分布式文件系统--HDFS
前提和设计目标
硬件错误
硬件错误是常态而不是异常。HDFS可能由成百上千的服务器所构成,每个服务器上存储着文件系统的部分数据。我们面对的现实是构成系统的组件数目是巨大的,而且任一组件都有可能失效,这意味着总是有一部分HDFS的组件是不工作的。因此错误检测和快速、自动的恢复是HDFS最核心的架构目标。
流式数据访问
运行在HDFS上的应用和普通的应用不同,需要流式访问它们的数据集。HDFS的设计中更多的考虑到了数据批处理,而不是用户交互处理。比之数据访问的低延迟问题,更关键的在于数据访问的高吞吐量。POSIX标准设置的很多硬性约束对HDFS应用系统不是必需的。为了提高数据的吞吐量,在一些关键方面对POSIX的语义做了一些修改。
大规模数据集
运行在HDFS上的应用具有很大的数据集。HDFS上的一个典型文件大小一般都在G字节至T字节。因此,HDFS被调节以支持大文件存储。它应该能提供整体上高的数据传输带宽,能在一个集群里扩展到数百个节点。一个单一的HDFS实例应该能支撑数以千万计的文件。
简单的一致性模型
HDFS应用需要一个“一次写入多次读取”的文件访问模型。一个文件经过创建、写入和关闭之后就不需要改变。这一假设简化了数据一致性问题,并且使高吞吐量的数据访问成为可能。Map/Reduce应用或者网络爬虫应用都非常适合这个模型。目前还有计划在将来扩充这个模型,使之支持文件的附加写操作。
“移动计算比移动数据更划算”
一个应用请求的计算,离它操作的数据越近就越高效,在数据达到海量级别的时候更是如此。因为这样就能降低网络阻塞的影响,提高系统数据的吞吐量。将计算移动到数据附近,比之将数据移动到应用所在显然更好。HDFS为应用提供了将它们自己移动到数据附近的接口。
异构软硬件平台间的可移植性
HDFS在设计的时候就考虑到平台的可移植性。这种特性方便了HDFS作为大规模数据应用平台的推广。
Namenode(NN)和 DatanodeNN(DN)
NN:是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。
DN:存储用户的文件对应的数据块(Block),比如一个130M文件会被存储为一个128M的block和一个2M的block(默认blockSize是128M)
架构
HDFS采用master/slave架构。master(NameNode)和slaver(DataNode),一个NameNode+N个DataNode
建议:NN和DN是部署在不同的节点上
replication factor:副本系数、副本因子
搭建HDFS
执行环节:1、linux系统
2、java运行环节
3、必须安装ssh(1.检测是否安装ssh:sudo service sshd status,如果没有安装执行:sudo yum install ssh)
配置面密码登录:1.生成ssh文件:执行ssh-keygen -t -rsa,一路回车就可以
2、在当前用户目录下可以看到.ssh文件
3.cp ~/.ssh.id_rsa,pub ~/.ssh/authorized_keys
下载hadoop安装包:
1.下载路径:http://archive.cloudera.com/cdh5/cdh/5/ 本处使用的是hadoop-2.6.0-cdh5.7.0版本,也可以直接从百度云盘上下载:https://pan.baidu.com/s/1v_fB7mvAfYH1k9uHeEn5Pw
