java Conllection接口及其实现类
Java集合大致可分为Set、List和Map三种体系,其中Set代表无序、不可重复的集合;List代表有序、重复的集合;
而Map则代表具有映射关系的集合。Java 5之后,增加了Queue体系集合,代表一种队列集合实现。Java集合框架主要由Collection和Map两个根接口及其子接口、实现类组成。
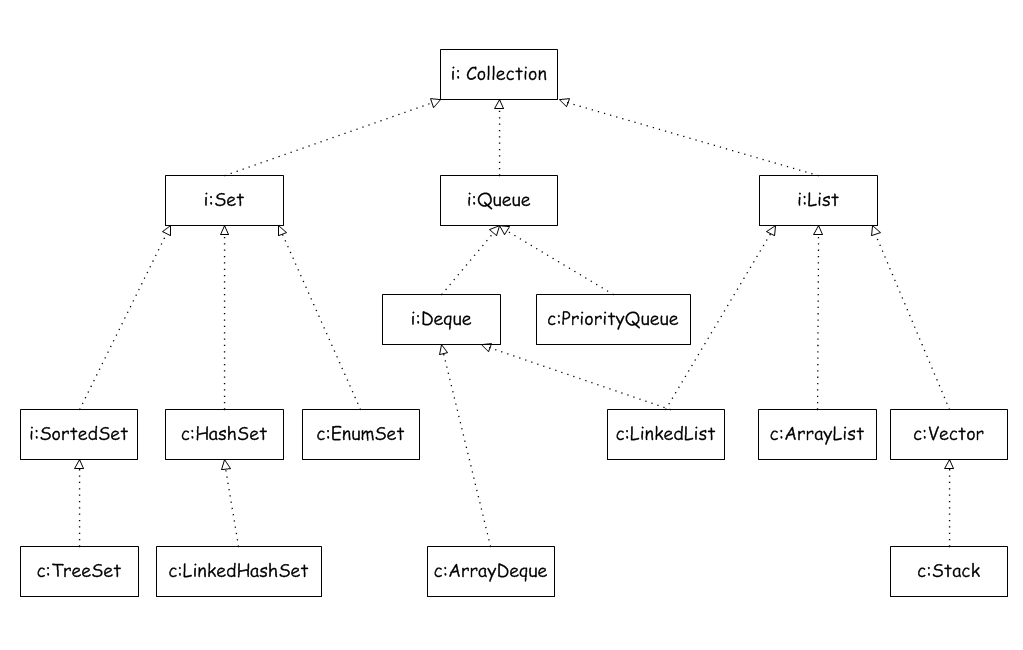
Collection接口接口是Set、List和Queue接口的父接口,方法有- add(Object o):添加元素
- addAll(Collection c):添加c集合中所有元素
- clear():删除Collection对象中的所有元素
- contains(Object o):是否包含o元素,底层调用为equals()方法
- containsAll(Collection c):是否包含集合c中的所有元素
- iterator():返回Iterator对象,用于遍历集合中的元素
- remove(Object o):移除元素
- removeAll(Collection c):从集合中移出它和C对象相同的元素。而对于A中含有而B中不含有的对象,不移除。
- retainAll(Collection c):相当于求与c的交集
- size():返回元素个数
- toArray():把集合转换为一个数组
-
hashCode():返回字符串的哈希码。
Collection接口中并未重写toString(),toString的重写是在它的实现类AbstractCollection中实现的。
Set子接口
Set接口是Collection接口的子类,其继承了所有方法,HashSet集合则实现了Set接口,其内部存储数据时依靠哈希表,一个类似数组和链表的结合体。设置空集合时,存在默认的容量和加载因子,再用HashSet对象调用add方法时,其实是先比较其Hash值,若是没有的话,则直接添加到集合中,若有的话,则再equals下比较其内容(因为有可能内容不一样,但是其Hash值一样),若是内容不一样,则在这个地址下添加(链式),若是一样的话,则丢掉。注意就保证了其的唯一性。(以后定义变量时,都需要重写其hashcode和equals方法)至于LinkedHashSet则在HashSet基础上保证了其的有序性(取出和存入顺序一样)。
HashSet:
由HashSet的源码可知,HashSet底层就是一个HashMap。我们在往HashSet中存储数据的时候,HashSet添加的元素是存放在HashMap的key位置上,而value取了默认常量PRESENT,是一个空对象。
HashSet底层的数据结构是一个哈希表,存在HashSet中的元素应该重写其hashCode()方法,故存在HashMap中的key,应该 重写其hashCode()方法。HashSet集合不能保证迭代顺序与元素的存储顺序相同。
扩容机制:默认初始容量为16。加载因子为0.75:即当 元素个数 超过 容量长度的0.75倍 时,进行扩容。扩容增量:原容量的 1 倍
LinkedHashSet类
LinkedHashSet具有set集合不重复的特点,同时具有可预测的迭代顺序,也就是我们插入的顺序。因为是HashSet的子类,所以也是保证元素唯一的,与HashSet的原理一样。
此实现与 HashSet 的不同之处在于,LinkedHashSet 维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序可为插入顺序或是访问顺序。
SortSet接口与TreeSet类
TreeSet为SortSet的一个实现类,该类可以按照元素大小进行排序,但是存入的对象必须实现Comparable<T>接口并对其比较方法进行重写,可以比较出对象比较后的大小。或者使用java.util.Comparator;来单独编写一个比较器,创建TreeSet集合的时候提供这个比较器,如果未实现接口或提供比较器会抛出ClassCastException。
新增方法:
- first():返回第一个元素
- last():返回最后一个元素
- lower(Object o):返回指定元素之前的元素
- higher(Obect o):返回指定元素之后的元素
- subSet(fromElement, toElement):返回子集合
EnumSet类
EnumSet这是一个用来操作Enum的集合,EnumSet中的所有元素都必须是指定枚举类型的枚举值,它是一个抽象类,有两个继承类:JumboEnumSet和RegularEnumSet。在使用的时候,需要确定枚举类型。它的特点也是速度非常快。
EnumSet是一个抽象类,不能直接通过new新建,noneOf方法会创建一个指定枚举类型的EnumSet,不含任何元素。创建的EnumSet对象的实际类型是EnumSet的子类,线程不安全
List接口
List子接口是有序集合。有索引,包含了一些带索引的方法,还允许存储重复的元素。
void add(int index, E element) 在指定 index 索引处理插入元素 element
