第4章网络层:数据平面
第4章网络层:数据平面

4.1 导论
4.1.1 章节定位:从网络 “边缘” 到 “核心”
(1)网络分层学习的过渡
- 前序章节(1-3 章):聚焦网络 “边缘”,覆盖应用层(HTTP、DNS)、传输层(TCP、UDP),核心是端系统间的进程通信(如浏览器与 Web 服务器的交互);
- 本章(第 4 章)+ 第 5 章:进入网络 “核心”,聚焦网络层,核心是主机到主机的分组交付(如主机 A 经多台路由器到主机 B);
- 教材版本差异:本版教材将网络层拆分为数据平面(第 4 章) 与控制平面(第 5 章),前版教材未拆分(将两者合并讲解),这是本版的最大区别。
(2)导论的角色
导论作为第 4 章的开篇,核心是 “建立网络层数据平面的基础认知”,为后续 4.2(路由器组成)、4.3(IP 协议)、4.4(SDN)的学习铺垫框架性理解。
4.1.2 导论的核心学习目标

导论需达成的 4 个核心目标,也是本章数据平面的学习基础:
- 理解网络层数据平面的基本原理,明确 “数据平面” 与 “控制平面” 的定义及区别;
- 掌握网络层向上层(传输层)提供的核心服务(主机到主机的分组交付);
- 区分网络层的两大功能 —— 转发(数据平面)与路由(控制平面),理解两者的配合关系;
- 初步认识网络层服务模型(如 “尽力而为”),了解不同网络架构的服务差异(如 IP vs ATM)。
4.1.3 核心概念:数据平面与控制平面
数据平面与控制平面是网络层的两大核心组成,课件 4-7 通过 “本地执行” 与 “全局决策” 的逻辑明确两者差异,结合老师的讲解补充如下:
| 维度 | 数据平面(Data Plane) | 控制平面(Control Plane) |
|---|---|---|
| 课件对应 | 课件 4-7 “数据平面” 模块 | 课件 4-7 “控制平面” 模块 |
| 功能定位 | 本地执行功能:单台网络设备(如路由器)对到来的分组做 “入 - 出” 转发,核心是 “怎么转” | 全局决策功能:规划 “源主机到目标主机” 的端到端路径,核心是 “转哪条” |
| 作用范围 | 仅单台网络设备(如 1 台路由器) | 整个网络(跨多台路由器、端系统) |
| 核心依赖 / 输出 | 依赖 “路由表(传统)/ 流表(SDN)”,输出 “转发动作”(如从端口 2 转发) | 输出 “路由表 / 流表”,为数据平面提供转发决策依据 |
| 老师举例 | 路由器插 3 块网卡(以太网、ATM、帧中继):接收以太网帧→解封装到网络层→查目标 IP→从帧中继端口转发 | 春游去植物园选路线:规划 “五里墩 / 黄山路 / 南二环” 的全局路径,而非单个路口的转弯 |
| 实现方式 | 传统:IP 协议按目标 IP 查路由表;SDN:按多字段查流表 | 传统:路由器分布式交互路由信息(如 OSPF);SDN:远程控制器集中计算路径 |
4.1.4 网络层两大核心功能:转发(数据平面)与路由(控制平面)

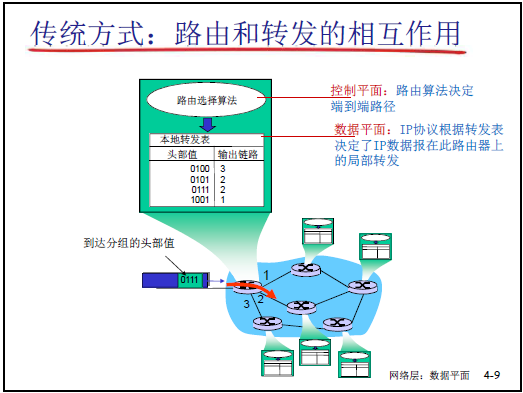
(1)转发(Forwarding):数据平面的核心动作
- 定义:单台网络设备(如路由器)从 “入端口” 接收分组,通过查 “转发表 / 流表”,选择 “出端口” 将分组转发出去的局部功能,不关心端到端路径;
- 老师补充例子(修正后):路由器插 3 块网卡(以太网、ATM、帧中继),接收以太网帧后:
- 数据链路层解封装,提取 IP 分组;
- 网络层提取目标 IP 地址,查本地路由表;
- 确定从帧中继网卡转发,将 IP 分组封装为帧中继帧;
- 从帧中继端口发送到下一跳;
- 传统转发 vs SDN 转发:
- 传统转发:仅依赖 IP 分组的目标 IP 地址,查 “转发表”,动作只有 “转发”;
- SDN 转发:依赖多字段(源 MAC、目标 IP、源端口等),查 “流表”,动作可包括转发、Block、修改字段等。
(2)路由(Routing):控制平面的核心动作
- 定义:规划 “源主机到目标主机” 的全局路径(如 “主机 A→路由器 1→路由器 3→主机 B”),通过路由算法生成 “路由表 / 流表” 的功能;
- 老师类比:路由相当于 “春游前规划去植物园的整体路线”,转发相当于 “到五里墩路口后选择左转 / 右转的局部动作”;
- 传统路由实现:
- 每台路由器运行路由协议(如 RIP、OSPF),与其他路由器分布式交互路由信息(如 “我到主机 A 的距离是 2 跳”);
- 通过路由算法(如最短路径算法)计算最优路径;
- 生成 “本地转发表”,下发到数据平面用于转发。
(3) 转发与路由的四种组合

转发与路由各有 “传统方式” 和 “SDN 方式”,共 4 种组合(导论仅分类,不深入细节):
- 传统转发 + 传统路由(互联网主流):IP 协议查路由表转发,路由表由分布式协议生成;
- 传统转发 + SDN 路由:SDN 控制器生成路由表,设备按传统方式(目标 IP)转发;
- SDN 转发 + 传统路由:设备按多字段查流表转发,流表由传统路由协议生成;
- SDN 转发 + SDN 路由(新型核心):控制器集中生成流表,设备多字段匹配 + 多动作转发。
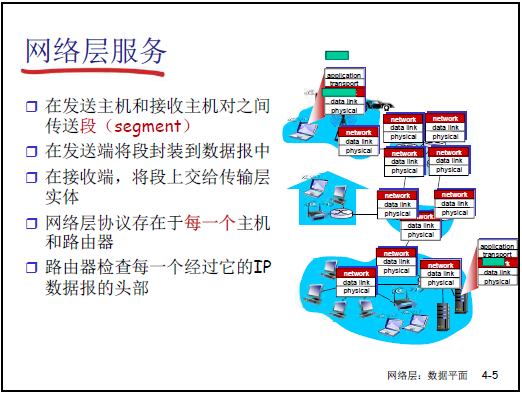
4.1.5 网络层向上层提供的核心服务:主机到主机的分组交付
网络层的核心服务是 “主机到主机的分组交付”,流程如下:
(1)服务流程
- 发送端封装:传输层(TCP 段 / UDP 数据报)→ 交给网络层→ IP 协议封装为IP 数据报(添加源 IP、目标 IP、TTL 等头部);
- 网络核心转发:每台路由器接收帧→ 解封装到网络层→ 查路由表 / 流表→ 重新封装为下一跳物理网络的帧(如 ATM 帧→以太网帧);
- 接收端解封装:目标主机解封装 IP 数据报→ 提取 TCP 段 / UDP 数据报→ 交给传输层,最终交付应用层。
(2)服务的两个关键特性
- 服务范围:主机到主机(Host-to-Host),区别于传输层的 “进程到进程”(如 TCP 的进程通信);
- 协议实体分布:每台主机、每台路由器中均包含网络层协议实体(如 IP 模块)—— 主机的 IP 模块负责封装 / 解封装,路由器的 IP 模块负责转发;
- 逐跳解封装:IP 数据报在传输过程中,每经过一台路由器都要 “解封装(帧→IP)→转发→重新封装(IP→新帧)”,仅目标主机完成最终解封装(IP→TCP/UDP)。
4.1.6 网络层服务模型:基于指标的标准化服务
(1) 服务模型的定义

服务模型是 “网络层向上层提供服务的标准化描述”—— 当 “可靠性、延迟、保序性、带宽” 等服务指标取特定值时,形成的固定服务类型(如 “尽力而为”“恒定带宽”)。
课件 4-11 明确服务指标分为两类:
- 针对单个数据报:可靠性(是否不丢失 / 不出错)、延迟保障(是否≤40ms);
- 针对系列数据报(如视频流):保序性(接收顺序与发送顺序一致)、带宽保障(是否固定 10Mbps)、延迟差(系列分组的延迟差值,延迟差 = 0 适配多媒体)。
(2) 典型服务模型对比
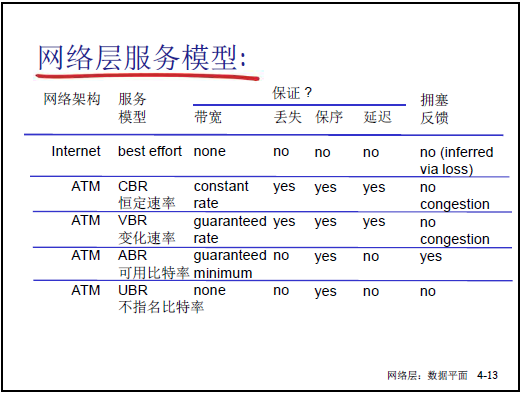
通过表格对比 IP、ATM 的服务模型,结合老师的讲解补充如下:
| 网络架构 | 服务模型 | 带宽保障 | 丢失保障 | 保序保障 | 延迟保障 | 拥塞反馈 |
|---|---|---|---|---|---|---|
| Internet | 尽力而为(Best Effort) | 无 | 无 | 无 | 无 | 无(通过丢失推断) |
| ATM | CBR(恒定比特率) | 恒定速率(如 64kbps) | 有 | 有 | 有 | 无 |
| ATM | VBR(可变比特率) | 保障最小速率 | 有 | 有 | 有 | 无 |
| ATM | ABR(可用比特率) | 保障最小速率 | 无 | 有 | 无 | 有 |
| ATM | UBR(未指定比特率) | 无 | 无 | 有 | 无 | 无 |
① IP 的 “尽力而为” 模型(重点)
- 核心特点:所有指标均无保障,是 “委婉的称呼”(老师类比:“老板交办任务说‘尽力而为’,实际不承诺结果”);
- 实际表现:无带宽 / 丢包 / 保序 / 延迟保障,不向主机反馈拥塞状态,是互联网的基础服务模型。
② ATM 的有保障模型(对比案例)
ATM 是 “有连接” 的网络层技术,明确其 4 类模型均比 IP 的 “尽力而为” 更具保障,如 CBR 适合语音传输(恒定带宽),ABR 适合弹性业务(动态调整带宽)。
4.1.7 关键区分:网络层 “有连接” 与传输层 “面向连接”

