SKLearn数据集API(二)
注:本文是人工智能研究网的学习笔记
计算机生成的数据集
用于分类任务和聚类任务,这些函数产生样本特征向量矩阵以及对应的类别标签集合。
| 数据集 | 简介 |
|---|---|
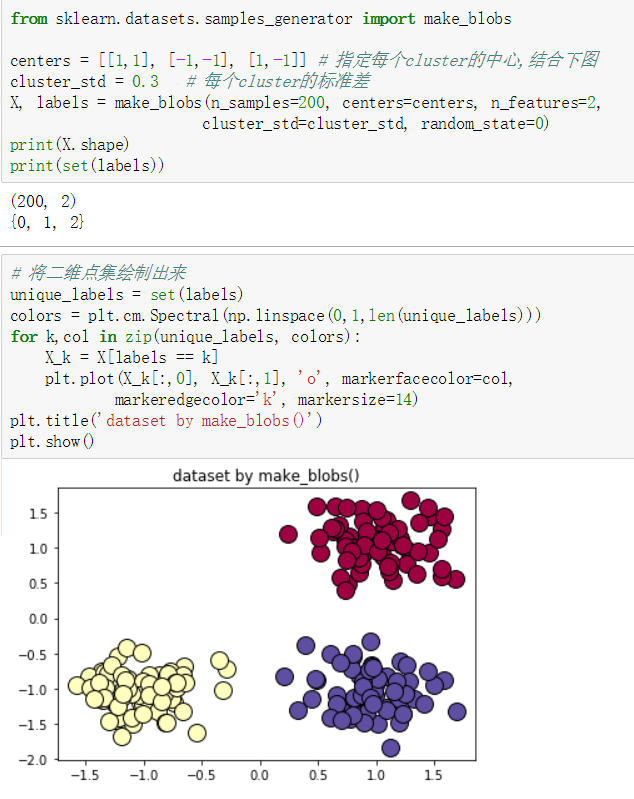
| make_blobs | 多类单标签数据集,为每个类分配一个或者多个正态分布的点集,提供了控制每个数据点的参数:中心点(均值),标准差,常用于聚类算法。 |
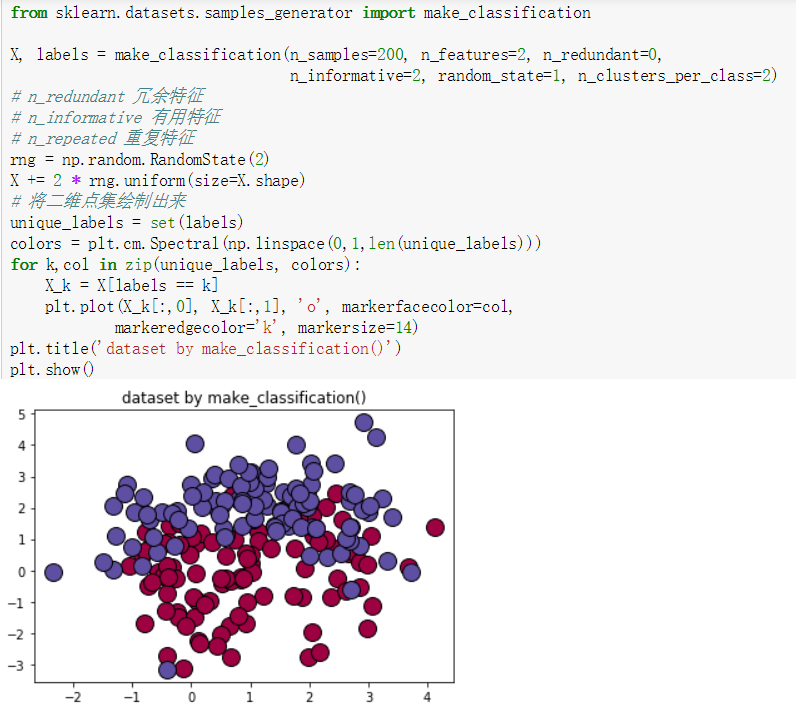
| make_classification | 多类单标签数据集,为每个类分配了一个或者多个正态分布的点集。提供了为数据集添加噪声的方式,包括维度相性,无效特征和冗余特征等。 |
| make_gaussian_quantiles | 将一个单高斯分布的点集活粉为两个数量均等的点集,作为两类。 |
| make_hastie_10_2 | 产生一个相似的二元分类器数据集,有10个维度。 |
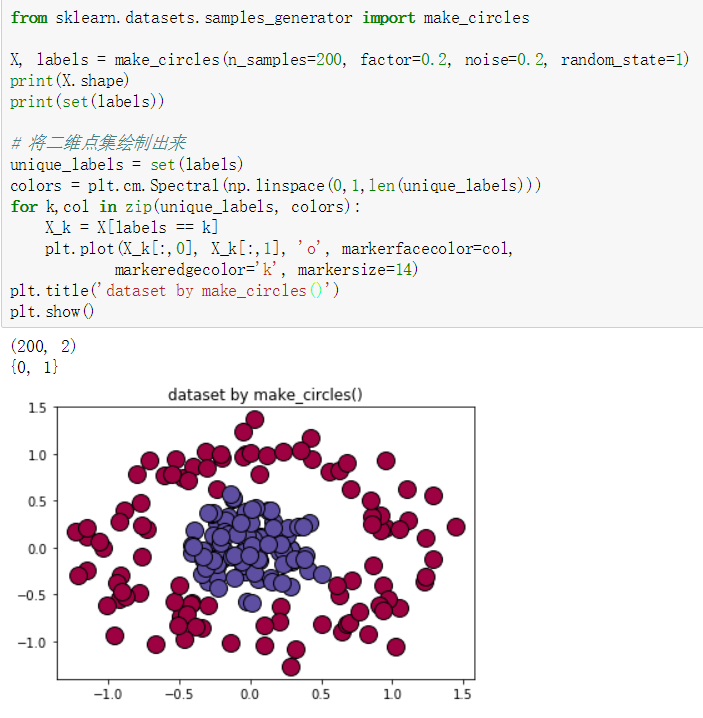
| make_circles/make_moons | 产生二维分类数据集来测试某些算法(e.g.centroid-based clustering或linear classfication)的性能。可以为数据集添加噪声,可以为二元分类器产生一些球形判决表面的数据。 |
用于多标签分类任务
| 数据集 | 简介 |
|---|---|
| make_multilabel_classification | 产生多类多标签随机样本,这些样本模拟了从很多话题的混合分布中抽取的词袋模型,每个文档的话题数量符合泊松分布,话题本身则从一个固定的随机分布中抽取出来,同样的,单词数量也是泊松分布抽取,句子则是从多项式抽取。 |
用于回归任务的
| 数据集 | 简介 |
|---|---|
| make_regression | 产生回归任务的数据集,期望目标输出是随机特征的稀疏随机线性组合,并且附带有噪声,它的有用的特征可能是不相关的,或者低秩的(引起目标值的变动的只有少量的集合特征) |
