(AAAI26) 攻克场景级伪造检测难题!BR-Gen数据集+NFA-ViT助力伪造检测新突破!
(AAAI26) 攻克场景级伪造检测难题!BR-Gen数据集+NFA-ViT助力伪造检测新突破!
随着生成式AI技术的飞速发展,图像局部篡改手段日益精细,各种伪造内容在视觉上愈发逼真,给内容真实性验证带来了严峻挑战。现有检测方法局限于物体级伪造,对更精细或更广泛的内容束手无策。针对这一领域痛点,厦门大学与腾讯优图实验室联合推出了大规模场景感知局部伪造检测数据集 BR-Gen 与基于伪造特征放大的检测模型 NFA-ViT。该研究已被人工智能顶级会议 AAAI 2026 接收,为解决复杂场景下的伪造检测问题提供了全新的技术方案。

项目主页:https://github.com/clpbc/BR-Gen
论文链接:https://arxiv.org/abs/2504.11922
挑战:现有方法为何在真实场景失效?
当前伪造图像检测领域存在三大核心瓶颈,严重制约了技术落地效果:
- 传统检测方法(如ManTranet)对图像中的全部区域施加同等关注度,而图像中大面积的真实区域特征导致掩盖了微小的伪造痕迹,从而检测失败;
- 基于区域对比的方法(如TruFor)专注于图像中的差异性辨别,识别图像中不同质的两个区域,但没学习到伪造区域或伪造痕迹的具体特征。易导致真实与伪造区域的相互错检,模型倾向于过拟合到具体的数据集形式。

- 现有数据存在严重的“区域与类型偏见”,集中于物体级伪造,如交通工具、生活用品等物体级类型;忽视了现实场景下天空、地面、背景等更广泛的场景级元素的篡改;
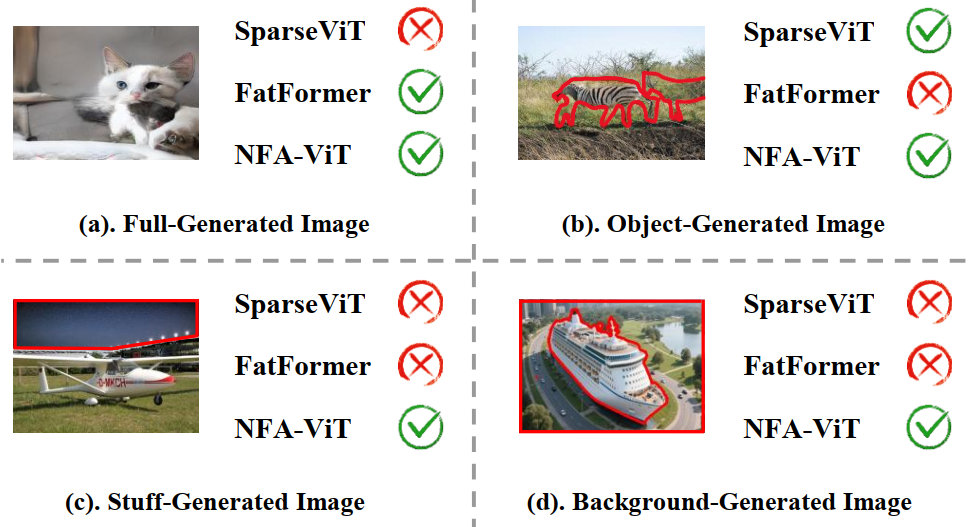
创新:双管齐下,破解现实级伪造检测难题
BR-Gen 数据集与 NFA-ViT 检测模型形成 "数据 + 算法" 的双重突破,从根源上解决现有技术的局限性,构建起高鲁棒性的现实检测体系。