强调两者的核心差异在于 “是否涉及中间路由器”,补充如下:
| 连接类型 | 网络层 “有连接”(如 ATM) | 传输层 “面向连接”(如 TCP) |
|---|---|---|
| 课件对应 | 课件 4-12 “网络层连接” 模块 | 课件 4-12 “传输层连接” 模块 |
| 涉及设备 | 源主机、目标主机 + 中间所有路由器 | 仅源主机、目标主机(中间路由器无连接状态) |
| 状态维护 | 所有设备维护 “连接状态”(如 ATM 的虚电路表) | 仅端系统维护 “连接状态”(如 TCP 的 TCB) |
| 老师举例 | ATM 网络:通信前建立虚电路,路径上所有路由器维护虚电路表 | TCP 三次握手:仅主机 A 和主机 B 维护连接状态,路由器仅转发 IP 分组 |
| 核心差异 | 连接覆盖 “端到端 + 中间节点”,是 “主机到主机” 的连接 | 连接仅覆盖 “端到端”,是 “进程到进程” 的连接 |
导论核心总结
导论作为第 4 章的开篇,核心是建立 “数据平面” 的基础框架,关键结论如下:
- 网络层分为数据平面(本地转发)和控制平面(全局路由),本版教材拆分讲解是核心差异;
- 转发是数据平面的核心,依赖路由表 / 流表;路由是控制平面的核心,生成转发决策依据;
- 网络层服务是 “主机到主机的分组交付”,IP 的 “尽力而为” 是互联网的基础服务模型;
- 网络层 “有连接” 与传输层 “面向连接” 的本质区别是 “是否涉及中间路由器”。
4.2 路由器组成
4.2.1路由器结构概况
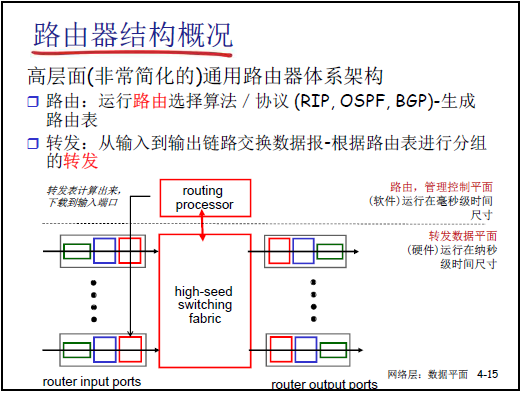
(1)核心架构与功能分工
- 高层面通用架构:路由器核心分为控制平面与数据平面,二者通过 “路由表” 衔接,配合输入端口、输出端口与高速交换机构(high-speed switching fabric)完成分组转发。
- 控制平面(软件实现,毫秒级响应):由路由处理器(processor routing)运行路由选择算法 / 协议(如 RIP、OSPF、BGP),计算并生成路由表,最终将路由表下载到所有输入端口的网络层模块。
- 数据平面(硬件实现,纳秒级响应):基于输入端口接收的路由表,将输入端口的分组通过交换机构转发到合适的输出端口,完成 “局部转发”(单个路由器内的分组交换)。
- 补充细节:
- 实际路由器的 “输入端口” 与 “输出端口” 是整合的(同一物理端口可双向传输),在此中分开讲解是为了简化原理;
- 多个路由器的 “局部转发” 通过链路串联,最终实现源主机到目标主机的端到端分组交付。
4.2.2输入端口功能
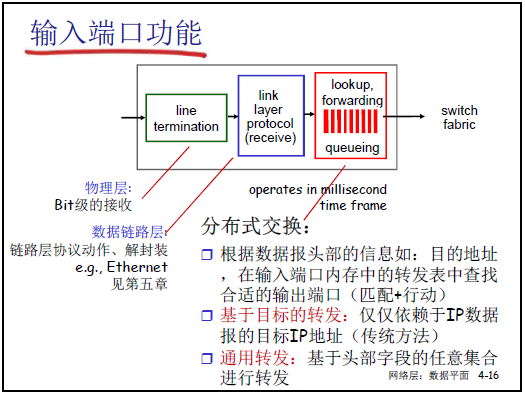
(1)分层功能实现(从物理层到网络层)
输入端口是分组进入路由器的 “第一站”,需完成物理层接收、链路层解封装、网络层转发决策,具体流程如下:
| 分层 | 功能描述(课件核心内容) | 补充细节 |
|---|---|---|
| 物理层 | 完成 “比特级接收”(line termination),将链路上的物理信号(电磁波 / 光信号)转换为数字信号(0/1)。 | 转换粒度可为 “比特” 或 “字(word)”,取决于物理编码方式。 |
| 数据链路层 | 执行链路层协议动作(如以太网解封装),校验帧完整性(如 CRC),判断帧的目标 MAC 地址是否匹配本端口,提取帧中封装的 IP 分组。 | 若目标 MAC 不匹配,直接丢弃帧;仅提取匹配帧的数据部分(即 IP 分组)交给网络层。 |
| 网络层 | 基于分组头部信息(如目标 IP 地址),在输入端口内存的转发表中执行 “匹配 + 行动”,确定转发到的输出端口。 | 传统转发仅依赖 “目标 IP 地址”,SDN 通用转发可基于头部多字段(如源 MAC、TCP 端口);分组需先在队列(queueing)中排队,等待转发决策。 |
4.2.3基于目标的转发与最长前缀匹配(对应课件图 4-17、4-19、4-20)
(1)基于目标的转发(传统方式)
-
转发表结构(课件图 4-17):转发表通过 “目标地址范围” 关联 “输出接口”,示例如下:

-
问题:若地址范围划分不规整,可能导致匹配歧义(如分组地址同时落在多个范围)。
(2)最长前缀匹配(解决歧义的核心机制)
-
定义:查找转发表时,选择与分组目标地址 “前缀重叠最长” 的表项,确保匹配唯一。转发表示例优化如下:

-
硬件支持:采用 TCAMs(三态内容可寻址存储器)实现,可在 1 个时钟周期内完成检索,不受表项数量影响(如 Cisco Catalyst 系列路由器可存储约 1 百万条路由表项)。
-
举例验证:
- 分组目标地址(DA)1:11001000 00010111 00010110 10100001 → 匹配前缀 “00010****”,转发到接口 0;
- 分组目标地址(DA)2:11001000 00010111 00011000 10101010 → 匹配前缀 “00011000 ****”,转发到接口 1。

(3)输入端口缓存与头端阻塞
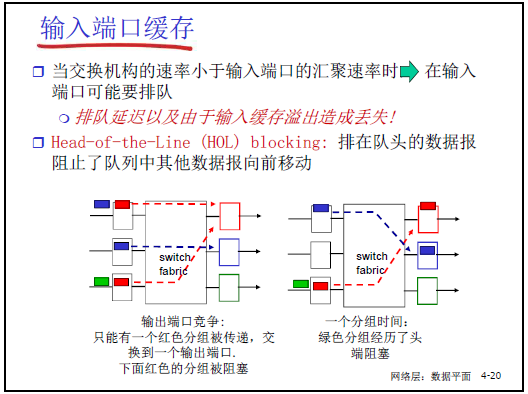
- 缓存必要性:当交换机构的速率<输入端口的汇聚速率时,输入端口需通过缓存(队列)暂存分组,避免因 “瞬时速率不匹配” 导致分组丢失(如 “双十一” 期间大量分组向 “天猫方向” 转发,输入速率骤增)。
- 头端阻塞(Head-of-the-Line, HOL):
- 定义:若队列头部的分组因目标输出端口繁忙无法转发,会阻塞队列中后续所有分组(即使后续分组的目标输出端口空闲)。
- 示例:课件图中 “绿色分组” 目标端口空闲,但因 “红色分组”(队头)阻塞,无法提前转发;若缓存溢出,后续分组会被丢弃(这是分组丢失的常见原因之一)。
4.2.4交换机构(对应课件图 4-21、4-22、4-23、4-24)
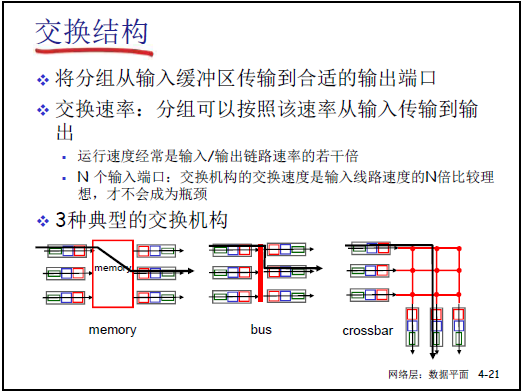
交换机构是连接输入端口与输出端口的 “桥梁”,核心功能是将输入端口缓存的分组传输到目标输出端口,需满足 “交换速率≥N 倍输入 / 输出链路速率”(N 为输入端口数量),避免成为性能瓶颈。课件中定义了 3 种典型交换机构:
(1)基于内存的交换
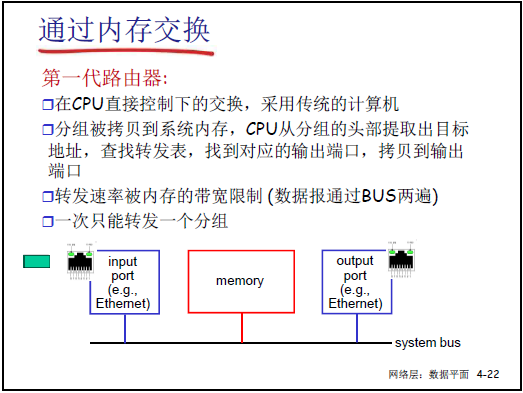
- 架构:采用传统通用计算机实现,分组需通过系统总线(system bus)在 “输入端口→内存→CPU→内存→输出端口” 之间传输。
- 工作流程:
- 输入端口将分组拷贝到系统内存;
- CPU 从分组头部提取目标地址,查询路由表确定输出端口;
- CPU 将分组从内存拷贝到输出端口。
- 特点与局限:
- 是 “第一代路由器” 的实现方式(如思科早期产品),依赖软件转发;
- 瓶颈:分组需过系统总线 2 次,转发速率受内存带宽限制,一次仅能转发 1 个分组。
- 补充:互联网第一台路由器由麻省理工团队用通用计算机软件实现,后续衍生出思科公司;但该方式因速率低,仅适用于早期小规模网络。
(2)基于总线的交换

