径(如 uvwxz/uxyz),仅靠调整链路代价无法实现(IP 路由不支持细粒度路径控制);
- 案例 2:需将 “u 到 z” 的流量分两路(负载均衡),传统路由无法实现(全网更新路由算法成本极高);
- 案例 3:需让不同流量(如蓝色 / 红色流)走不同路径,传统 LS/DV 路由基于目标转发,无法区分流量。
(2)SDN 下的流量工程:简单灵活
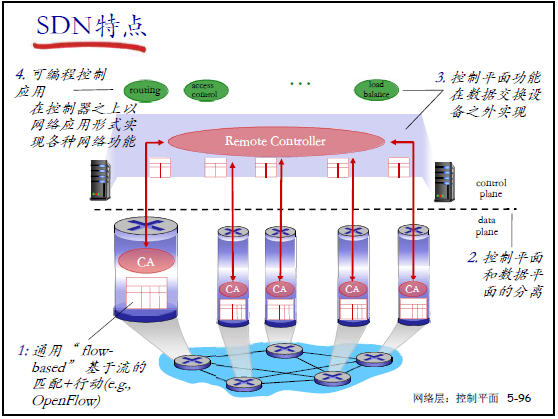
SDN 通过基于流的 “匹配 + 动作” 模式实现细粒度流量控制,核心特点:
- 通用基于流的转发:以流(而非仅目标地址)为单位匹配分组,支持多字段匹配(如源 / 目标端口、主机等);
- 控制平面与数据平面分离:控制功能由控制器实现,交换机仅执行转发;
- 控制平面功能外置:网络功能(路由、负载均衡等)在控制器 / 应用层实现;
- 可编程控制:通过控制器上的应用定义网络行为,灵活调整流量路径。
5.5.5 SDN 架构的组成
(1)数据平面交换机
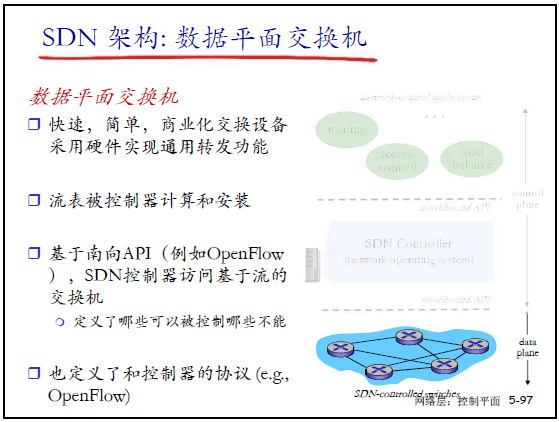
- 特性:快速、简单的商业化交换设备,硬件实现通用转发功能;
- 核心逻辑:按控制器下发的流表执行 “匹配 + 动作”;
- 交互方式:通过南向接口(如 OpenFlow) 与控制器通信:
- 定义了 “哪些功能可被控制器控制”;
- 定义了控制器与交换机的通信协议(如 OpenFlow)。
(2)SDN 控制器(网络 OS)
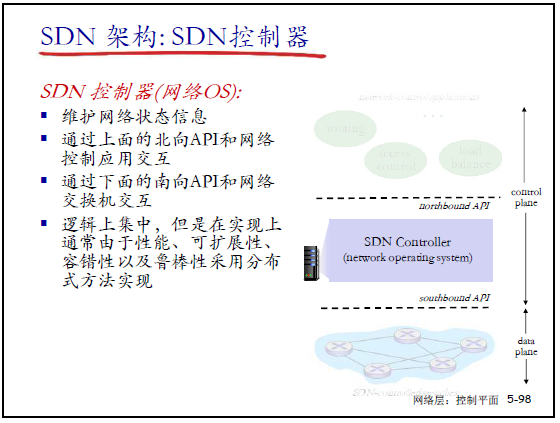
SDN 控制器也称为 “网络操作系统”,核心功能:
- 维护网络状态信息(链路、节点、统计信息等);
- 通过北向接口与网络控制应用交互;
- 通过南向接口与交换机交互(下发流表、接收状态上报);
- 部署方式:逻辑集中、物理分布式(兼顾性能、可靠性、可扩展性)。
(3)控制应用
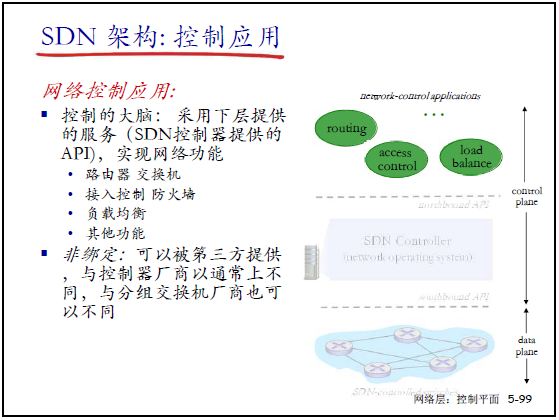
- 定位:“控制的大脑”,通过控制器提供的 API 实现网络功能;
- 功能覆盖:传统网络设备的所有功能(路由、交换、防火墙、负载均衡等),也支持未来新网络功能;
- 生态特点:非绑定(第三方可开发),与控制器 / 交换机厂商解耦,形成开放竞争生态。
(4)SDN 控制器的内部元件
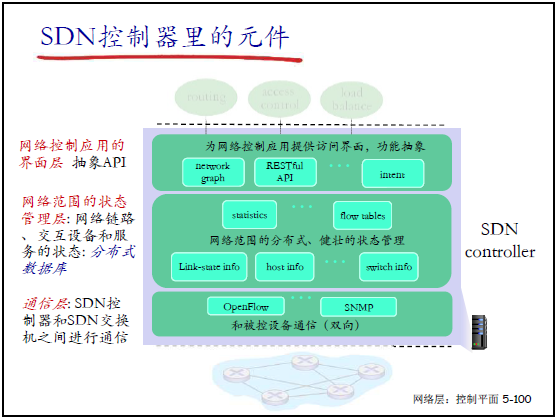
控制器内部分为三层:
- 界面层(北向接口):提供抽象 API(如 network graph、RESTful API),为控制应用提供访问接口;
- 状态管理层:维护网络范围的状态(链路、主机、交换机、流表、统计信息等),基于分布式数据库实现;
- 通信层(南向接口):与交换机通信,支持 OpenFlow、SNMP 等协议(双向交互:状态上报、流表下发)。
5.5.6 OpenFlow 协议:SDN 的南向接口
(1)OpenFlow 协议概述
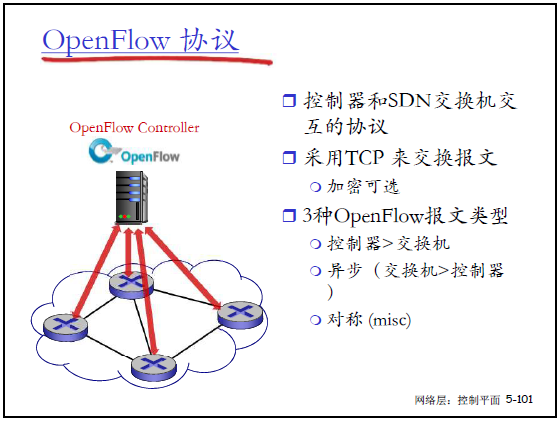
- 定位:控制器与 SDN 交换机的交互协议;
- 通信方式:基于 TCP 传输,加密可选;
- 报文类型:
- 控制器→交换机;
- 交换机→控制器(异步);
- 对称报文(misc)。
(2)控制器→交换机的报文
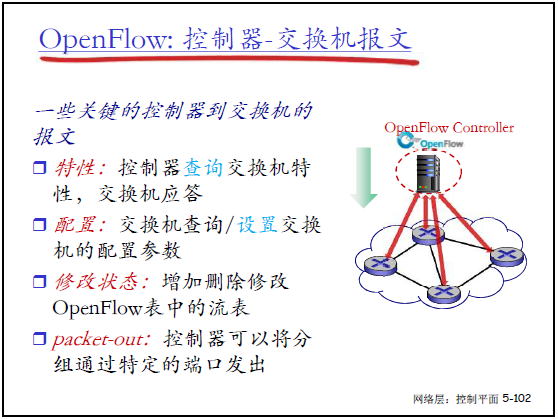
核心报文类型:
- 特性:控制器查询交换机特性,交换机应答;
- 配置:控制器查询 / 设置交换机的配置参数;
- 修改状态:控制器增 / 删 / 改交换机的流表;
- packet-out:控制器指令交换机将特定分组从指定端口发出(用于无匹配流表的分组)。
(3)交换机→控制器的报文
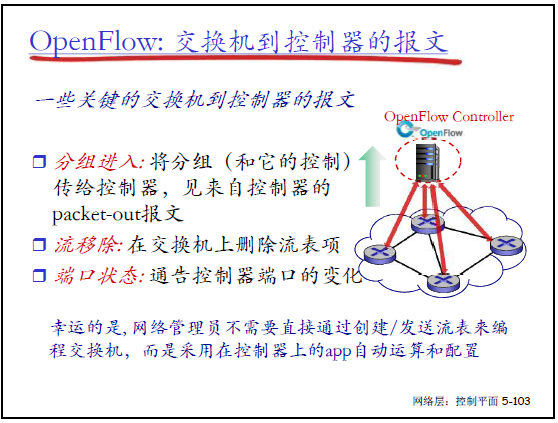
核心报文类型:
- 分组进入:交换机收到无匹配流表的分组时,将分组传给控制器,等待 packet-out 指令;
- 流移除:交换机删除流表项时通告控制器;
- 端口状态:交换机端口状态变化时(如失效)通告控制器;
- 注:流表由控制器应用自动计算下发,无需管理员手动配置。
5.5.7 SDN 控制 / 数据平面交互示例
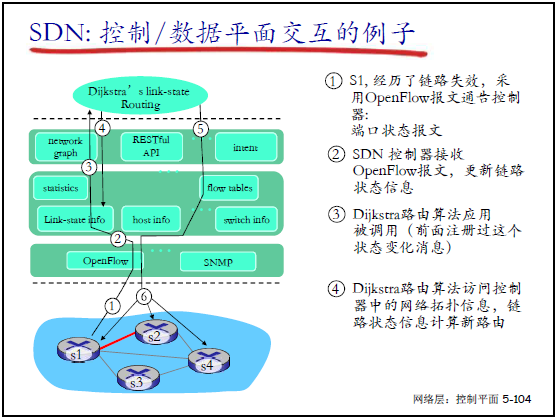
以 “S1-S2 链路失效” 为例,交互流程:
- 状态上报:S1 通过 OpenFlow 报文向控制器通告端口状态(链路失效);
- 状态更新:控制器接收报文,更新链路状态数据库;
- 事件触发:触发已注册的 “Dijkstra 路由应用”(事件驱动编程);
- 拓扑查询:Dijkstra 应用通过北向接口查询网络拓扑信息;
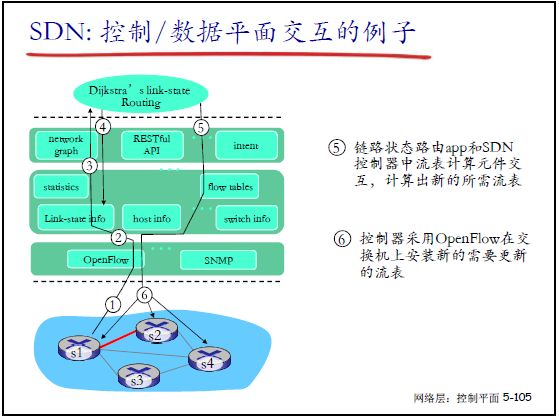
- 流表计算:应用计算新路由,生成对应的流表;
- 流表下发:控制器通过 OpenFlow 将新流表下发给相关交换机,完成路径更新。
5.5.8 主流 SDN 控制器
