分库分表之shardingjdbc应用相关概念和原理(二)
源码地址:https://github.com/apache/shardingsphere
Apache ShardingSphere 提供的 3 种运行模式分别是内存模式、单机模式和集群模式。
DistSQL(Distributed SQL)是 Apache ShardingSphere 特有的操作语言。 它与标准 SQL 的使用方式完全一致,用于提供增量功能的 SQL 级别操作能力。
DistSQL 细分为 RDL、RQL 和 RAL 三种类型。
- RDL(Resource & Rule Definition Language)负责资源和规则的创建、修改和删除;
- RQL(Resource & Rule Query Language)负责资源和规则的查询和展现;
- RAL(Resource & Rule Administration Language)负责 Hint、事务类型切换、分片执行计划查询等管理功能。
DistSQL 只能用于 ShardingSphere-Proxy,ShardingSphere-JDBC 暂不提供。
1)表:
表是透明化数据分片的关键概念。 Apache ShardingSphere 通过提供多样化的表类型,适配不同场景下的数据分片需求。
逻辑表
相同结构的水平拆分数据库(表)的逻辑名称,是 SQL 中表的逻辑标识。 例:订单数据根据主键尾数拆分为 10 张表,分别是 t_order_0 到 t_order_9,他们的逻辑表名为 t_order
真实表
在水平拆分的数据库中真实存在的物理表。 即上个示例中的 t_order_0 到 t_order_9
绑定表
指分片规则一致的一组分片表。 使用绑定表进行多表关联查询时,必须使用分片键进行关联,否则会出现笛卡尔积关联或跨库关联,从而影响查询效率。
例如:
t_order 表和 t_order_item 表,均按照 order_id 分片,并且使用 order_id 进行关联,则此两张表互为绑定表关系。 绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。 举例说明,如果 SQL 为:
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
广播表
指所有的分片数据源中都存在的表,表结构及其数据在每个数据库中均完全一致。 适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
单表
指所有的分片数据源中仅唯一存在的表。 适用于数据量不大且无需分片的表。
2)数据节点
数据分片的最小单元,由数据源名称和真实表组成。
例:ds_0.t_order_0
逻辑表与真实表的映射关系,可分为均匀分布和自定义分布两种形式。
均匀分布:
db0.t_order0, db0.t_order1, db1.t_order0, db1.t_order1
自定义分布:
db0.t_order0, db0.t_order1, db1.t_order2, db1.t_order3, db1.t_order4
3)分片
用于将数据库(表)水平拆分的数据库字段。
分片算法: 用于将数据分片的算法,支持 =、>=、<=、>、<、BETWEEN 和 IN 进行分片。 分片算法可由开发者自行实现,也可使用 Apache ShardingSphere 内置的分片算法语法糖,灵活度非常高。
自动化分片算法
分片算法语法糖,用于便捷的托管所有数据节点,使用者无需关注真实表的物理分布。 包括取模、哈希、范围、时间等常用分片算法的实现。
(1)标准分片算法
用于处理使用单一键作为分片键的 =、IN、BETWEEN AND、>、<、>=、<= 进行分片的场景。
(2)复合分片算法
用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。
(3)Hint 分片算法
用于处理使用 Hint 行分片的场景。
分片策略
包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。 真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。
强制分片路由
对于分片字段并非由 SQL 而是其他外置条件决定的场景,可使用 SQL Hint 注入分片值。
例:按照员工登录主键分库,而数据库中并无此字段。 SQL Hint 支持通过 Java API 和 SQL 注释(待实现)两种方式使用。
4)行表达式
配置的简化与一体化是行表达式所希望解决的两个主要问题。
语法:只需要在配置中使用 ${ expression } 或 $->{ expression } 标识行表达式即可。 目前支持数据节点和分片算法这两个部分的配置。 行表达式的内容使用的是 Groovy 的语法,Groovy 能够支持的所有操作,行表达式均能够支持。 例如:
${begin..end} 表示范围区间
${[unit1, unit2, unit_x]} 表示枚举值
行表达式中如果出现连续多个 ${ expression } 或 $->{ expression } 表达式,整个表达式最终的结果将会根据每个子表达式的结果进行笛卡尔组合。
