

云计算之路-黎明前的黑暗:20130424网站故障经过
一、背景
4月18日的访问高峰扛过去之后,我们和阿里云一直在努力寻找问题的真正原因。是问题,躲不去的,不找到根源,随时会突然袭击。
压力测试未能重现问题,只能进行大海捞针般的猜测:SLB(均衡均衡)、Web服务器(虚拟机)、应用程序、缓存服务器(虚拟机)、SLB与Web服务器之间的网络通信,Web服务器与缓存服务器之间的网络通信、Web服务器与RDS(关系型数据库服务)之间的网络通信?
我们怀疑的对象是:SLB(请求分配有问题)、SLB与Web服务器之间的网络通信(TCP连接)、VM与RDS之间的网络通信(TCP连接)。
阿里云怀疑的对象是:我们的应用程序、缓存服务器。
对于我们怀疑的对象,我们没有任何侦测手段,只能将我们的怀疑抛给阿里云。
对于阿里云怀疑的对象,我们一万个不认同应用程序会引起这个问题(应用程序的问题不会引起SLB中的所有Web服务器同时出问题)。对于缓存服务器,存在可能,但我们没有特别重视。因为在之前出问题期间,缓存的命中率在正常范围,即使缓存服务器down掉,也会直接走RDS,访问速度也不会有大的影响。我们有两种类型的缓存服务器memcached与NoSQL,都用的是couchbase。阿里云建议我们memcached与NoSQL都进行负载均衡,昨天我们只对NoSQL进行了负载均衡(负载比较高)。并将memcached与NoSQL客户端的连接超时设置修改为1秒,也就是说只要缓存服务器有问题,1秒钟连接超时后就会直接走RDS从数据库中获取数据。具体设置如下:
<couchbase> <servers bucket="default"> <add uri="http://ip1:8091/pools" /> <add uri="http://ip2:8091/pools" /> </servers> <socketPool