2022年Redis最新面试题第2篇 - Redis数据结构
最近整理一份关于Redis常见面试题的,也会根据自己的经验, 标注一些出现的概率,最高5颗★出现的概率最高。比如这样:
Redis 最适合的场景, 可以简单的说说吗?
出现概率: ★★★★
目录
-
一、Redis基础知识
- 1、什么是 Redis, 有哪些优缺点?
- 2、Redis 最适合的场景, 可以简单的说说吗?
- 3、Redis 相比 Memcached 有哪些优势?
- 4、一个字符串类型的值能存储最大容量是多少?
- 5、Redis 读写分离
-
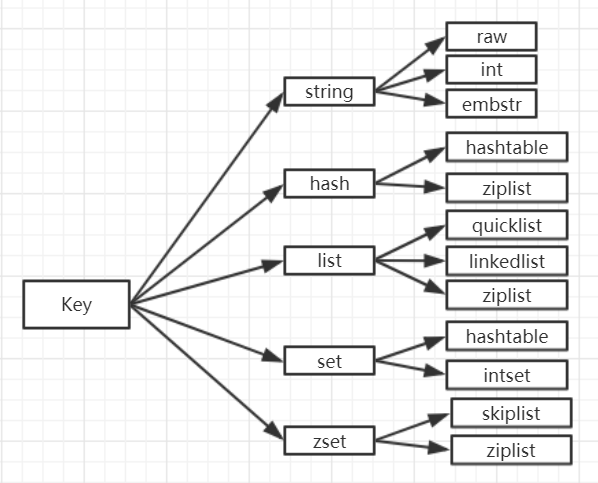
二、数据结构
- 1、Redis的数据类型有哪些?
- 2、说说 Redis 哈希槽的概念?
- 3、Hash如何实现O(1)的查询和设置速度, 以及扩容原理
- 4、布隆过滤器
-
三、事务
- 1、怎么理解 Redis 事务?
- 2、Redis事务执行过程
- 3、Redis事务的一些使用场景
- 4、Redis事务与Redis pipeline的区别
- 5、集群模式下Redis事务如何保证原子性
-
四、Redis数据持久化
- 1、为什么 Redis 需要把所有数据放到内存中?
- 2、Redis如何做持久化的?
- 3、Redis key 的过期时间和永久有效分别怎么设置?
-
五、Redis集群
- 1、Redis 是单进程单线程的?
- 2、是否使用过 Redis 集群,集群的原理是什么?
- 3、可以简单说说你对Redis Sentinel的理解
- 4、Redis Sentinal和Redis Cluster的区别
- 5、Redis 的同步机制了解么?
- 6、Redis 集群最大节点个数是多少?
-
六、Redis淘汰策略
- 1、Redis过期键的删除策略?
- 2、你可以简单聊聊Redis内存淘汰机制(回收策略)
-
七、Redis分布式锁
- 1、你知道实现实现分布式锁有哪些方案?
-
八、Redis缓存问题
- 1、Redis缓存雪崩
- 2、Redis缓存击穿
- 3、Redis缓存穿透
- 4、缓存预热
- 5、缓存降级
-
九、运维和部署
- 1、Redis 如何设置密码及验证密码?
- 2、Redis 如何做内存优化?
一般来讲在面试当中, 关于Redis相关的面试题频率出现比较高的几个关键词是适合哪些场景、数据结构、hash实现原理和如何扩容、如何做持久化、关系型数据库和非关系数据库对比等等。 把这几个点问完基本也差不多10~20分钟了(一般一轮面试1小时左右), 基本这些可以让面试官对你的Redis知识有一定的了解了。
也欢迎关注我的公众号: 漫步coding。 一起交流, 在coding的世界里漫步, 回复: redis, 免费获取最新Redis面试题(含答案)。

希望这篇文章可以帮助大家, 也希望大家都能找到的好工作。
也可以在线看我的博客, 界面如下:

数据结构
- Redis的数据类型有哪些?
- 说说 Redis 哈希槽的概念?
- Hash如何实现O(1)的查询和设置速度, 以及扩容原理
- 布隆过滤器
Redis的数据类型有哪些?
出现概率: ★★★★★
这个在面试的过程出现的概率特别高了。
Redis 支持五种常用的数据类型:string( 字符串),hash( 哈希), list( 列表), set( 集合) 及 zsetsorted set:有序集合)。

redis 的基本数据结构对应的底层实现如下图所示:
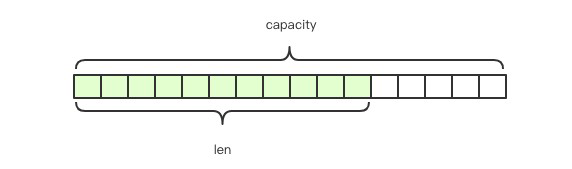
1)、Redis 的字符串是动态字符串,是可以修改的字符串,内部结构实现上类似于 Java 的 ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配,如图所示:
len 是当前字符串实际长度,capacity 是为字符串分配的可用空间,当字符串长度小于 1M 时,扩容都是加倍现有的空间,如果超过 1M,扩容时一次只会多扩 1M 的空间。字符串最大长度为 512M。
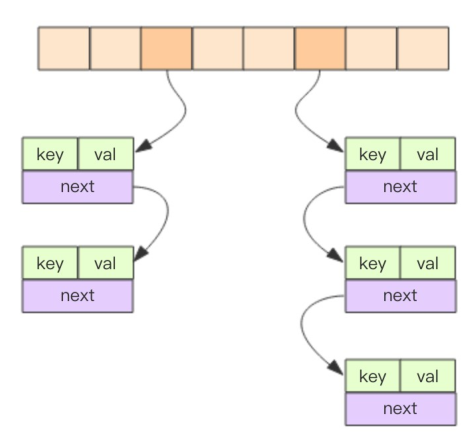
2)、hash
Redis Hash通过分桶的方式解决 hash 冲突。它是无序字典。内部实现结构是同样的数组 + 链表二维结构。第一维 hash 的数组位置碰撞时,就会将碰撞的元素使用链表串接起来。第一维是数组,第二维是链表。数组中存储的是第二维链表的第一个元素的指针。
3)、list
Redis 的列表相当于 Java 语言中的 LinkedList,注意它是链表而不是数组。这意味着 list 的插入和删除操作非常快,时间复杂度为 O(1),但是索引定位很慢,时间复杂度为 O(n)。
list的特点是:
- 有序
- 可以重复
- 右边进左边出或者左边进右边出,则列表可以充当队列
- 左边进左边出或者右边进右边出,则列表可以充当栈

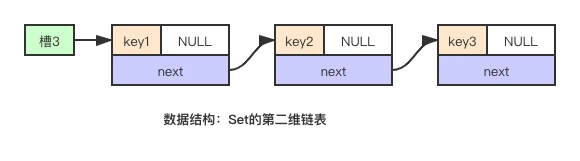
4)、set
set和字典非常类似,其内部实现就是上述的hashTable的特殊实现,与字典不同的地方有两点:
- 只关注key值,所有的value都是NULL。
- 在新增数据时会进行去重。
5)、zsetsorted set
zset是Redis非常有特色的数据结构,它是基于Set并提供排序的有序集合。其中最为重要的特点就是支持通过score的权重来指定权重。一些排行榜、延迟任务比如指定1小时后执行, 就是使用这个数据结构实现的。

6)、拓展篇
如果你说你还知道一些其他的几种数据结构比如: HyperLogLog、Geo、Pub/Sub、Redis Module,BloomFilter,RedisSearch,Redis-ML,面试官得眼睛就开始发亮了。
Redis5.0带来了Stream类型。从字面上看是流类型,但其实从功能上看,应该是Redis对消息队列(MQ,Message Queue)的完善实现。用过Redis做消息队列的都了解,基于Reids的消息队列实现有很多种,例如:
- PUB/SUB,订阅/发布模式
- 基于List的 LPUSH+BRPOP 的实现
- 基于Sorted-Set的实现
Redis Stream的结构如图所示,它有一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的ID和对应的内容。消息是持久化的,Redis重启后,内容还在。