(1)OpenDaylight(ODL)控制器
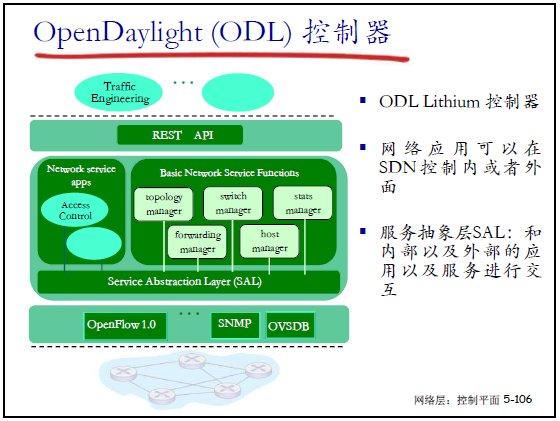
- 架构:
- 北向接口:REST API;
- 服务层:包含接入控制、拓扑管理、转发管理等网络服务组件;
- 服务抽象层(SAL):统一内部 / 外部应用与服务的交互;
- 南向接口:支持 OpenFlow 1.0、SNMP、OVSDB 等协议。
(2)ONOS 控制器
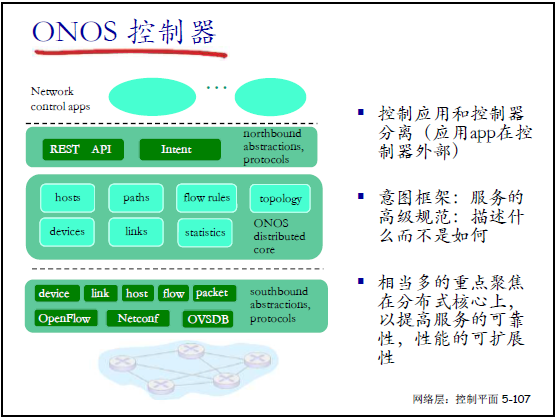
- 特点:
- 控制应用可在控制器内 / 外实现(通过北向接口交互);
- 意图框架:支持 “描述目标而非实现方式” 的高级规则;
- 分布式核心:聚焦可靠性、性能与可扩展性,适用于大规模网络。
5.5.9 SDN 面临的挑战

- 控制平面强化:需实现可信、可靠、高性能、安全的分布式控制平面(如失效鲁棒性、安全认证);
- 特殊场景适配:需满足实时性、超高可靠性、超高安全性等特殊任务需求;
- 互联网级扩展性:当前 SDN 多部署于单个 AS 内,需解决全网范围的扩展性问题。
5.6 总结
5.6.1 本章核心:网络层控制平面的功能及实现方式
本章核心围绕 “网络层控制平面的功能及相应实现” 展开,主要分为两种实现方式,具体如下:
(1)传统方式实现网络层控制功能
- 核心功能聚焦:传统方式下,重点实现网络层的控制功能,其中最关键的是路由功能
- 控制平面实现逻辑:路由功能通过 “垂直集成方式”(注:原文 “垂直竞争方式” 推测为 AI 提取误差,结合网络层控制平面传统实现逻辑修正,即控制功能与数据转发功能在同一设备中垂直集成实现)实现,属于传统控制平面的核心功能之一
(2)SDN 方式实现网络层控制功能
- 整体说明:作为传统方式的补充,本章介绍了 SDN(软件定义网络)架构下网络控制功能的实现思路,具体细节在后续内容展开
5.6.2 路由选择的算法与协议
本章详细介绍了路由选择相关的算法与协议,分类如下:
(1)路由选择算法
-
链路状态路由选择算法
- 核心依据:基于迪杰斯特拉(注:原文 “D 些斯特拉” 为 AI 提取误差,修正为标准名称)算法实现
- 算法特点:属于链路状态(注:原文 “电路状态” 为 AI 提取误差,修正为 “链路状态”)类路由选择算法,通过获取全网链路状态信息计算最优路由
-
距离矢量路由选择算法
-
核心依据:基于贝尔曼福特方程的动态规划思想实现
-
算法别称:原文提及 “DV 算法”,即距离矢量(Distance Vector)算法的简称
