第四次作业----K均值算法--应用
1. 应用K-means算法进行图片压缩
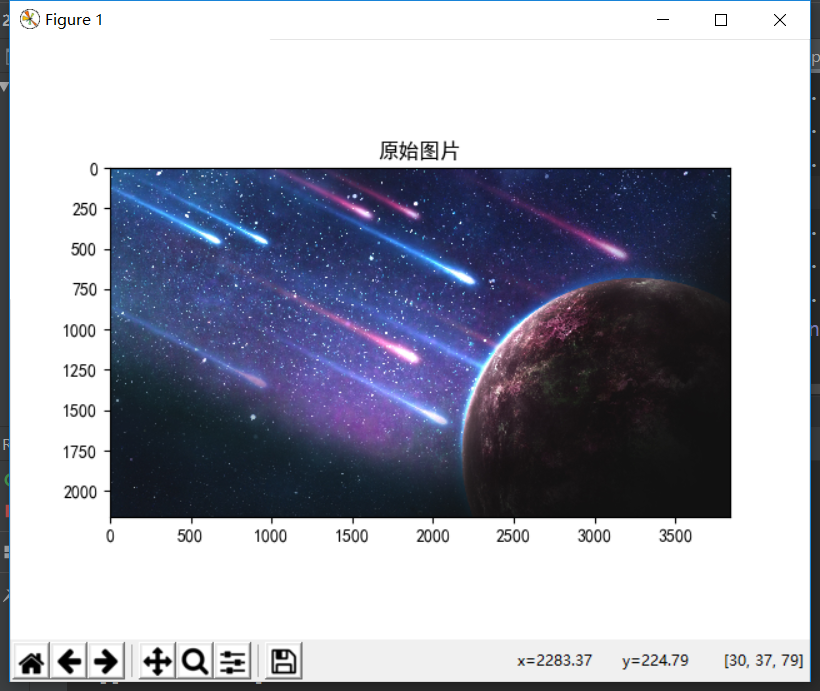
读取一张图片
观察图片文件大小,占内存大小,图片数据结构,线性化
用kmeans对图片像素颜色进行聚类
获取每个像素的颜色类别,每个类别的颜色
