Jsoup爬取网页壁纸
前言
最近看着有几位小伙伴,在用爬虫,虽然之前也用过Python爬虫,但是java我没有用过,所以我也去学了一下。特此记录一下。
网页解析
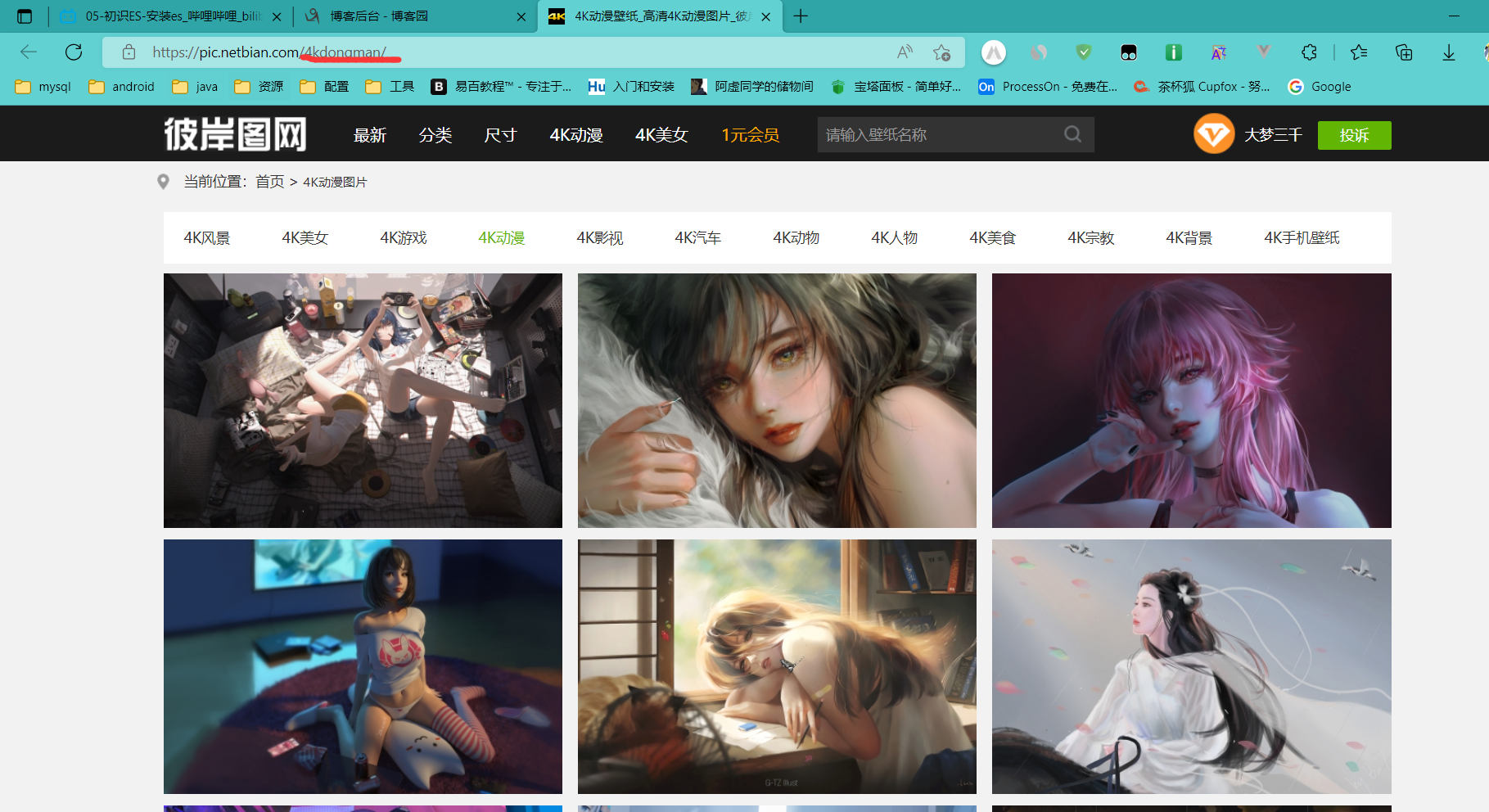
首先url的变化是这样的,第一页的页面url是这样的,其实的url的后缀都是index_加上.html形成的url
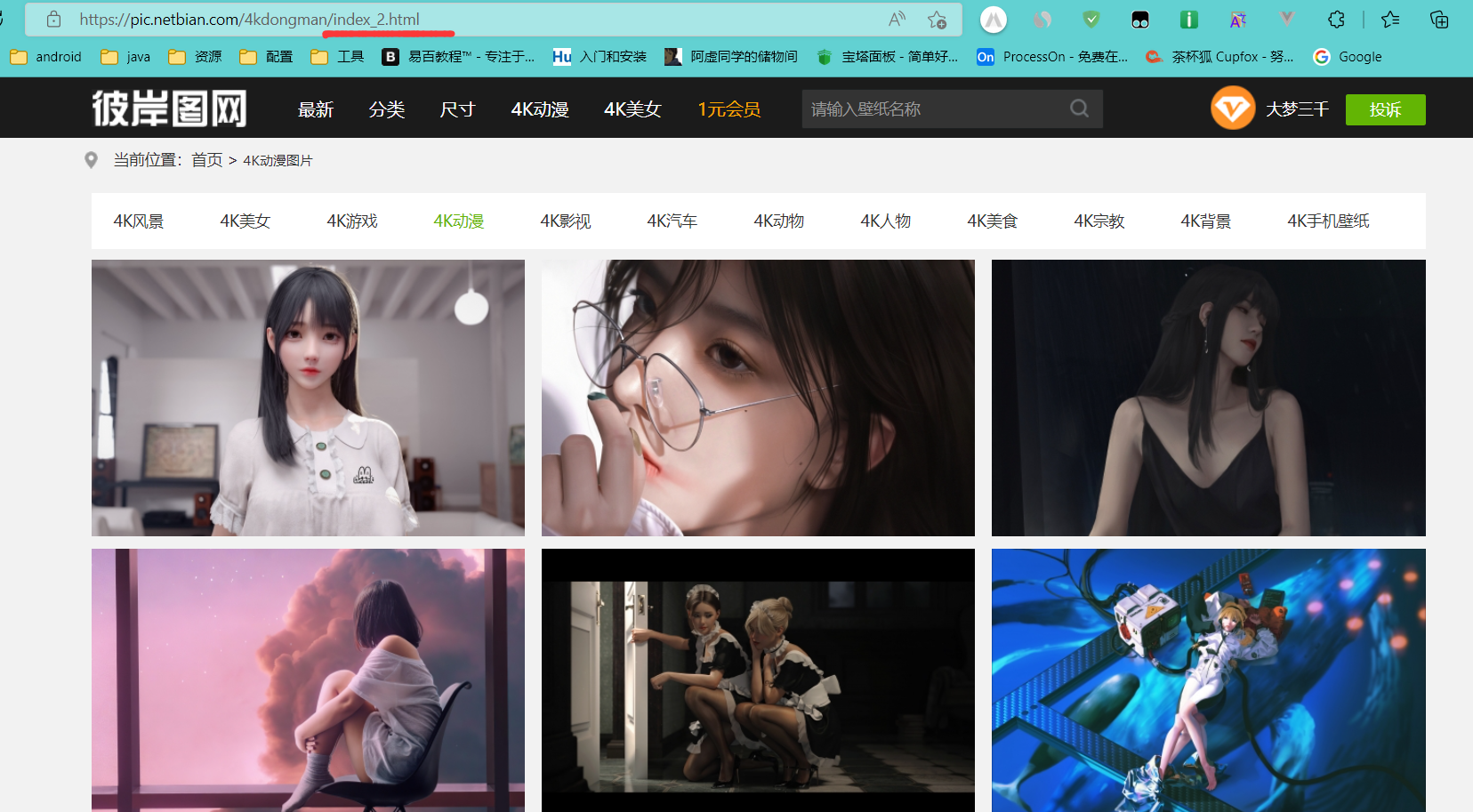
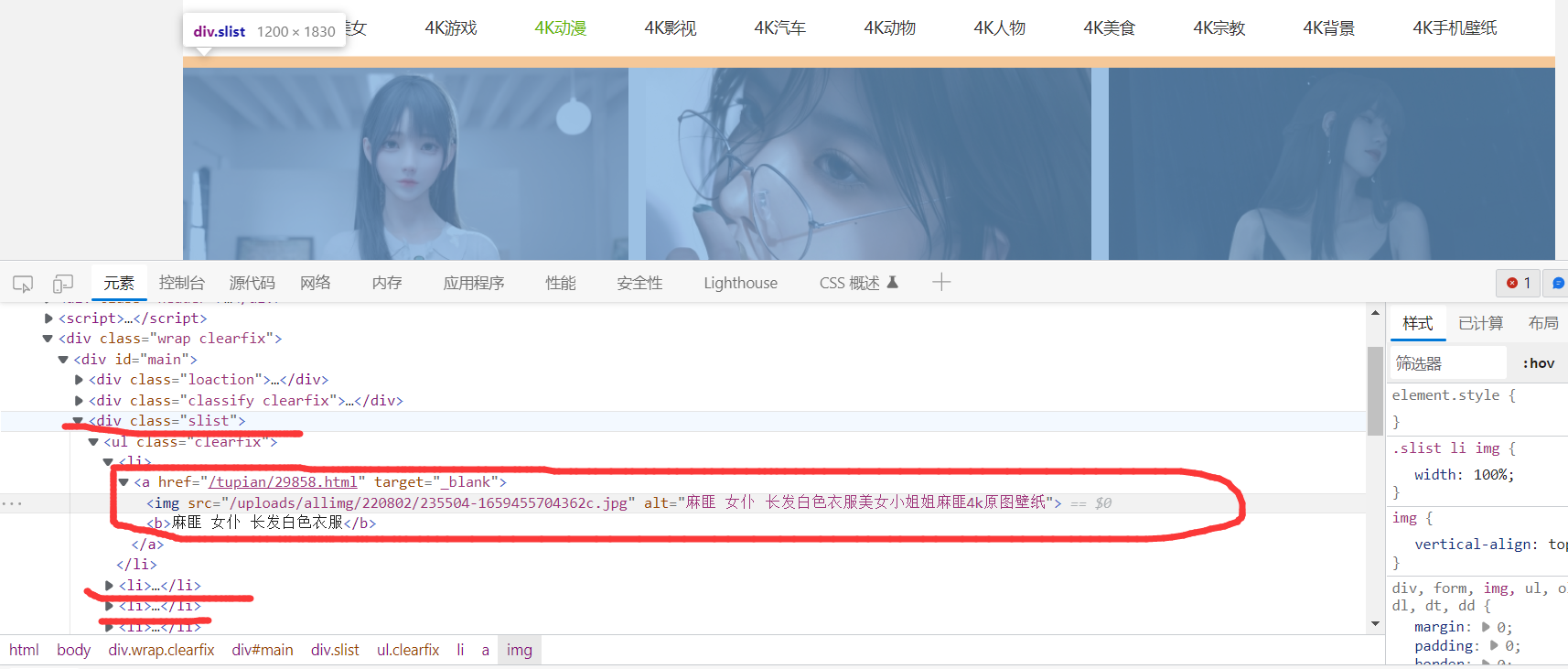
其次就是可以观察到slist这个类的div包含了所有的壁纸的信息,其中每个li就是对应的每个图片对应的信息,解析li标签中的img的路径即可。
引入依赖
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.24</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.12.0</version>
</dependency>
实体类对象
package com.mrs.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* description: WallPaper
* date: 2022/9/7 15:27
* author: MR.孙
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class WallPaper {
private String fileName;
private String imgUrl;
}
代码(这里手动传入页数):
package com.mrs.main;
import com.mrs.entity.WallPaper;
import com.sun.org.apache.xpath.internal.compiler.Keywords;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
/**
* description: GetWallPaper
* date: 2022/9/7 15:02
* author: MR.孙
*/
public class GetWallPaper {
public static void main(String[] args) throws Exception {
//传入页数
parseWallPaper(120);
}
public static void parseWallPaper(Integer pageNum) throws Exception {
