
再学串串(三):被构造自动机上计数 DP 题吓晕
过去的章节
:::info[关于上一篇文章内容的补充]
设 \(n\) 个模式串长度为 \(len_i\),\(q\) 个文本串长度为 \(m_i\)。
如果用哈希做的话,录入模式串的复杂度为 \(O(\sum len)\),查询复杂度为 \(O(\sum m + nq)\)。
Trie 构造的复杂度还是 \(O(\sum len)\),但是查询的复杂度降到了 \(O(\sum m)\)。
所以 Trie 相比于哈希做法的优势一般只有在插入和查询字符串的数量较多时才能体现。
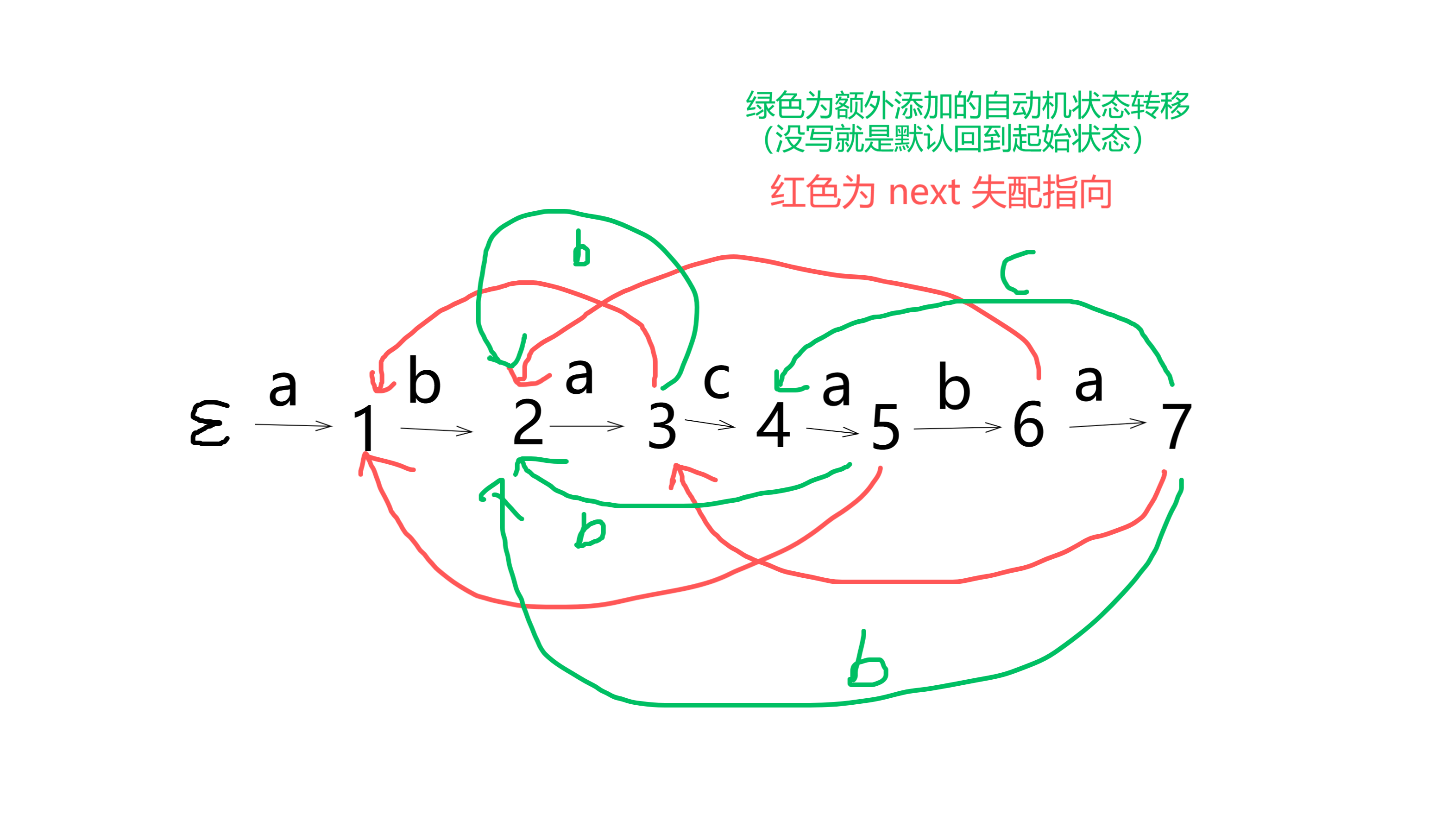
此图中忽略了 \(next\) 失配指向 \(\epsilon\) 的情况,因此漏掉了部分状态转移。读者可仿照 AC 自动机 \(\delta(x,c)\) 转移函数和 \(fail\) 指针构造的方式自行补全。
并且 \(5\to 2\) 的部分出现了不该出现的转移,添加 \(\texttt{b}\) 时应转移到 \(6\)。
失配树 其实和 AC 自动机中 \(fail\) 指针统计的内容类似。一般只需要求当前文本串 \(T\) 后缀与模式串 \(S\) 的最大公共前缀时用 \(T\) 跑 \(S\) 的 KMP 自动机即可,但如果要求所有的公共前缀就需要用到失配树的内容。
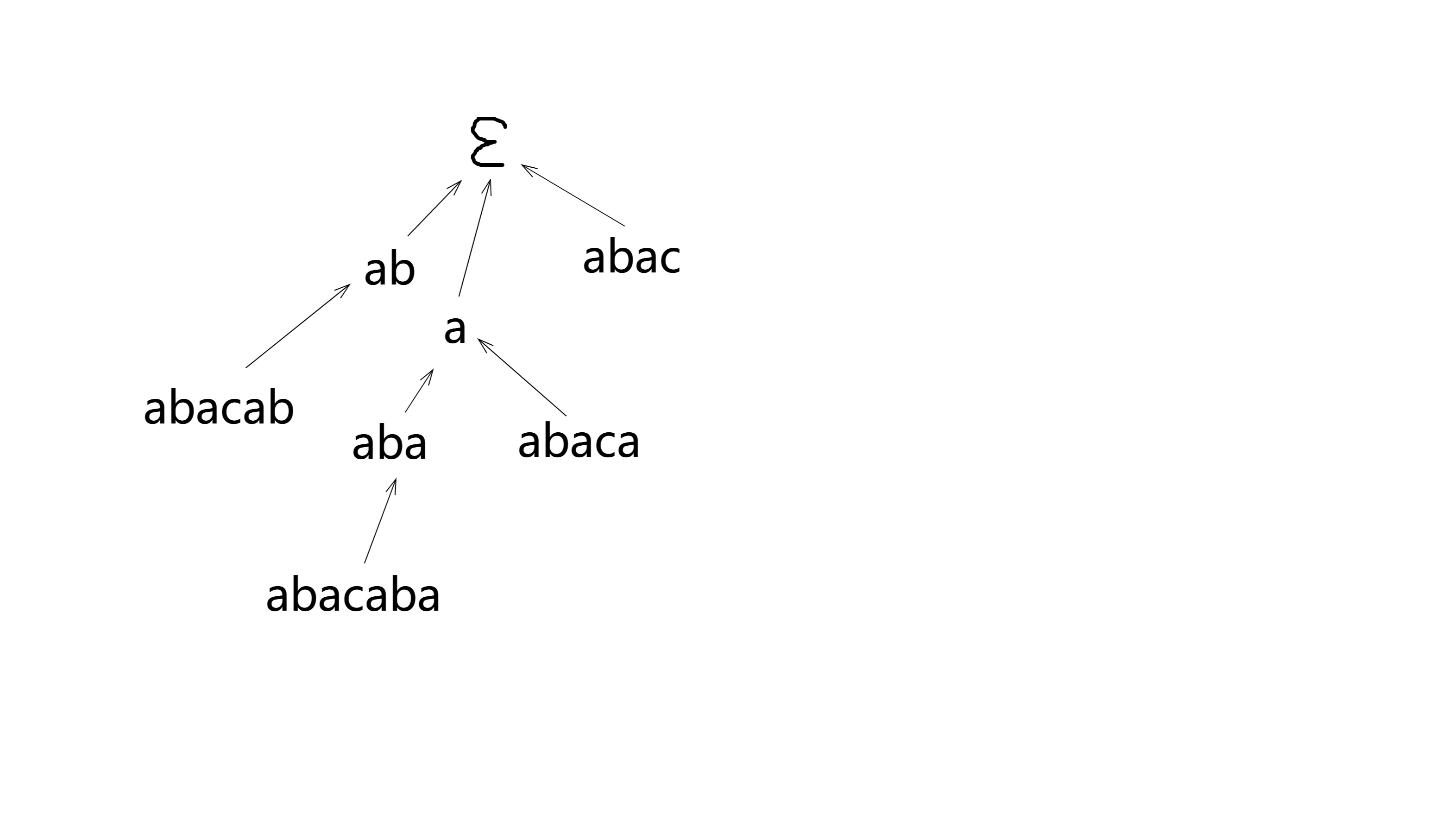
图中 KMP 自动机运行到对应 \(\texttt{abaca}\) 的状态(即 \(5\)) 时,通过失配树即可看出还有 \(\texttt{a}\) 为 \(S\) 后缀与 \(T\) 的公共前缀。
对于一些计数题(如下文的例题),还可以通过一个状态在失配树对应的深度方便地求出一共有多少公共前缀。
关于失配树的构造:平凡地,将所有前缀对应一个点,以 \(next\) 数组[1]为树边建树即可。
:::
第三站:KMP 自动机上 DP
状态转移这个词在动态规划相关内容中出现频率也相当高。这并不是巧合。事实上,很多时候建模一个自动机的目的就是为了在上面进行动态规划。
对于不同的题目,DP 的方式往往不同,因此本篇内容会以讲解例题为主。
P14874 [ICPC 2020 Yokohama R] Suffixes may Contain Prefixes
