分布式计算框架MapReduce
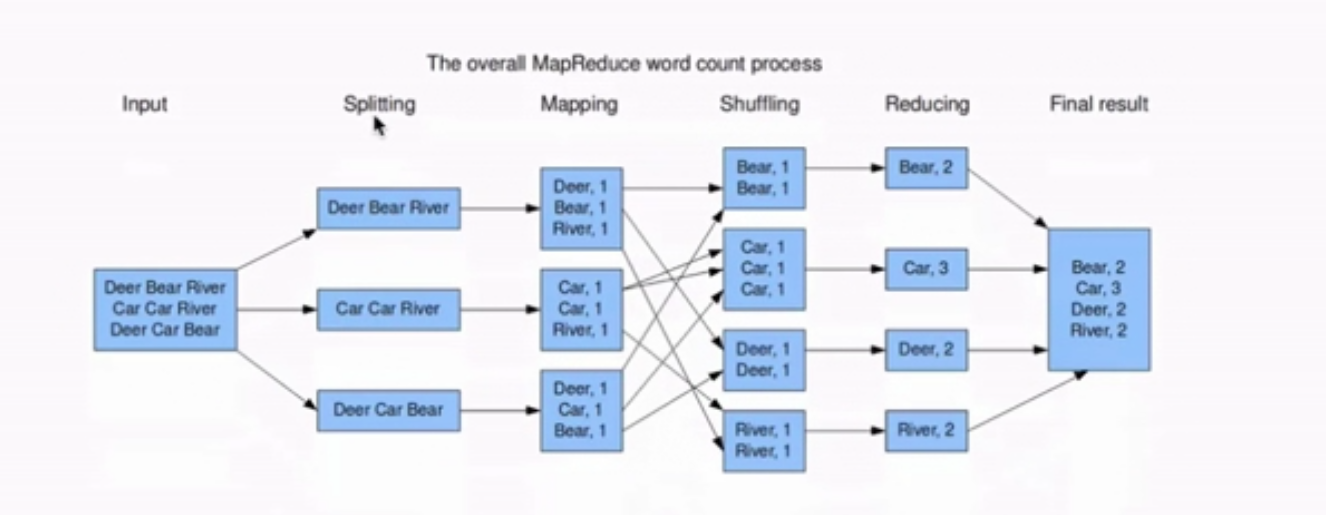
MapReduce编程模型之执行步骤:
准备map处理的输入数据
Mapper处理
shuffle处理
reduce处理
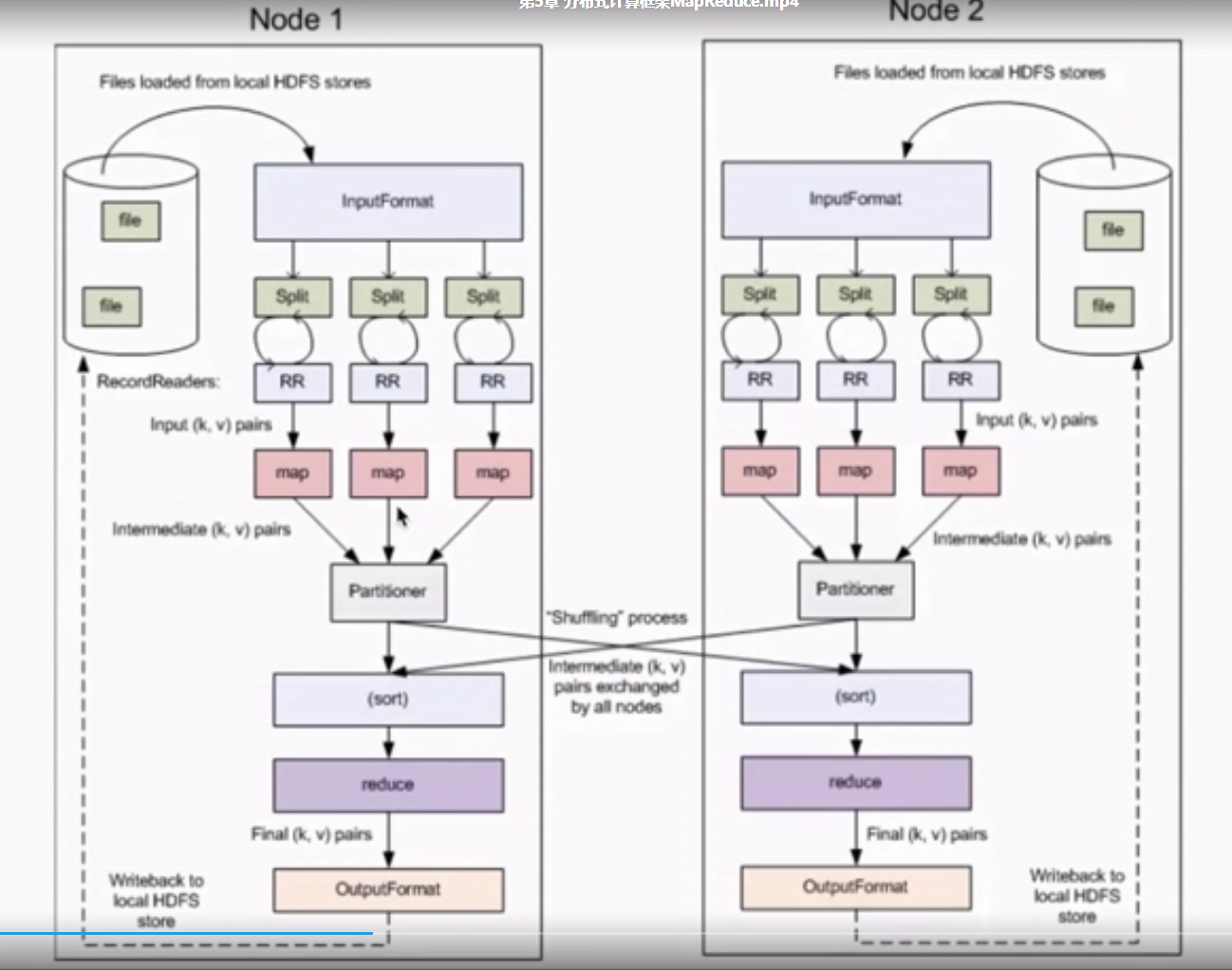
InputFormat:将我们的输入数据进行分片(Split):InputSplit[] getSplitss()
TextInptFormat:处理文本格式的数据
outputFormat:输出
MapReduce1.X架构
1) JobTracker:
作业管理者
将作业分解成一堆的任务:Task(MapTask和ReduceTask)
将任务分配给taskTracker运行
作业的监控、容错处理(Task作业挂了重启task机制)
在一定时间间隔内,JT没有收到TT的心跳信息,tt可能是挂了,TT上运行的任务会被支配到其他TT上执行
2)TaskTracker:TT
任务的执行者
在TT上执行我们的task 、
与JT交互:执行、启动、停止 发送心跳信息给JT
3) mapTask
自己开发的map任务交给task处理
将map输出结写到本地磁盘
4) reduceTask
将map的输入数据进行读取
按照数据进行分组传给我们自己编写的reduce方法处理
输入结构写到hdfs

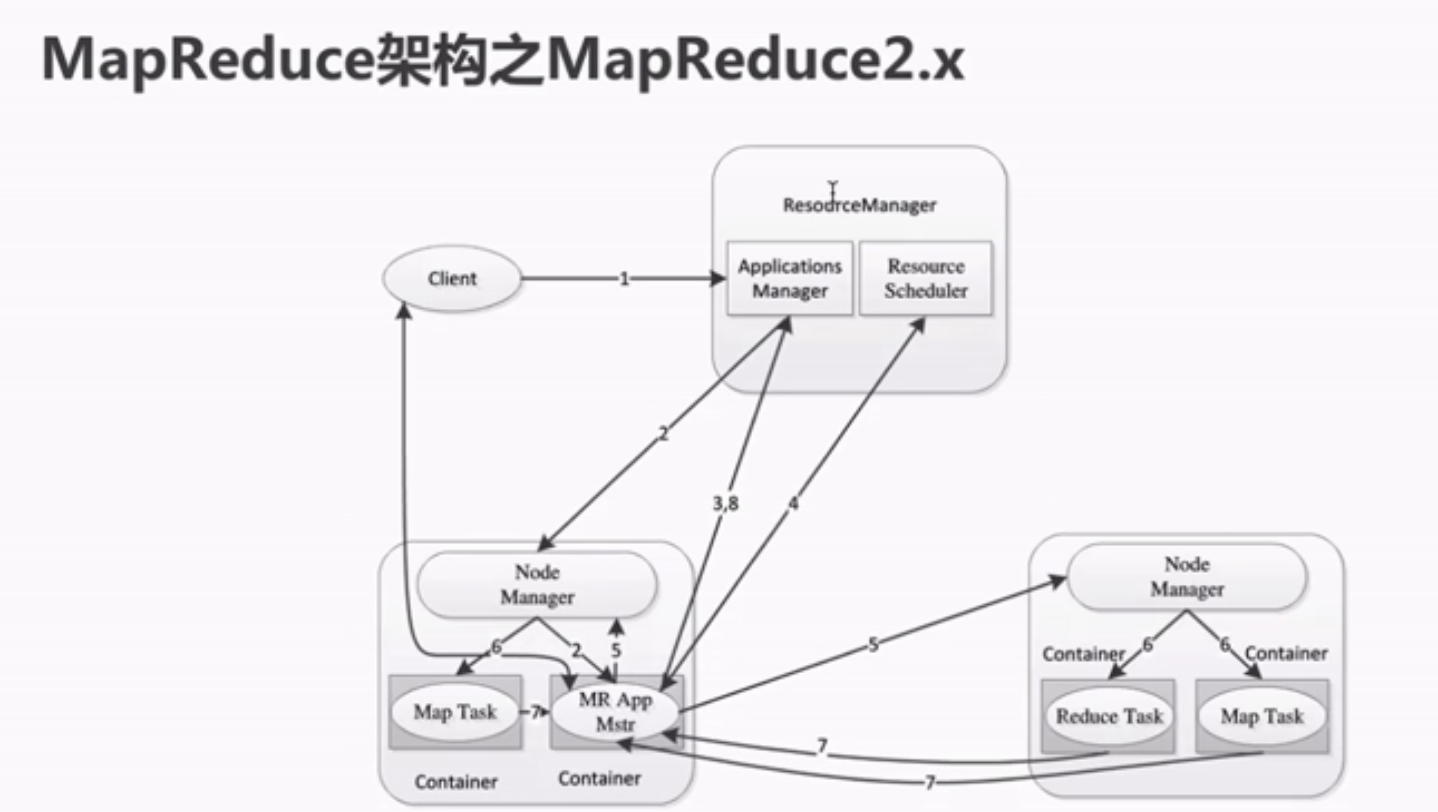
MapReduce2.x的架构
编写MapReduce作业 代码如下:
package com.zl.hadoop.mapreduce; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /** * MapReduce开发wordCount应用 * * @author zhagnlei * @ProjectName: hadoopResource * @create 2018-12-08 20:48 * @Version: 1.0 * <p>Copyright: Copyright (zl) 2018</p> **/ public class WordCountApp { /** * Map:读取输入文件 */ public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> { LongWritable one = new LongWritable(1); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] words = line.split(" "); for (String word :words) { //通过上下文静map结果输出 context.write(new Text(word), one); } } } /** * Reduce:归并操作 */ public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> { @Override protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { long sum = 0; for (LongWritable value : values) { //求key单词出现的次数总和 sum += value.get(); } context.write(key, new LongWritable(sum)); } } /** * 定义Driver:封装MapReduce作业的所有信息 */ public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration, "wordCount"); //设置job的处理类 job.setJarByClass(WordCountApp.class); //设置作业处理的输入路径 FileInputFormat.setInputPaths(job, new Path(args[0])); //设置map相关的参数 job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); //通过job的设置combiner,是的在map的时候统计一次,减少网络传输 job.setCombinerClass(MyReducer.class); //设置Reduce相关输出路径 job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); //设置作业输出 FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
通过maven编译成jar文件,提交到服务器执行
hadoop执行命令: hadoop jar +jar文件路径+主类+参数
具体命令如下:hadoop jar hadoopResource-1.0-SNAPSHOT.jar com.zl.hadoop.mapreduce.WordCountApp hdfs://192.168.1.4:8020/hello.txt hdfs://192.168.1.4:8020/wo

 浙公网安备 33010602011771号
浙公网安备 33010602011771号