【故障公告】再次出现数据库 CPU 居高不下的问题以及找到了最可能的原因
非常非常抱歉,今天上午的故障又一次给大家带来麻烦了,再次恳请大家的谅解。
在昨天升级阿里云 RDS SQL Server 实例的配置后(详见昨天的博文),万万没有想到,今天上午更高配置的阿里云 RDS 实例依然出现了 CPU 居高不下的问题。
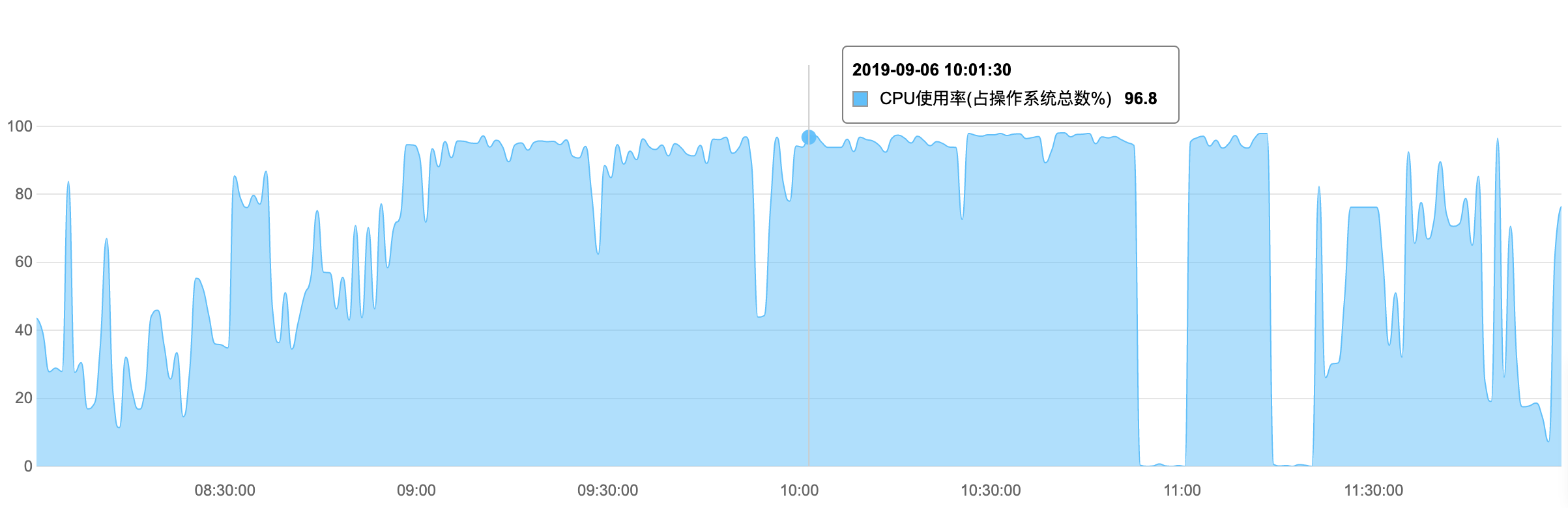
在数据库 CPU 高的情况下,有时对访问速度影响不大,有时巨慢无边,在今天上午的故障期间,我们通过2次主备切换才恢复了正常。
下午,我们我们调整了服务器的部署,用了更多服务器进行混合部署(docker-compose与docker swarm),情况有了明显改善。
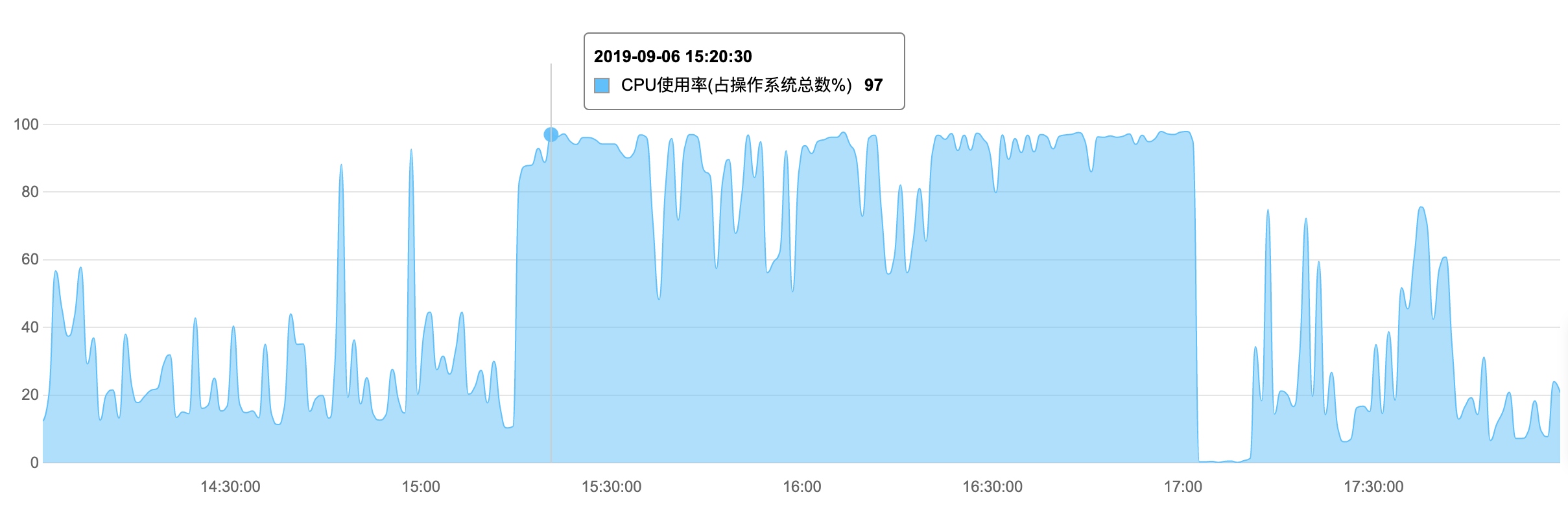
但是,15:15 开始数据库 CPU 又飚了上去,但访问速度没有受到明显影响,一致坚持到 16:50 左右,在扛不住的时候,我们再次通过主备切换恢复了正常。
这次恢复正常后,我们才突然想到,数据库每天一大早会跑一个整理索引碎片的任务,是不是升级后这个任务不能正常执行了?打开 SSMS 一看,果然是。
昨天因为升级 SQL Server 后重建备库,整理索引碎片任务失败了。
Date 9/5/2019 06:30:00 Log Job History (Reorganize Index) Step ID 1 Server SD39184A Job Name Reorganize Index Step Name Reorganize Index Duration 00:00:00 Sql Severity 14 Sql Message ID 927 Message Executed as user: xxx. Database 'xxx' cannot be opened. It is in the middle of a restore. [SQLSTATE 42000] (Error 927). The step failed.
