
爬取百度贴吧热榜信息
一、选题的背景
百度贴吧是一个较大的交流平台,网友们经常会在上面讨论和发表自己的意见,热门榜是网友们讨论最多的话题,我们从这里可以清楚看到当前网友们讨论的最多的话题是什么
二、设计方案
1.爬虫名称:爬取百度贴吧热榜
2.爬取的内容:爬取百度贴吧热榜排名、标题名称、实时热度
3.爬虫设计方案概述:
- 找到需要爬取的页面
- 查找页面源码
- 对源码进行解析,找到标题、热度等信息
- 编写代码
- 对数据进行持久化存储
- 数据清洗
- 数据分析
8.技术难点:代码编写需要导入许多的第三方库,对python语言要有一点的基础,要会使用函数,正则表达式,要会对页面进行分析和内容定位
三、实现步骤及代码(60分)
1.找到自己需要爬取的页面,获取url
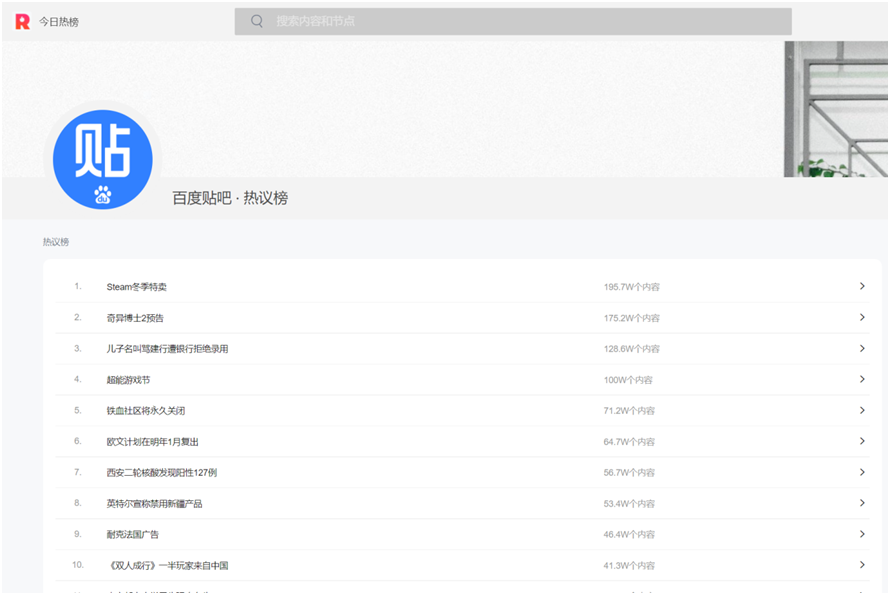
这里我们选择今日热榜上的百度贴吧热榜板块进行爬取
网址是:https://tophub.today/n/Om4ejxvxEN
-
进行页面解析,按F12打开开发者模式,点击图中所指图标,选中标题
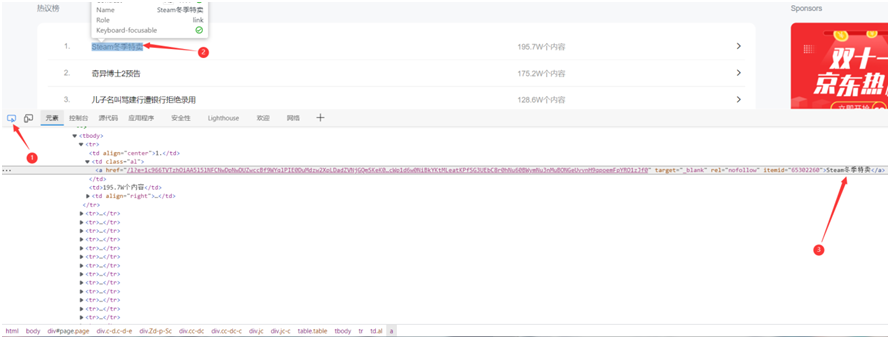
- 我们可以看到我们需要获取的所有标题和热度在都在属性名为”al”下的子标签a和td中
分析完后就可以进行代码编写
2.爬虫代码编写
1 #导入爬虫所需要的包 2 import requests 3 import bs4 4 import pandas as pd 5 from bs4 import BeautifulSoup 6 import numpy as np 7 import matplotlib 8 import seaborn as sns 9 from matplotlib import pyplot as plt 10 import re 11 from scipy.sparse import data 12 from wordcloud import WordCloud 13 import matplotlib.pyplot as plt 14 from imageio import imread 15 16 17 #获取页面url并进行头部伪装 18 #获取页面数据 19 def getHtml(url): 20 #UA伪装 21 headers = { 22 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62' 23 } 24 html_text = page_text = requests.get(url = url,headers = headers).text 25 return html_text 26 27 28 #获取页面数据并进行标签定位 29 #html解析 30 def htmlJs(html_text): 31 soup = BeautifulSoup(html_text,'lxml') 32 return soup 33 #标签定位 34 def getTitle(): #获取标题 35 title_text = htmlJs(getHtml(url)).select('tbody > tr > .al > a') 36 return title_text 37 #获取热度 38 def getRedu(): 39 redu = htmlJs(getHtml(url)).select('tbody > tr > td:nth-of-type(3)') 40 return redu 41 42 43 #.进行持久化存储 44 if __name__ == '__main__': 45 url = "https://tophub.today/n/Om4ejxvxEN" 46 getHtml(url) 47 biaoti = [] #存放获取到的标题 48 hot = [] #存放获取到的热度信息 49 for tit in getTitle(): 50 biaoti.append(tit.text) #将获取到的标题存放在biaoti数组中 51 # print(biaoti) 52 for rd in getRedu(): 53 num = re.findall('\d+\.\d+|\d+',rd.text) 54 # print(num) 55 hot.append(num[0]) 56 # print(hot) 57 58 #对数据进行持久化 59 shuju = [] #存储数据 60 print("{:^10}\t{:^40}\t{:^25}".format('排名','标题','热度')) 61 # 将标题和热度存储到列表中 62 for i in range(15): 63 print("{:^10}\t{:^40}\t{:^25}".format(i+1,biaoti[i],hot[i])) 64 shuju.append([i+1,biaoti[i],hot[i]]) 65 #将数据存储到表格里 66 df = pd.DataFrame(shuju,columns = ["排名",'标题','热度']) 67 df.to_csv('百度贴吧热搜榜.csv',index = False) 68 print("保存成功!!!")
