Hadoop复习第五章MapReduce
1.会编程,参考实验
1.1编程实现词频统计基本操作
主函数
public static void main(String[] args) throws Exception{ Configuration conf = new Configuration(); //程序运行时参数 String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: wordcount <in> <out>"); System.exit(2); } Job job = new Job(conf,“word count”); //创建一个job和任务入口 job.setJarByClass(WordCount.class); // job.setInputFormatClass(TextInputFormat.class); //第一步:读取输入文件解析成key,value对 FileInputFormat.addInputPath(job,new Path(otherArgs[0])); //设置输入文件 job.setMapperClass(WordCountMapper.class); //第二步:添加WordCountMapper类 //第三步,第四步,第五步,第六步,省略 job.setReducerClass(WordCountReducer.class); //第七步:添加WordCountReducer类 job.setOutputKeyClass(Text.class); //设置输出类型 job.setOutputValueClass(LongWritable.class); //设置输出类型 FileOutputFormat.setOutputPath(job,new Path(otherArgs[1])); //设置输出文件 System.exit(job.waitForCompletion(true)?0:1); //提交执行 }
Mapper
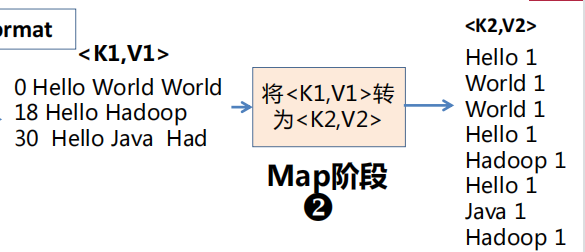
K1:LongWritable V1:Text
K2:Text V2:IntWritable
public static class WordCountMapper extends Mapper<LongWritable,Text,Text,LongWritable> { @Override public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); //获取value中的值 String[] split = line.split(","); //分词 for (String word : split) { context.write(new Text(word),new LongWritable(1)); //输出 } }
Reducer
public static class WordCountReducer extends Reducer<Text,LongWritable,Text,LongWritable> { /** * 自定义我们的reduce逻辑 * 所有的key都是我们的单词,所有的values都是我们单词出现的次数 *
@param key ,@param values ,@param context */ @Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { long count = 0; for (LongWritable value : values) { count += value.get(); //统计}
context.write(key,new LongWritable(count));
} }
2.MapReduce 核心思想、作用、工作流程(理解)
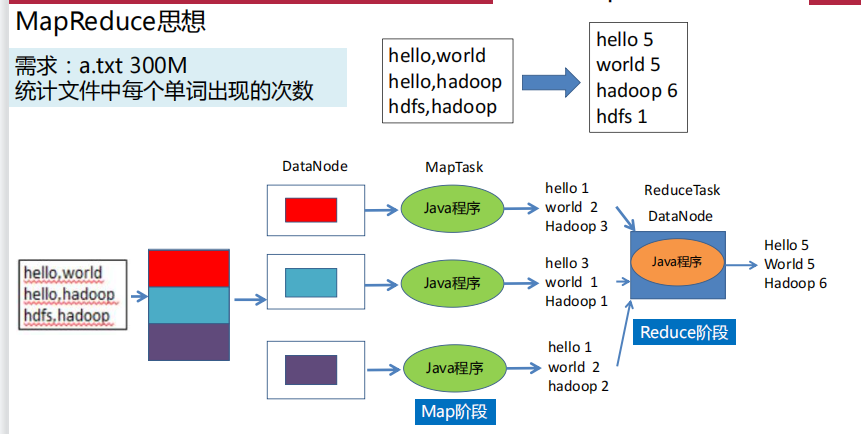
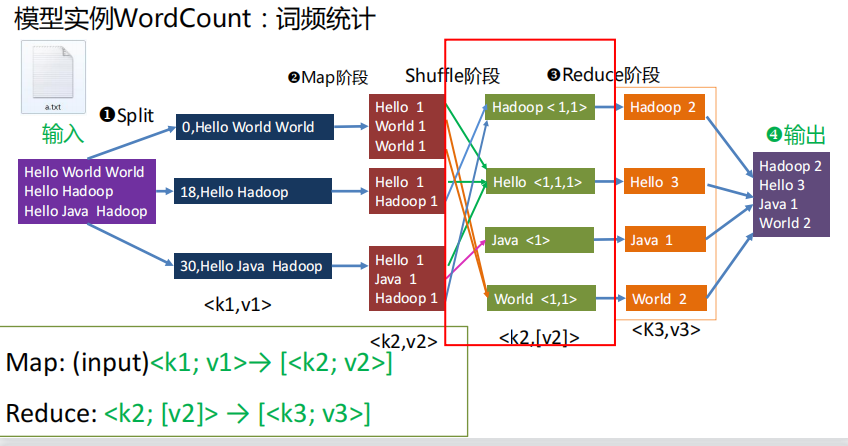
3.MapReduce 的 Shuffle 过程(包含哪些,哪些是必须的等,这些阶段有
什么作用)

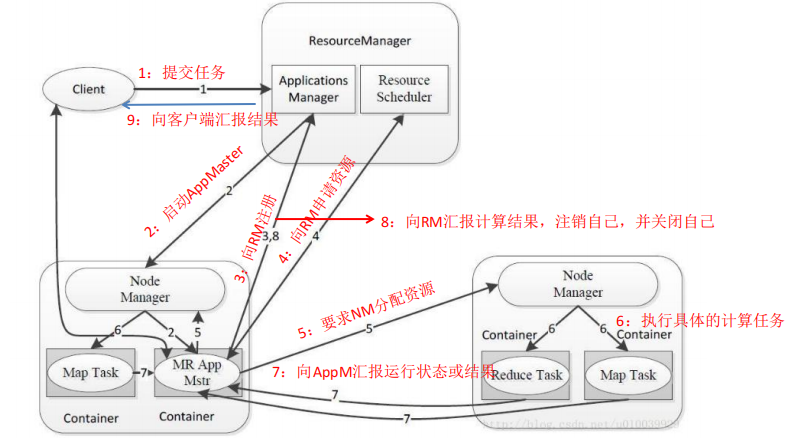
4.MapReduce 体系结构主要包含哪四个部分,这四个部分的主要作用


 浙公网安备 33010602011771号
浙公网安备 33010602011771号