
04 Hadoop思想与原理
1.用图与自己的话,简要描述Hadoop起源与发展阶段。
从与谷歌系统的关系,关键时间节点,1.x,2.x与3.x的区别,不同公司发行版本等方面来讲。
Hadoop之父:

1. Hadoop是一个对海量数据存储和海量数据分析计算的分布式系统。它最早起源于lucene下的Nutch。
2. 03、04年谷歌发表的三篇论文:
分布式文件系统(GFS)——处理海量网页的存储分布式计算框架
MAPREDUCE——处理海量网页的索引计算问题。
分布式的结构化数据存储系统Bigtable——处理海量结构化数据。
3. 基于论文 Hadoop被剥离,08年1月,Hadoop成为Apache顶级项目(同年,cloudera公司成立),迎来了它的快速发展期。
Hadoop的历史版本介绍
0.x系列版本:Hadoop当中最早的一个开源版本,是发展基础 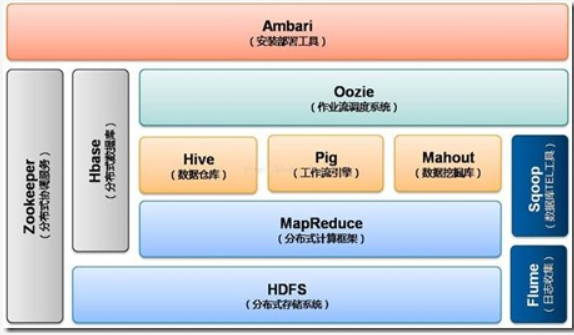
1.x版本系列:二代开源版本,主要修复0.x版本的一些bug等 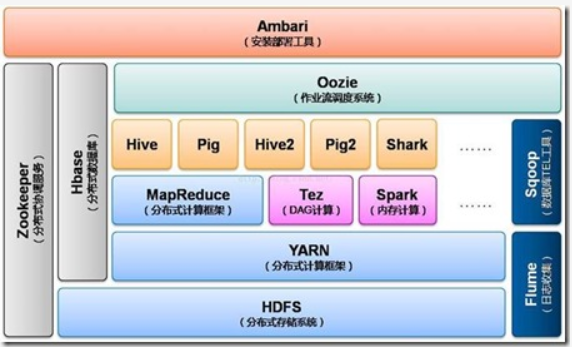