ex:
${['online', 'offline']}_table${1..3}
最终解析为:
online_table1, online_table2, online_table3, offline_table1, offline_table2, offline_table3
对于均匀分布的数据节点,如果数据结构如下:
用行表达式可以简化为:
db${0..1}.t_order${0..1} 或者 db$->{0..1}.t_order$->{0..1}
自定义的数据节点:
db0.t_order${0..1},db1.t_order${2..4} 或者 db0.t_order$->{0..1},db1.t_order$->{2..4}
对于有前缀的数据节点,也可以通过行表达式灵活配置:
db${0..1}.t_order_0${0..9}, db${0..1}.t_order_${10..20}
或者
db$->{0..1}.t_order_0$->{0..9}, db$->{0..1}.t_order_$->{10..20}
分片算法
对于只有一个分片键的使用 = 和 IN 进行分片的 SQL,可以使用行表达式代替编码方式配置。
例如:分为 10 个库,尾数为 0 的路由到后缀为 0 的数据源, 尾数为 1 的路由到后缀为 1 的数据源,以此类推。用于表示分片算法的行表达式为:
ds${id % 10}
或者
ds$->{id % 10}
5)分布式主键
(1)UUID
采用 UUID.randomUUID() 的方式产生分布式主键。
(2)NanoID
生成长度为 21 的字符串分布式主键。
(3)SNOWFLAKE
在分片规则配置模块可配置每个表的主键生成策略,默认使用雪花算法(snowflake)生成 64bit 的长整型数据。服务器时钟回拨会导致产生重复序列,因此默认分布式主键生成器提供了一个最大容忍的时钟回拨毫秒数。最大容忍的时钟回拨毫秒数的默认值为 0,可通过属性设置。
6)强制分片路由
通过解析 SQL 语句提取分片键列与值并进行分片是 Apache ShardingSphere 对 SQL 零侵入的实现方式。 若 SQL 语句中没有分片条件,则无法进行分片,需要全路由。在一些应用场景中,分片条件并不存在于 SQL,而存在于外部业务逻辑。 因此需要提供一种通过外部指定分片结果的方式,在 Apache ShardingSphere 中叫做 Hint。
实现机制:
使用 ThreadLocal 管理分片键值。 可以通过编程的方式向 HintManager 中添加分片条件,该分片条件仅在当前线程内生效。
除了通过编程的方式使用强制分片路由,Apache ShardingSphere 还可以通过 SQL 中的特殊注释的方式引用 Hint,使开发者可以采用更加透明的方式使用该功能。
7)sql支持:
兼容全部常用的路由至单数据节点的 SQL; 路由至多数据节点的 SQL 由于场景复杂,分为稳定支持、实验性支持和不支持这三种情况。
稳定支持
全面支持 DML、DDL、DCL、TCL 和常用 DAL。 支持分页、去重、排序、分组、聚合、表关联等复杂查询。 支持 PostgreSQL 和 openGauss 数据库 SCHEMA DDL 和 DML 语句。
不支持
以下 CASE WHEN 语句不支持:
CASE WHEN中包含子查询CASE WHEN中使用逻辑表名(请使用表别名)
8)分页
完全支持 MySQL、PostgreSQL 和 Oracle 的分页查询,SQLServer 由于分页查询较为复杂,仅部分支持。
针对性能瓶颈,采用流式处理 + 归并排序的方式来避免内存的过量占用。
查询偏移量过大的分页会导致数据库获取数据性能低下,以 MySQL 为例:
SELECT * FROM t_order ORDER BY id LIMIT 1000000, 10
而在分库分表的情况下(假设分为2个库),为了保证数据的正确性,SQL 会改写为:
SELECT * FROM t_order ORDER BY id LIMIT 0, 1000010
ShardingSphere 进行了 2 个方面的优化:
首先,采用流式处理 + 归并排序的方式来避免内存的过量占用。
其次,ShardingSphere 对仅落至单分片的查询进行进一步优化。
分页方案优化
SELECT * FROM t_order WHERE id > 100000 AND id <= 100010 ORDER BY id
2)通过记录上次查询结果的最后一条记录的 ID 进行下一页的查询:
SELECT * FROM t_order WHERE id > 100000 LIMIT 10
分页子查询
- Oracle
支持使用 rownum 进行分页:
SELECT * FROM (SELECT row_.*, rownum rownum_ FROM (SELECT o.order_id as order_id FROM t_order o JOIN t_order_item i ON o.order_id = i.order_id) row_ WHERE rownum <= ?) WHERE rownum > ?