第一眼看上去求后缀与另一串的最长公共前缀长度可能会想到扩展 KMP[2],但注意到是要从一开始构造一个字符串 \(S\) 所以还是要用 KMP 自动机加 DP。
注意到一个串 \(S\) 对 \(T\) 的得分事实上等价于所有为 \(T\) 前缀的 \(S\) 的子串数量,本题实际计数。
考虑状态设计。容易发现往后加一个字符 \(c\) 时相当于所有后缀同时加了一个字符 \(c\) 并且额外添加了一个后缀 \(c\),因此至少需要一维表示已构造的长度,还需要一维表示在 KMP 自动机的状态,总共二维。
由此设计 DP 状态 \(f_{i,j}\) 表示目前已构造 \(S[1,i]\),\(S[1,i]\) 对应在 \(T\) 的 KMP 自动机的状态为 \(j\) 上时的最大可能得分。
因为往后增加一个字符 \(c\) 时不会影响之前的子串,因此只需要考虑当前新增的子串,即 \(S'=S+c\) 的所有后缀。
如何求出中所有为 \(T\) 前缀的 \(S'\) 后缀数量?使用 失配树 相关内容即可。新增的贡献即为经过 \(c\) 到达的状态 \(\delta(j,c)\) 在失配树上的深度。
:::info[转移方程]
\(\delta(j,c)\) 为 \(T\) KMP 自动机上的状态转移函数。
:::
注意:
- DP 时要注意判断转移是否合法。
- 最后统计的时候要算上所有最后在 \(T\) KMP 自动机上状态的情况取最大值。
:::success[Accepted]
#include<bits/stdc++.h>
using namespace std;
const int maxn = 2000;
string S;
size_t nxt[maxn + 1][26], fails[maxn + 1], depin_fail[maxn + 1], n;
void get_fail()
{
depin_fail[0] = 0;
// 0 状态为为匹配字符 S[0,0] 匹配成功后为状态 1
// fails[0] 未定义
for(int i = 0; i < n; i++)
{
for(int k = 0; k < 26; k++)
{
if(S[i] - 'a' == k)
{
nxt[i][k] = i + 1; // 进到下一个状态
fails[i + 1] = (i ? nxt[fails[i]][k] : 0);