- 架构:输入端口与输出端口共享一条高速总线(bus),分组通过总线直接从输入端口传输到输出端口(无需经过 CPU / 内存)。
- 工作流程:
- 输入端口在分组头部添加 “目标输出端口地址”;
- 分组通过总线广播,所有输出端口监听总线;
- 仅目标输出端口接收分组,其他端口丢弃分组。
- 特点与应用:
- 优势:分组仅过总线 1 次,转发速率远高于 “基于内存的交换”;
- 速率示例:Cisco 1900(1Gbps 总线)、Cisco 5600(32Gbps 总线);
- 局限:总线存在竞争,速率受总线带宽限制;适用于接入网、企业网路由器,不适用于骨干网。
(3)基于互联网络(Crossbar / 榕树网)的交换
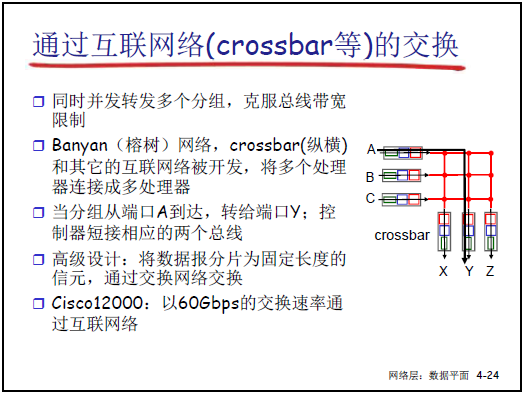
- 架构:采用 Crossbar(纵横交叉开关)或 Banyan(榕树网)结构,可同时并发转发多个分组(每个交叉节点可独立控制通断)。
- 工作流程:
- 分组从输入端口到达后,控制器控制对应交叉节点 “短接”(如端口 A→Y、端口 B→Z 可同时通断);
- 高级设计:将变长分组分割为固定长度的 “信元”,确保通过交换网络的时间一致,简化调度。
- 特点与应用:
- 优势:无总线竞争,支持并发转发,交换速率极高;
- 速率示例:Cisco 12000 系列(60Gbps 及以上交换速率);
- 适用场景:互联网骨干路由器,可应对大规模高带宽分组转发需求。
4.2.5输出端口(对应课件图 4-25、4-26、4-27)
(1)输出端口功能
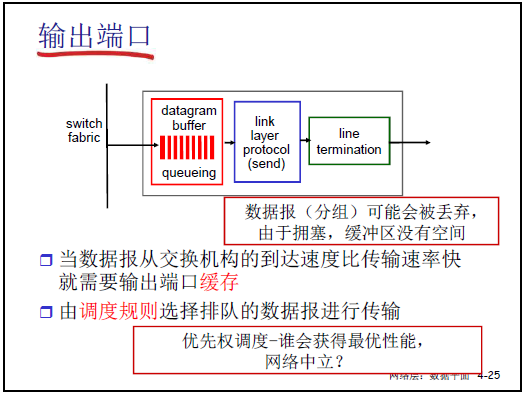
输出端口是分组离开路由器的 “最后一站”,需完成 “分组缓存→链路层封装→物理层发送”,具体流程如下:
| 分层 | 功能描述(课件核心内容) | 老师补充细节 |
|---|---|---|
| 网络层 | 接收交换机构转发的分组,在数据报缓存(datagram buffer)中排队,由调度规则选择分组发送顺序。 | 排队原因:多个输入端口同时向同一输出端口转发,导致 “输入速率>输出速率”(如多用户同时访问天猫,输出端口带宽不足)。 |
| 链路层 | 执行链路层协议(发送端),将 IP 分组封装为帧(添加帧头 / 帧尾、源 MAC 地址、目标 MAC 地址、CRC 校验码)。 | 封装需符合链路类型(如以太网),下一章会详细讲解链路层协议(如接入控制、CRC 计算)。 |
| 物理层 | 将帧的数字信号转换为物理信号(电磁波 / 光信号),通过链路发送到下一个路由器 / 主机。 | 转换粒度可为 “比特” 或 “字”,需与链路的物理编码方式匹配。 |
(2)输出端口排队
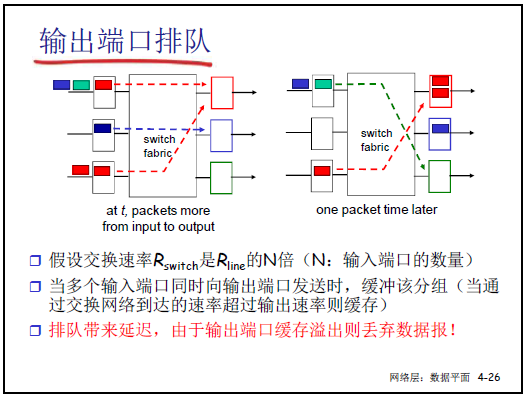
- 排队原因:即使交换速率是链路速率的 N 倍(N 为输入端口数),当多个输入端口向同一输出端口并发转发时,分组到达速率仍可能超过输出端口的传输速率,需通过缓存排队。
- 后果:排队会产生 “排队延迟”;若缓存溢出,后续到达的分组会被丢弃(这是分组丢失的另一常见原因,如 “订单发送后天猫未收到” 可能是分组在此处丢失)。
(3)缓存大小计算

-
RFC 3439 拇指规则(经验公式):平均缓存大小 = 典型 RTT(往返时间,如 250ms)× 链路容量 C。
示例:10Gbps 链路的缓存大小 = 250ms × 10Gbps = 2.5Gbit。
-
优化公式(多流场景):当网络存在 N(极大)个流时,缓存大小 = (RTT×C)/√N,避免缓存过大导致分组超时(如缓存 80T 会使分组排队到 “订单超时”,用户重复发送)。
4.2.6调度机制
调度机制的核心是 “选择队列中下一个要传输的分组”,需兼顾 “公平性” 与 “服务质量(QoS)”,课件中定义了 4 类典型调度策略:
(1)FIFO(先入先出)调度