| make_sparse_uncorrelated | 产生四个特征的线性组合(固定参数)作为期望目标输出 |
| make_friedman1 | 采用了多项式和正弦变换 |
| make_friedman2 | 包含了特征的乘积和互换操作 |
| make_friedman3 | 类似于arctan变换 |
用于流行学习的
| 数据集 | 简介 |
|---|---|
| make_s_curve | 生成S型曲线数据集 |
| make_swiss_roll | 生成瑞士卷曲线数据集 |
用于因子分解的
| 数据集 | 简介 |
|---|---|
| make_low_rank_matrix | |
| make_sparse_coded_signal | |
| nake_spd_matrix | 产生的是随机的堆成的正定矩阵 |
| make_sparse_spd_matrix | 产生的是稀疏的堆成正定矩阵 |
make_blobs()
make_classification()
make_moons()

make_circles()
svmlight/libsvm格式的数据集
svmlight/libsvm的每一行样本的存放格式
<label> <feature-id>:<feature-value> <feature-id>:<feature-value>...
使用下面的方式导入该格式的数据集
X_train, y_train = sklearn.datasets.load_svmlight_file('train.txt')
还可以使用下面的方式将训练集和测试集一起导入,可以保证X_train和X_test有同样数目的特征
X_train, y_train, X_test, y_test = sklearn.datasets.load_svmlight_file(('train.txt', 'test.txt'))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号