内存是如何分配的
内存分配流程图:
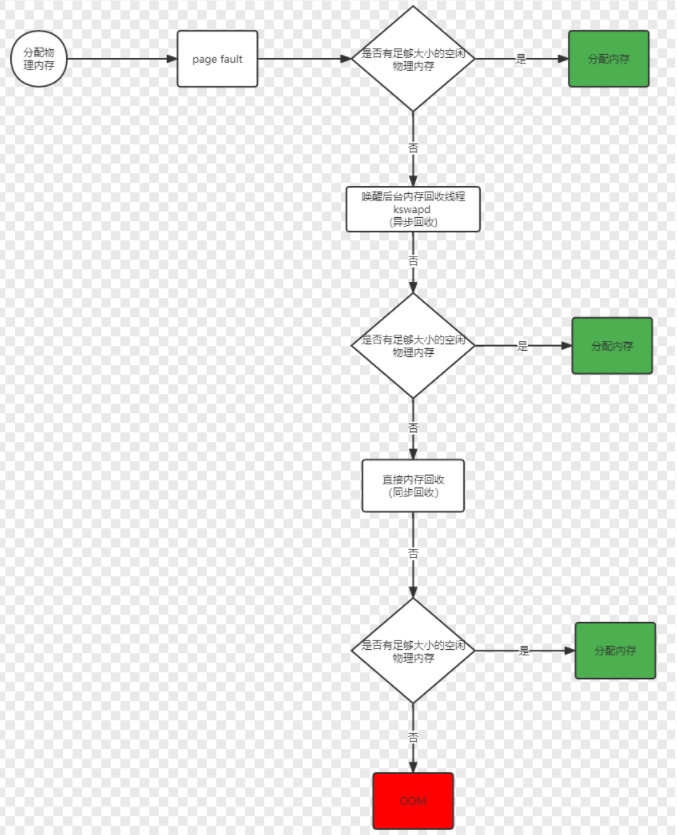
哪些内存可以被回收?
主要有两类内存可以被回收,而且它们的回收方式也不同。
- 文件页(File-backed Page):内核缓存的磁盘数据(Buffer)和内核缓存的文件数据(Cache)都叫作文件页。大部分文件页,都可以直接释放内存,以后有需要时,再从磁盘重新读取就可以了。而那些被应用程序修改过,并且暂时还没写入磁盘的数据(也就是脏页),就得先写入磁盘,然后才能进行内存释放。所以,回收干净页的方式是直接释放内存,回收脏页的方式是先写回磁盘后再释放内存。
- 匿名页(Anonymous Page):应用程序通过 mmap 动态分配的堆内存叫作匿名页,这部分内存很可能还要再次被访问,所以不能直接释放内存,它们回收的方式是通过 Linux 的 Swap 机制,Swap 会把不常访问的内存先写到磁盘中,然后释放这些内存,给其他更需要的进程使用。再次访问这些内存时,重新从磁盘读入内存就可以了。
文件页和匿名页的回收都是基于 LRU 算法,也就是优先回收不常访问的内存。LRU 回收算法,实际上维护着 active 和 inactive 两个双向链表,其中:
- active_list 活跃内存页链表,这里存放的是最近被访问过(活跃)的内存页;
- inactive_list 不活跃内存页链表,这里存放的是很少被访问(非活跃)的内存页;
越接近链表尾部,就表示内存页越不常访问。这样,在回收内存时,系统就可以根据活跃程度,优先回收不活跃的内存。
活跃和非活跃的内存页,按照类型的不同,又分别分为文件页和匿名页。可以从 /proc/meminfo 中,查询它们的大小,比如:
# grep表示只保留包含active的指标(忽略大小写)
# sort表示按照字母顺序排序
cat /proc/meminfo | grep -i active | sort
针对回收内存导致的性能影响,常见的解决方式:
1)调整文件页和匿名页的回收倾向
文件页对于干净页回收是不会发生磁盘 I/O 的,而匿名页的 Swap 换入换出这两个操作都会发生磁盘 I/O。
Linux 提供了一个 /proc/sys/vm/swappiness 选项,用来调整文件页和匿名页的回收倾向。
swappiness 的范围是 0-100,数值越大,越积极使用 Swap,也就是更倾向于回收匿名页;数值越小,越消极使用 Swap,也就是更倾向于回收文件页。一般建议 swappiness 设置为 0(默认就是 0),这样在回收内存的时候,会更倾向于文件页的回收,但是并不代表不会回收匿名页。
cat /proc/sys/vm/swappiness
2)尽早触发 kswapd 内核线程异步回收内存
查看系统的直接内存回收和后台内存回收的指标?