depin_fail[i + 1] = depin_fail[fails[i + 1]] + 1;
}
else nxt[i][k] = (i ? nxt[fails[i]][k] : 0);
}
}
for(int k = 0; k < 26; k++)
{
nxt[n][k] = (n ? nxt[fails[n]][k] : 0);
}
}
size_t m; // 子弹字符串的长度
size_t f[maxn + 1][maxn + 1], ans;
int main()
{
cin.tie(nullptr)->sync_with_stdio(false);
cin >> S >> m;
n = S.size();
get_fail();
memset(f, 0x3f, sizeof f);
f[0][0] = 0;
for(size_t i = 0; i < m; i++)
{
for(size_t j = 0; j <= n; j++)
{
if(f[i][j] == 0x3f3f3f3f3f3f3f3f)
{
continue;
}
for(size_t c = 0; c < 26; c++)
{
auto new_state = f[i][j] + depin_fail[nxt[j][c]];
if(f[i + 1][nxt[j][c]] == 0x3f3f3f3f3f3f3f3f || f[i + 1][nxt[j][c]] < new_state)
{
f[i + 1][nxt[j][c]] = new_state;
// cout << i + 1 << ' ' << nxt[j][c] << ' ' << f[i + 1][nxt[j][c]] << endl;
if(i + 1 == m && ans < f[i + 1][nxt[j][c]])
{
ans = f[i + 1][nxt[j][c]];
// cout << "get_new_ans" << endl;
}
}
}
}
}
cout << ans << endl;
return 0;
}
:::
P15650 [省选联考 2026] 摩卡串 / string
唉,邦邦,唉唉。
被构造自动机上计数 DP 题吓晕。
转移大致思路跟上一道题一样,每次添加一个字符接着考虑所有新增的后缀;不同之处在于上一题是伪装成最优化的计数,这道题直接是个伪装成 DP 的搜索。