2.解压安装包:下载安装包并解压到到hadoop用户下的app目录;文件目录如下:

3.修改 配置文件
配置文件
修改export JAVA_HOME=java_home的文件地址。直接执行echo $JAVA_HMOE就可以查看java_home
4.配置etc/hadoop/core-site.xml(home/hadoop/app/hadoop-2.6.0-cdn5.7.0/etc/hadoop/core-site.xml),配置HDFS文件地址
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.1.4:8020</value>
</property>
<--->作用:避免创建零时文件夹,当linux重启后,文件全部丢失,此处是存放到指定文件夹中<!-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/tmp</value>
</property>
5.配置etc/hadoop/hdfs-site.xml (home/hadoop/app/hadoop-2.6.0-cdn5.7.0/etc/hadoop/hdfs-site.xml),设置副本系数为1(因为此处部署的是单节点)
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
6.配置home/hadoop/app/hadoop-2.6.0-cdn5.7.0/etc/hadoop下的slaves(作用:有多少个DataNode,就将DataNode的ip写在这个里面)
此处是单机版,可以不做修改,直接写成localhost或者是hadoop都可以;
7、启动hdfs
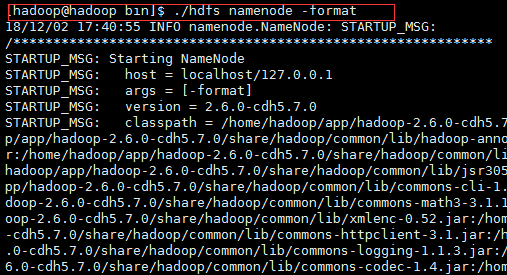
7.1格式化文件系统(仅第一次执行即可,不要重复执行):进入hadoop下的bin目录执行格式化命令hdfs namenode -format
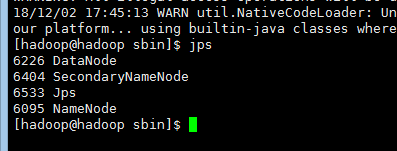
7.2:启动NameNode和DataNode
进入hadoop目录下的sbin目录,执行:./start-dfs.sh
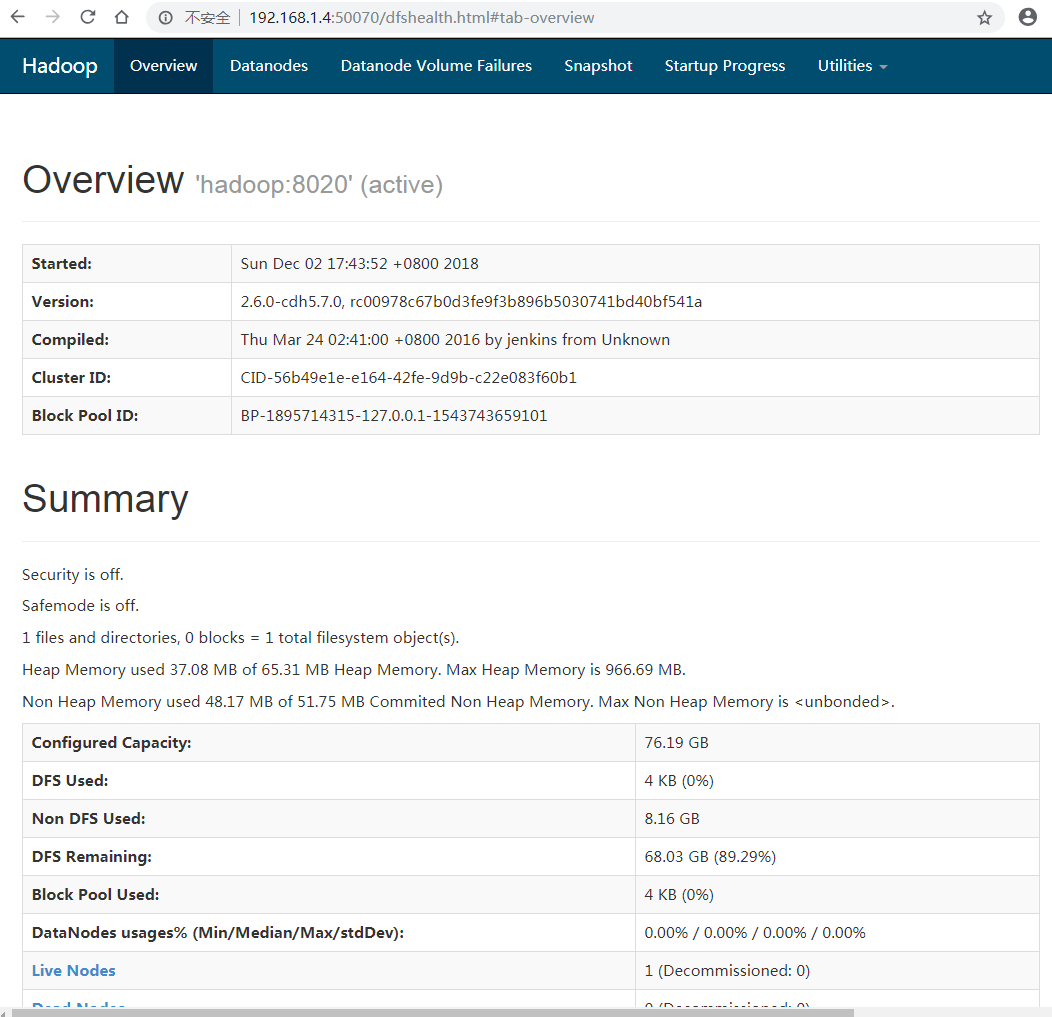
7.3 校验是否启动成功,或者通过浏览器直接验证:localhost:50070
浏览器校验:
7.4 :停止dfs服务
进入hadoop的sbin目录,执行:./stop-dfs.sh
建议操作:将hadoop的bin目录配置到环境变量中去:
在文件中加入:
export HADOOP_HOME=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0
export PATH=$HADOOP_HOME/bin:$PATH
然后使配置文件生效:source ~/.bash_profile
检测配置是否成功:echo $HADOOP_HOME

 浙公网安备 33010602011771号
浙公网安备 33010602011771号