String pages = "";
String url = "";//动漫url
//爬取每页的数据
for (int i = 1; i < pageNum; i++) {
pages = "index_" + i + ".html";
if (i == 1) {
url = "http://pic.netbian.com/4kdongman/";
List<WallPaper> wallPapers = parseHtml(url);
saveToLocal(wallPapers);
continue;
}
url = "http://pic.netbian.com/4kdongman/" + pages;
List<WallPaper> wallPapers = parseHtml(url);
saveToLocal(wallPapers);
}
}
private static List<WallPaper> parseHtml(String url) throws Exception {
List<WallPaper> wallPapers = new ArrayList<>();
try {
//使用Jsoup解析网页
Document document = Jsoup.connect(url)
.ignoreContentType(true)
.userAgent("Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1")
.timeout(12000)
.followRedirects(true)
.get();
// System.out.println(document.html());
Elements elements = document.getElementsByClass("slist");
Element element = elements.eq(0).first();
// System.out.println(element);
//获取所有的li标签
Elements li = element.getElementsByTag("li");
// System.out.println(li);
//解析li中的信息
for (Element elementLi : li) {
//获取图片名称
String fileName = elementLi.getElementsByTag("img").eq(0).attr("alt");
String imgUrl = "http://pic.netbian.com" + elementLi.getElementsByTag("img").eq(0).attr("src");