压缩图片生成:以聚类中收替代原像素颜色,还原为二维
观察压缩图片的文件大小,占内存大小
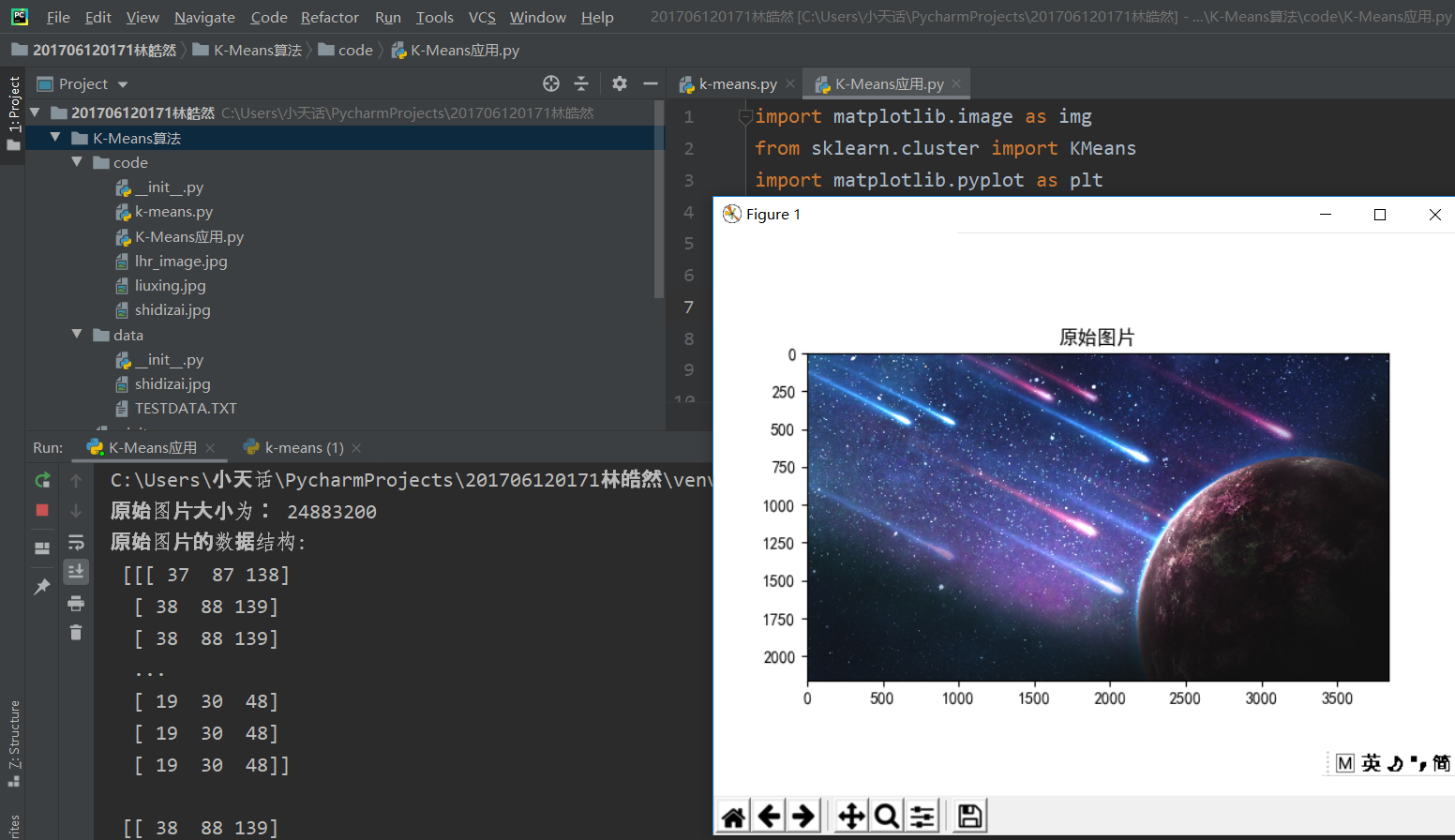
读取图片,获得图片大小和数据结构,如下图
这里说明一下,getsizeof和size不一样
(1)sys.getsizeof只计算实际使用的内存大小,引用所消耗的内存大小不计算。