先设想构造一棵无限大的,包含所有字符集允许的字符串的字典树,字符集 \(\Sigma=\{0,1\}\)。(仅为抽象数学模型,不需要真的建一个)那么摩卡串 \(t\) 必然在这一个字典树的某个位置上,只需要从该字典树根节点开始 BFS 必然能找到最短的 \(t\)。(不明白为什么的回去补习 BFS)
但是,现在有两个问题摆在眼前:
- BFS 时不可能存下当前所有的 \(t\)。
- 挨个检验 \(t\) 是否为摩卡串太耗时了。
这两个问题实际上可以用一句话给出解决思路:明白转移 需要 什么,而 不需要 什么。
判定 \(t\) 是否是摩卡串需要回答的问题只有两个:
- \(s\) 是 \(t\) 的子串吗?
- \(t\) 中有多少个子串的字典序小于 \(s\)?
真正被 需要 的只有回答这两个问题 需要 的信息。不能帮助回答这两个问题的则是 不需要 的。
前一个问题的解决是平凡的,只需要在维护 \(t\) 目前在 \(s\) KMP 自动机上的状态以及 \(t\) 中是否曾出现过 \(s\) 即可。
后一个问题的解决可能会有一点棘手。
考虑当前已经知道了 \(t\) 中有 \(k\) 个子串的字典序小于 \(s\),考虑多加一个字符 \(c\in \Sigma\) 会对其产生什么影响。
加字符必不会影响原本的子串,因此 \(k\) 是只增的,设增加量为 \(\Delta k\)。原 \(t\) 加上 \(c\) 构成的新串 \(t'\) 的每个后缀[3]中字典序小于 \(s\) 的数量即为 \(\Delta k\)。
分析 \(\Delta k\) 中字典序小于 \(s\) 的字符串的组分:
- 某一位的字符的字典序小于 \(s\) 的对应字符。
- \(s\) 的真前缀。
第一种情况对于本题具体地说,即前面一部分是 \(s\) 的真前缀,而后面一位为 \(0\),\(s\) 对应的位置为 \(1\)。
第二种情况依旧按 \(t'\) 后在 \(s\) KMP 自动机上的状态用 失配树 解决,仅需注意这里不包含 \(s\) 本身,需要特判。
再回看到第一种情况。
这第一种情况又可以分成两种情况:
(a) 前面这一部分 \(t\) 的后缀属于第二种情况,\(c=0\),\(s\) 这一位为 \(1\)。
(b) 前面这一部分 \(t\) 的后缀就属于第一种情况。
所以还需要存 \(\Delta k\) 中第一种情况的串有多少个。
然后分类讨论状态转移做就可以了!