结果如下

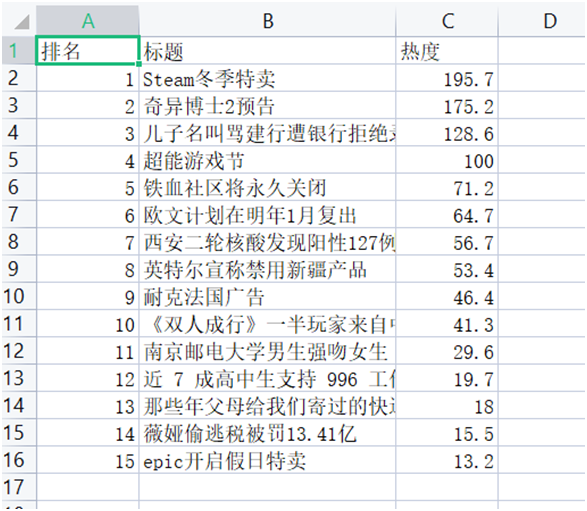
数据清洗
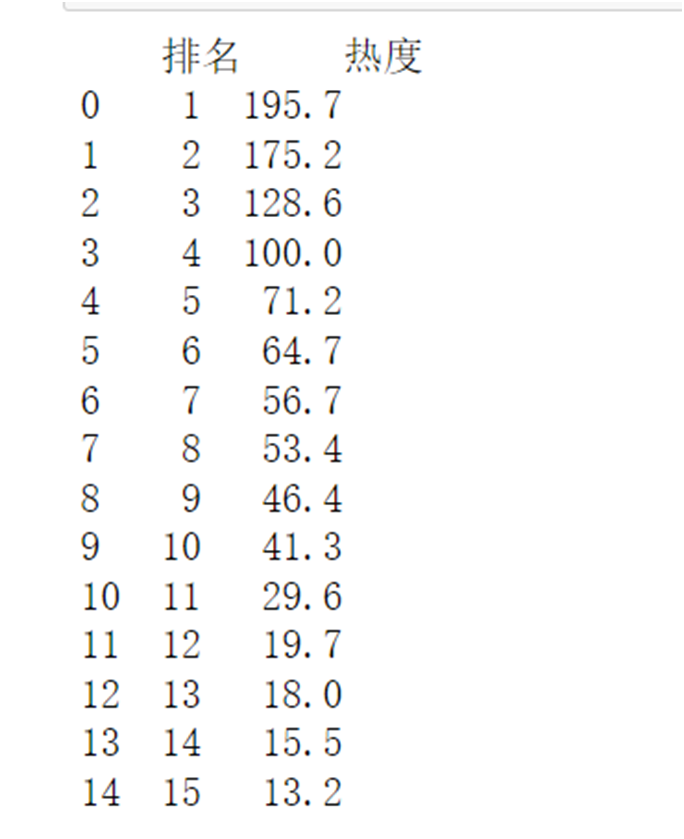
1 #数据清洗 2 #导入文件 3 df = pd.DataFrame(pd.read_csv('百度贴吧热搜榜.csv')) 4 #删除无效行列 5 # 删除无效行 6 df.drop('标题',axis = 1,inplace = True) 7 print(df.head(20))
1 #查找重复值 2 #查找重复值 3 print(df.duplicated())
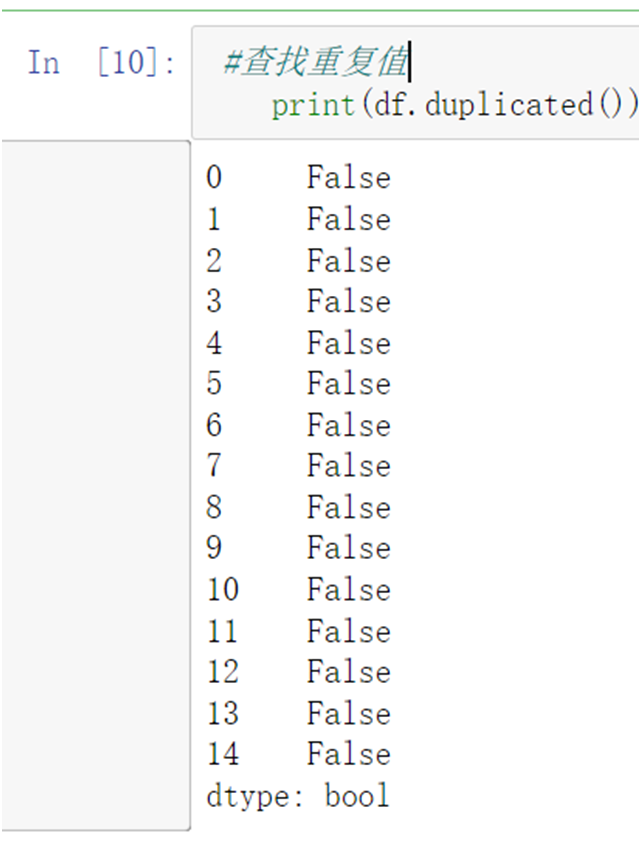
结果:无重复值
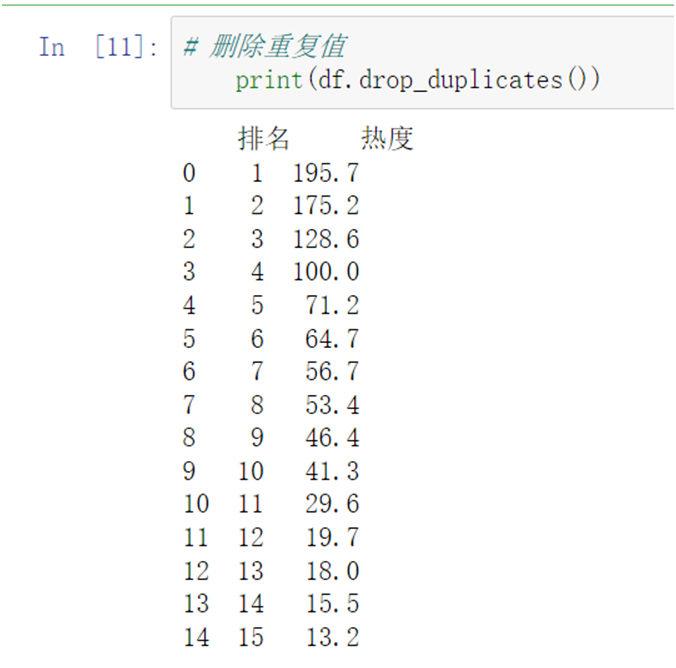
1 # 删除重复值 2 print(df.drop_duplicates())
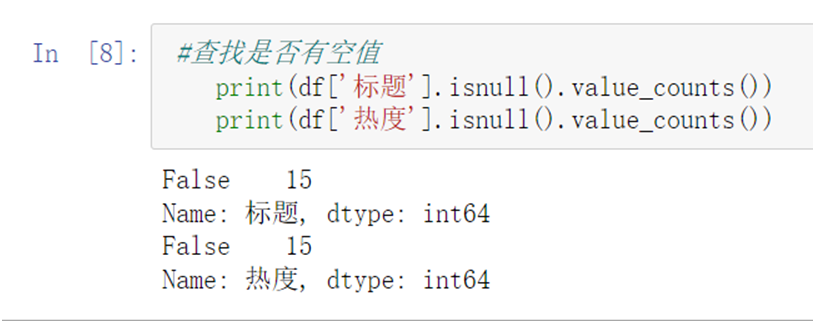
1 #查找是否有空值 2 print(df['标题'].isnull().value_counts()) 3 print(df['热度'].isnull().value_counts())
1 #异常值的观察 2 print(df.describe())
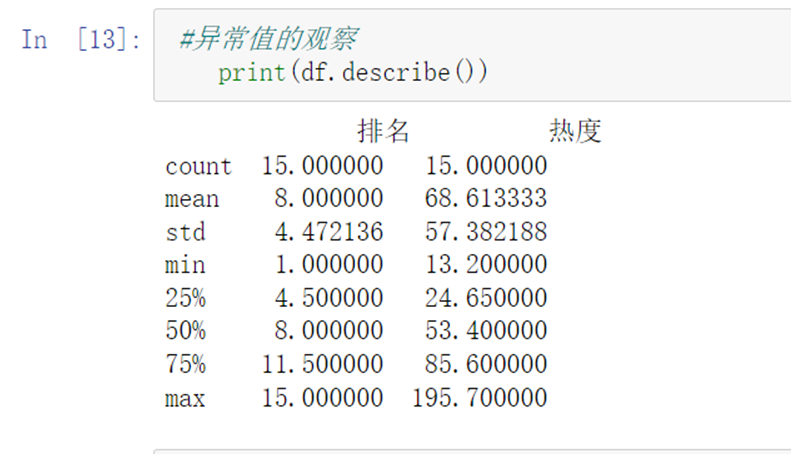
结果:没问题
1 #查看相关系数 2 print(df.corr())
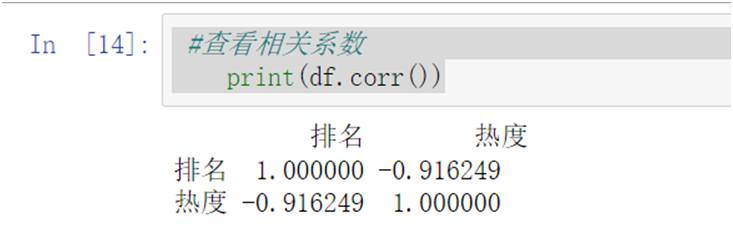
- 数据可视化
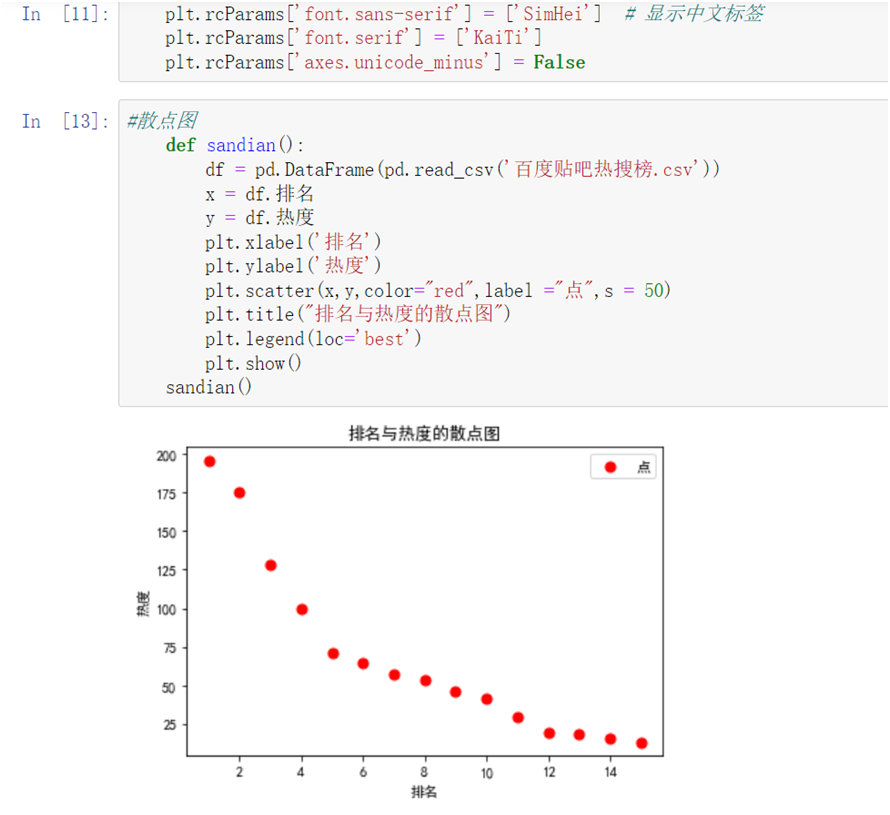
1 #散点图 2 def sandian(): 3 df = pd.DataFrame(pd.read_csv('百度贴吧热搜榜.csv')) 4 x = df.排名 5 y = df.热度 6 plt.xlabel('排名') 7 plt.ylabel('热度') 8 plt.scatter(x,y,color="red",label ="点",s = 50) 9 plt.title("排名与热度的散点图") 10 plt.legend(loc='best') 11 plt.show() 12 sandian()
![]()
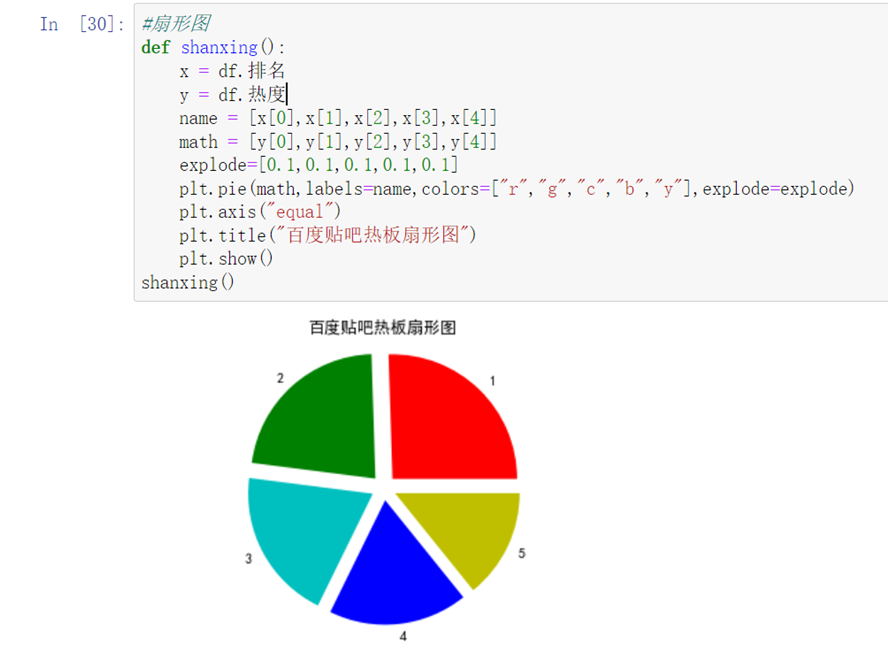
1 #扇形图 2 def shanxing(): 3 x = df.排名 4 y = df.热度 5 name = [x[0],x[1],x[2],x[3],x[4]] 6 math = [y[0],y[1],y[2],y[3],y[4]] 7 explode=[0.1,0.1,0.1,0.1,0.1] 8 plt.pie(math,labels=name,colors=["r","g","c","b","y"],explode=explode) 9 plt.axis("equal") 10 plt.title("百度贴吧热板扇形图") 11 plt.show() 12 shanxing()
![]()
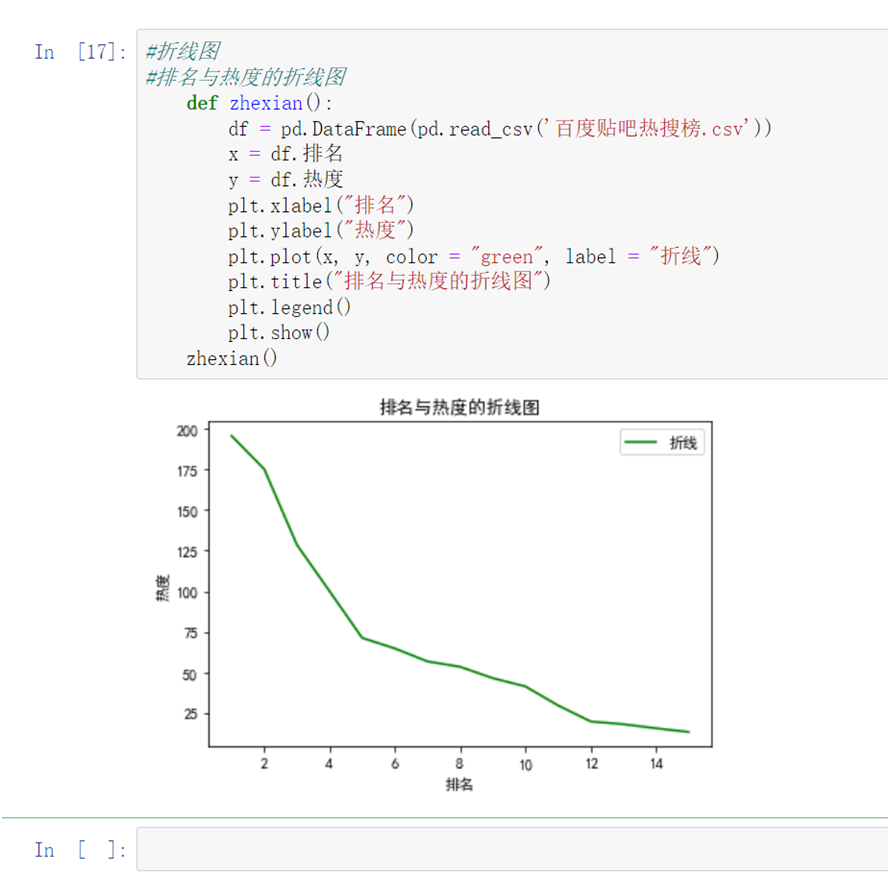