- 规则:严格按照分组到达顺序发送(“先来先传”),是最基础的调度方式。
- 丢弃策略:当缓存满时,选择以下方式丢弃分组:
- Tail Drop(尾丢弃):丢弃刚到达的分组(“谁后到谁丢”);
- Priority(按优先级丢弃):丢弃优先级低的分组(如保留 VIP 用户分组,丢弃普通用户分组);
- Random(随机丢弃):随机选择一个分组丢弃(“拼人品”,避免单一分组持续被丢弃)。
- 举例:日常 “排队打饭” 本质是 FIFO,但缓存满时若按 “尾丢弃”,晚到的订单分组会丢失。
(2)优先权调度
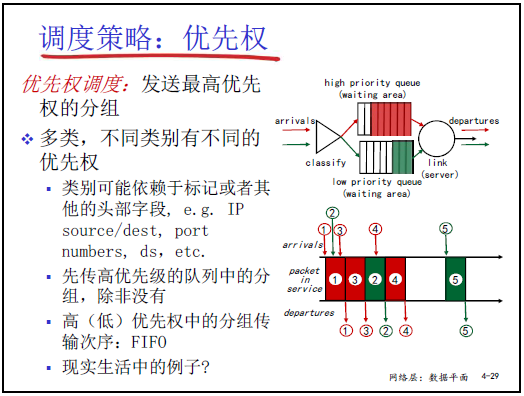
- 规则:
- 将分组按 “优先级” 分为多类(如实时多媒体分组为高优先级,Telnet 分组为低优先级);
- 优先发送高优先级队列的分组(“有高优先级就不传低优先级”),同一优先级队列内按 FIFO 顺序发送。
- 优先级划分依据:可基于分组头部字段(如 IP 地址、TCP 端口号、DS 标志位),具体标记方式属于 “高级计算机网络” 内容(研究生阶段讲解)。
- 举例:网络中 “视频通话分组”(高优先级)优先于 “文字聊天分组”(低优先级),确保视频流畅。
(3) Round Robin(RR,轮转调度)
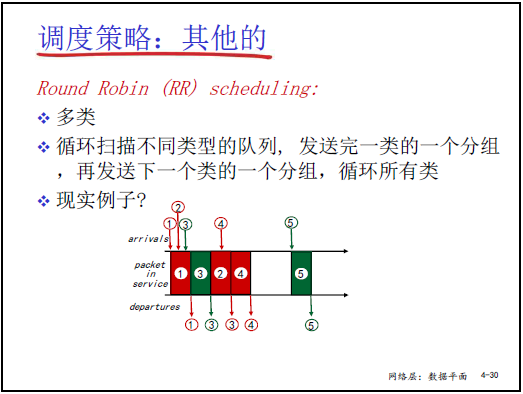
- 规则:
- 将分组分为多类(如红、绿、蓝三类);
- 循环扫描各类队列,每类队列每次发送 1 个分组(“红→绿→蓝→红→绿→蓝”)。
- 特点:保证各类分组 “公平轮转”,避免单一类别长期占用链路。
- 类比:类似针式打印机的 “色带轮转”(打完一个位置后移到下一个,避免色带局部磨损),确保每类分组都有发送机会。
(4)Weighted Fair Queuing(WFQ,加权公平队列)
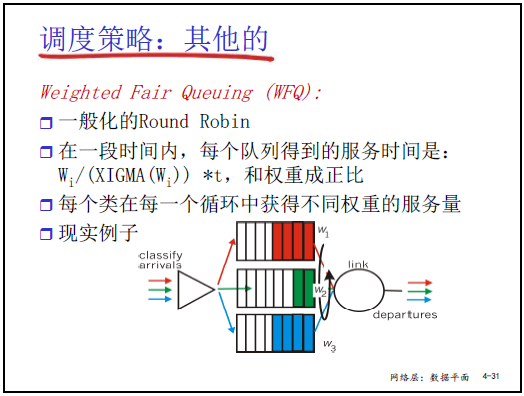
- 规则:
- 为每类分组分配 “权重 W_i”(如红类 20%、绿类 50%、蓝类 30%,总和为 100%);
- 在时间 t 内,第 i 类队列获得的服务时间 = (W_i / ΣW_i) × t,即按权重分配链路带宽。
- 举例:若链路带宽为 1Mbps,红类(20% 权重)获 200kbps、绿类(50%)获 500kbps、蓝类(30%)获 300kbps,既保证公平又支持差异化服务(如绿类对应核心业务,分配更多带宽)。
4.3 IP: Internet Protocol 总结
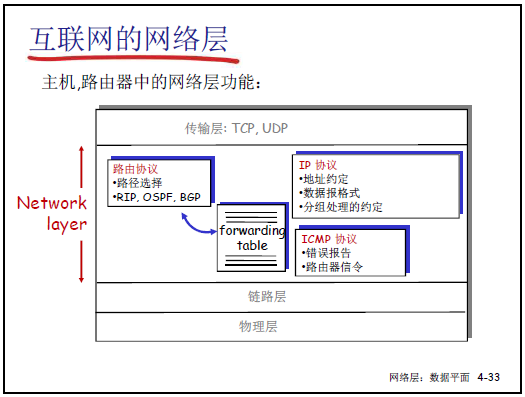
4.3.1 IP 数据报格式
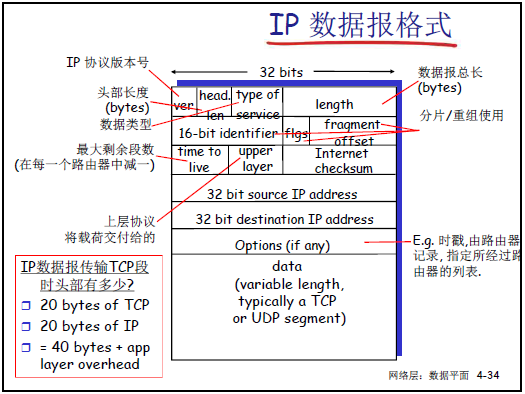
-
头部结构(32 位为单位):
-
包含 IP 协议版本号(如 IPv4 为 4)、头部长度(单位为 4 字节块)、数据报总长度(头部 + 数据,最大 65535 字节)、服务类型(Type of Service,用于 QoS 相关标识)。
-
分片 / 重组字段:16 位标识(同一数据报分片标识相同)、3 位标志(最低位表是否还有分片,0 为最后一片)、13 位偏移量(分片在原数据报中的位置,以 8 字节为单位)。
-
其他核心字段:生存时间(TTL,每经过路由器减 1,为 0 则丢弃)、16 位头部校验和(验证头部完整性)、32 位源 IP 地址、32 位目的 IP 地址、上层协议字段(指示数据部分交付给 TCP/UDP 等上层协议)。
-
可选字段(Options):如时间戳、指定必经路由器列表,长度可变(0-40 字节)。
-
-
数据部分:通常为 TCP 或 UDP 段,整体构成 IP 数据报载荷。
4.3.2 IP 分片和重组
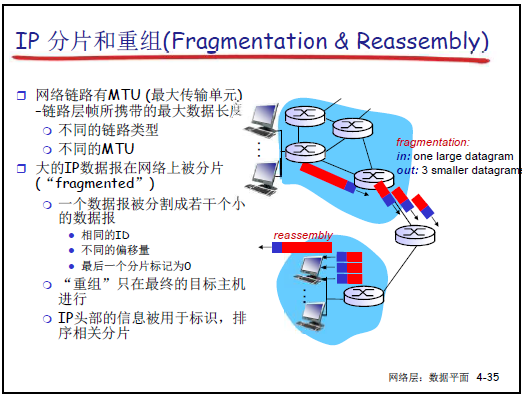
(1)核心背景
-
MTU(最大传输单元):链路层帧可携带的最大数据长度,不同链路类型 MTU 不同(如以太网 MTU 通常 1500 字节)。
-
当 IP 数据报长度超过链路 MTU 时,需在路由器进行分片,重组仅在最终目标主机完成(路由器不重组分片)。
(2)分片示例

-
原数据报:4000 字节(20 字节头部 + 3980 字节数据),MTU=1500 字节。
-
第一片:20 字节头部 + 1480 字节数据,总长度 1500 字节,标识 = x,标志 = 1(有后续分片),偏移量 = 0。
-
第二片:20 字节头部 + 1480 字节数据,总长度 1500 字节,标识 = x,标志 = 1,偏移量 = 1480/8=185。
-
第三片:20 字节头部 + 1020 字节数据(3980-1480-1480=1020),总长度 1040 字节,标识 = x,标志 = 0(最后一片),偏移量 = 2960/8=370。
-
4.3.3 IPv4 地址
(1)IP 编址导论
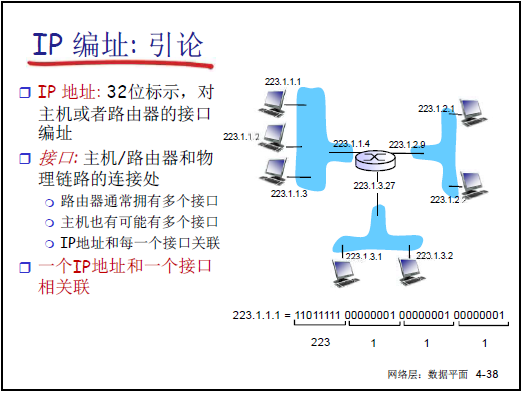
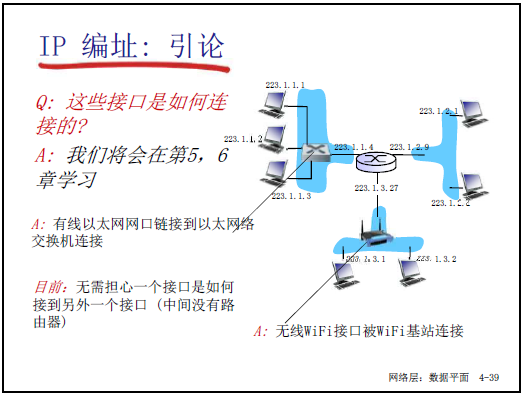
-
IP 地址为 32 位二进制数,用于标识主机或路由器的接口(而非设备):
-
路由器通常有多个接口,每个接口对应一个 IP 地址;主机可能有多个接口(如有线 + 无线),每个接口也对应一个 IP 地址。
-
示例:接口 IP =223.1.1.1(二进制 11011111 00000001 00000001 00000001),通过接口连接物理链路(如以太网、WiFi)。
-
(2)子网(Subnets)与子网掩码
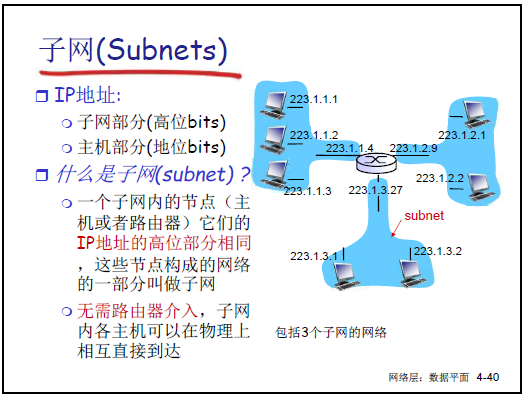
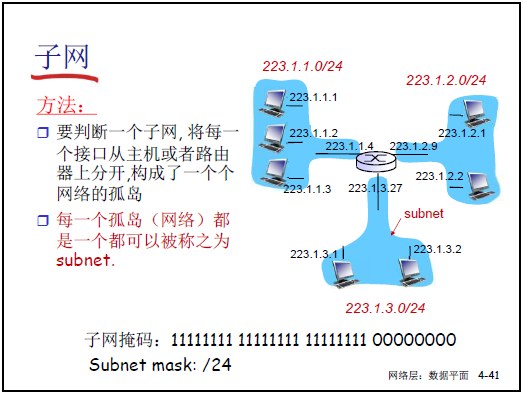
-
子网定义:IP 地址高位(子网部分)相同的节点(主机 / 路由器)集合,子网内节点无需路由器可直接通信。
-
子网表示:如 [223.1.1.0/24](CIDR 表示法,“/24” 表前 24 位为子网部分),对应子网掩码 [255.255.255.0](二进制 11111111 11111111 11111111 00000000)。
-
子网掩码作用:32 位二进制,“1” 对应 IP 地址的子网部分,“0” 对应主机部分;通过 “IP 地址 & 子网掩码” 可提取子网号,用于路由匹配。
(3)IP 地址分类与特殊地址
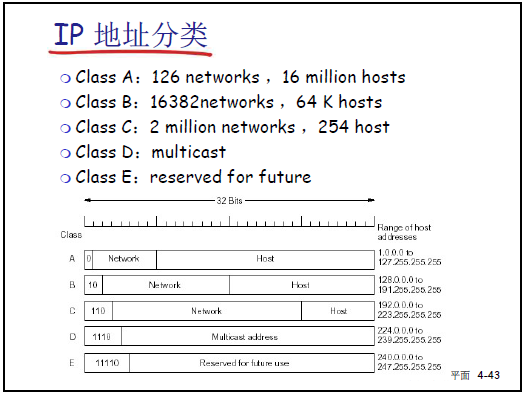

