一、DevOps
编排:执行一系列预定的工作流。容器编排是指自动化容器应用的部署、管理、扩展和联网的一系列管控操作。
标准化 - 自动化 - Devops - AIops
ansible saltstack puppet 应用编排工具
Devops MicroServices Blockchain
docker compose docker swarm(调度) docker machine(初始化主机为docker使用的主机) --- 使用少
mesos 资源分配工具 marathon 使用少
kubernetes 容器编排工具 占据80%的市场份额 - 舵手, OpenShift = k8s发行版,提供Devops需要的一系列软件,资源。(paas平台即服务)
RKT 类似docker的容器。
设计 - 代码编写 - 构建 - 自动化测试 - 交付
CI 持续集成(代码编写提交后到交付给运维上线整个过程流水线完成,自动实现,没有人工干预)
CD 持续交付(Delivery)(在自动化测试完成后可以将项目打包提供出来)
CD 持续部署(Deployment)(交付后自动发布到线上去)
二、K8S架构介绍
1、k8s的特性:
自动装箱,自我修复,自动实现水平扩展,服务发现和负载均衡,自动发布和回滚
密钥和配置管理(基于同一个镜像运行不同配置的容器,容器去加载第三方配置中心的配置来启动服务。 ),存储编排(存储卷动态),批量处理执行
2、k8s环境架构
组合多台主机的资源统一对外提供存储等能力的集群。master/nodes(worker)
PS: 集群模型(p2p - redis,有中心节点的集群)
master (冗余3个)处理创建启动容器的请求,调度器分析现有资源的各状态,将其调度到对应节点
node 运行启动容器,管理容器。
etcd 共享存储,键值存储仓库,类似zk,存储集群对象的状态信息,用于配置共享和服务发现。需要两套ca证书:etcd内部通信,与api-server通信(restful风格:https)
3、组件:
来源:《https://blog.csdn.net/weixin_44296862/article/details/108138482》
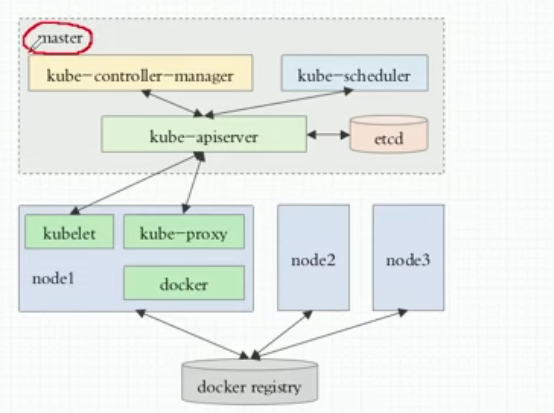
Kubernetes在架构上主要由Master和Node两种类型的节点组成,这两种节点分别对应着控制节点和计算节点。其中Master即控制节点,是整个Kubernetes集群的大脑,主要负责编排、管理和调度用户提交的作业,并能根据集群系统资源的整体使用情况将作业任务自动分发到可用Node计算节点。具体看Master节点主要由三个紧密协作的独立组件组合而成,它们分别是:
kube-apiserver:是Kubernetes集群API服务的入口,主要提供资源访问操作、认证、授权、访问控制及API注册和发现等功能机制。
kube-scheduler:负责Kubernetes的资源调度,能按照预定的调度策略将Pod调度到相应的机器上。
kube-controller-manager:负责容器编排及Kubernetes集群状态的维护,例如故障检测、自动扩展、滚动更新等。
需要说明的是,上述组件在工作状态下还会产生许多需要进行持久化的数据,这些数据会通过kube-apiserver处理后统一保存到Etcd存储服务中。所以从这个角度看kube-apiserver不仅是外部访问Kubernetes集群的入口,也是维护整个Kubernetes集群状态的信息中枢。
而在Kubernetes计算节点中,除了上述3个系统组件外,其他基本与Master节点相同,而其中最核心的部分就是kubelet组件。它的核心功能具如下:
通过CRI(Container Runtime Interface)远程接口同容器运行时(如Docker)进行交互,对容器生命周期进行维护。其中CRI接口会定义了容器运行时的各项核心操作,例如启动容器所需的命令及参数等。
通过GRPC协议同Device Plugin插件交互,实现Kubernetes对宿主机物理设备的管理。
此外kubelet另一个重要的功能则是通过CNI(Container Networking Interface)来调用网络插件为容器配置网络,以及通过CSI(Container Storage Interface)和存储插件交互为容器配置持久化存储。
master组件:
kube-apiserver:接收,解析,处理请求
kube-scheduler:调度容器创建的请求,根据用户请求创建容器所需的最低资源,确定合适的节点node; 两级评选(筛选哪些节点符合;在符合节点中优选,由调度算法的优选算法决定)
kube-controller-manager 控制器管理器:保证控制器的正常运行,控制器确保已创建的pod为健康状态。(容器控制器,可用性探测机制,持续性探测,确保容器运行状态为用户所期望的,当pod状态不符合期望,进行处理,比如node宕机,在其他node上重建)除了容器控制器,还有其他类型的控制器。
addons插件:
CoreDNS
网络插件(flannel calico)
用户UI(kube-danshboard)
监控(prometheus grafana)
日志收集(ElasticSearch Kibana)
......