1 #折线图 2 #排名与热度的折线图 3 def zhexian(): 4 x = df.排名 5 y = df.热度 6 plt.xlabel("排名") 7 plt.ylabel("热度") 8 plt.plot(x, y, color = "green", label = "折线") 9 plt.title("排名与热度的折线图") 10 plt.legend() 11 plt.show() 12 zhexian()
![]()
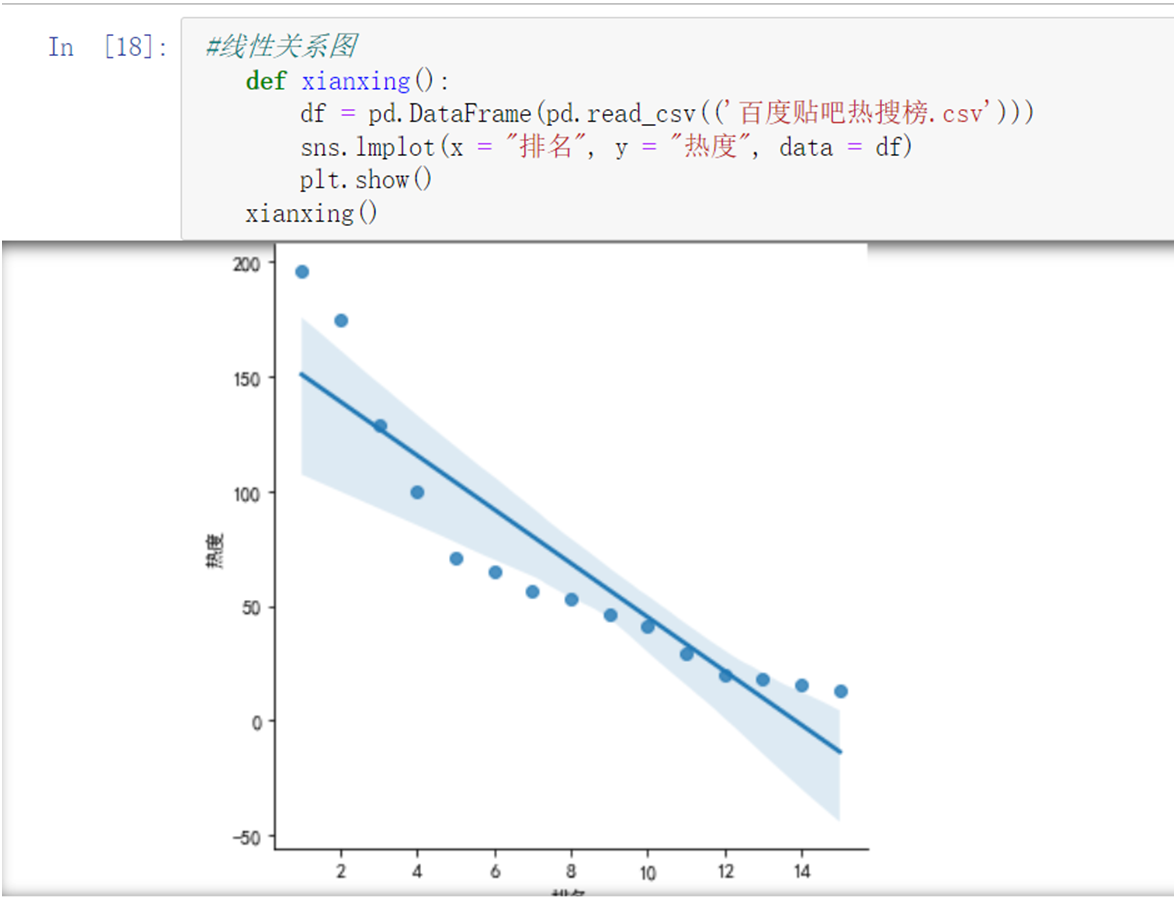
1 #线性关系图 2 def xianxing(): 3 sns.lmplot(x = "排名", y = "热度", data = df) 4 plt.show() 5 xianxing()
![]()
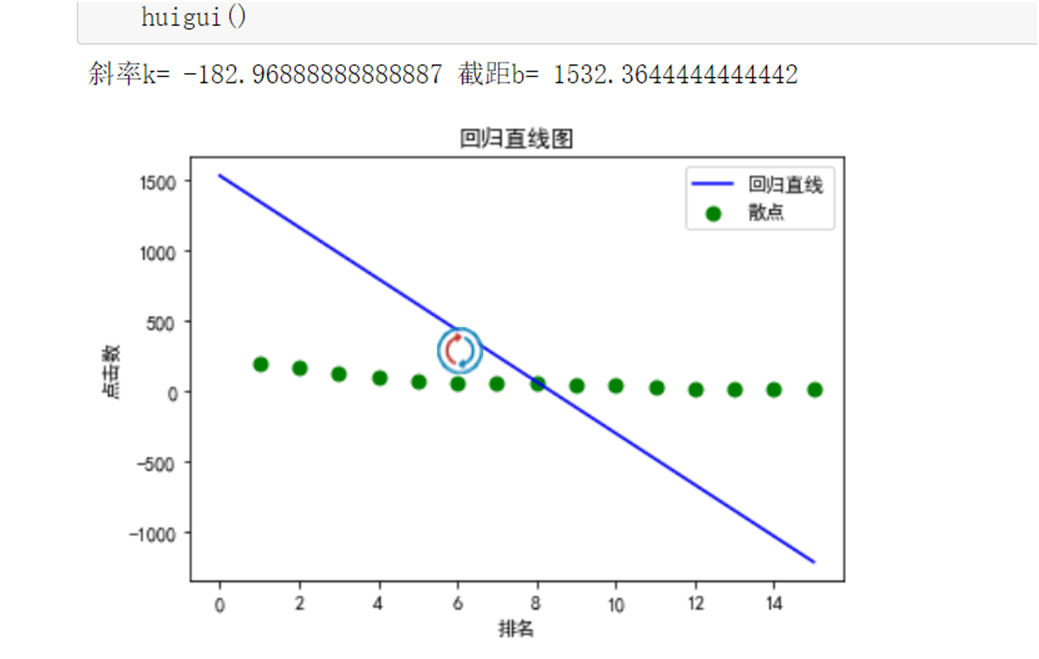
1 # 回归直线的图 2 def huigui(): 3 # x,y为回归直线的排名和点击数 4 x = df.排名 5 y = df.热度 6 # X,Y为散点图的 7 X = df.排名 8 Y = df.热度 9 # 先定义所需要的数据 10 x_i2 = 0 11 x_i = 0 12 y_i = 0 13 # 计算出x,y的均值用mean() 14 q = x.mean() 15 w = y.mean() 16 for i in range(15): 17 x_i2 = x_i + x[i] * x[i] 18 x_i = x_i + x[i] 19 y_i = y_i + y[i] 20 # 运用回归直线的公式计算出所需要的值 21 # 分子 22 m_1 = x_i * y_i - 15 * q * w 23 # 分母 24 m_2 = x_i2 - 15 * q * q 25 # 斜率 26 k = m_1 / m_2 27 # 截距 28 b = w - q * k 29 x = np.linspace(0, 15) 30 y = k * x + b 31 print("斜率k=", k, "截距b=", b) 32 plt.figure(figsize = (6, 4)) 33 plt.xlabel('排名') 34 plt.ylabel('点击数') 35 plt.scatter(X, Y, color = "green", label = "散点", linewidth = 2) 36 plt.plot(x, y, color = "blue", label = "回归直线") 37 plt.title("回归直线图") 38 plt.legend() 39 plt.show() 40 huigui()
![]()
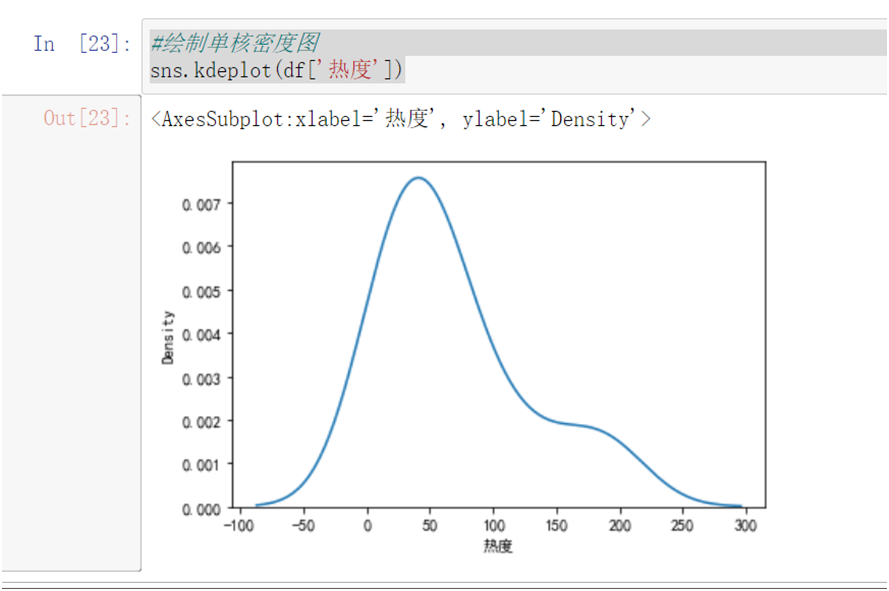
#绘制单核密度图 sns.kdeplot(df['热度'])
![]()
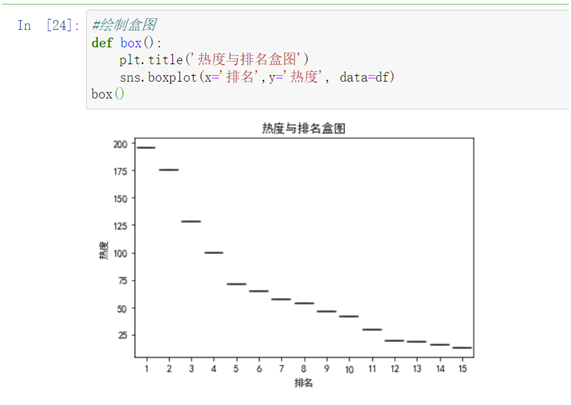
1 #绘制盒图 2 def box(): 3 plt.title('热度与排名盒图') 4 sns.boxplot(x='排名',y='热度', data=df) 5 box()
![]()
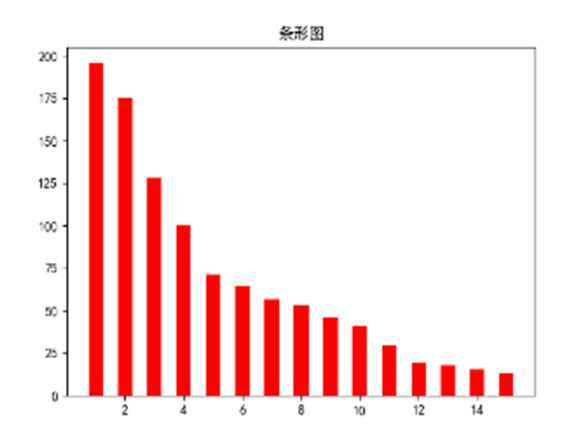