-
地址分类:
-
A 类:首位 0,范围 1.0.0.0-126.255.255.255,共 126 个网络,每个网络 16777214 个主机(排除子网 / 主机全 0 / 全 1)。
-
B 类:前两位 10,范围 128.0.0.0-191.255.255.255,共 16382 个网络,每个网络 65534 个主机。
-
C 类:前三位 110,范围 192.0.0.0-223.255.255.255,共 2097152 个网络,每个网络 254 个主机。
-
D 类:前四位 1110,用于多播(如 224.0.0.0-239.255.255.255;E 类:前四位 1111,预留未来使用。
-
-
特殊地址:
-
子网部分全 0:表示本网络;主机部分全 0:表示本主机。
-
主机部分全 1:广播地址,用于向子网内所有主机发送数据(如 223.1.1.255)。
-
127.x.x.x:回路地址(如 127.0.0.1),用于主机自测(发送给该地址的数据包不经过网络,直接回环到本机上层协议)。
-
(4)内网(专用)IP 地址

-
定义:地址空间中预留的专用地址,不分配为公网地址,仅在局域网内有效,路由器不转发目标为专用地址的数据包。
-
专用地址范围:
-
A 类:10.0.0.0-10.255.255.255(子网掩码 255.0.0.0)。
-
B 类:172.16.0.0-172.31.255.255(子网掩码 255.255.0.0)。
-
C 类:192.168.0.0-192.168.255.255(子网掩码 255.255.255.0)。
(5)CIDR(无类域间路由)

-
背景:解决 A/B/C 类地址浪费问题(如 B 类网络过大、C 类过小),子网部分可在 IP 地址任意位置划分。
-
格式:a.b.c.d/x,x 为子网长度(如 200.23.16.0/23,前 23 位为子网部分,子网掩码 11111111 11111111 11111110 00000000)。
(6)转发表和转发算法
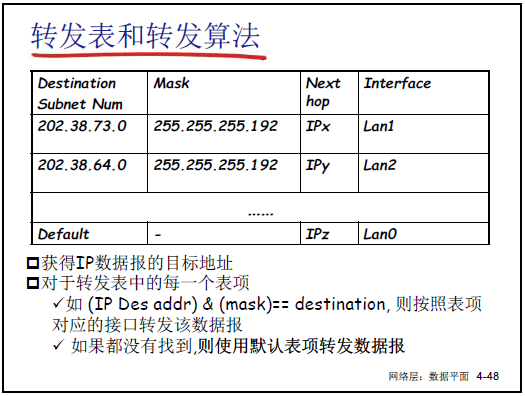
-
转发表结构:包含 “目标子网号、掩码、下一跳 IP、输出接口” 四列。
-
转发流程:
- 提取 IP 数据报的目的 IP 地址。
- 对转发表中每个表项,计算 “目的 IP & 掩码”,若结果等于 “目标子网号”,则按该表项的 “输出接口” 转发。
- 若所有表项均不匹配,按 “默认表项”(通常指向默认网关)转发。
(7)IP 地址获取方式

①手工配置
-
Windows:控制面板→网络→TCP/IP 属性,手动输入 IP、子网掩码、默认网关、DNS 服务器。
-
UNIX/Linux:编辑 /etc/rc.config 等配置文件,写入 IP 相关参数。
②DHCP(动态主机配置协议)

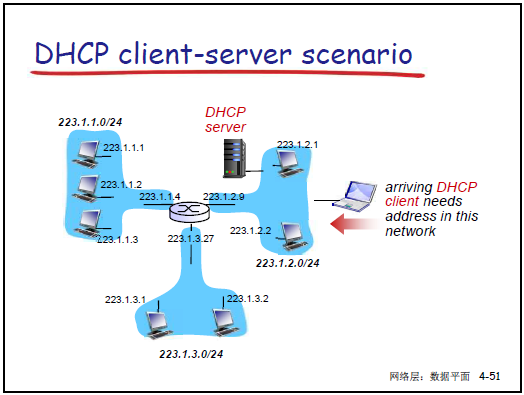

-
目标:实现 “即插即用”,主机动态从 DHCP 服务器获取 IP 及配套信息,支持租期更新、移动用户接入。
-
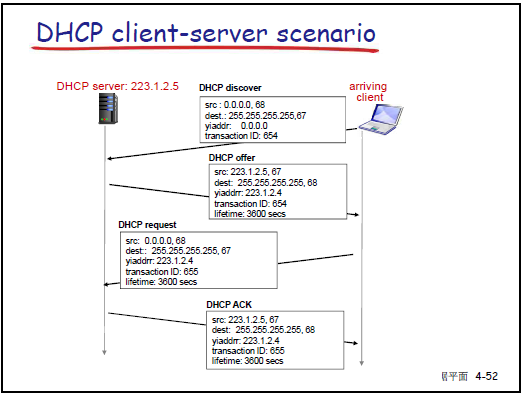
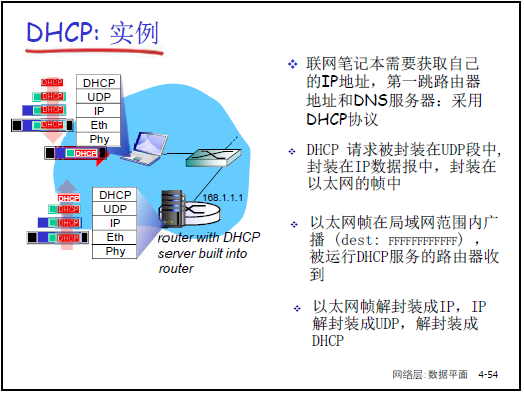
工作流程:
- DHCP Discover:主机广播请求(源 IP 0.0.0.0,目的 IP 255.255.255.255),寻找 DHCP 服务器。
- DHCP Offer:DHCP 服务器广播响应,提供 IP 地址、租期(如 3600 秒)、子网掩码等。
- DHCP Request:主机广播请求,确认使用某 DHCP 服务器提供的 IP。
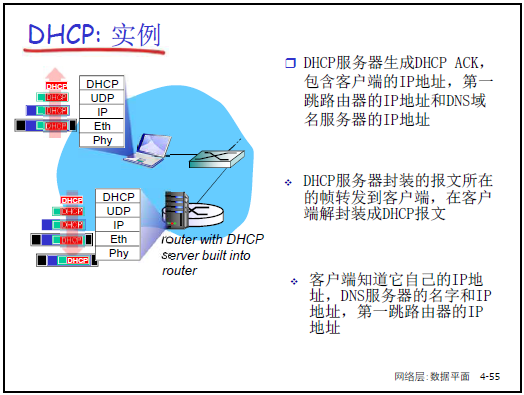
- DHCP ACK:DHCP 服务器广播确认,正式分配 IP 及配套信息(默认网关、DNS 服务器地址)。
-
DHCP 返回信息:IP 地址、子网掩码、第一跳路由器(默认网关)IP、DNS 服务器 IP。

(8)机构地址块获取与路由聚集
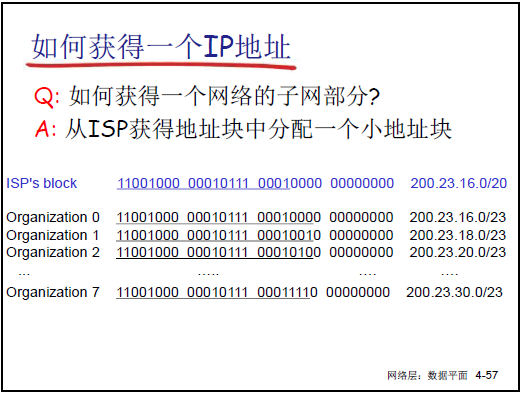
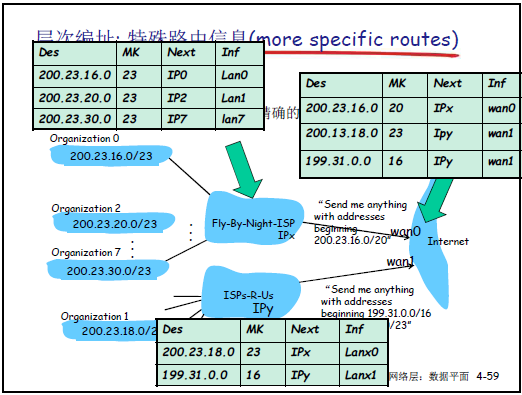

-
地址块获取:
-
方式 1:从 ISP(互联网服务提供商)分配(如 ISP 从 ICANN 获得大地址块,再拆分给下属机构)。
-
方式 2:直接向 ICANN(互联网名称与数字地址分配机构)申请,ICANN 负责全球 IP 地址分配、DNS 管理。
-
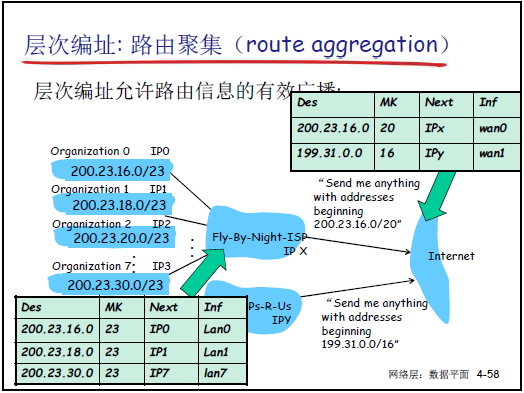
-
路由聚集:基于层次编址,将多个连续子网的路由信息合并为一条,减少广域网路由表项数量。例如:200.23.16.0/23、200.23.18.0/23等 8 个子网,可聚集为 200.23.16.0/20(前 20 位相同),降低路由信息传输与计算代价。
4.3.4 NAT(网络地址转换)
(1)动机
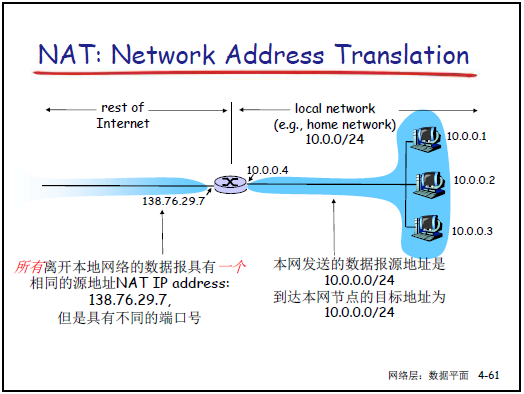