node组件:
kubelet 负责确保容器始终处于运行状态。管理已分配给node的pod,Pod对应的容器的创建启停等。
kube-proxy:K8S Service的通信负载均衡,Kube-proxy是一个简单的网络代理和负载均衡器,它的作用主要是负责Service的实现,具体来说,就是实现了内部从Pod到Service和外部的从NodePort向Service的访问,每台机器上都运行一个 kube-proxy 服务,它监听 API server 中 service 和 endpoint 的变化情况,并通过 iptables 等来为服务配置负载均衡(仅支持 TCP 和 UDP)。
docker
fluentd 日志收集工具
4、基础概念
pod:k8s中最小的可操作的单元。一个pod中可运行多个容器,这些多个容器共享同一个namespace(net,uts,ipc) (user,pid,)的namespace互相隔离,并且共享同一个存储卷,存储卷不属于容器,属于pod。一般来说,一个pod 内只放一个容器。
Label(标签) Label selecter(标签选择器)
![]()
![]()
Pod:自主式pod,控制器管理的pod。有生命周期的对象
pod控制器:确保不同类型的应用支持符合人们期望的方式进行运行。pod数量精确符合人的期望;滚动更新容器;支持回滚
ReplicationController --> ReplicaSet ---声明式更新的控制器 deployment(管理无状态的应用) statefulSet(管理有状态的应用)
DaemonSet(守护进程) cronjob(时间不固定的操作,根据job运行状态)
HPA(HorizontalPodAutoscaler自动伸缩控制器,二级pod控制器)根据资源使用率,自动增加或减少pod。
提供相同服务的pod 与客户端之间的中间层service 为固定的,service不会变,不会删除,提供稳定的功能,也有调度作用。service 关联后端的pod不是根据ip地址或主机名,是根据label来关联后端的pod的,关联后动态探测后端的ip等信息。service手动创建,可创建为集群内部访问,也可创建为共有访问。
service 名可以解析为service的ip,需要dns来解析。service的地址仅存在于集群内部。
AddOns:附件,k8s自身运行需要的pod,基础性服务。dns算一种,动态删除,动态创建,动态更新,假如手动改了service的名字,dns会自动更新解析记录。
service 转发后端pod用的是端口代理(dnat),1.0为iptables,目前为nat模型的ipvs,用户可指定调度算法,提高了调度性能。
监控系统:prometheus + grafana 也应该运行成pod
k8s名称空间:一类pod运行在一类空间中,管理的边界。
Pod的不同阶段:
Pending:写数据到etcd,调度,pull镜像,启动容器四阶段之一
Running:Pod已绑定在NOde,并且所有容器正常启动,或者至少一个容器在运行或重启
Succeeded:所有容器已经全部正常自行退出并且k8s永远不会重启
Failed:所有容器已经停止,至少有一个容器终止于失败,非正常退出。
Unknown:通常由于与运行Pod的Node通信错误。
k8s中的常用资源对象:
Deployment、event、Endpoint、Job、Pod、Secret、Service、ResourceQuota、Node、Namespace等
三、客户端管理工具kubectl
kubectl是通过master上的api-server对集群上的资源进行管理(唯一入口),有很多的子命令。
节点 增加污点(taints)与高级调度相关,能容忍污点的pod才能被调度到节点上。master上有很多的污点,其他pod都不能容忍,保证master上只运行api-server,scheduler等几个重要资源。
创建pod:(nginx-deploy为deployment控制器的名字)
kubectl run --help 查看创建命令帮助
kubectl run nginx-deploy --image=nginx:1.14-alpine --port=80 --replicas=3 --dry-run=true
kubectl get deployment -o wide
kubectl get pods --show-labels -n kube-system -o wide
kubectl describe deployment nginx-deploy
创建service:
kubectl expose --help
kubectl expose deployment nginx-deploy --name=nginx --port=80 --target-port=80 --protocol=TCP
kubectl get service 或 kubectl get svc
kubectl get pods -n kube-system -o wide
kubectl describe svc nginx
kubectl edit service nginx #编辑service资源
kubectl delete svc nginx #删除名为nginx的这个service
kubectl scale --help 动态扩展pod数量(可增可减)
kubectl scale --replicas=5 deployment nginx
kubectl set image --help # 改变容器用的镜像的版本,滚动更新
kubectl describe pods pod_name #查看容器的名称等信息
kubectl set image deployment myapp myapp=ikubernetes/myapp:v2 #更新名为myapp的deployment控制器下容器名为myapp的镜像版本为ikubernetes/myapp:v2
kubectl rollout status deployment myapp #查看myapp的deployment 的更新过程
kubectl rollout undo --help #回滚版本
kubectl rollout undo deployment myapp #回滚myapp控制器的版本

 浙公网安备 33010602011771号
浙公网安备 33010602011771号