-
-
其他提及算法:原文提及 “IOS 算法”,推测为 AI 提取误差(结合网络层经典路由算法,可能为 “LS 算法”,即链路状态(Link State)算法的误写),暂以原文表述记录,需结合课件图进一步确认对应算法细节
(2)路由选择协议
按协议作用范围,分为 “自治系统内部” 和 “自治系统之间” 两类:
-
内部网关协议(自治系统内部的路由选择协议)
-
核心作用:用于解决单一自治系统(AS)内部的路由选择问题,确定自治系统内的最优路由路径
-
具体协议:
-
重点介绍协议:RIP(路由信息协议)、OSPF(开放式最短路径优先协议)
-
额外提及协议:思科设备专用的 RGRP 协议(仅提及名称,未展开细节)
-
-
-
自治系统间的路由选择协议 ——BGP 协议
-
协议全称:边界网关协议(Border Gateway Protocol)
-
核心地位:互联网中自治系统之间事实上的标准路由协议
-
主要功能:决定不同自治系统之间的路由走向,实现跨自治系统的路由选择
-
讲解程度:“浅尝辄止”
-
原因:BGP 协议本身复杂度较高,难以在本章总结阶段深入展开
-
讲解内容:仅介绍 BGP 协议的大致工作原理及核心作用,未涉及复杂的协议细节(如报文格式、邻居建立流程等)
-
-
5.6.3 SDN 方式下控制平面的具体实现
(1)控制平面的部署位置
SDN 架构下,网络层的控制平面不再分散在各个网络设备中,而是集中在SDN 控制器上实现,由控制器统一管理和控制全网的路由及转发策略
(2)网络功能的实现方式
- 依托接口:基于 SDN 控制器的北向接口(注:原文 “北向结构” 为表述误差,修正为 “北向接口”,即控制器向上层应用提供的接口)
- 实现形式:以 “网络应用” 的方式在北向接口之上开发和部署,通过这些网络应用实现各种各样的网络功能(如路由计算、流量调度、访问控制等)
5.6.4 本章内容范围总结
本章围绕 “网络层控制平面” 展开,涵盖传统方式(以路由功能为核心,含路由算法与协议)和 SDN 方式(集中式控制器 + 北向接口网络应用)的控制平面实现,未展开 ICMP 协议及 SSMP 网络管理内容,至此本章所有计划讲解的内容介绍完毕
参考资料来源:中科大郑烇、杨坚全套《计算机网络(自顶向下方法 第7版,James F.Kurose,Keith W.Ross)》课程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号