boolean addAll(int index, Collection<? extends E> c) 在指定 index 索引处理插入集合元素 cE remove(int index) 删除指定索引 index 处的元素E set(int index, E element) 修改指定索引 index 处的元素为 element E get(int index) + int size() for循环遍历集合中的每一个元素
ListIterator<E> listIterator() 通过列表迭代器遍历集合中的每一个元素
ListIterator<E> listIterator(int index) 通过列表迭代器从指定索引处开始正向或者逆向遍历集合中的元素
E get(int index) 获取指定索引处的元素
int indexOf(Object o) 从左往右查找,获取指定元素在集合中的索引,如果元素不存在返回 -1
int lastIndexOf(Object o) 从右往左查找,获取指定元素在集合中的索引,如果元素不存在返回 -1
List<E> subList(int fromIndex, int toIndex) 截取从 fromIndex 开始到 toIndex-1 处的元素
ArrayList
ArrayList 是一个数组队列,相当于 动态数组。与Java中的数组相比,它的容量能动态增长。它继承于AbstractList,实现了List, RandomAccess, Cloneable, java.io.Serializable这些接口。ArrayList 继承了AbstractList,实现了List。
它是一个数组队列,提供了相关的添加、删除、修改、遍历等功能。
ArrayList 实现了RandmoAccess接口,即提供了随机访问功能。RandmoAccess是java中用来被List实现,为List提供快速访问功能的。在ArrayList中,我们即可以通过元素的序号快速获取元素对象;这就是快速随机访问。
ArrayList 实现了Cloneable接口,即覆盖了函数clone(),能被克隆。
ArrayList 实现java.io.Serializable接口,这意味着ArrayList支持序列化,能通过序列化去传输。ArrayList的操作不是线程安全的。
扩容机制:当ArrayList不为空时,并且它的大小不超过10时,它的容量都是10.但当大小从10增加到11时,容量变成了15,扩大了1.5倍。
如果ArrayList的容量大于MAX_ARRAY_SIZE,来比较 minCapacity 和 MAX_ARRAY_SIZE,如果minCapacity大于最大容量,则新容量则为Integer.MAX_VALUE,否则,新容量大小则为 MAX_ARRAY_SIZE
即为 Integer.MAX_VALUE - 8。
Vector
Vector 类实现了一个动态数组。和 ArrayList 很相似,但是两者是不同的:
- Vector 是同步访问的。
- Vector 包含了许多传统的方法,这些方法不属于集合框架。
Vector 主要用在事先不知道数组的大小,或者只是需要一个可以改变大小的数组的情况。
第一种构造方法创建一个默认的向量,默认大小为 10;
Vector()
第二种构造方法创建指定大小的向量。
Vector(int size)
第三种构造方法创建指定大小的向量,并且增量用 incr 指定。增量表示向量每次增加的元素数目。
Vector(int size,int incr)
第四种构造方法创建一个包含集合 c 元素的向量:
Vector(Collection c)
Stack
栈是Vector的一个子类,它实现了一个标准的后进先出的栈。它也是线程安全的。
堆栈只定义了默认构造函数,用来创建一个空栈。 堆栈除了包括由Vector定义的所有方法,也定义了自己的一些方法。
Stack()除了由Vector定义的所有方法,自己也定义了一些方法:
E push(E item) 把项压入堆栈顶部
E pop() 移除堆栈顶部的对象,并作为此函数的值返回该对象。
E peek() 查看堆栈顶部的对象,但不从堆栈中移除它。
boolean empty() 测试堆栈是否为空。
int search(Object o) 返回对象在堆栈中的位置,以 1 为基数。
Linkedlist
它继承了AbstractSequentialList 类,同时也实现了 Deque 接口Linkedlist是线性数据结构,其中元素不存储在连续的位置,每个元素都是具有数据部分和地址部分的独立对象。元素使用指针和地址进行链接。每个元素被称为节点。由于插入和删除的动态性和易用性,它们优于阵列。
它也有一些缺点,比如节点不能直接访问,我们需要从头开始,然后通过链接到达我们希望访问的节点。
为了将元素存储在链表中,我们使用一个双向链表,它提供了一个线性数据结构,并且还用于继承一个抽象类并实现list和deque接口。
以下情况使用 ArrayList :
- 频繁访问列表中的某一个元素。
- 只需要在列表末尾进行添加和删除元素操作。
以下情况使用 LinkedList :
- 你需要通过循环迭代来访问列表中的某些元素。
- 需要频繁的在列表开头、中间、末尾等位置进行添加和删除元素操作。
Queue子接口
Queue接口与List、Set同一级别,都是继承了Collection接口。LinkedList实现了Queue接口。
队列的主要特点是在基本的集合方法之外,还提供特殊的插入、获取和检验操作。每个操作都提供两个方法,一种返回异常,一种返回null或者false.