注:目前不支持 rownum + BETWEEN 的分页方式。
- SQLServer
支持使用 TOP + ROW_NUMBER() OVER 配合进行分页:
SELECT * FROM (SELECT TOP (?) ROW_NUMBER() OVER (ORDER BY o.order_id DESC) AS rownum, * FROM t_order o) AS temp WHERE temp.rownum > ? ORDER BY temp.order_id
支持 SQLServer 2012 之后的 OFFSET FETCH 的分页方式:
SELECT * FROM t_order o ORDER BY id OFFSET ? ROW FETCH NEXT ? ROWS ONLY
- MySQL, PostgreSQL
MySQL 和 PostgreSQL 都支持 LIMIT 分页,无需子查询。
分布式事务:
事务四个特性 ACID(原子性、一致性、隔离性、持久性)。
XA 协议:
XA 协议最早的分布式事务模型是由 X/Open 国际联盟提出的 X/Open Distributed Transaction Processing (DTP) 模型,简称 XA 协议。
ShardingSphere 对外提供 begin/commit/rollback 传统事务接口,通过 LOCAL,XA,BASE 三种模式提供了分布式事务的能力。
1)LOCAL 事务
支持项
- 完全支持非跨库事务,例如:仅分表,或分库但是路由的结果在单库中;
- 完全支持因逻辑异常导致的跨库事务。例如:同一事务中,跨两个库更新。更新完毕后,抛出空指针,则两个库的内容都能够回滚。
不支持项
- 不支持因网络、硬件异常导致的跨库事务。例如:同一事务中,跨两个库更新,更新完毕后、未提交之前,第一个库宕机,则只有第二个库数据提交,且无法回滚。
原理:
LOCAL 模式基于 ShardingSphere 代理的数据库 begin/commit/rolllback 的接口实现, 对于一条逻辑 SQL,ShardingSphere 通过 begin 指令在每个被代理的数据库开启事务,并执行实际 SQL,并执行 commit/rollback。 由于每个数据节点各自管理自己的事务,它们之间没有协调以及通信的能力,也并不互相知晓其他数据节点事务的成功与否。 在性能方面无任何损耗,但在强一致性以及最终一致性方面不能够保证。
2)XA 事务
支持项
- 支持 Savepoint 嵌套事务;
- PostgreSQL/OpenGauss 事务块内,SQL 执行出现异常,执行
Commit,事务自动回滚; - 支持数据分片后的跨库事务;
- 两阶段提交保证操作的原子性和数据的强一致性;
- 服务宕机重启后,提交/回滚中的事务可自动恢复;
- 支持同时使用 XA 和非 XA 的连接池。
不支持项
- 服务宕机后,在其它机器上恢复提交/回滚中的数据;
- MySQL 事务块内,SQL 执行出现异常,执行
Commit,数据保持一致。
原理:
XA 事务采用的是 X/OPEN 组织所定义的 DTP 模型 所抽象的 AP(应用程序), TM(事务管理器)和 RM(资源管理器) 概念来保证分布式事务的强一致性。 其中 TM 与 RM 间采用 XA 的协议进行双向通信,通过两阶段提交实现。 与传统的本地事务相比,XA 事务增加了准备阶段,数据库除了被动接受提交指令外,还可以反向通知调用方事务是否可以被提交。 TM 可以收集所有分支事务的准备结果,并于最后进行原子提交,以保证事务的强一致性。
XA 事务建立在 ShardingSphere 代理的数据库 xa start/end/prepare/commit/rollback/recover 的接口上。
对于一条逻辑 SQL,ShardingSphere 通过 xa begin 指令在每个被代理的数据库开启事务,内部集成 TM,用于协调各分支事务,并执行 xa commit/rollback。
基于 XA 协议实现的分布式事务,由于在执行的过程中需要对所需资源进行锁定,它更加适用于执行时间确定的短事务。 对于长事务来说,整个事务进行期间对数据的独占,将会对并发场景下的性能产生一定的影响。
3)BASE 事务