2.x版本系列:架构产生重大变化,引入了yarn平台等许多新特性 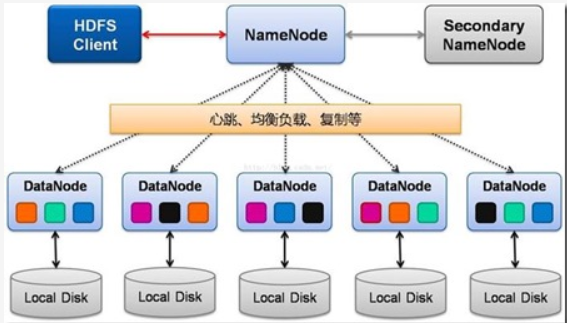
发行版本对比:
DKhadoop发行版:有效的集成了整个HADOOP生态系统的全部组件,并深度优化,重新编译为一个完整的更高性能的大数据通用计算平台,实现了各部件的有机协调。因此DKH相比开源的大数据平台,在计算性能上有了高达5倍(最大)的性能提升。DKhadoop将复杂的大数据集群配置简化至三种节点(主节点、管理节点、计算节点),极大的简化了集群的管理运维,增强了集群的高可用性、高可维护性、高稳定性。
cloudera发行版:CDH是Cloudera的hadoop发行版,完全开源,比Apache hadoop在兼容性,安全性,稳定性上有增强
hortonworks发行版:Hortonworks 的主打产品是Hortonworks Data Platform (HDP),也同样是100%开源的产品,其版本特点:HDP包括稳定版本的Apache Hadoop的所有关键组件;安装方便,HDP包括一个现代化的,直观的用户界面的安装和配置工具。
MAPR发行版:mapR有免费和商业两个版本,免费版本在功能上有所减少。
