
一、什么是Hive
Hive是建立在 Hadoop 上的数据仓库基础构架。
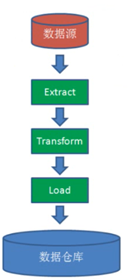
它提供了一系列的工具,可以用来进行数据提取,转化,加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。
可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,Hive底层是将 SQL语句转换为MapReduce任务进行。

一、Hive和Hadoop之间的关系
Hive 处理的数据存储在HDFS;利用MapReduce查询数据;执行程序在YARN上。
Hive可以看做是MapReduce的客户端
因为Hive的底层运算是MapReduce计算框架,Hive只是将可读性强,容易编程的SQL语句通过Hive软件转换成MR程序在集群上执行。hive可以看做mapreduce客户端,能用mapreduce程序完成的任务基 本都可以对应的替换成hql(Hive SQL)编写的hive任务。所以因为hadoop和hdfs的本身设计的特点,也限制了hive所能胜任的工作特性。Hive最大的限制特点就是不支持基于行记录的更新,删除,增 加。但是用户可以通过查询生成新表,或者将查询结果导入文件中来“实现”hive基于行记录的操作
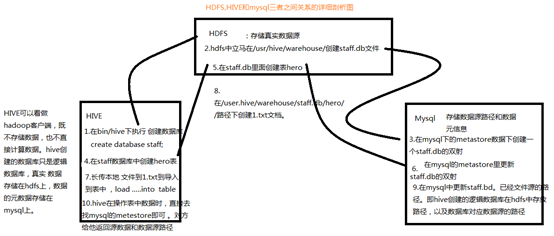
二、hive和hdfs,mysql,mapreduce之间的关系
1,举例说明hive,mysql和hdfs之间的关系
下面是一个完成的流程,从hive中创建表,到往表里导入数据,1-9说明了hive,mysql,hdfs之间的流程。
2,要点总结
1.Hive不存储数据,Hive需要分析计算的数据,以及计算结果后的数据实际存储在分布式系统上,如HDFS上。
2.Hive某种程度来说也不进行数据计算,只是个解释器,只是将用户需要对数据处理的逻辑,通过SQL编程提交后解释成MapReduce程序,然后将这个MR程序提交给Yarn进行调度执行。所以实际进行分布式运算的是MapReduce程序
3.因为Hive为了能操作HDFS上的数据集,那么他需要知道数据的切分格式,如行列分隔符,存储类型,是否压缩,数据的存储地址等信息。为了方便以后操作所以他需要将这些信息通过一张表存储起来,然后将这张表(元数据)存储到mysql中。为了啥存储到mysql里(实际是远程mysql),因为hive本身就是一个解释器,所以他不存储数据 。
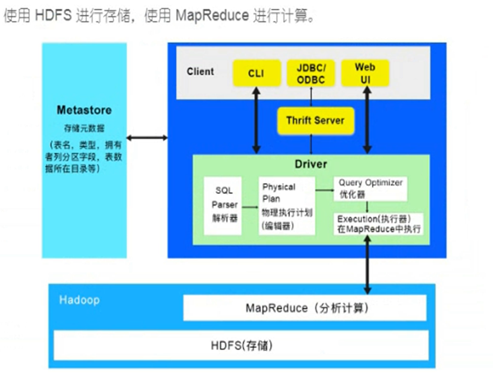
三、Hive的架构原理
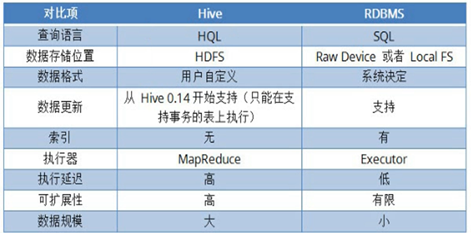
四、Hive和RDBMS的对比
五、三种运行模式



安装见链接


 浙公网安备 33010602011771号
浙公网安备 33010602011771号