支持项
- 支持数据分片后的跨库事务;
- 支持 RC 隔离级别;
- 通过 undo 快照进行事务回滚;
- 支持服务宕机后的,自动恢复提交中的事务。
不支持项
- 不支持除 RC 之外的隔离级别。
待优化项
- Apache ShardingSphere 和 SEATA 重复 SQL 解析。
原理:
如果将实现了 ACID 的事务要素的事务称为刚性事务的话,那么基于 BASE 事务要素的事务则称为柔性事务。 BASE 是基本可用、柔性状态和最终一致性这三个要素的缩写。
- 基本可用(Basically Available)保证分布式事务参与方不一定同时在线;
- 柔性状态(Soft state)则允许系统状态更新有一定的延时,这个延时对客户来说不一定能够察觉;
- 最终一致性(Eventually consistent)通常是通过消息传递的方式保证系统的最终一致性。
在 ACID 事务中对隔离性的要求很高,在事务执行过程中,必须将所有的资源锁定。 柔性事务的理念则是通过业务逻辑将互斥锁操作从资源层面上移至业务层面。 通过放宽对强一致性要求,来换取系统吞吐量的提升。
基于 ACID 的强一致性事务和基于 BASE 的最终一致性事务都不是银弹,只有在最适合的场景中才能发挥它们的最大长处。 Apache ShardingSphere 集成了 SEATA 作为柔性事务的使用方案。 可通过下表详细对比它们之间的区别,以帮助开发者进行技术选型。

1,读写分离
读写分离也就是将数据库拆分为主库和从库,即主库负责处理事务性的增删改操作,从库负责处理查询操作的数据库架构。
原理:
ShardingSphere 的读写分离主要依赖内核的相关功能。包括解析引擎和路由引擎。解析引擎将用户的 SQL 转化为 ShardingSphere 可以识别的 Statement 信息,路由引擎根据 SQL 的读写类型以及事务的状态来做 SQL 的路由。 在从库的路由中支持多种负载均衡算法,包括轮询算法、随机访问算法、权重访问算法等,用户也可以依据 SPI 机制自行扩展所需算法。
高可用
在存算分离的分布式数据库体系中,存储节点和计算节点的高可用方案是不同的。 对于有状态的存储节点来说,需要其自身具备数据一致性同步、探活、主节点选举等能力; 对于无状态的计算节点来说,需要感知存储节点的变化的同时,还需要独立架设负载均衡器,并具备服务发现和请求分发的能力。
尽可能的保证 7X24 小时不间断的数据库服务,是 Apache ShardingSphere 高可用模块的主要设计目标。
原理:
Apache ShardingSphere 提供的高可用方案,允许用户进行二次定制开发及实现扩展,主要分为四个步骤 : 前置检查、动态发现主库、动态发现从库、同步配置。

1)高可用类型
Apache ShardingSphere 不提供数据库高可用的能力,它通过第三方提供的高可用方案感知数据库主从关系的切换。 确切来说,Apache ShardingSphere 提供数据库发现的能力,自动感知数据库主从关系,并修正计算节点对数据库的连接。
2)动态读写分离
高可用和读写分离一起使用时,读写分离无需配置具体的主库和从库。 高可用的数据源会动态的修正读写分离的主从关系,并正确地疏导读写流量。
使用限制
支持项
- MySQL MGR 单主模式。
- MySQL 主从复制模式。
- openGauss 主从复制模式。
不支持项
- MySQL MGR 多主模式。
弹性伸缩
1)既能支持自定义的分片算法,又能高效地将数据节点进行扩缩容的方式,是弹性伸缩面临的第一个挑战;
2)在伸缩过程中,不应该对正在运行的业务造成影响。 尽可能减少伸缩时数据不可用的时间窗口,甚至做到用户完全无感知
3)弹性伸缩不应该对现有的数据造成影响,如何保证数据的正确性
ShardingSphere-Scaling 是一个提供给用户的通用数据接入迁移及弹性伸缩的解决方案。
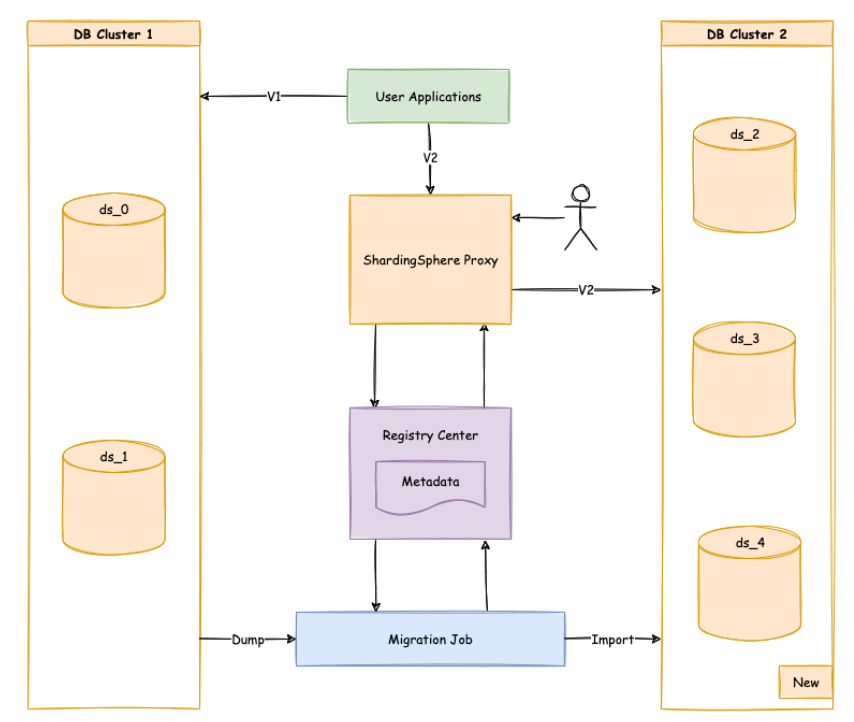
支持项
- 将外围数据迁移至 Apache ShardingSphere 所管理的数据库;
- 将 Apache ShardingSphere 的数据节点进行扩容或缩容。
不支持项
- 无主键表扩缩容;
- 复合主键表扩缩容;