华为hadoop发行版:华为的hadoop版本基于自研的Hadoop HA平台,构建NameNode、JobTracker、HiveServer的HA功能,进程故障后系统自动Failover,无需人工干预,这个也是对hadoop的小修补,远不如mapR解决的彻底。
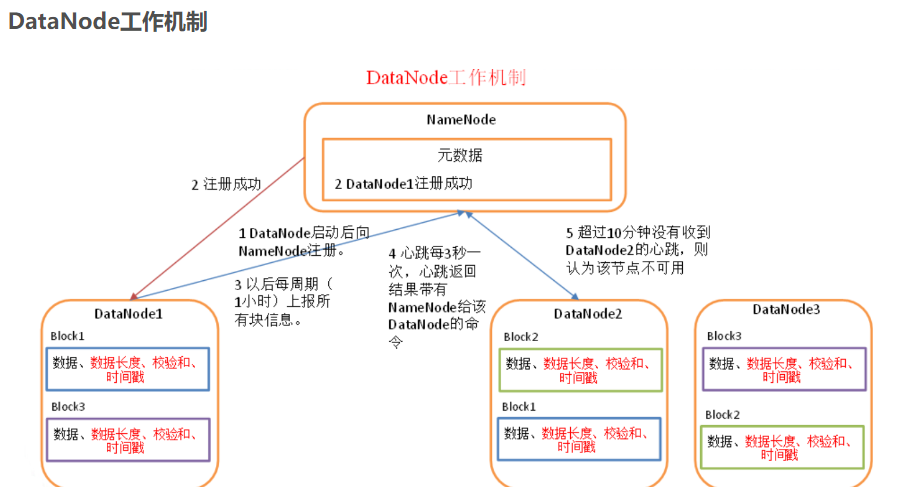
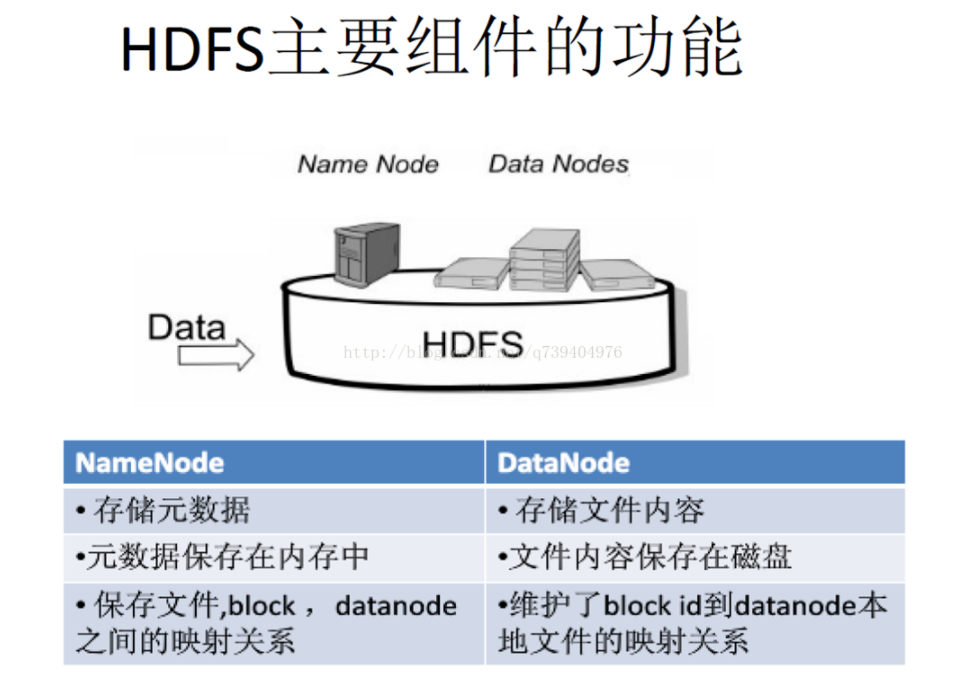
2.用图与自己的话,简要描述名称节点、数据节点的主要功能及相互关系、名称节点的工作机制。
名称节点(NameNode ):是HDFS主从结构中主节点上运行的主要进程,它指导主从结构中的从节点。
数据节点(DataNode):执行底层的I/O任务。
两者的关系:名称节点是 HDFS集群中的单一故障点,通过第二名称节点的检查点,可以减少停机的时间并减低名称节点元数据丢失的风险。没有名称节点,文件系统将无法使用。如果运行名称节点的机器被毁坏了,文件系统上所有的文件都会丢失,就无法知道如何通过数据节点上的块来重建文件。
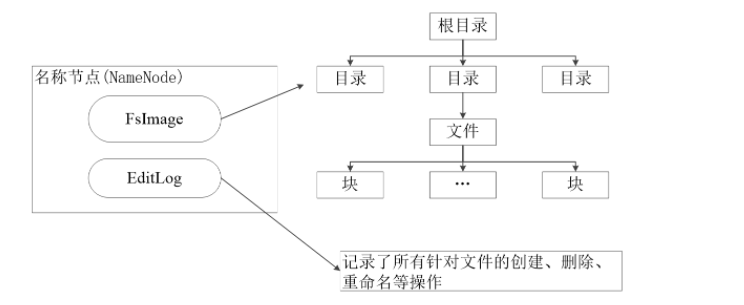
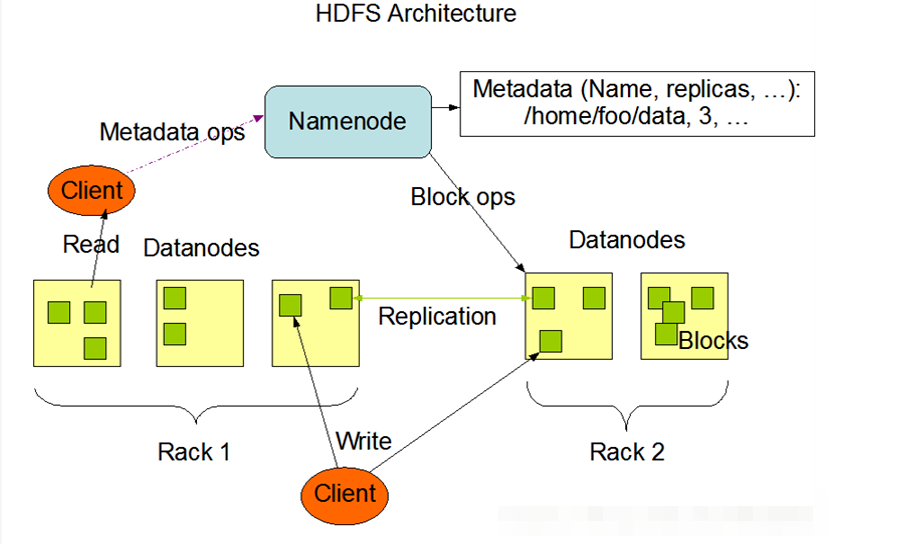