sar -B 1
指标介绍:
- pgscank/s : kswapd(后台回收线程) 每秒扫描的 page 个数。
- pgscand/s: 应用程序在内存申请过程中每秒直接扫描的 page 个数。
- pgsteal/s: 扫描的 page 中每秒被回收的个数(pgscank+pgscand)。
如果系统时不时发生抖动,并且在抖动的时间段里如果通过 sar -B 观察到 pgscand 数值很大,那大概率是因为「直接内存回收」导致的。
针对这个问题,解决的办法就是,可以通过尽早的触发「后台内存回收」来避免应用程序进行直接内存回收。
什么条件下才能触发 kswapd 内核线程回收内存呢?
内核定义了三个内存阈值(watermark,也称为水位),用来衡量当前剩余内存(pages_free)是否充裕或者紧张,分别是:
- 页最小阈值(pages_min);
- 页低阈值(pages_low);
- 页高阈值(pages_high);
三个内存阈值会划分为四种内存使用情况:
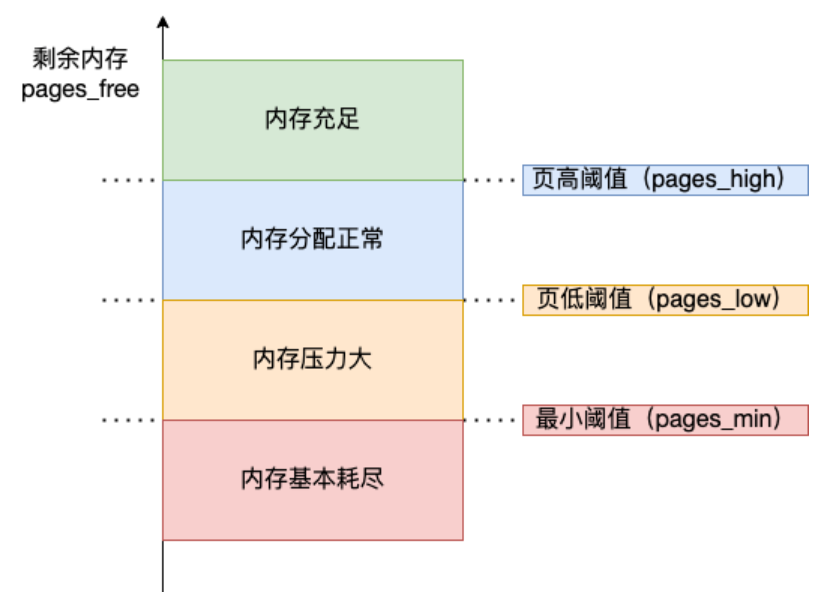
kswapd 的活动空间只有 pages_low 与 pages_min 之间的这段区域,如果剩余内测低于了 pages_min 会触发直接内存回收,高于了 pages_high 又不会唤醒 kswapd。
页低阈值(pages_low)可以通过内核选项 /proc/sys/vm/min_free_kbytes (该参数代表系统所保留空闲内存的最低限)来间接设置。
min_free_kbytes 虽然设置的是页最小阈值(pages_min),但是页高阈值(pages_high)和页低阈值(pages_low)都是根据页最小阈值(pages_min)计算生成的,它们之间的计算关系如下:
pages_min = min_free_kbytes pages_low = pages_min*5/4 pages_high = pages_min*3/2
如果系统时不时发生抖动,并且通过 sar -B 观察到 pgscand 数值很大,那大概率是因为直接内存回收导致的,这时可以增大 min_free_kbytes 这个配置选项来及早地触发后台回收,然后继续观察 pgscand 是否会降为 0。
增大了 min_free_kbytes 配置后,这会使得系统预留过多的空闲内存,从而在一定程度上降低了应用程序可使用的内存量,这在一定程度上浪费了内存。极端情况下设置 min_free_kbytes 接近实际物理内存大小时,留给应用程序的内存就会太少而可能会频繁地导致 OOM 的发生。