Hash如何实现O(1)的查询和设置速度, 以及扩容原理
出现概率: ★★★★★
Redis Hash通过分桶的方式解决 hash 冲突。它是无序字典。内部实现结构是同样的数组 + 链表二维结构。第一维 hash 的数组位置碰撞时,就会将碰撞的元素使用链表串接起来。第一维是数组,第二维是链表。数组中存储的是第二维链表的第一个元素的指针。
因为是通过数组取模的方式, 可以实现O(1)的查询和设置速度。
不过如果概率多时, 链表长度过长时,查询时间复杂度会降低到O(n)。这个需要进行扩容了。
大字典的扩容是非常耗时间的,需要重新申请新的数组,正常情况下,当 hash 表中元素的个数等于第一维数组的长度时,就会开始扩容,扩容的新数组是原数组大小的 2 倍,然后将旧字典所有链表中的元素重新挂接到新的数组下面,这是一个 O(n)级别的操作,Redis 使用渐进式 rehash 扩容,分多次来慢慢的将旧数组中的键值对rehash到新数组的操作就称之为渐进式rehash。渐进式rehash可以避免了集中式rehash带来的庞大计算量,在渐进式rehash过程中,因为还可能会有新的键值对存进来,此时Redis的做法是新添加的键值对统一放入ht[1]中,这样就确保了ht[0]键值对的数量只会减少,当执行rehash操作时需要执行查询操作,此时会先查询ht[0],查找不到结果再到ht[1]中查询。
说说 Redis 哈希槽的概念?
出现概率: ★★★
Redis集群没有使用一致性hash,而是引入了哈希槽的概念,Redis集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽,集群的每个节点负责一部分hash槽。
布隆过滤器
出现概率: ★★★
这个在面试中出现的概率, 主要看面试官的偏好, 不过如果问到,而且你能回答比较好的, 估计是一个比较好的加分项。
布隆过滤器是 Redis 的高级功能,虽然这种结构的去重率并不完全精确,但和其他结构一样都有特定的应用场景,比如当处理海量数据时,就可以使用布隆过滤器实现去重。
一些场景: 百度爬虫系统每天会面临海量的 URL 数据,我们希望它每次只爬取最新的页面,而对于没有更新过的页面则不爬取,因策爬虫系统必须对已经抓取过的 URL 去重,否则会严重影响执行效率。但是如果使用一个 set(集合)去装载这些 URL 地址,那么将造成资源空间的严重浪费。
布隆过滤器(Bloom Filter)是一个高空间利用率的概率性数据结构,由二进制向量(即位数组)和一系列随机映射函数(即哈希函数)两部分组成。
布隆过滤器使用exists()来判断某个元素是否存在于自身结构中。当布隆过滤器判定某个值存在时,其实这个值只是有可能存在;当它说某个值不存在时,那这个值肯定不存在,这个误判概率大约在 1% 左右。
Bloom Filter的原理
1)、工作流程-添加元素
布隆过滤器主要由位数组和一系列 hash 函数构成,其中位数组的初始状态都为 0。
下面对布隆过滤器工作流程做简单描述,如下图所示:
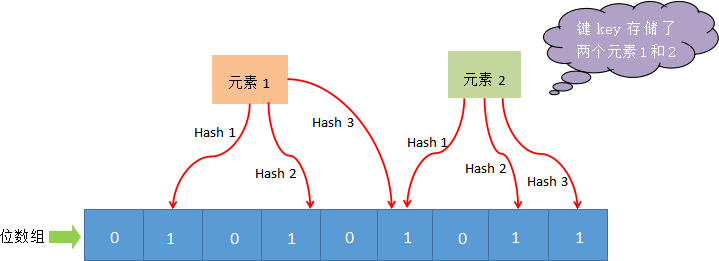
2)、工作流程-判定元素是否存在
当我们需要判断一个元素是否存时,其流程如下:首先对给定元素再次执行哈希计算,得到与添加元素时相同的位数组位置,判断所得位置是否都为 1,如果其中有一个为 0,那么说明元素不存在,若都为 1,则说明元素有可能存在。
3)、 为什么是可能“存在”
您可能会问,为什么是有可能存在?其实原因很简单,那些被置为 1 的位置也可能是由于其他元素的操作而改变的。比如,元素1 和 元素2,这两个元素同时将一个位置变为了 1(图1所示)。在这种情况下,我们就不能判定“元素 1”一定存在,这是布隆过滤器存在误判的根本原因。
Bloom Filter的缺点
bloom filter牺牲了判断的准确率、删除的便利性 ,才做到在时间和空间上的效率比较高,是因为
1)、存在误判,可能要查到的元素并没有在容器中,但是hash之后得到的k个位置上值都是1。如果bloom filter中存储的是黑名单,那么可以通过建立一个白名单来存储可能会误判的元素。
2)、删除数据。一个放入容器的元素映射到bit数组的k个位置上是1,删除的时候不能简单的直接置为0,可能会影响其他元素的判断。可以考虑Counting Bloom Filter

 浙公网安备 33010602011771号
浙公网安备 33010602011771号