(2)sys.getsizeof只能作为计算内存大小的参考~
因为读取的图片都是占用内存大小为128,所以这里我用size来获取图片大小
用kmeans对图片像素颜色进行聚类
获取每个像素的颜色类别,每个类别的颜色
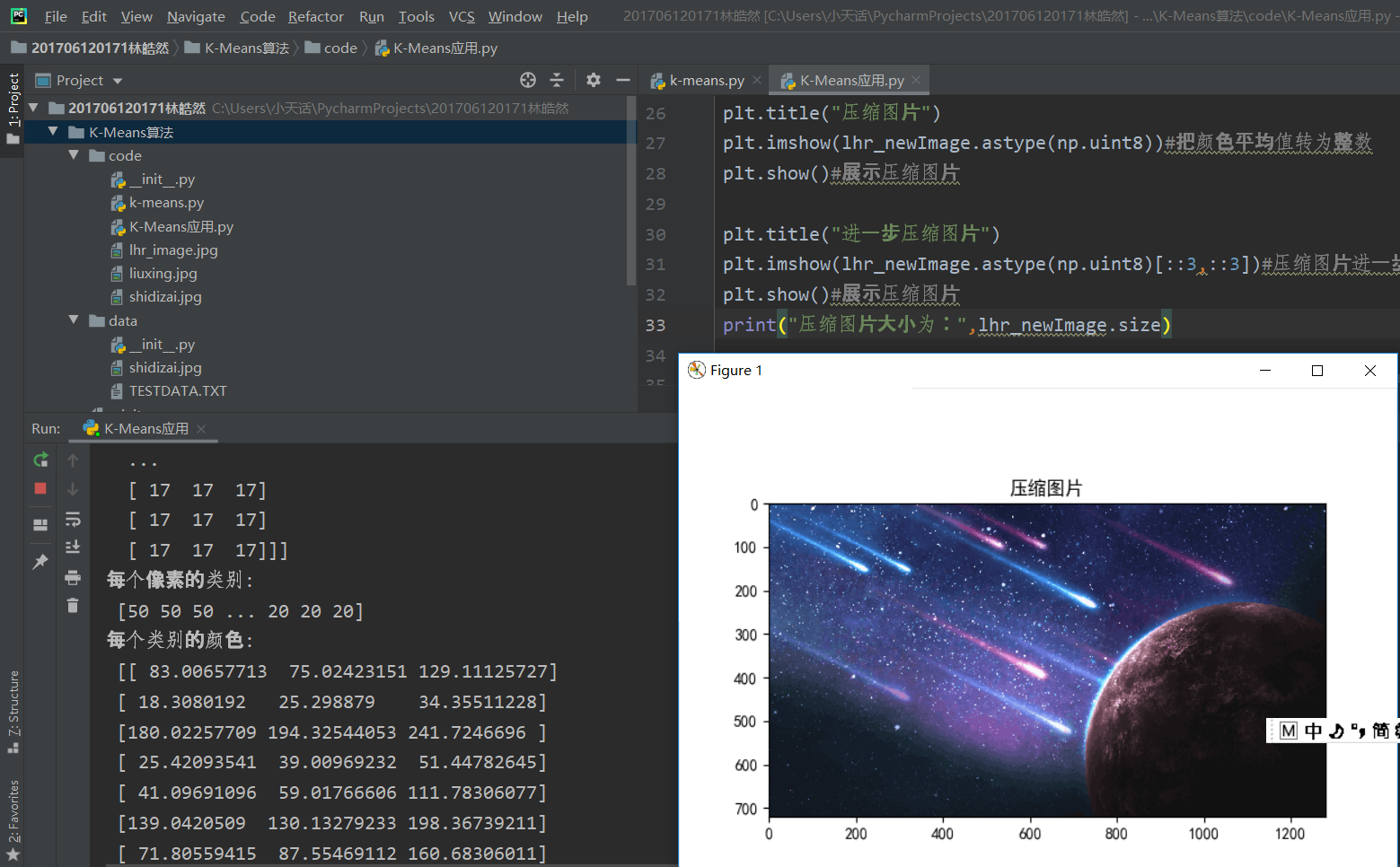