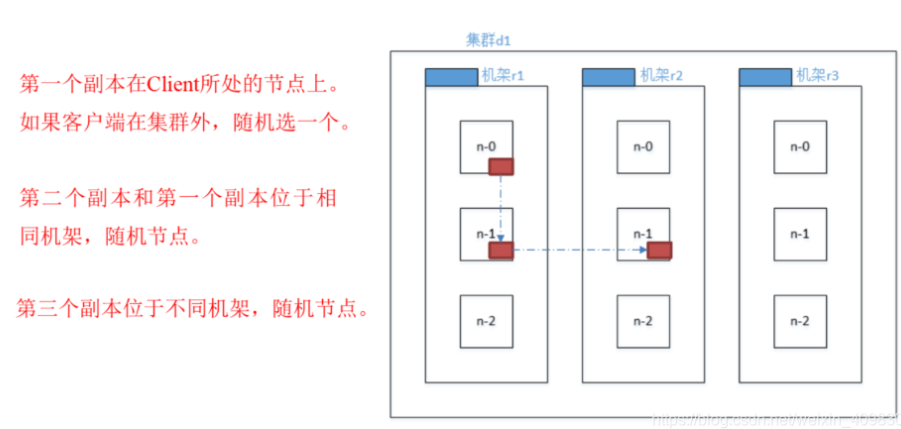
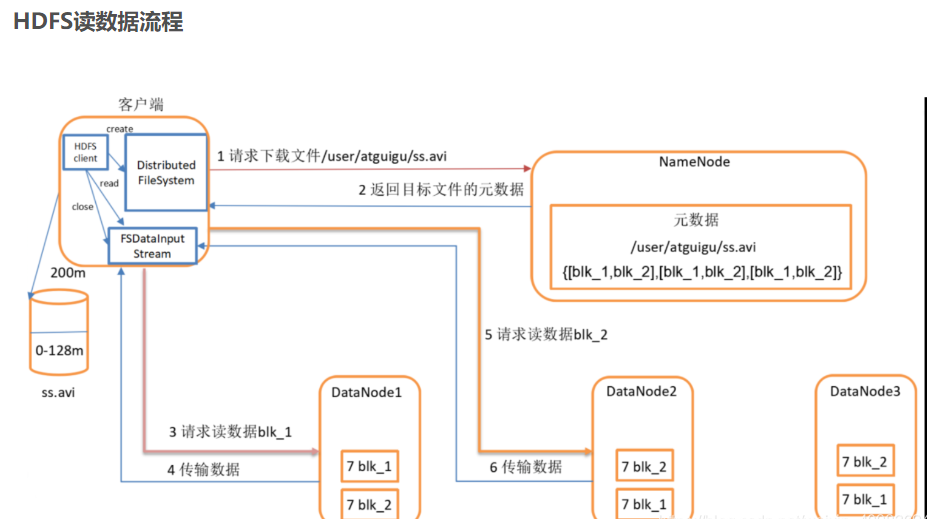
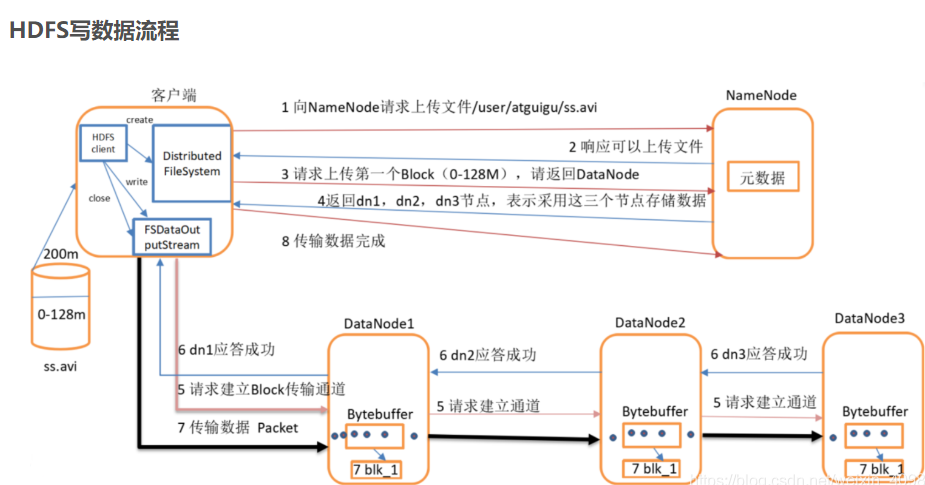
3.分别从以下这些方面,梳理清楚HDFS的 结构与运行流程,以图的形式描述。
- 客户端与HDFS
- 客户端读
- 客户端写
- 数据结点与集群
- 数据结点与名称结点
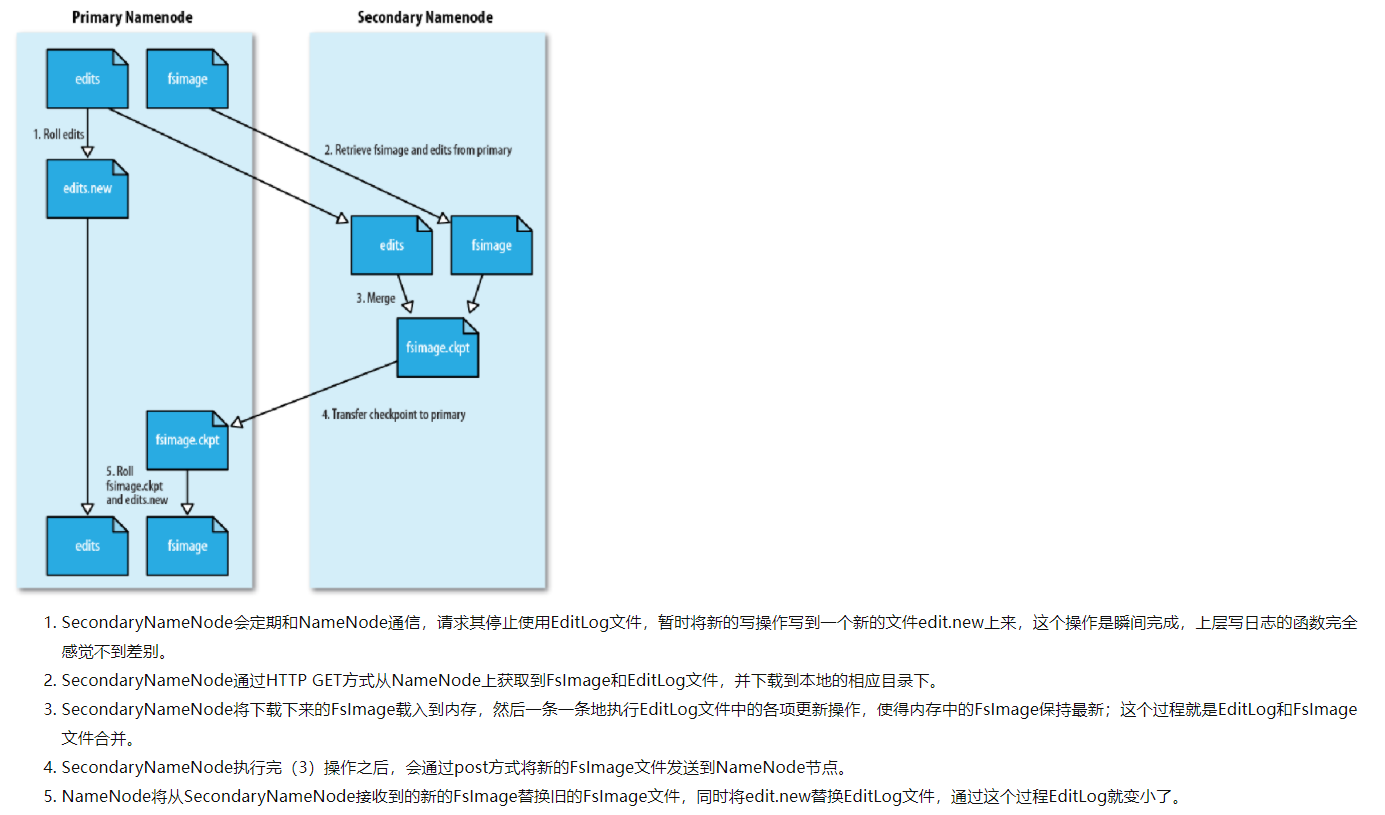
- 名称结点与第二名称结点
- 数据结点与数据结点
- 数据冗余
- 数据存取策略
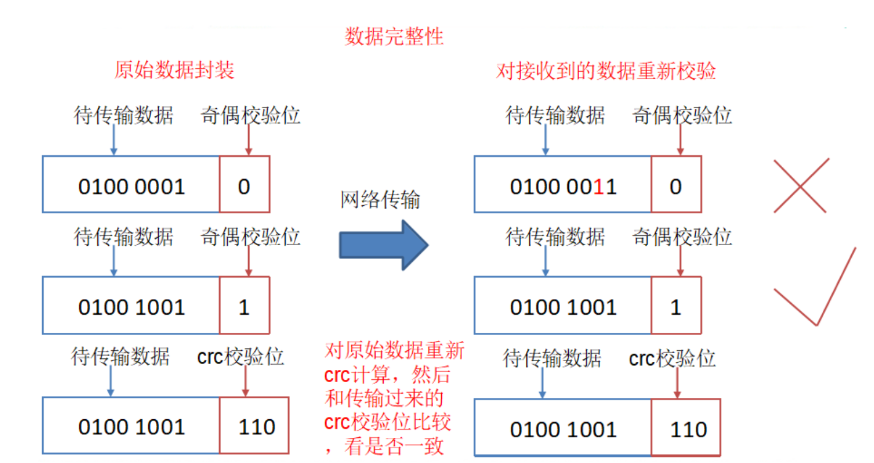
- 数据错误与恢复
4.简述HBase与传统数据库的主要区别
1.数据类型:Hbase只有简单的字符类型,所有的类型都是交由用户自己处理,它只保存字符串。而传统数据库有丰富的类型和存储方式。
2.数据操作:HBase只有很简单的插入、查询、删除、清空等操作,表和表之间是分离的,没有复杂的表和表之间的关系,而传统数据库通常有各式各样的函数和连接操作。