1 #绘制条形图 2 def bar(): 3 df = pd.DataFrame(pd.read_csv(('百度贴吧热搜榜.csv'))) 4 plt.bar(df.排名,df.热度,width = 0.5,align = 'center',color = 'r') 5 plt.title("条形图") 6 plt.show() 7 # bar()
![]()
1 9. 绘制标题词云图 2 #绘制词云图 3 def worldCold(): 4 text = '' 5 for line in df['标题']: 6 text += line 7 # 使用jieba模块将字符串分割为单词列表 8 cut_text = ' '.join(jieba.cut(text)) 9 10 color_mask = imread('白色.jpg') #设置背景图 11 cloud = WordCloud( 12 background_color = 'white', 13 # 对中文操作必须指明字体 14 font_path=r'simfang.ttf', 15 mask = color_mask, 16 max_words = 50, 17 max_font_size = 200 18 ).generate(cut_text) 19 20 # 保存词云图片 21 cloud.to_file('word_cloud.jpg') 22 plt.imshow(cloud) 23 plt.axis('off') 24 plt.show() 25 worldCold()
![]()

完整代码
1 # -*- coding: utf-8 -*- 2 3 # 导入爬虫所需要的包 4 5 import jieba as jieba 6 import requests 7 import bs4 8 import pandas as pd 9 from bs4 import BeautifulSoup 10 import numpy as np 11 import matplotlib 12 import seaborn as sns 13 from matplotlib import pyplot as plt 14 import re 15 from scipy.sparse import data 16 from wordcloud import WordCloud 17 import matplotlib.pyplot as plt 18 from imageio import imread 19 20 21 #获取页面数据 22 23 def getHtml(url): 24 #UA伪装 25 headers = { 26 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62' 27 } 28 #发起requsets请求 29 response = requests.get(url = url,headers = headers) 30 #获取页面数据 31 html_text = response.text 32 return html_text 33 34 35 # html解析 36 37 def htmlJs(html_text): 38 #使用BeautifulSoup工具对页面进行解析 39 soup = BeautifulSoup(html_text, 'lxml') 40 return soup 41 42 43 # 标签定位 44 45 def getTitle(): # 获取标题 46 #标题的位置在tbody标签下的tr标签中,使用select选择器 47 title_text = htmlJs(getHtml(url)).select('tbody > tr > .al > a') 48 return title_text 49 50 51 # 获取热度 52 53 def getRedu(): 54 # 热度的位置在tbody标签下的tr标签中的第三个td标签内部 55 redu = htmlJs(getHtml(url)).select('tbody > tr > td:nth-of-type(3)') 56 return redu 57 58 59 if __name__ == '__main__': 60 url = "https://tophub.today/n/Om4ejxvxEN" 61 getHtml(url) 62 # 存放获取到的标题 63 biaoti = [] 64 # 存放获取到的热度信息 65 hot = [] 66 # 将获取到的标题存放在biaoti数组中 67 for tit in getTitle(): 68 biaoti.append(tit.text) 69 # print(biaoti) 70 for rd in getRedu(): 71 # 用正则表达式筛选出热度的数字 72 num = re.findall('\d+\.\d+|\d+', rd.text) 73 # print(num) 74 hot.append(num[0]) 75 # print(hot) 76 77 # 对数据进行持久化 78 79 # 存储数据 80 81 shuju = [] 82 print("{:^10}\t{:^40}\t{:^25}".format('排名', '标题', '热度')) 83 # 将标题和热度存储到列表中 84 for i in range(15): 85 print("{:^10}\t{:^40}\t{:^25}".format(i + 1, biaoti[i], hot[i])) 86 shuju.append([i + 1, biaoti[i], hot[i]]) 87 88 # 将数据存储到表格里 89 90 df = pd.DataFrame(shuju, columns = ["排名", '标题', '热度']) 91 # df.to_csv('百度贴吧热搜榜.csv',index = False) 92 # print("保存成功!!!") 93 94 # 导入文件bar 95 96 # 删除无效效行 97 98 def drop(): 99 #标题是我们数据分析时用不到的,所以可以删除 100 df = pd.DataFrame(pd.read_csv("百度贴吧热搜榜.csv")) 101 drop = df.drop('标题', axis = 1, inplace = True) 102 print(drop) 103 # drop() 104 105 106 # 输出清除标题后的结果 107 108 print(df.head(20)) 109 