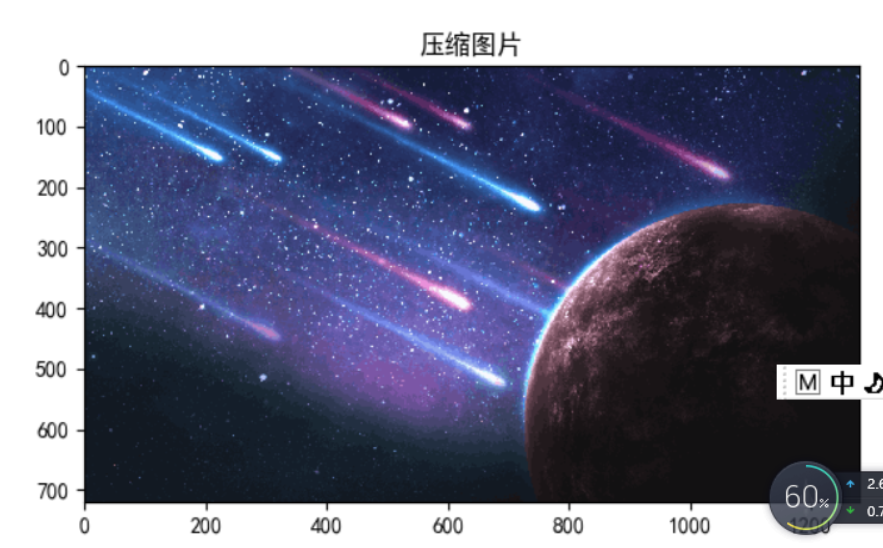
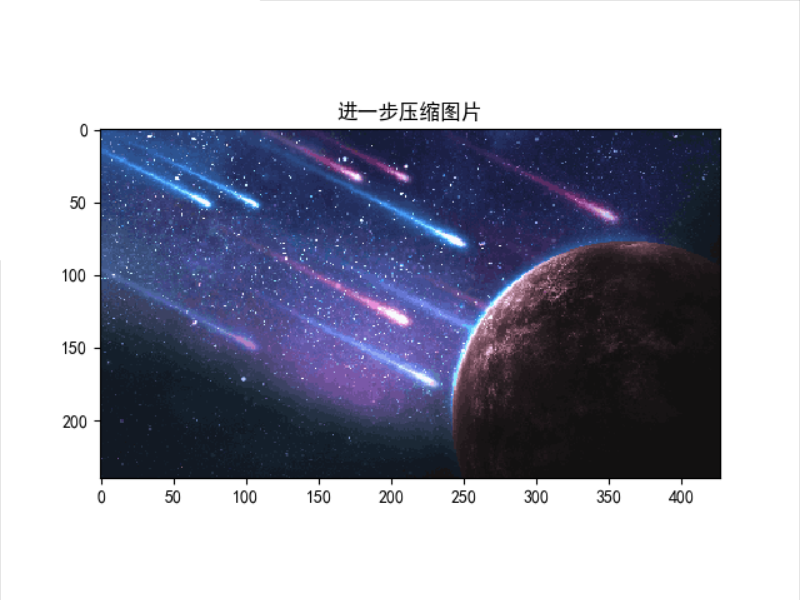
压缩图片大小和效果如图所示。
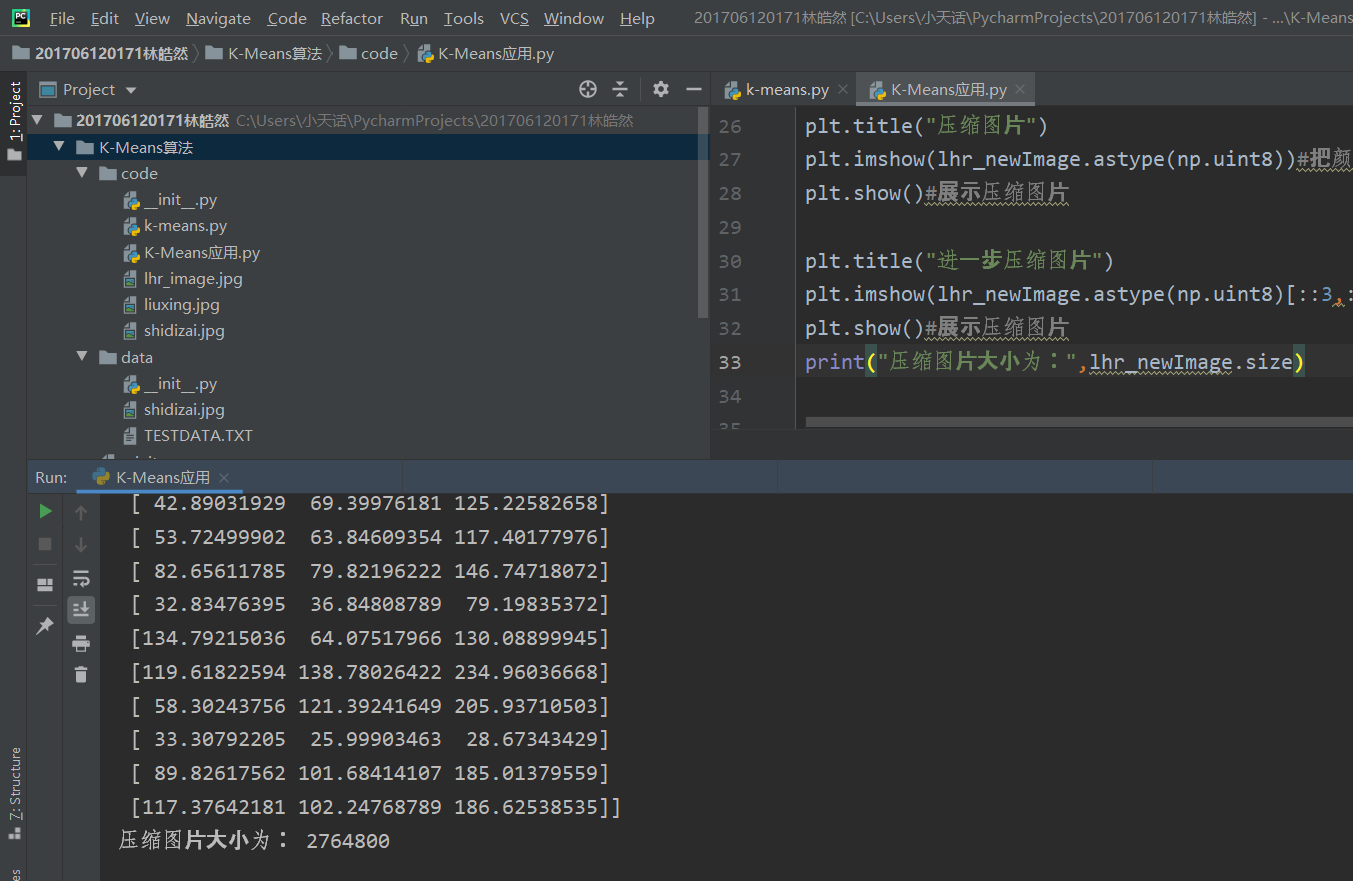
可以看到原始图片大小由24883200变为2764800。压缩图片成功!