minPoolSize="20" maxPoolSize="200" connectionTimeout="00:00:01" deadTimeout="00:00:02" /> </couchbase> <enyim.com> <memcached protocol="Binary"> <servers> <add address="ip1" port="11211" /> </servers> <socketPool minPoolSize="20" maxPoolSize="200" connectionTimeout="00:00:01" deadTimeout="00:00:02" /> </memcached> </enyim.com>
今天出故障之前,服务器的部署情况是:SLB+4台Web服务器+1台Memcached服务器+2台NoSQL服务器+RDS。
二、故障经过
上午出现了波动情况,见下图(负载均衡中波动最严重的一台)
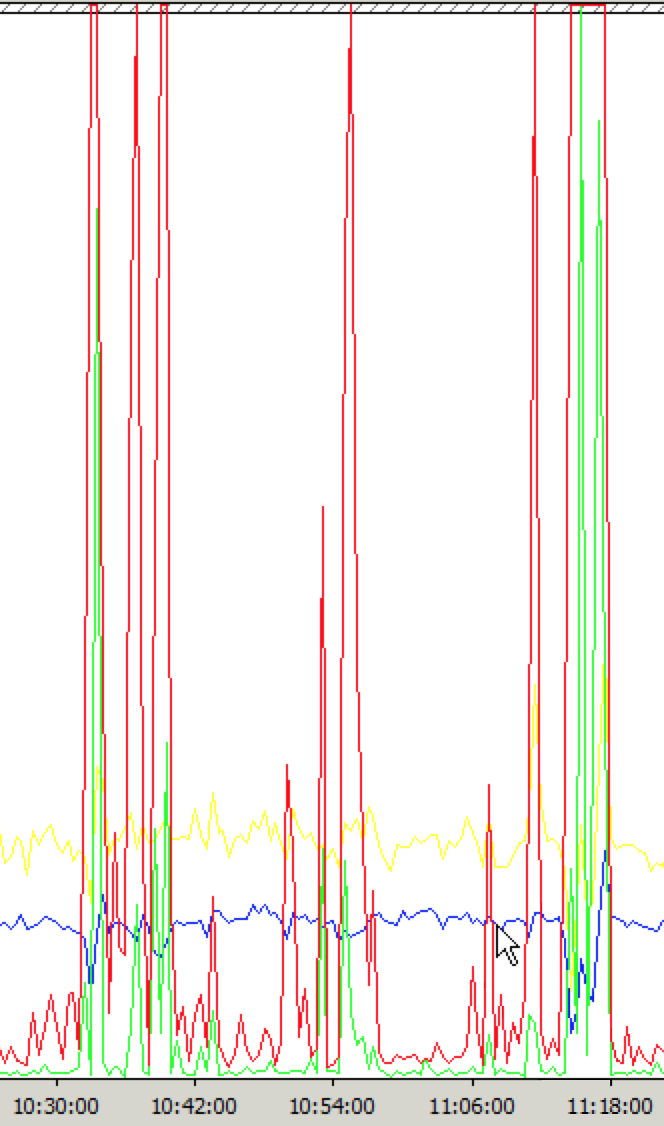
(红色曲线是博客IIS站点的Current Connections,绿色曲线是ASP.NET的Reqeust Execution Time)
下午2点开始,故障开始全面爆发,Windows性能监视器中的表现是Current Connections急剧增加、Reqeust Execution Time严重变慢、Requests/s大大减小。
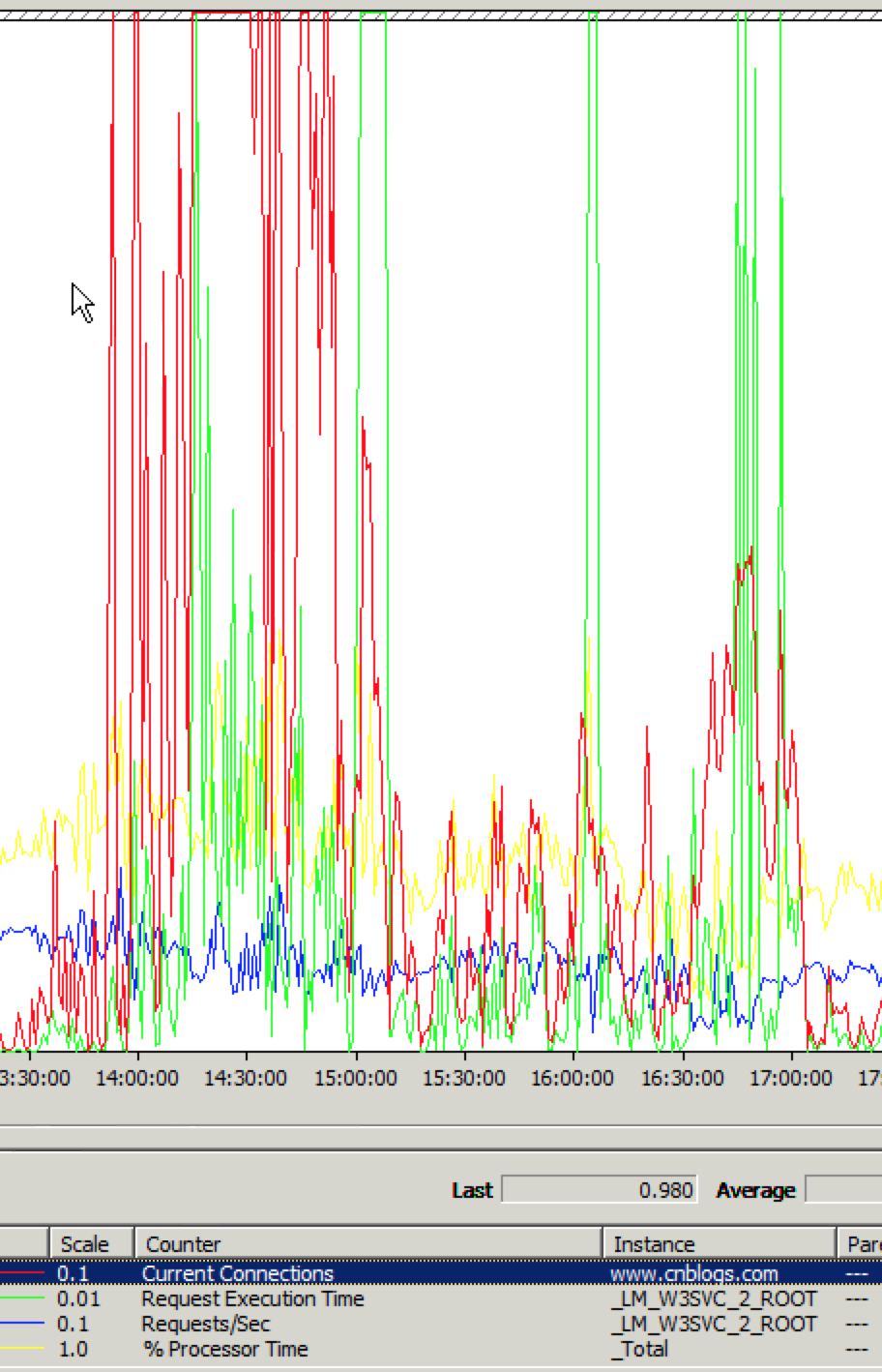
当时采取的解决方法是向负载均衡中增加云服务器,如果加云服务器能解决问题,那就说明是云服务器的负载能力问题。但是加了后发现,刚加之后有些缓解,但很快就故障如初。
后来采取限制每台云服务器的IIS的并发连接数缓解故障的影响面。如果不限制,大家都无法正常访问;限制之后,未被拒绝的请求的访问速度会好些,但被拒绝的请求会出现503错误。在正常期间,来自SLB的并发连接在100以内,但故障期间并发连接在1000之上(因为很多请求得不到正常响应,连接越积越多),我们将IIS的最大连接限制在500才缓解了故障。