所以在调整 min_free_kbytes 之前,需要先思考一下,应用程序更加关注什么,如果关注延迟那就适当地增大 min_free_kbytes,如果关注内存的使用量那就适当地调小 min_free_kbytes。
NUMA 架构下的内存回收策略
SMP 指的是一种多个 CPU 处理器共享资源的电脑硬件架构,也就是说每个 CPU 地位平等,它们共享相同的物理资源,包括总线、内存、IO、操作系统等。每个 CPU 访问内存所用时间都是相同的,因此,这种系统也被称为一致存储访问结构(UMA,Uniform Memory Access)。
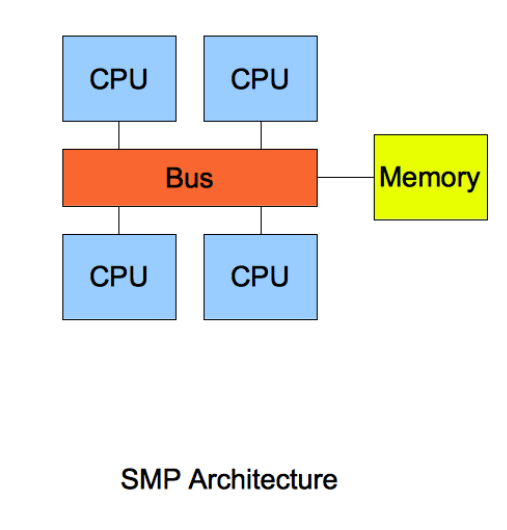
随着 CPU 处理器核数的增多,多个 CPU 都通过一个总线访问内存,这样总线的带宽压力会越来越大,同时每个 CPU 可用带宽会减少,这也就是 SMP 架构的问题。
NUMA 结构,即非一致存储访问结构(Non-uniform memory access,NUMA)。将每个 CPU 进行了分组,每一组 CPU 用 Node 来表示,一个 Node 可能包含多个 CPU 。
每个 Node 有自己独立的资源,包括内存、IO 等,每个 Node 之间可以通过互联模块总线(QPI)进行通信,所以,也就意味着每个 Node 上的 CPU 都可以访问到整个系统中的所有内存。但是,访问远端 Node 的内存比访问本地内存要耗时很多。
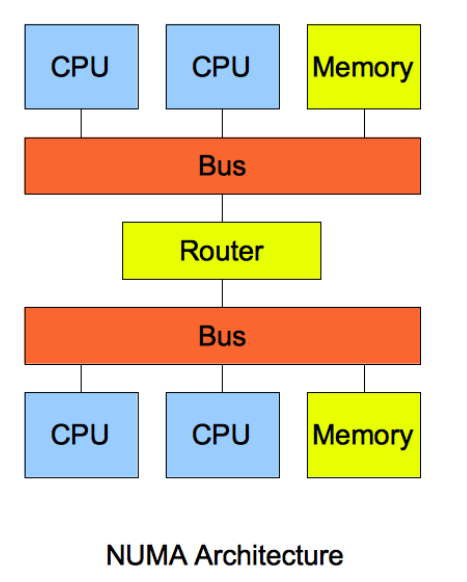
NUMA 架构跟回收内存有什么关系?
在 NUMA 架构下,当某个 Node 内存不足时,系统可以从其他 Node 寻找空闲内存,也可以从本地内存中回收内存。
具体选哪种模式,可以通过 /proc/sys/vm/zone_reclaim_mode 来控制。它支持以下几个选项:
- 0 (默认值):在回收本地内存之前,在其他 Node 寻找空闲内存;
- 1:只回收本地内存;
- 2:只回收本地内存,在本地回收内存时,可以将文件页中的脏页写回硬盘,以回收内存。
- 4:只回收本地内存,在本地回收内存时,可以用 swap 方式回收内存。
在使用 NUMA 架构的服务器,如果系统出现还有一半内存的时候,却发现系统频繁触发「直接内存回收」,导致了影响了系统性能,那么大概率是因为 zone_reclaim_mode 没有设置为 0 ,导致当本地内存不足的时候,只选择回收本地内存的方式,而不去使用其他 Node 的空闲内存。
虽然说访问远端 Node 的内存比访问本地内存要耗时很多,但是相比内存回收的危害而言,访问远端 Node 的内存带来的性能影响还是比较小的。因此,zone_reclaim_mode 一般建议设置为 0。
如何保护一个进程不被 OOM 杀掉呢?