原始图片、压缩图片、进一步压缩图片效果如图所示。
完整实现代码如下:
import matplotlib.image as img from sklearn.cluster import KMeans import matplotlib.pyplot as plt import numpy as np lhr_image = img.imread("liuxing.jpg") #读入图片路径 print("原始图片大小为:",lhr_image.size) print("原始图片的数据结构:\n",lhr_image) plt.rcParams['font.sans-serif'] = ['SimHei'] plt.title("原始图片") plt.imshow(lhr_image) plt.show() lhr_image=lhr_image[::3,::3] X = lhr_image.reshape(-1,3) # 进行线性化,因为只对颜色进行分类,所以丢弃位置信息 n_colors= 64#将255*255*255种颜色压缩成64种颜色 model= KMeans(n_colors)#建立模型 labels = model.fit_predict(X) #喂取数据 colors = model.cluster_centers_ #取出64个聚类中心,进行颜色值分类 lhr_newImage = colors[labels].reshape(lhr_image.shape) #以聚类中收替代原像素颜色,还原为二维 print("每个像素的类别:\n",labels) print("每个类别的颜色:\n",colors) plt.title("压缩图片") plt.imshow(lhr_newImage.astype(np.uint8))#把颜色平均值转为整数 plt.show()#展示压缩图片 plt.title("进一步压缩图片") plt.imshow(lhr_newImage.astype(np.uint8)[::3,::3])#压缩图片进一步压缩,隔3个像素选取 plt.show()#展示压缩图片 print("压缩图片大小为:",lhr_newImage.size)
2. 观察学习与生活中可以用K均值解决的问题。
从数据-模型训练-测试-预测完整地完成一个应用案例。
这个案例会作为课程成果之一,单独进行评分。
因为自己比较喜欢篮球,所以自己找了一点数据进行聚类分析,简单来说就是需要通过篮球运动员的数据来判断他属于什么样的球员。比如数据好的可能就是一流球员
首先看一下数据,一共有五列数据,96行数据
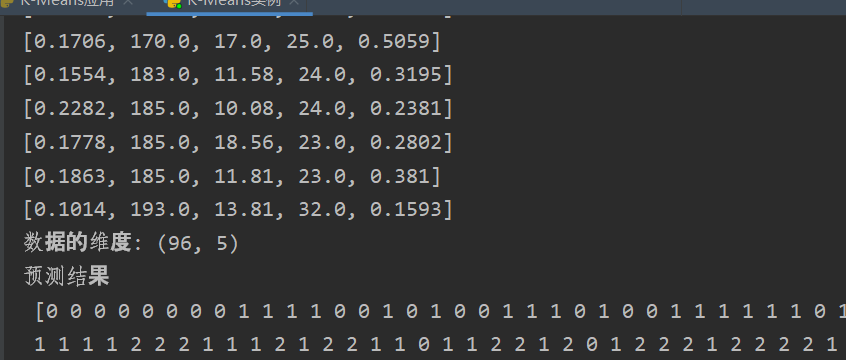
【1】每分钟助攻数【2】身高【3】出场时间【4】得分【5】每分钟得分数
进行模型构建,并且进行预测,得到预测结果如图所示。
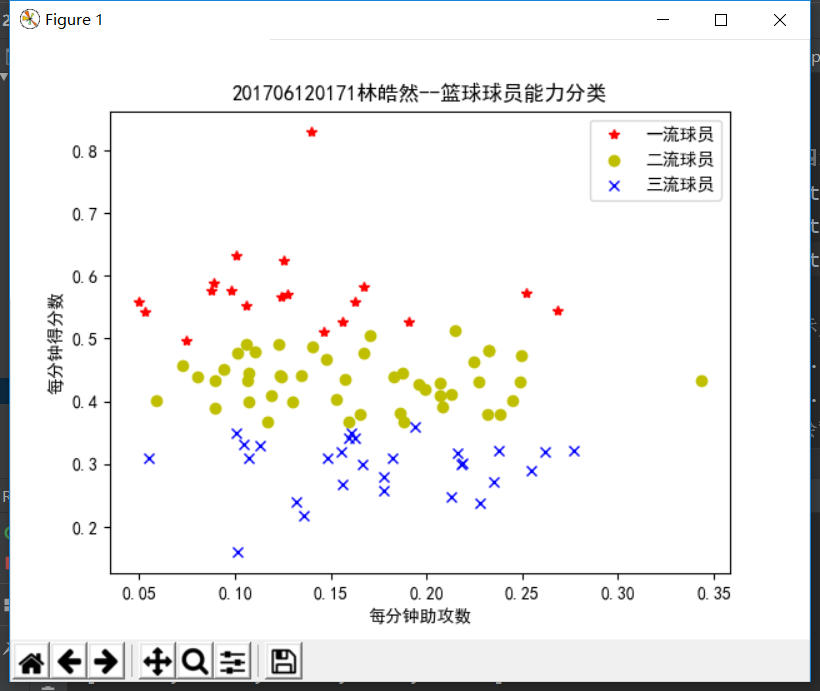
最终,得到分类结果如图所示,将97位球员数据分成了三类,区分出一流球员和二流球员以及三流球员。效果如图所示。
完整实现代码如下:
import matplotlib.pyplot as plt from sklearn.cluster import KMeans import numpy as np data = [] print("每分钟助攻数,身高,出场时间,得分,每分钟得分数") for line in open("../data/data.txt", "r").readlines(): line = line.rstrip() # 删除换行 result = ' '.join(line.split()) # strip()方法用于移除字符串头尾指定的字符(默认是空格),以,作为分隔符 s = [float(x.replace(',','')) for x in result.strip().split(' ')] print(s) # 数据累加到data里面 data.append(s) print("数据的维度:",(np.array(data)).shape) #求出第一列和第五列数据并转为list T = dict(zip([n[0] for n in data], [n[4] for n in data])) X = list(map(lambda x, y: (x, y), T.keys(), T.values())) LHR = KMeans(n_clusters=3) y_pred = LHR.fit_predict(X) # 输出聚类预测结果,96行数据,每个y_pred对应X一行或一个球员,聚成3类,类标为0、1、2 print("预测结果\n",y_pred) x1 = [] y1 = [] x2 = [] y2 = [] x3 = [] y3 = [] # 分别获取类别为0、1、2的数据分别赋值给(x1,y1) (x2,y2) (x3,y3) i = 0 while i < len(X): if y_pred[i] == 0: x1.append(X[i][0]) y1.append(X[i][1]) elif y_pred[i] == 1: x2.append(X[i][0]) y2.append(X[i][1]) elif y_pred[i] == 2: x3.append(X[i][0]) y3.append(X[i][1]) i = i + 1 plot1, = plt.plot(x1, y1, 'or', marker="*") plot2, = plt.plot(x2, y2, 'oy', marker="o") plot3, = plt.plot(x3, y3, 'ob', marker="x") # 标题 plt.rcParams['font.sans-serif'] = ['SimHei'] plt.title("201706120171林皓然--篮球球员能力分类") # 绘制x轴和y轴坐标 plt.xlabel("每分钟助攻数") plt.ylabel("每分钟得分数") # 设置图例 plt.legend((plot1, plot2, plot3), ('一流球员', '二流球员', '三流球员'), fontsize=10) plt.show()
通过这两次课也慢慢了解到了基本K-means的核心思想,并且可以熟练运用在生活之中。加油!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号