但后来即使Current Connections在200多,访问速度也很慢。我们继续加云服务器,有1台云服务器一上去,500的连接限制立即跑满。我们当时还以为是SLB分配请求有问题,实际是SLB给云服务器的请求得不到响应,像堵车一样堵在那,越堵越多。
期间,阿里云技术人员发现memcached那台云服务器磁盘IO高(这也是奇怪情况,memcached只在内存中进行缓存),问题可能与memcached服务器有关,但从couchbase控制台看memcached的缓存命中率正常。我们在一台Web服务器上试了不走memcached,但从测试情况看,那台服务器的响应速度还是慢(可能当时是因为很多请求继续在那堵着)。
后来,阿里云技术人员发现memcached那台云服务器内网接口流量波动很大(这个监视数据我们看不到)。
于是,我们想到重启memcached服务器(操作系统是CentOS 6.2 64位)试试。结果reboot命令发出不久(17:00左右),故障竟然消失了,Current Connections立即下降,打开网站速度飞快(在memcached服务器重启阶段,memcached客户端连接超时,程序会直接从数据库取数据)。等memcached服务器启动好之后,故障又立即出现。
于是,我们关闭那台memcached服务器,故障又立即消失。然后重新购买了一台云服务器,操作系统是CentOS 6.3 64位,安装同样版本的couchbase,切换上去,故障没有出现。网站就这么恢复了正常。晚上我们又加了一台memcached服务器,用2台组建了负载均衡。
忙完之后,就写了这篇博客。
我们已经无颜向大家道歉了,我们只有一个选择:全力以赴彻底解决这个问题,战胜困难,度过难关!
故障原因分析见:云计算之路-柳暗花明:为什么memcached会堵车

 浙公网安备 33010602011771号
浙公网安备 33010602011771号