

2.安装Spark与Python练习
一、安装Spark
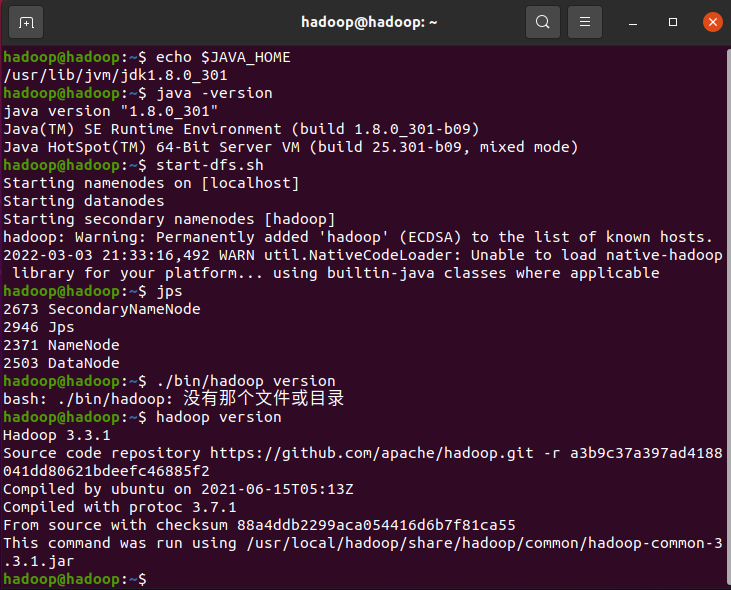
1、检查基础环境hadoop,jdk
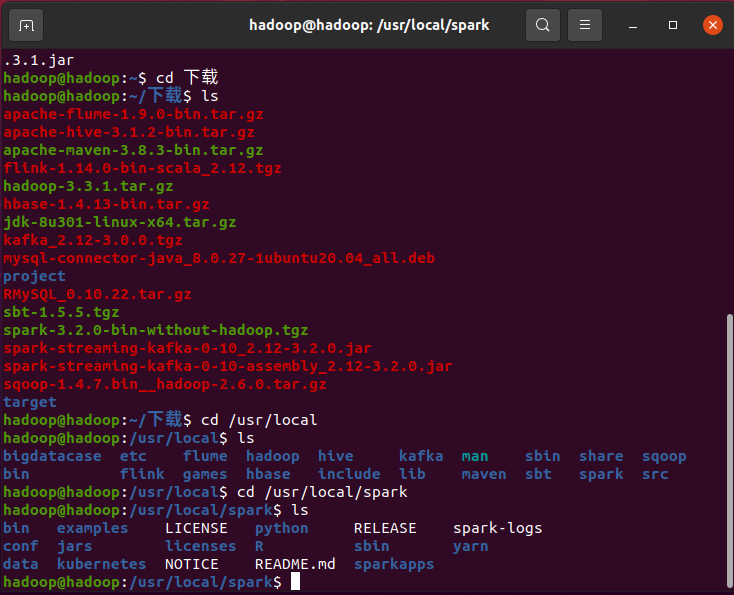
2、下载spark
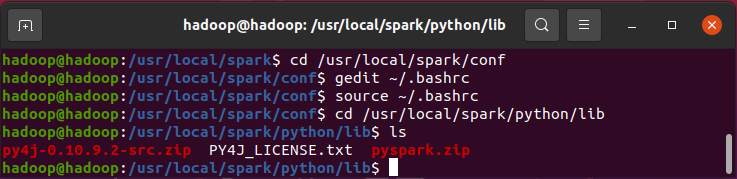
3、环境变量
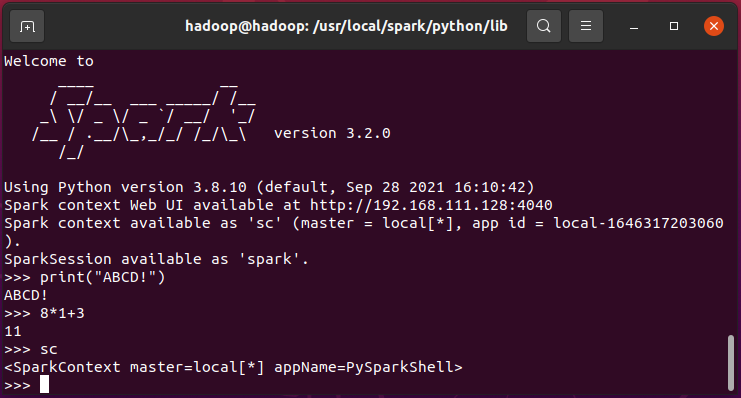
二、Python编程练习:英文文本的词频统计
准备文本文件(1.txt与2.txt相同)
#文本内容
May you have enough happiness to make you sweet,enough trials to make you strong,enough sorrow to keep you human,enough hope to make you happy? Always put yourself
in others’shoes.If you feel that it hurts you,it probably hurts the other person, too.