队列一般满足先进先出规则(FIFO),除了优先队列(priority queue)和栈(stack),但是栈是FILO(先进后出规则),优先队列自己定义了排序规则。
队列不允许插入null元素,但是LinkedList可以
java.ulil.concurrent包提供了阻塞队列的4个变种。默认情况下,LinkedBlockingQueue的容量是没有上限的,但是也可以选择指定其最大容量,它是基于链表的队列,此队列按 FIFO(先进先出)排序元素。
ArrayBlockingQueue在构造时需要指定容量, 并可以选择是否需要公平性,如果公平参数被设置true,等待时间最长的线程会优先得到处理(其实就是通过将ReentrantLock设置为true来 达到这种公平性的:即等待时间最长的线程会先操作)。通常,公平性会使你在性能上付出代价,只有在的确非常需要的时候再使用它。它是基于数组的阻塞循环队 列,此队列按 FIFO(先进先出)原则对元素进行排序。
PriorityBlockingQueue是一个带优先级的 队列,而不是先进先出队列。元素按优先级顺序被移除,该队列也没有上限(看了一下源码,PriorityBlockingQueue是对 PriorityQueue的再次包装,是基于堆数据结构的,而PriorityQueue是没有容量限制的,
与ArrayList一样,所以在优先阻塞 队列上put时是不会受阻的。虽然此队列逻辑上是无界的,但是由于资源被耗尽,所以试图执行添加操作可能会导致 OutOfMemoryError),但是如果队列为空,那么取元素的操作take就会阻塞,所以它的检索操作take是受阻的。
另外,往入该队列中的元 素要具有比较能力。
最后,DelayQueue(基于PriorityQueue来实现的)是一个存放Delayed 元素的无界阻塞队列,只有在延迟期满时才能从中提取元素。该队列的头部是延迟期满后保存时间最长的 Delayed 元素。
如果延迟都还没有期满,则队列没有头部,并且poll将返回null。当一个元素的 getDelay(TimeUnit.NANOSECONDS) 方法返回一个小于或等于零的值时,则出现期满,poll就以移除这个元素了。此队列不允许使用 null 元素。 下面是延迟接口:
- add(E e) 插入一个元素到队列中,失败时返回IllegalStateException (队列容量不够)
- element() 返回队列头部的元素
- offer(E e) 插入一个元素到队列中,失败时返回false
- peek() 返回队列头部的元素,队列为空时返回null
- poll() 返回并移除队列的头部元素,队列为空时返回null
- remove() 返回并移除队列的头部元素
Deque接口
双端队列是一种线性集合,可以从两端操作的队列。
- add(E e) 将新元素添加到队列的尾端(当不超过队列的容量时)
- addFirst(E e) 将新元素添加到队列的头部
- addLast(E e) 将新元素添加到队列的尾部
- contains(Object o) 双端队列是否含有对象o
- descendingIterator()倒叙返回队列的迭代器
- element() 返回队列的头部元素
- getFirst() 获取头部元素
- getLast() 获取尾部元素
- iterator() 迭代队列
- offer(E e) 将新元素插入到队列尾部
- offerFirst(E e) 将新元素添加到队列的头部
- offerLast(E e) 将新元素添加到队列的尾部
- peek() 返回队列的头部元素
- peekFirst() 获取头部元素
- peekLast() 获取尾部元素
- pool() 返回并移除队列的头部元素
- poolFirst() 获取并移除头部元素
- poolLast() 获取并移除尾部元素
- pop() 将一个元素出栈
- push(E e) 讲一个元素压入栈
- remove() 移除队列的头部元素
- remove(Object o) 移除队列中第一个o
- removeFirst() 移除队列的头部元素
- removeFirstOccurrence(Object o) 移除队列中第一个o
- removeLast() 移除队列的尾部元素
- removeLastOccurrence(Object o) 移除队列中最后一个o

 浙公网安备 33010602011771号
浙公网安备 33010602011771号