3.存储模式:HBase是基于列存储的,每个列族都由几个文件保存,不同的列族的文件时分离的。而传统的关系型数据库是基于表格结构和行模式保存的
4.数据维护:HBase的更新操作不应该叫更新,它实际上是插入了新的数据,而传统数据库是替换修改
5.可伸缩性:Hbase这类分布式数据库就是为了这个目的而开发出来的,所以它能够轻松增加或减少硬件的数量,并且对错误的兼容性比较高。而传统数据库通常需要增加中间层才能实现类似的功能
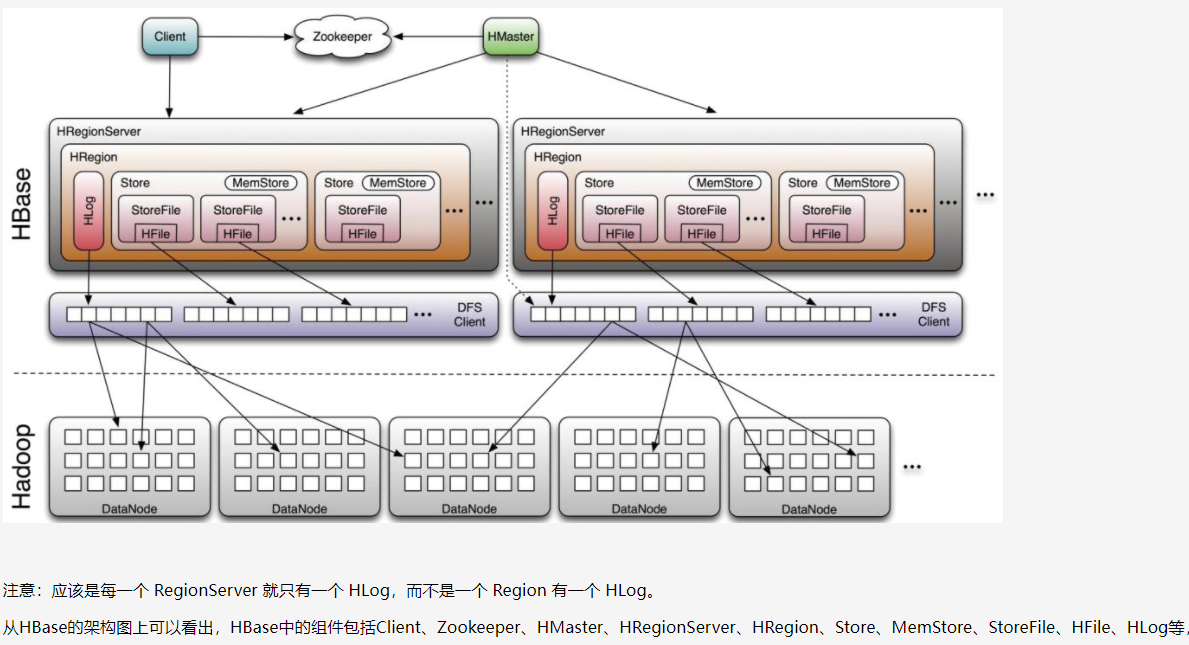
5.梳理HBase的结构与运行流程,以用图与自己的话进行简要描述,图中包括以下内容:
- Master主服务器的功能:
1、为 RegionServer 分配 Region
2、负责 RegionServer 的负载均衡
3、发现失效的 RegionServer 并重新分配其上的 Region
4、HDFS 上的垃圾文件(HBase)回收
5、处理 Schema 更新请求(表的创建,删除,修改,列簇的增加等等)
- Region服务器的功能
table在行的方向上分隔为多个Region。Region是HBase中分布式存储和负载均衡的最小单元,即不同的region可以分别在不同的Region Server上,但同一个Region是不会拆分到多个server上。Region按大小分隔,每个表一般是只有一个region。随着数据不断插入表,region不 断增大,当region的某个列族达到一个阈值时就会分成两个新的region。每个region由以下信息标识:< 表名,startRowkey,创建时间>由目录表(-ROOT-和.META.)记录该region的endRowkey
- Zookeeper协同的功能:
1、ZooKeeper 为 HBase 提供 Failover 机制,选举 Master,避免单点 Master 单点故障问题
2、存储所有 Region 的寻址入口:-ROOT-表在哪台服务器上。-ROOT-这张表的位置信息
3、实时监控 RegionServer 的状态,将 RegionServer 的上线和下线信息实时通知给 Master
4、存储 HBase 的 Schema,包括有哪些 Table,每个 Table 有哪些 Column Family
- Client客户端的请求流程
- 四者之间的相系关系
- 与HDFS的关联

 浙公网安备 33010602011771号
浙公网安备 33010602011771号