110 111 # 查找重复值 112 113 def duplicate(): 114 df = pd.DataFrame(pd.read_csv("百度贴吧热搜榜.csv")) 115 print(df.duplicated()) 116 # duplicate() 117 118 119 #查找是否有重复值 120 121 def repeat(): 122 df = pd.DataFrame(pd.read_csv("泉州市楼房价格.csv")) 123 print(df.duplicated()) 124 125 # repeat() 126 127 128 # 查找是否有空值 129 130 def isnull(): 131 df = pd.DataFrame(pd.read_csv("百度贴吧热搜榜.csv")) 132 print(df['标题'].isnull().value_counts()) 133 print(df['热度'].isnull().value_counts()) 134 # isnull() 135 136 # 异常值的观察 137 138 def outliers(): 139 df = pd.DataFrame(pd.read_csv("百度贴吧热搜榜.csv")) 140 print(df.describe()) 141 142 # outliers() 143 144 145 # 查看相关系数 146 147 def correlation(): 148 print(df.corr()) 149 150 # correlation() 151 152 153 #载入绘图时需要的数字代码 154 155 plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文标签 156 plt.rcParams['font.serif'] = ['KaiTi'] 157 plt.rcParams['axes.unicode_minus'] = False 158 159 160 # 散点图 161 162 def sandian(): 163 df = pd.DataFrame(pd.read_csv('百度贴吧热搜榜.csv')) 164 x = df.排名 165 y = df.热度 166 plt.xlabel('排名') 167 plt.ylabel('热度') 168 plt.scatter(x, y, color = "red", label = "点", s = 50) 169 plt.title("排名与热度的散点图") 170 plt.legend(loc = 'best') 171 plt.show() 172 173 # sandian() 174 175 176 # 扇形图 177 178 def shanxing(): 179 df = pd.DataFrame(pd.read_csv('百度贴吧热搜榜.csv')) 180 x = df.排名 181 y = df.