-
节省公网 IP:局域网内设备使用专用 IP,共用一个公网 IP 访问互联网。
-
灵活性:内网设备地址变化无需通知外界,更换 ISP 时仅需修改 NAT 路由器的公网 IP,不影响内网。
-
安全性:内网设备对外不可见,减少外部直接攻击风险。
(2)实现原理

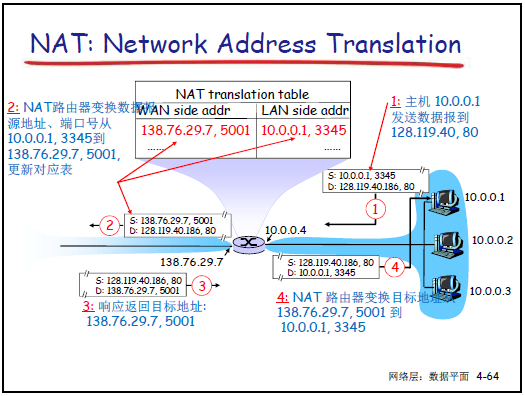
-
NAT 路由器核心功能:维护 “NAT 转换表”(记录内网 IP + 端口与公网 IP + 端口的映射关系)。
-
外出数据包:替换源 IP 为 NAT 公网 IP,源端口为新端口(未被占用),目标 IP / 端口不变,更新转换表。
-
进入数据包:根据目标 IP + 端口查询转换表,替换为内网 IP + 端口,源 IP / 端口不变。
-
-
端口资源:16 位端口字段支持 65535 个同时连接,满足局域网多设备并发访问需求。
(3)争议与 NAT 穿越

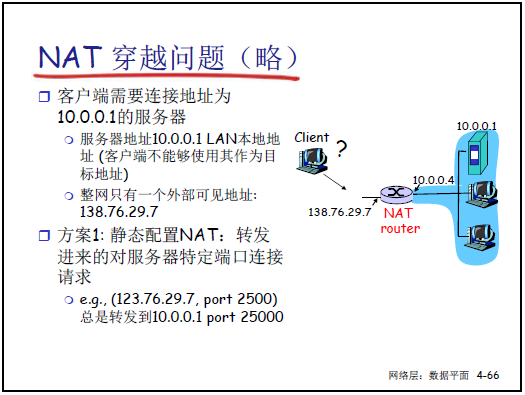
-
争议:
-
违反分层原则:路由器(网络层设备)处理传输层端口信息。
-
违反端到端原则:需在中间设备(NAT 路由器)维护连接状态,增加网络复杂性。
-
外网无法主动访问内网设备:需特殊机制实现 “NAT 穿越”。
-
-
NAT 穿越方案:
-
静态配置:固定映射公网 IP + 端口到内网 IP + 端口(如公网 138.76.29.7:2500 映射到内网 10.0.0.1:2500)。
-
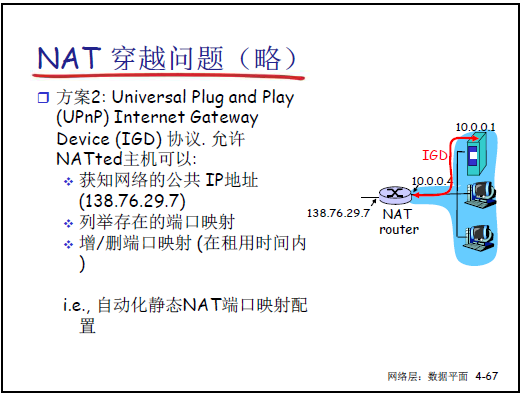
UPnP(通用即插即用):内网设备通过 UPnP 协议自动查询、添加 / 删除 NAT 映射表项。
-
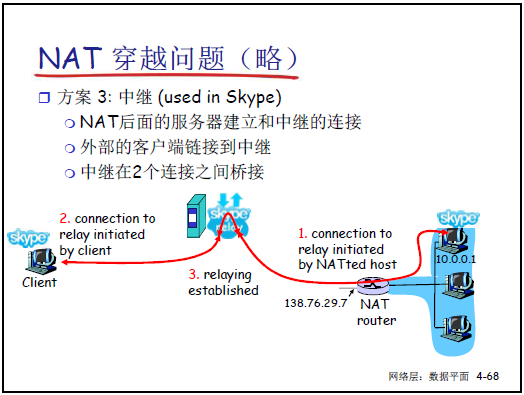
中继(如 Skype):内网设备主动与中继服务器建立连接,外网设备通过中继服务器与内网设备通信。
-
4.3.5 IPv6
(1)动机

-
IPv4 地址耗尽:32 位 IPv4 地址仅约 43 亿个,无法满足物联网等场景需求;IPv6 为 128 位地址,地址空间极大(可满足长期需求)。
-
简化头部处理:移除校验和(由链路层 / TCP/UDP 校验)、固定头部长度(40 字节),加速路由器转发。
-
支持 QoS:新增 “优先级”“流标签” 字段,便于对不同数据流提供差异化服务。
-
取消路由器分片:仅目标主机重组,路由器若遇 MTU 不足,直接丢弃数据包并发送 ICMPv6 “Packet Too Big” 报文,由源主机调整数据包大小。
(2)IPv6 头部格式

-
固定 40 字节头部:
-
版本(4 位,IPv6 为 6)、优先级(4 位,数据流优先级)、流标签(20 位,标识同一数据流)。
-
载荷长度(16 位,头部后的数据长度)、下一跳(8 位,指示上层协议或选项)、跳限制(8 位,类似 IPv4 的 TTL)。
-
源 IP 地址(128 位)、目的 IP 地址(128 位)。
-
(3)与 IPv4 的关键差异

-
移除头部校验和:降低路由器处理开销。
-
选项处理:选项通过 “下一跳” 字段标识,不包含在固定头部中,保持头部简洁。
-
ICMPv6:新增报文类型(如 “Packet Too Big”),整合 IPv4 中 IGMP(多播组管理)功能,支持多播组加入 / 退出。
(4)IPv4 到 IPv6 的平移

-
核心挑战:无法通过 “标记日(Flag Day)” 一次性升级(设备数量庞大,用户 / 应用兼容性要求高),需平滑过渡。
-
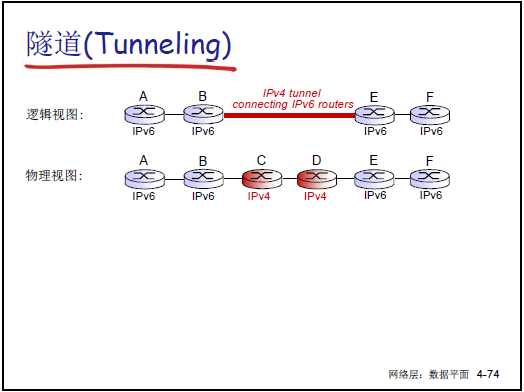
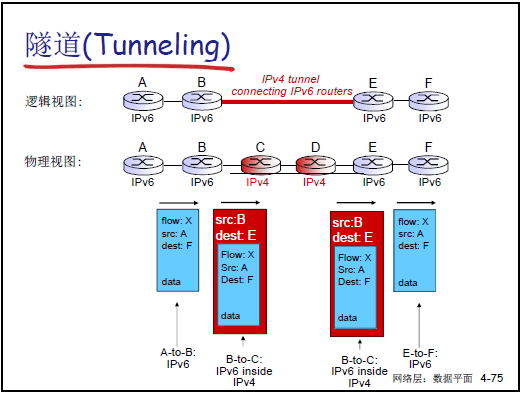
隧道技术:在 IPv4 网络中传输 IPv6 数据包,将 IPv6 数据包封装为 IPv4 数据包的载荷,通过 IPv4 路由器传输,到达目标 IPv6 网络后解封装。例如:两个 IPv6 “孤岛” 通过 IPv4 “海洋” 通信,借助隧道实现数据互通。
(5)IPv6 应用现状
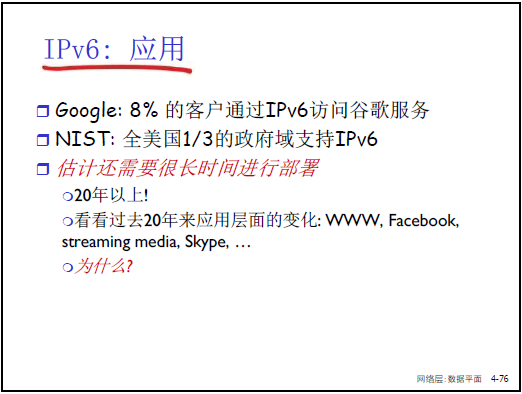
-
部分场景已落地:谷歌约 8% 用户通过 IPv6 访问服务,美国 NIST(国家标准与技术研究院)1/3 政府域支持 IPv6。
-
部署周期长:预计需 20 年以上完成全面过渡,因设备升级、应用兼容性适配需长期推进。
4.4 通用转发和 SDN
4.4.1 传统网络的控制平面与数据平面
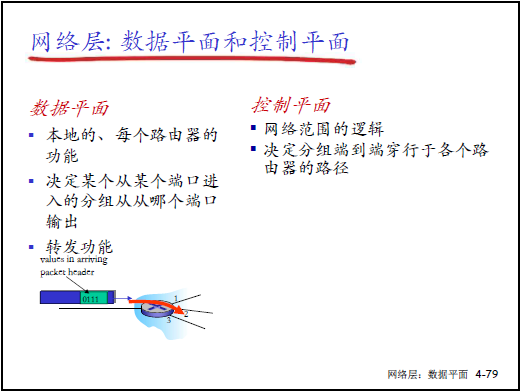
(1)网络层功能的平面划分