BR-Gen: 首个大规模场景感知伪造检测数据集
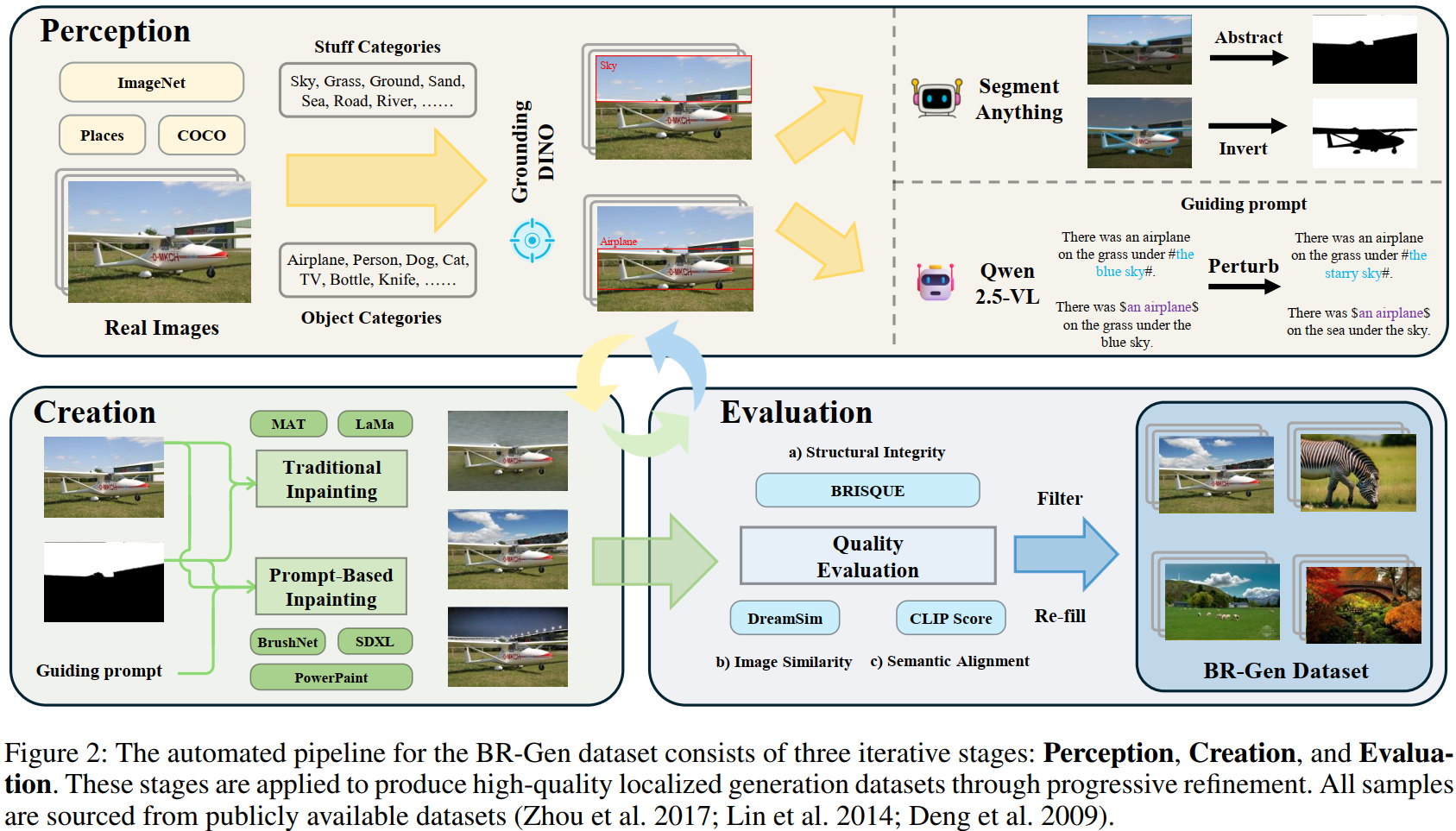
BR-Gen包含15万张高质量局部伪造图像,涵盖场景元素(Stuff)、背景(Background)两大篡改类型,彻底填补了场景级伪造数据的空白。数据构建过程采用 "感知 - 生成 - 评估" 三阶段流水线,确保样本语义连贯性与视觉真实性。
感知阶段,模型理解图像中的各类元素。 GroundingDINO 与 SAM2 进行区域定位与掩码的生成,同时利用当前先进的Qwen2.5-VL视觉多模态模型进行场景的详细感知与元素改写。
生成阶段,模型基于感知信息进行篡改区域的生成。结合当前5种主流的生成模型(2种GAN-based + 3种 Diffusion-based),通过传统Inpainting以及基于Prompt的Inpainting方式进行局部篡改的合成。
评估阶段,模型基于篡改图像进行质量评估并过滤低质图像。通过 CLIP Score、BRISQUE、DreamSim 等多维度指标筛选高质量样本,剔除纹理失真、边界明显的低质数据。
在整个过程中,BR-Gen构建的三阶段形成循环迭代形式,不断提升数据生成的质量,确保最终合成数据的质量及难度。
NFA-ViT:噪声引导的伪造特征放大检测模型
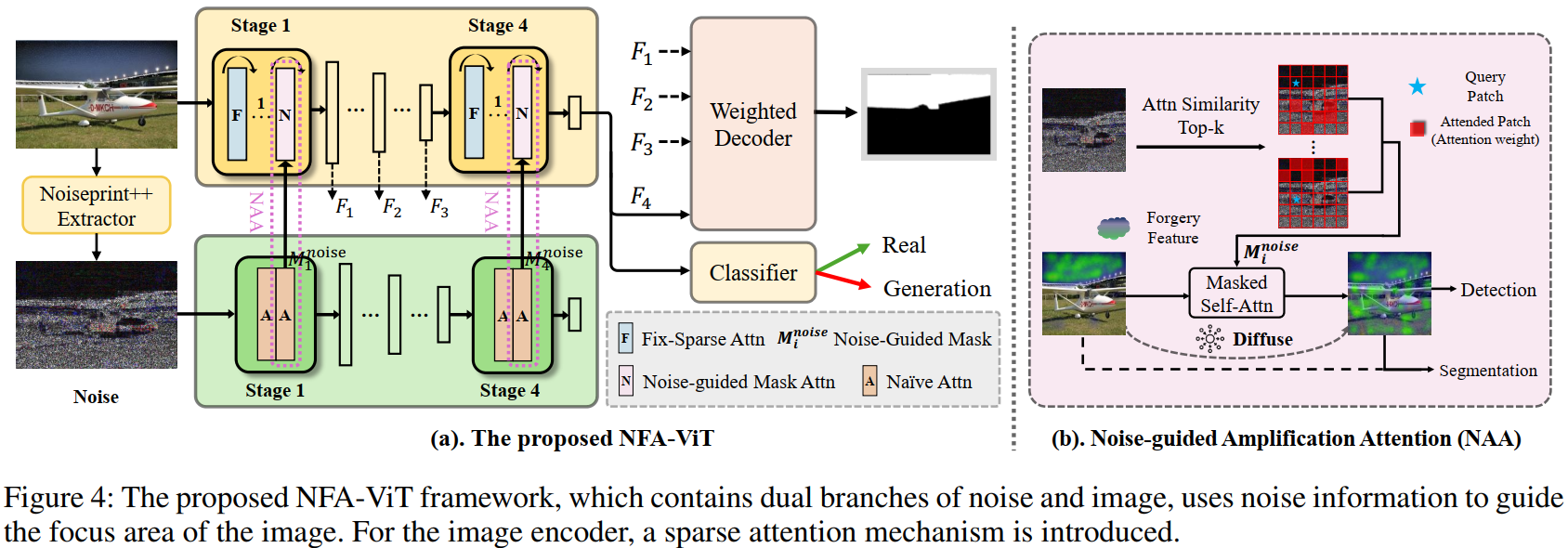
针对传统伪造信号微弱、分散的特点,NFA-ViT 提出了创新的伪造特征放大机制,通过双分支网络结构实现对细微伪造痕迹的放大与伪造特征的精确学习:
核心设计:噪声引导的特征放大
利用 Noiseprint++ 提取图像噪声指纹,通过噪声分支识别真实区域与伪造区域的细微差异,生成噪声引导掩码;在图像分支中引入噪声引导放大注意力(NAA)机制,迫使真实区域与异常区域进行特征交互,将局部微弱的伪造信号扩散至全图,显著提升检测灵敏度。
自适应特征融合解码器