今天不知什么原因整理索引碎片的任务也失败了。
Date 9/6/2019 06:30:00 Log Job History (Reorganize Index) Step ID 1 Server SD39184A Job Name Reorganize Index Step Name Reorganize Index Duration 00:00:00 Sql Severity 14 Sql Message ID 954 Message Executed as user: xxx. The database "xxx" cannot be opened. It is acting as a mirror database. [SQLSTATE 42000] (Error 954). The step failed.
CPU 高的问题很可能就是索引碎片没有被及时整理引起的,是否真的是这个原因,要等下周的访问高峰才能得到验证。
对于升级后整理索引碎片任务失败的问题,我们向阿里云提交工单后,阿里云建议我们先关闭 mirror database 。
alter database 库名 set partner off
目前我们没有采用这个建议,还在考虑更好的解决方法。
【更新】
7:40 非常奇怪,今天凌晨负载极低的时候,阿里云 RDS 实例竟然也出现了 CPU 居高不下的问题,而且 CPU 近 100% 。
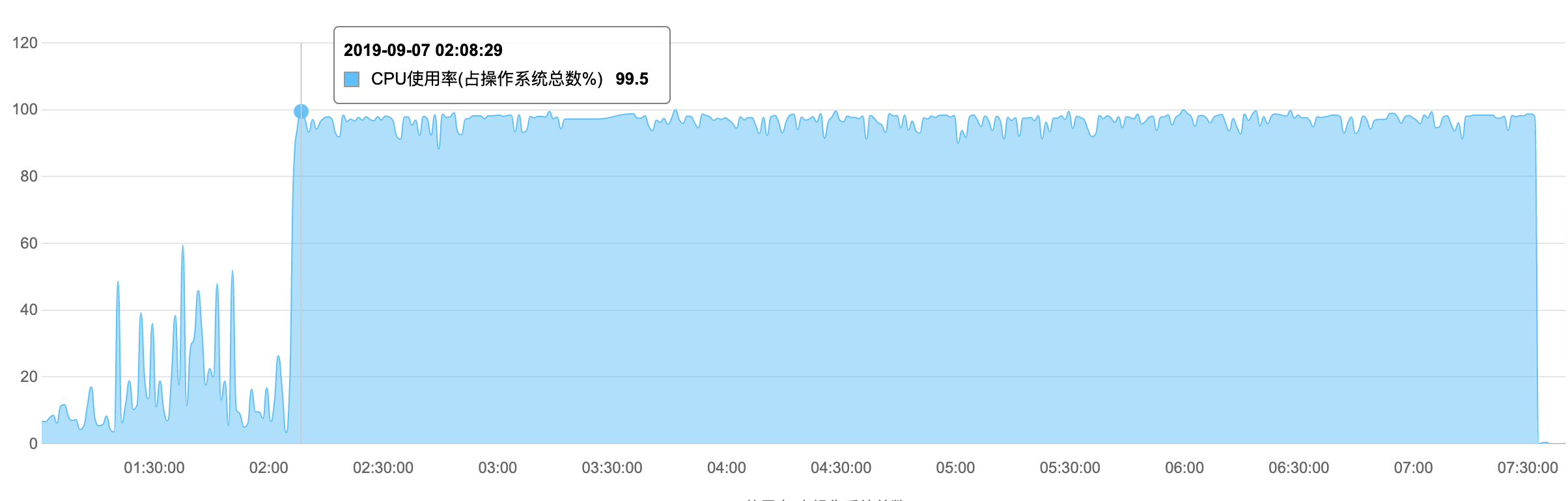
主备切换后才恢复正常。
8:30 手动完成了索引碎片的整理。
9月10日更新:经后来的验证,CPU 高的确是索引碎片引起的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号