- 核心逻辑:网络层功能分为 “数据平面” 与 “控制平面”,两者配合实现主机到主机的分组交付;
- 类比:
- 转发(数据平面):类似 “通过单个路口的进出过程”(局部动作);
- 路由(控制平面):类似 “从源到目标的旅行路径规划”(全局决策)。
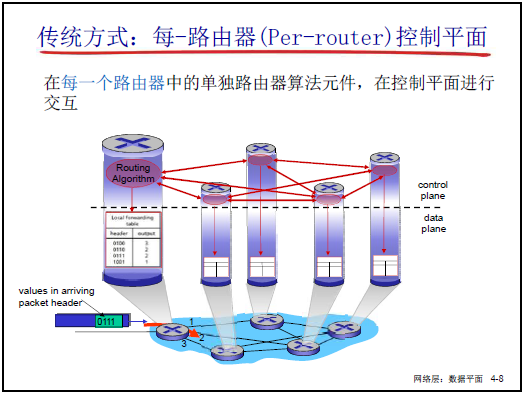
(2)传统控制平面的实现方式
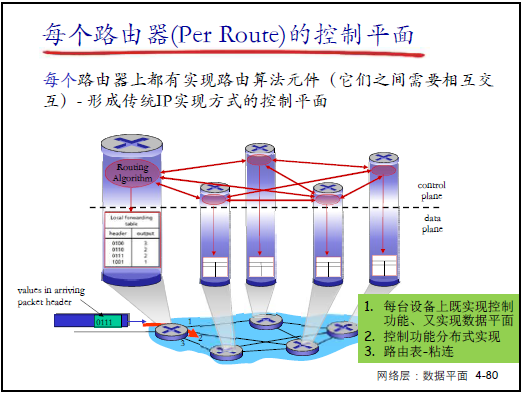
- 垂直集成:每台路由器同时实现控制平面与数据平面功能:
- 控制平面:路由器运行 “路由协议实体”,通过与其他路由器的路由通告(如 “告知邻居下一跳”)计算路由表;
- 数据平面:路由器的 “RP 协议实体” 按路由表对分组执行转发;
- 分布式实现:每台路由器仅实现控制平面的一部分功能,通过路由协议交互(如 OSPF),共同完成全局路由计算(老师举例:“全球几百万台路由器,各自算路由表,再配合实现全网可达”);
- 核心粘连:路由表是控制平面与数据平面交互的关键(控制平面生成路由表,数据平面依赖路由表转发)。
4.4.2 传统网络的问题:中间盒与垂直集成缺陷
(1)数量众多、功能各异的中间盒

- 中间盒类型:除路由器外,还有交换机、防火墙、NAT、IDS(入侵检测系统)、负载均衡设备等;
- 核心问题:
- 功能与设备绑定:每个网络功能需专属设备实现,且每台设备均 “垂直集成控制 + 数据平面”;
- 维护难度大:网络管理员需掌握不同设备的拓扑、工作原理及配置(老师举例:“新人难以快速上手,网络管理员薪资高,因需维护大量复杂设备”);
- 升级成本高:新增功能需部署新设备,无法通过软件灵活调整。
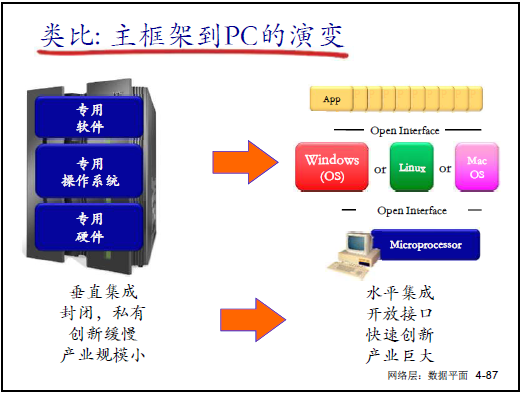
(2)垂直集成的核心缺陷(对应课件 4-82、4-83)


-
垂直集成的三层绑定:
- 硬件绑定:设备硬件为厂商专属(如华为路由器硬件);
- OS 绑定:硬件需运行厂商私有 OS(如华为专用 OS、新华三 Commware OS);
- 协议绑定:OS 上运行厂商私有实现的标准协议(如 IP、OSPF);
- 老师举例:“买华为设备不能拆卖 —— 无法用华为硬件跑其他 OS,也不能用其他硬件跑华为软件,被厂商‘绑架’”;
-
传统方式的三大问题:
- 成本高、生态差:垂直集成无竞争,设备昂贵,阻碍第三方创新;
- 功能固化、灵活度低:无法实现流量工程(如拆分流量),升级需全网设备变更(如 IPv4→IPv6 难);
- 管理复杂:配置错误影响全网,新增功能需部署新设备;
-
突破方向:2005 年提出 “控制平面与数据平面分离 + 集中控制”,即 SDN 雏形。
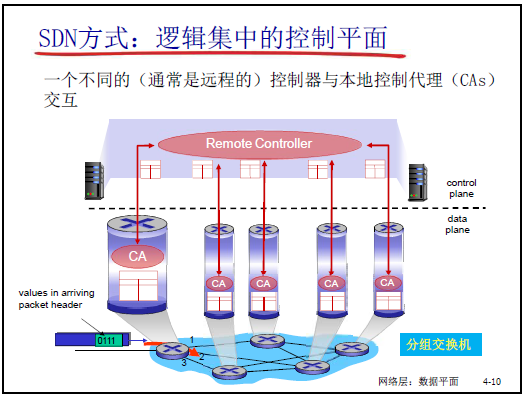
4.4.3 SDN 的核心思路与架构
(1)SDN 的核心思想:控制与数据平面分离
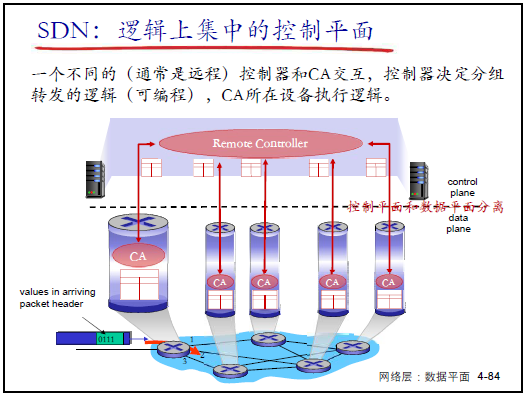

- 核心逻辑:打破传统 “垂直集成”,将控制平面从设备中剥离,由远程控制器集中实现;
- 架构分工:
- 数据平面:分组交换机(SDN 交换机)—— 仅按流表执行 “匹配 + 行动”,功能单一(如转发、丢弃、修改字段);
- 控制平面:控制器 + 网络应用 —— 控制器集中计算流表,网络应用(如路由 APP、防火墙 APP)实现具体网络功能;
- 强调:“运营商仅需部署一种 SDN 交换机,下发不同流表即可实现路由器、防火墙等功能,大幅降低设备维护成本”。
(2)SDN 的优势

- 开放生态:水平集成控制平面,交换机、控制器、网络应用可由不同厂商提供(如白盒交换机厂商竞争,价格降低);
- 易管理:控制器掌握全网状态,集中编程替代分布式配置,减少误操作;
- 可编程:通过修改网络应用或流表,快速升级网络功能(如无需等待 “标记日”,改流表即可调整路由)。
(3)SDN 的三大核心特点
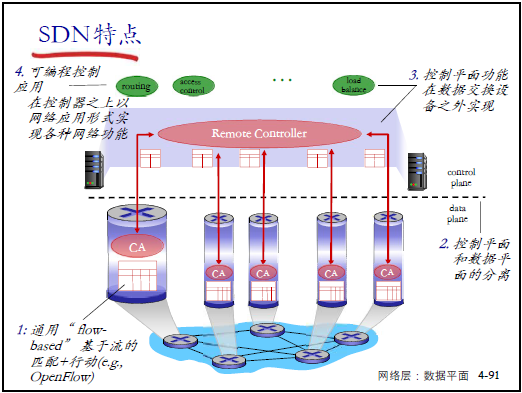
- 基于流的 “匹配 + 行动” 机制(如 OpenFlow):匹配多字段(源 IP、端口等),支持多动作;
- 控制平面与数据平面分离:数据平面仅执行,控制平面集中决策;
- 控制平面在数据设备外实现:网络功能以 APP 形式运行在控制器上,支持灵活扩展。
(4)SDN 架构的三大组件
① 数据平面:SDN 分组交换机
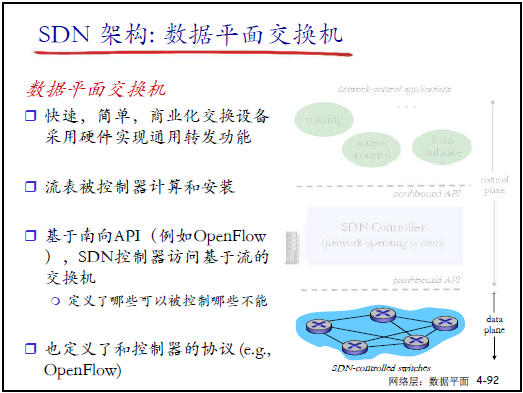
- 特点:快速、简单、标准化,硬件实现转发功能;
- 核心交互:通过南向 API(如 OpenFlow)接收控制器下发的流表,上报自身状态(如端口流量);
- 补充:“交换机像‘执行者’,不做复杂计算,仅按流表行动,成本低且易批量部署”。
② 控制平面:SDN 控制器(网络 OS)
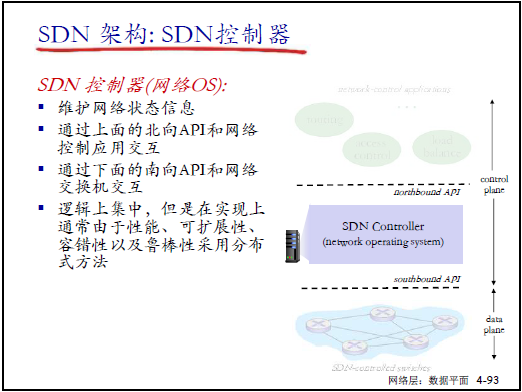
- 核心功能:维护全网状态、计算流表、通过南北向接口交互;
- 接口分工:
- 北向接口:与网络应用交互,接收功能需求(如防火墙 APP 需 “block 128.119.1.1”);
- 南向接口:与交换机交互,下发流表、接收状态上报;
- 部署特点:逻辑上集中,物理上可分布式部署(保障性能与可靠性)。
③ 控制应用
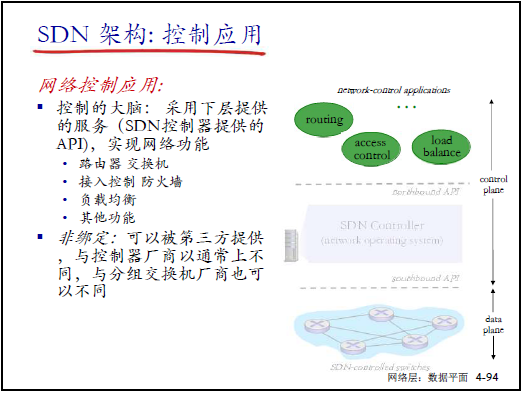
- 定位:网络的 “智能中枢”,基于控制器 API 实现网络功能(如路由、防火墙、负载均衡);
- 优势:与厂商解耦 —— 第三方可开发应用(如创业公司开发新型流量调度 APP),促进创新。
4.4.4 OpenFlow:SDN 的 “匹配 + 行动” 标准
(1)流表:SDN 转发的核心
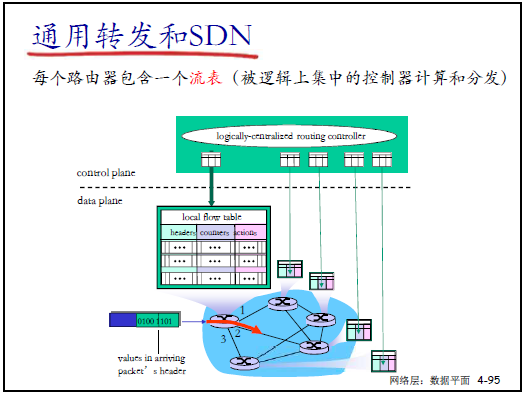