设计加权解码器,通过可学习的缩放参数动态调整不同层级特征的贡献权重,有效整合多尺度特征信息,优化篡改区域定位精度,解决传统特征融合方法效果不佳的问题。
无需复杂微调,泛化能力强劲
模型以 SegFormer 为骨干网络,训练过程简洁高效,在不同类型的伪造数据上均表现出优异的泛化性能。
优势:性能卓越,全面超越现有方案
✅ 数据集更具挑战性:BR-Gen 涵盖现有数据集未覆盖的场景级伪造类型,对现有检测模型构成严峻考验,推动检测技术向更真实场景演进。
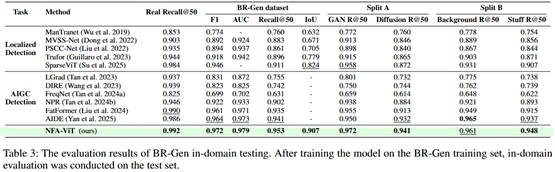
✅ 检测精度领先:在 BR-Gen 数据集上,NFA-ViT 的 F1 分数达到 0.972,IoU 指标高达 0.907,分别超越现有最优模型 0.8% 和 8.3%,在场景级伪造检测任务中表现突出。
✅ 泛化能力强劲:NFA-ViT 能够有效处理不同生成模型、不同篡改尺寸的伪造图像,在跨数据集测试中表现稳定,解决了现有模型泛化能力差的痛点。
✅ 定位精准:通过伪造特征放大机制,即使是微小、分散的场景级伪造区域,也能被精准定位,可视化结果清晰展示了微小的篡改边界。

应用场景与价值
BR-Gen 数据集与 NFA-ViT 模型的推出,不仅填补了场景级局部伪造检测领域的技术空白,更构建了一套 "高质量数据 + 高效检测算法" 的完整解决方案,在多个关键领域都具有重要应用价值:
- 媒体内容审核:助力社交平台、新闻媒体识别经过场景篡改的虚假图像,维护内容生态真实性;
- 数字取证:为司法、版权保护等场景提供精准的图像篡改检测与定位工具,保障合法权益;
- 视觉内容安全:防范 AI 伪造技术被滥用,为企业、政府机构的视觉资产提供安全保障。
未来这种组合范式也将继续推动检测领域技术的发展与进步,为构建可信的数字内容环境提供核心技术支撑。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号