:::info[状态转移]
设当前状态为 \((i,j,k,0/1)\),即 \(t\) 在 \(s\) KMP 自动机上的状态为 \(i\),\(\Delta k\) 中有 \(j\) 个第一种情况,\(t\) 中有 \(k\) 个子串字典序小于 \(s\),\(t\) 中是否曾经出现过 \(s\)。
又设转移到的下一个状态为 \((i',j',k',0/1)\),转移字符为 \(c\)。
\(0/1\) 是容易转移的,初始取 \(0\),在 \(i'\) 为 \(s\) KMP 自动机的接受状态时取 \(1\),其他时刻保持不变即可。
\(cnt_i\) 表示的是 \(i\) 状态的失配树上有多少祖先(包括 \(i\) 自身) \(fa\) 满足 \(\delta(fa,1) = fa+1\),用以统计第一种情况的 (a) 分支发生的次数。
:::
最后要输出 \(t\),但由于是在一个虚拟的字典树上跑的,因此只需要存储每个转移的前驱节点和转移的字符,相比于直接存储所有的 \(t\) 省下了大量的空间!代价是需要记录之前的所有状态所以编码会麻烦一点。
:::success[Accepted]
#include<bits/stdc++.h>
using namespace std;
const int maxn = 200;
string s;
size_t n, moca; // n 表示 s 长度,moca 摩卡串要求 moca 个子串严格小于 s
size_t nxt[maxn + 1][2], fails[maxn + 1], depin_fail[maxn + 1], cnt[maxn + 1];
void get_fail()
{
depin_fail[0] = 0;
// 0 状态为为匹配字符 S[0,0] 匹配成功后为状态 1
// fails[0] 未定义
for(size_t i = 0; i < n; i++)
{
for(int k = 0; k <= 1; k++)
{
if(s[i] - '0' == k)
{
nxt[i][k] = i + 1; // 进到下一个状态
fails[i + 1] = (i ? nxt[fails[i]][k] : 0);
depin_fail[i + 1] = depin_fail[fails[i + 1]] + 1;
}
else nxt[i][k] = (i ? nxt[fails[i]][k] : 0);
}
}
for(int k = 0; k <= 1; k++)
{
nxt[n][k] = (n ? nxt[fails[n]][k] : 0);
}
for(size_t i = 0; i <= n; i++)
{
cnt[i] = (i ? cnt[fails[i]] : 0) + (i < n ? s[i] == '1' : 0);
}
} // KMP 自动机和失配树
struct bfs_state
{
size_t i, j, k;
bool s_in;
size_t pre;
bool lst_c = 0;
bfs_state(size_t i_ = 0, size_t j_ = 0, size_t k_ = 0, bool s_in_ = 0, size_t pre_ = 0, size_t lst_c_ = 0) : i(i_), j(j_), k(k_), s_in(s_in_), pre(pre_), lst_c(lst_c_) {}
} st[1600001]; // bfs 的状态
void output(size_t pid)
{
const auto &[i, j, k, s_in, pre, lst_c] = st[pid];
cout << "id=" << pid
<< " i=" << i
<< " j=" << j
<< " k=" << k
<< " s_in=" << s_in
<< " pre=" << pre;
string ret;
for(; pid; pid = st[pid].pre)
{
ret += (st[pid].lst_c ? '1' : '0');
}
reverse(ret.begin(), ret.end());
if(!ret.size())
{
ret = "empty";
}
cout << " ret=" << ret << endl;
}
bool vis[maxn + 1][maxn + 1][maxn + 1][2];