热度 182 # 前五名的学校名称 183 name = [x[0], x[1], x[2], x[3], x[4]] 184 math = [y[0], y[1], y[2], y[3], y[4]] 185 explode = [0.1, 0.1, 0.1, 0.1, 0.1] 186 plt.pie(math, labels = name, colors = ["r", "g", "c", "b", "y"], explode = explode) 187 plt.axis("equal") 188 plt.title("百度贴吧热板扇形图") 189 plt.show() 190 191 # shanxing() 192 193 194 # 折线图 195 196 # 排名与热度的折线图 197 198 def zhexian(): 199 df = pd.DataFrame(pd.read_csv('百度贴吧热搜榜.csv')) 200 x = df.排名 201 y = df.热度 202 plt.xlabel("排名") 203 plt.ylabel("热度") 204 plt.plot(x, y, color = "green", label = "折线") 205 plt.title("排名与热度的折线图") 206 plt.legend() 207 plt.show() 208 209 # zhexian() 210 211 212 # 线性关系图 213 214 def xianxing(): 215 df = pd.DataFrame(pd.read_csv(('百度贴吧热搜榜.csv'))) 216 sns.lmplot(x = "排名", y = "热度", data = df) 217 plt.show() 218 219 # xianxing() 220 221 222 # 回归直线的图 223 224 def huigui(): 225 df = pd.DataFrame(pd.read_csv(('百度贴吧热搜榜.csv'))) 226 # x,y为回归直线的排名和点击数 227 x = df.排名 228 y = df.热度 229 # X,Y为散点图的 230 X = df.排名 231 Y = df.热度 232 # 先定义所需要的数据 233 x_i2 = 0 234 x_i = 0 235 y_i = 0 236 # 计算出x,y的均值用mean() 237 q = x.mean() 238 w = y.mean() 239 for i in range(15): 240 x_i2 = x_i + x[i] * x[i] 241 x_i = x_i + x[i] 242 y_i = y_i + y[i] 243 # 运用回归直线的公式计算出所需要的值 244 # 分子 245 m_1 = x_i * y_i - 15 * q * w 246 # 分母 247 m_2 = x_i2 - 15 * q * q 248 # 斜率 249 k = m_1 / m_2 250 # 截距 251 b = w - q * k 252 x = np.linspace(0, 15) 253 y = k * x + b 254 print("斜率k=", k, "截距b=", b) 255 plt.figure(figsize = (6, 4)) 256 plt.xlabel('排名') 257 plt.ylabel('点击数') 258 plt.scatter(X, Y, color = "green", label = "散点", linewidth = 2) 259 plt.plot(x, y, color = "blue", label = "回归直线") 260 plt.title("回归直线图") 261 plt.legend() 262 plt.show() 263 264 # huigui() 265 266 # 绘制单核密度图 267 268 def singleCore(): 269 df = pd.DataFrame(pd.read_csv(('百度贴吧热搜榜.csv'))) 270 sns.kdeplot(df['热度']) 271 # singleCore() 272 273 # 绘制盒图 274 275 def box(): 276 df = pd.DataFrame(pd.read_csv(('百度贴吧热搜榜.csv'))) 277 plt.title('热度与排名盒图') 278 sns.boxplot(x = '排名', y = '热度', data = df) 279 # box() 280 281 282 #绘制条形图 283 284 def bar(): 285 df = pd.DataFrame(pd.read_csv(('百度贴吧热搜榜.csv'))) 286 plt.bar(df.排名,df.热度,width = 0.5,align = 'center',color = 'r') 287 plt.title("条形图") 288 plt.show() 289 # bar() 290 291 #绘制词云图 292 293 def worldCold(): 294 text = '' 295 for line in df['标题']: 296 text += line 297 # 使用jieba模块将字符串分割为单词列表 298 cut_text = ' '.join(jieba.cut(text)) 299 300 color_mask = imread('白色.jpg') #设置背景图 301 cloud = WordCloud( 302 background_color = 'white', 303 # 对中文操作必须指明字体 304 font_path=r'simfang.ttf', 305 mask = color_mask, 306 max_words = 50, 307 max_font_size = 200 308 ).generate(cut_text) 309 310 # 保存词云图片 311 312 cloud.to_file('word_cloud.jpg') 313 plt.imshow(cloud) 314 plt.axis('off') 315 plt.show()
四、总结(10分)
描述完成此项目得到哪些有益的结论?是否达到预期的目标?以及要改进的建议?
结论:可以较为熟练的运用python知识,学会了如何获取一个网站里自己想要的信息,掌握了爬虫的运行原理和使用。对我在python方面的学习有很大的帮助。
预期:达标
改进:有些网页的元素较为复杂,或者有相同的属性,导致结果会获得一些冗余的数据,使得数据清洗较为困难。之后会使用xpath解析对获取页面元素的代码进行优化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号