在 Linux 内核里有一个 oom_badness() 函数,它会把系统中可以被杀掉的进程扫描一遍,并对每个进程打分,得分最高的进程就会被首先杀掉。
进程得分的结果受下面这两个方面影响:
- 第一,进程已经使用的物理内存页面数。
- 第二,每个进程的 OOM 校准值 oom_score_adj。它是可以通过
/proc/[pid]/oom_score_adj来配置的。我们可以在设置 -1000 到 1000 之间的任意一个数值,调整进程被 OOM Kill 的几率。
函数 oom_badness() 里的最终计算方法是这样的:
/ points 代表打分的结果 // process_pages 代表进程已经使用的物理内存页面数 // oom_score_adj 代表 OOM 校准值 // totalpages 代表系统总的可用页面数 points = process_pages + oom_score_adj*totalpages/1000
每个进程的 oom_score_adj 默认值都为 0,所以最终得分跟进程自身消耗的内存有关,消耗的内存越大越容易被杀掉。我们可以通过调整 oom_score_adj 的数值,来改成进程的得分结果:
- 如果你不想某个进程被首先杀掉,那你可以调整该进程的 oom_score_adj,从而改变这个进程的得分结果,降低该进程被 OOM 杀死的概率。
- 如果你想某个进程无论如何都不能被杀掉,那你可以将 oom_score_adj 配置为 -1000。
不建议将我们自己的业务程序的 oom_score_adj 设置为 -1000,因为业务程序一旦发生了内存泄漏,而它又不能被杀掉,这就会导致随着它的内存开销变大,OOM killer 不停地被唤醒,从而把其他进程一个个给杀掉。
总结:
内核在给应用程序分配物理内存的时候,如果空闲物理内存不够,那么就会进行内存回收的工作,主要有两种方式:
- 后台内存回收:在物理内存紧张的时候,会唤醒 kswapd 内核线程来回收内存,这个回收内存的过程异步的,不会阻塞进程的执行。
- 直接内存回收:如果后台异步回收跟不上进程内存申请的速度,就会开始直接回收,这个回收内存的过程是同步的,会阻塞进程的执行。
可被回收的内存类型有文件页和匿名页:
- 文件页的回收:对于干净页是直接释放内存,这个操作不会影响性能,而对于脏页会先写回到磁盘再释放内存,这个操作会发生磁盘 I/O 的,这个操作是会影响系统性能的。
- 匿名页的回收:如果开启了 Swap 机制,那么 Swap 机制会将不常访问的匿名页换出到磁盘中,下次访问时,再从磁盘换入到内存中,这个操作是会影响系统性能的。
文件页和匿名页的回收都是基于 LRU 算法,也就是优先回收不常访问的内存。回收内存的操作基本都会发生磁盘 I/O 的,如果回收内存的操作很频繁,意味着磁盘 I/O 次数会很多,这个过程势必会影响系统的性能。
针对回收内存导致的性能影响,常见的解决方式。
- 设置 /proc/sys/vm/swappiness,调整文件页和匿名页的回收倾向,尽量倾向于回收文件页;
- 设置 /proc/sys/vm/min_free_kbytes,调整 kswapd 内核线程异步回收内存的时机;
- 设置 /proc/sys/vm/zone_reclaim_mode,调整 NUMA 架构下内存回收策略,建议设置为 0,这样在回收本地内存之前,会在其他 Node 寻找空闲内存,从而避免在系统还有很多空闲内存的情况下,因本地 Node 的本地内存不足,发生频繁直接内存回收导致性能下降的问题;
在经历完直接内存回收后,空闲的物理内存大小依然不够,那么就会触发 OOM 机制,OOM killer 就会根据每个进程的内存占用情况和 oom_score_adj 的值进行打分,得分最高的进程就会被首先杀掉。
我们可以通过调整进程的 /proc/[pid]/oom_score_adj 值,来降低被 OOM killer 杀掉的概率。
原文地址:https://mp.weixin.qq.com/s/ciisLBp6ijjTJZfSMGj0Jw

 浙公网安备 33010602011771号
浙公网安备 33010602011771号