- 流的定义:由分组头部字段(如源 IP、目标 MAC、TCP 端口)共同定义的分组集合;
- 通用转发规则四要素:
- 模式(Pattern):分组头部字段与流表项匹配(支持通配符,如 “src=10.1..”);
- 行动(Action):对匹配分组执行的操作(转发、丢弃、上报控制器等);
- 优先权(Priority):解决多表项匹配歧义(优先级高的先执行);
- 计数器(Counters):统计匹配的分组数、字节数(用于流量监控)。
(2)OpenFlow 流表项结构
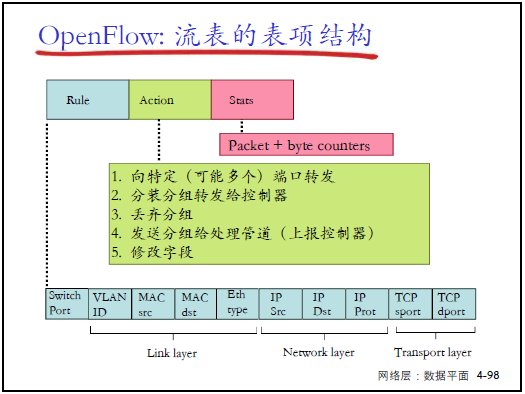
- 表项组成:Rule(匹配规则)+ Action(行动)+ Stats(统计);
- 匹配规则(Rule):覆盖链路层(MAC)、网络层(IP)、传输层(TCP/UDP 端口)字段;
- 行动(Action):支持转发到端口、丢弃、修改字段、上报控制器等;
- 统计(Stats):记录匹配的分组数、字节数。
(3)OpenFlow 应用实例
① 实现传统设备功能
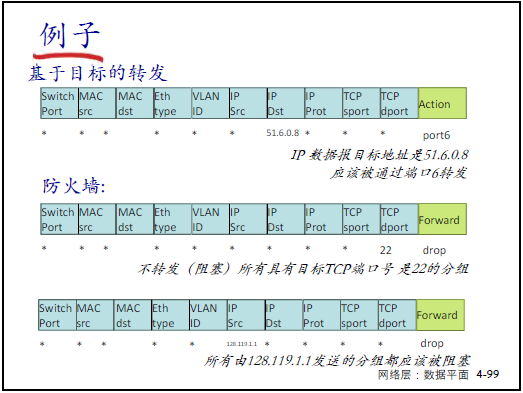
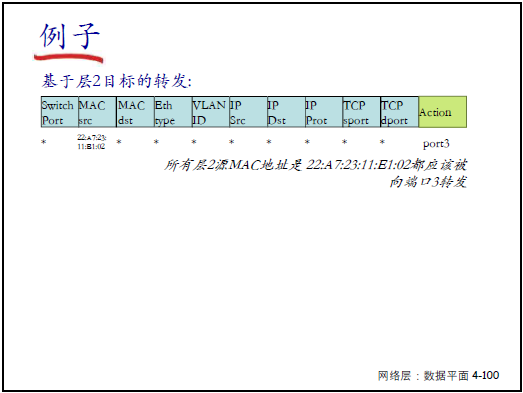
- 路由器:匹配 “目标 IP(最长前缀)”,行动 “转发到指定端口”;
- 防火墙:匹配 “TCP 端口 = 22” 或 “源 IP=128.119.1.1”,行动 “丢弃”;
- 交换机:匹配 “源 MAC=22:A7:23:11:E1:02”,行动 “转发到端口 3”;
- NAT:匹配 “源 IP=10.0.0.1”,行动 “修改源 IP 为 138.76.29.7”。
② 统一网络设备功能

- 核心逻辑:所有网络设备(路由器、防火墙、NAT 等)均可通过 “匹配 + 行动” 抽象描述,实现 “一种设备支持多场景”;
- 老师强调:“运营商仅需管理一种 SDN 交换机,通过流表切换功能,可维护性大幅提升”。
4.4.5 SDN 的流量工程优势
(1)传统路由的流量工程困境
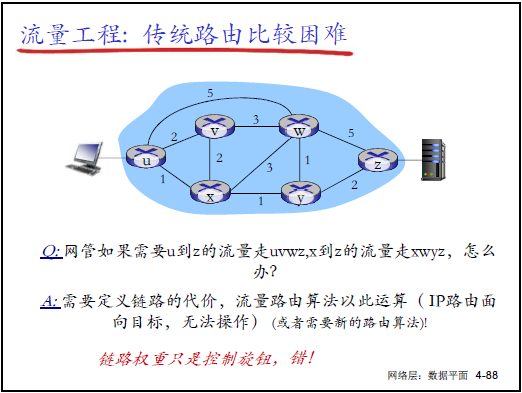
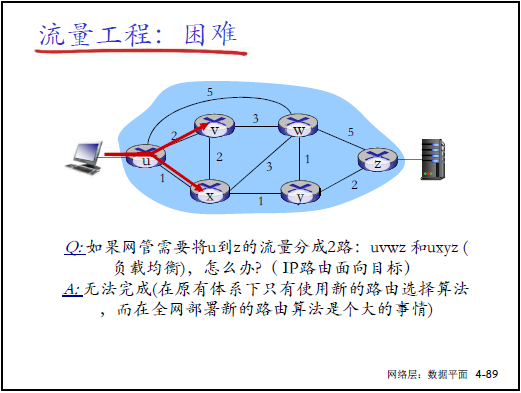
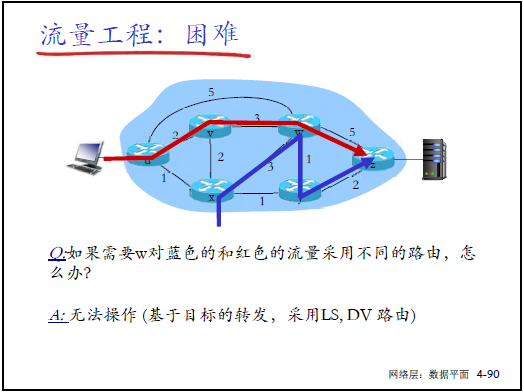
- 传统局限:仅基于 “目标 IP + 链路代价” 选路,无法实现:
- 路径控制(如指定 U→Z 走特定路径);
- 流量拆分(如 U→Z 的流量分两路负载均衡);
- 流量区分(如蓝色流量与红色流量走不同路径)。
(2)SDN 的流量控制实例
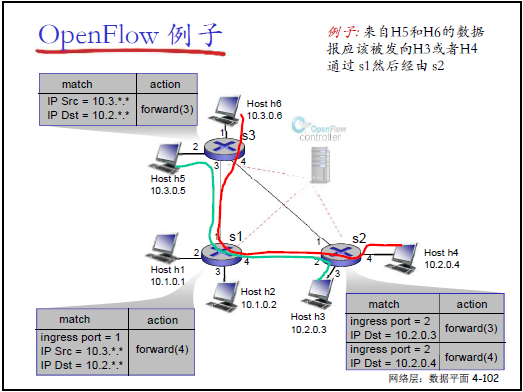
-
场景:控制 H5(10.3.0.5)→H3(10.2.0.3)走 “S1→S3”,H6(10.3.0.6)→H4(10.2.0.4)走 “S1→S2”;
-
流表配置(S1 为例):
匹配条件 行动 ingress port=1,IP src=10.3..,IP dst=10.2.. forward(4) ingress port=2,IP dst=10.2.0.3 forward(3) -
优势:通过多字段匹配(入端口、源 IP、目标 IP),精准控制路径,传统路由无法实现。
4.4.6 4.4 核心总结
- 传统网络:控制 + 数据平面垂直集成,转发表由分布式路由协议生成,功能固化;
- SDN:控制 + 数据平面分离,流表由集中式控制器生成,网络可编程;
- 关键衔接:流表 / 转发表的计算逻辑(控制平面如何生成规则),将在第 5 章详细讲解。
参考资料来源:中科大郑烇、杨坚全套《计算机网络(自顶向下方法 第7版,James F.Kurose,Keith W.Ross)》课程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号