WallPaper wallPaper = new WallPaper();
wallPaper.setFileName(fileName);
wallPaper.setImgUrl(imgUrl);
wallPapers.add(wallPaper);
System.out.println("文件名:"+fileName);
System.out.println("图片地址:"+imgUrl);
}
}catch (Exception ex){
Thread.sleep(30000);
ex.printStackTrace();
}
return wallPapers;
}
public static void saveToLocal(List<WallPaper> wallPapers){
wallPapers.stream().forEach((wallPaper -> {
//壁纸路径
String imgUrl = wallPaper.getImgUrl();
//文件名
String suffix = imgUrl.substring(imgUrl.lastIndexOf("."));
String fileName = wallPaper.getFileName()+suffix;
try {
URL url = new URL(imgUrl);
URLConnection urlConnection = url.openConnection();
//获取url的输入流
InputStream inputStream = urlConnection.getInputStream();
//创建输出流
FileOutputStream outputStream = new FileOutputStream(new File("D:\\download\\wallpaper\\download\\" + fileName));
byte[] buf = new byte[1024 * 1024 * 1024];
int img = 0;
if((img=inputStream.read(buf))!=-1){
outputStream.write(buf,0,img);
System.out.println("图片->" + fileName + "下载完成");
}
} catch (Exception e) {
e.printStackTrace();
}
}));
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号