插入代码
path='/home/hadoop/wc/1.txt' with open(path) as f: text=f.read() words = text.split() wc={} for word in words: wc[word]=wc.get(word,0)+1 wclist=list(wc.items()) wclist.sort(key=lambda x:x[1],reverse=True) print(wclist)
结果显示
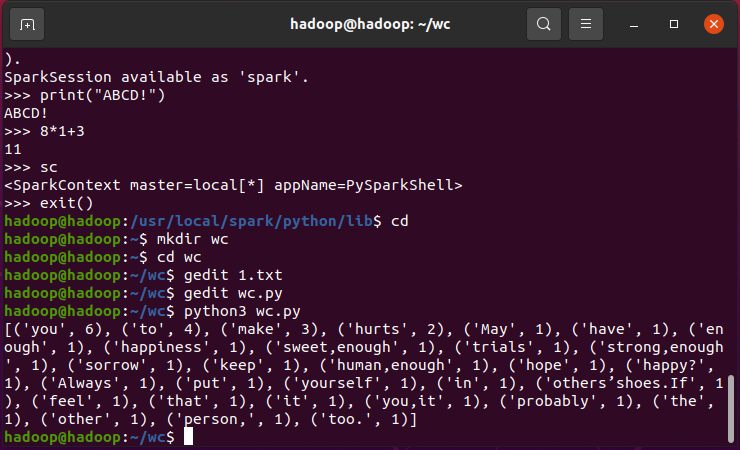
插入代码
#读取文件,将所有单词统一为小写,空格替换特殊字符 def gettext(): txt = open("2.txt","r",errors='ignore').read() txt = txt.lower() for ch in '!"#$&()*+,-./:;<=>?@[\\]^_{|}·~‘’': txt = txt.replace(ch,"") return txt #对处理后的文本进行词频统计存入字典 txt = gettext() words = txt.split() counts = {} for word in words: counts[word] = counts.get(word,0) + 1 #统计结果存为列表类型,按词频由高到低进行排序,输出前十位 items = list(counts.items()) items.sort(key=lambda x:x[1],reverse=True) for i in range(10): word,count = items[i] print("{0:<10}{1:>5}".format(word,count))
结果显示
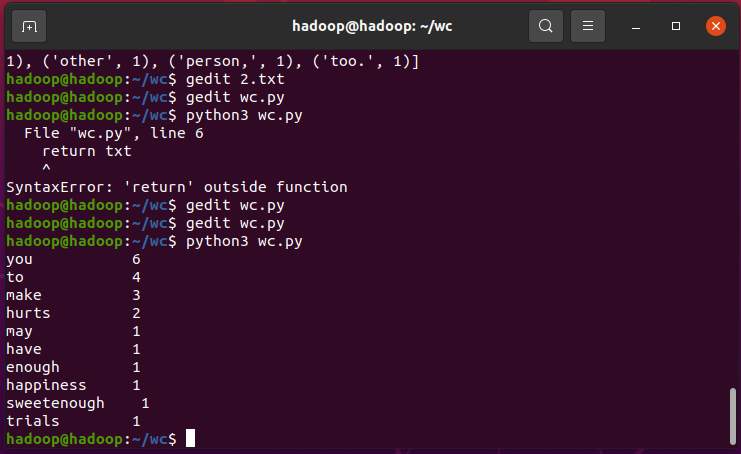

 浙公网安备 33010602011771号
浙公网安备 33010602011771号