size_t lst = 0;
int solve()
{
memset(vis, 0, sizeof vis);
cin >> n >> moca >> s;
get_fail();
st[lst = 0] = bfs_state(0, 0, 0, 0, 0, 0); // 起始状态,注意这个的字符不要计入统计
queue<size_t> q;
q.push(lst);
size_t wer = 0;
while(!q.empty())
{
auto id = q.front();
q.pop();/*
output(id);*/
if(st[id].s_in && st[id].k == moca)
{
wer = id;
break;
}
for(int c = 0; c <= 1; c++)
{
const auto &[i, j, k, s_in, pre, lst_c] = st[id];
bfs_state new_st(nxt[i][c], j + (c == 0 ? cnt[i] : 0));
new_st.k = k + new_st.j + (depin_fail[new_st.i] - (new_st.i == n)); // 求真前缀 排除 s
new_st.s_in = (s_in | (new_st.i == n));
new_st.pre = id;
new_st.lst_c = c;
if(vis[new_st.i][new_st.j][new_st.k][s_in] || new_st.k > moca)
{
continue;
}
vis[new_st.i][new_st.j][new_st.k][s_in] = 1;
st[++lst] = new_st;
q.push(lst);
}
}
string ans;
for(; wer; wer = st[wer].pre)
{
ans += (st[wer].lst_c ? '1' : '0');
}
reverse(ans.begin(), ans.end());
if(!ans.size())
{
ans = "Impossible";
}
cout << ans << endl;
return 0;
}
int main()
{
int c, t;
cin.tie(nullptr)->sync_with_stdio(false);
cin >> c >> t;
while(t--)
solve();
return 0;
}
:::
算法时间复杂度方面这里就不具体证明了,感兴趣的可以去看原题题解。大概是先根据所有可能的状态总数有一个上界 \(O(nk^2)\),但添加 \(1\) 操作对 \(k\) 是成平方级别的增长的,所以最后是一个 \(O(nk^{\frac{3}{2}})\)。
一点悄悄话
本系列写作的起因是笔者被 P15650 [省选联考 2026] 摩卡串 / string 创飞后回看发现 KMP 标签疑惑自己为什么连这都做不出来时看到 KMP 自动机直接吓晕。
后面才明白自己的字符串完全属于在地上蠕动的状态(区),决定从零开始再学一遍,慢慢地就有了本系列。
这段话写作的目的也是为了警示后人:不要盲目追求那些看上去 高精尖 的做法,学好基础的算法往往更重要。
故不积跬步,无以至千里;不积小流,无以成江海。
而现代的文章也提出了类似的说法:
真正的强者,从不吝啬对他人的尊重,也从不随意在自己未知的领域指手画脚。
《【杂谈】隔行如隔山:如何正确看待算法竞赛与软件工程》中的内容,我认为于此也适用。不限于单纯的算法竞赛与软件工程间的矛盾与统一,这句话无论在哪里都是适用的。
在这里不同的是,我们审视、批判的不是别人,而正是我们自己。
尊重 一词说起来容易,做起来却难。尊重与自己不同领域的人,尊重那些看似简单的算法,尊重那些仿佛微不足道的数学公理……这样看来,刘慈欣先生在《三体》中的那句话也不无道理:
弱小和无知不是生存的障碍,傲慢才是。
下一篇内容
马拉车[4]还是 SA,又或者是其他串串内容,在评论区下方投票喵。
友链
创作声明
本文遵循 CC BY-NC-SA 4.0 协议。
保证本文未使用任何 AI 工具辅助创作。
转载例如下:
原文作者为 clx201022,转载人保证会遵循 CC BY-NC-SA 4.0 协议:以适当的方式署名,不以盈利为目的进行转载,并以相同方式共享此文。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号