- 不支持在当前存储节点之上做迁移,需要准备一个全新的数据库集群作为迁移目标库。
数据加密
原理:
Apache ShardingSphere 通过对用户输入的 SQL 进行解析,并依据用户提供的加密规则对 SQL 进行改写,从而实现对原文数据进行加密,并将原文数据(可选)及密文数据同时存储到底层数据库。 在用户查询数据时,它仅从数据库中取出密文数据,并对其解密,最终将解密后的原始数据返回给用户。 Apache ShardingSphere 自动化 & 透明化了数据加密过程,让用户无需关注数据加密的实现细节,像使用普通数据那样使用加密数据。 此外,无论是已在线业务进行加密改造,还是新上线业务使用加密功能,Apache ShardingSphere 都可以提供一套相对完善的解决方案。

加密规则
加密配置主要分为四部分:数据源配置,加密算法配置,加密表配置以及查询属性配置

数据源配置:指数据源配置。
加密器配置:指使用什么加密算法进行加解密。目前 ShardingSphere 内置了三种加解密算法:AES,MD5 和 RC4。用户还可以通过实现 ShardingSphere 提供的接口,自行实现一套加解密算法。
加密表配置:用于告诉 ShardingSphere 数据表里哪个列用于存储密文数据(cipherColumn)、哪个列用于存储明文数据(plainColumn)以及用户想使用哪个列进行 SQL 编写(logicColumn)。
查询属性的配置:当底层数据库表里同时存储了明文数据、密文数据后,该属性开关用于决定是直接查询数据库表里的明文数据进行返回,还是查询密文数据通过 Apache ShardingSphere 解密后返回。该属性开关支持表级别和整个规则级别配置,表级别优先级最高。
影子库
Apache ShardingSphere 全链路在线压测场景下,在数据库层面对于压测数据治理的解决方案。
影子算法。
-
基于列的影子算法 通过识别 SQL 中的数据,匹配路由至影子库的场景。 适用于由压测数据名单驱动的压测场景。
-
基于 Hint 的影子算法 通过识别 SQL 中的注释,匹配路由至影子库的场景。 适用于由上游系统透传标识驱动的压测场景。
使用限制
基于 Hint 的影子算法
- 无。
基于列的影子算法
-
不支持 DDL;
-
不支持范围、分组和子查询,如:BETWEEN、GROUP BY … HAVING 等。SQL 支持列表:INSERT
原理:
Apache ShardingSphere 通过解析 SQL,对传入的 SQL 进行影子判定,根据配置文件中用户设置的影子规则,路由到生产库或者影子库。

可观察性
通过对可系统观察性数据的遥测是分布式系统推荐的运维方式。
Agent
基于字节码增强和插件化设计,以提供 Tracing 和 Metrics 埋点,以及日志输出功能。 需要开启 Agent 的插件功能后,才能将监控指标数据输出至第三方 APM 中展示。
APM
APM 是应用性能监控的缩写。 着眼于分布式系统的性能诊断,其主要功能包括调用链展示,应用拓扑分析等。
Tracing
链路跟踪,通过探针收集调用链数据,并发送到第三方 APM 系统。
Metrics
系统统计指标,通过探针收集,并且写入到时序数据库,供第三方应用展示。
Logging
日志,通过 Agent 能够方便的扩展日志内容,为分析系统运行状态提供更多信息。
原理:
ShardingSphere-Agent 模块为 ShardingSphere 提供了可观察性的框架,它是基于 Java Agent 技术实现的。 Metrics、Tracing 和 Logging 等功能均通过插件的方式集成在 Agent 中

DISTSQL
Apache ShardingSphere 特有的操作语言。 它与标准 SQL 的使用方式完全一致,用于提供增量功能的 SQL 级别操作能力。DistSQL 只能用于 ShardingSphere-Proxy,ShardingSphere-JDBC 暂不提供。
参考资料:
https://shardingsphere.apache.org/document/current/en/overview/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号