
Linux->Windows主机目录和文件名中文乱码恢复
Linux->Windows主机目录和文件名中文乱码恢复
标签: 字符编码 Python
声明
本文主要记述作者如何通过Python脚本恢复跨平台传输导致的目录和文件名中文乱码。作者对Python编程和字符编码了解不多,纰漏难免,欢迎指正。同时,本文兼做学习笔记,存在啰嗦之处,敬请谅解。
本文同时也发布于作业部落,阅读体验可能更好。
一. 乱码问题
一年前,作者将Windows XP系统主机下创建的一批文件(以多级目录组织),通过Samba手工拷贝至Linux系统主机,能正常显示目录和文件名中包含的中文字符。然后,通过filezilla连接Linux主机,将上述文件下载至移动硬盘,这个过程中也未出现乱码。但将移动硬盘连接到Windows 7系统主机上时,却发现目录和文件名中包含的中文字符出现乱码。
例如,文件名"GNU Readline库函数的应用示例"和"守护进程接收终端输入的一种变通性方法"分别显示为"GNU Readlineåºå½æ°çåºç¨ç¤ºä¾"和"å®æ¤è¿ç¨æ¥æ¶ç»ç«¯è¾å ¥çä¸ç§åéæ§æ¹æ³"。
但除目录和文件名出现中文乱码外,文件内容并无乱码。
作者当时并不熟悉字符编码知识,于是请教《通俗易懂地解决中文乱码问题(1) --- 跨平台乱码》一文的作者Roly-Poly。Roly-Poly非常热心地转换了上述两个文件名,并给出效果图:

以及相应的Java转换方法:
String str = new String(new String(messyName.getBytes("ISO-8859-1"), "GBK").getBytes("GBK"), "UTF-8");
其中,messyName对应出现乱码的字符串。getBytes(charset)将Unicode编码存储的字符串按照charset编码,并以字节数组表示;new String(bytes[], charset)则将字节数组按照charset编码进行组合识别,最后转换为Unicode存储。因此,上述代码表示先将当前编码从 ISO-8859-1转为GBK,然后再从GBK转为UTF-8。
当然,Roly-Poly的转换仍有缺憾,毕竟还存在未能正确解析的乱码。"幸运"的是,当时出于谨慎,作者分别通过dir /S path、tree /F path(Windows)和ls -lRS --time-style=long-iso(Linux)创建了三份文件列表。这样,在Roly-Poly转码的基础上再做些校验,有望替换为完全正确的文件名。
然而,一方面因为作者对Java语言和字符编码比较陌生(主要是懒),另一方面因为解析文件列表并更名的工作量预期较大,作者一直未付诸实践。直到最近,才开始从头着手处理乱码问题。这一过程学到不少知识,也走过不少弯路。教训就是:凡事要一鼓作气!
二. 调试环境
作者使用Python 2.7自带的IDLE进行编码调试。除非特别说明,本文所有代码均为Python语言。
参考Python字符编码详解一文,获取当前环境的默认编码:
#!/usr/bin/python
# -*- coding: utf-8 -*-
import sys, locale
def SysCoding():
fmt = '{0}:{1}'
#当前系统所使用的默认字符编码
print fmt.format('DefaultEncoding ', sys.getdefaultencoding())
#转换Unicode文件名至系统文件名时所用的编码('None'表示使用系统默认编码)
print fmt.format('FileSystemEncoding ', sys.getfilesystemencoding())
#默认的区域设置并返回元祖(语言, 编码)
print fmt.format('DefaultLocale ', locale.getdefaultlocale())
#用户首选的文本数据编码(猜测结果)
print fmt.format('PreferredEncoding ', locale.getpreferredencoding())
if __name__ == '__main__':
SysCoding()
作者的Windows XP系统主机上,区域和语言选项->区域选项->标准和格式及高级->非Unicode程序的语言均设置为"中文(中国)";Windows 7系统主机上,区域和语言->格式及管理->非Unicode程序的语言均设置为"中文(简体,中国)"。两台主机的SysCoding()输出相同,均显示如下:
DefaultEncoding :ascii
FileSystemEncoding :mbcs
DefaultLocale :('zh_CN', 'cp936')
PreferredEncoding :cp936
三. 目录和文件名乱码恢复
3.1 可选方案
3.1.1 通过合适的编解码转换
可使用chardet模块detect()函数检测给定字符的编码。该函数返回检测到的编码'encoding'及其可信度'confidence'。
安装方法为:命令提示符下执行C:\Python27\Scripts>easy_install.exe chardet后,自动下载egg文件包。若未安装成功(import提示"ImportError: No module named chardet"),可到C:\Python27\Lib\site-packages目录解压egg文件包,将其中的chardet目录(所有文件)拷贝到site-packages下面即可。
安装成功后,按照以下方法检测字符编码:
#coding: gbk
import chardet
print chardet.detect('abc') #{'confidence': 1.0, 'encoding': 'ascii'}
print chardet.detect('喊') #{'confidence': 0.73, 'encoding': 'windows-1252'}
print chardet.detect('汉') #{'confidence': 0.99, 'encoding': 'TIS-620'} ##Thailand
print chardet.detect('汉中华人民共和国') #{'confidence': 0.99, 'encoding': 'GB2312'}
print '汉中华人民共和国', repr('汉中华人民共和国')
#汉中华人民共和国 '\xba\xba\xd6\xd0\xbb\xaa\xc8\xcb\xc3\xf1\xb9\xb2\xba\xcd\xb9\xfa'
可见,当字符"样本"过少时,chardet检测结果并不准确(如'汉'被识别为泰文)。在Shell中执行上述检测时,结果与之相同。
作为对比,声明为coding: utf-8时,检测结果又是另一番"景象":
import chardet
print chardet.detect('abc') #{'confidence': 1.0, 'encoding': 'ascii'}
print chardet.detect('æCUnitè¿è¡') #{'confidence': 0.99, 'encoding': 'utf-8'}
print chardet.detect('喊') #{'confidence': 0.73, 'encoding': 'windows-1252'}
print chardet.detect('汉') #{'confidence': 0.73, 'encoding': 'windows-1252'}
print chardet.detect('汉中华人民共和国') #{'confidence': 0.99, 'encoding': 'utf-8'}
print '汉中华人民共和国', repr('汉中华人民共和国')
#姹変腑鍗庝汉姘戝叡鍜屽浗 '\xe6\xb1\x89\xe4\xb8\xad\xe5\x8d\x8e\xe4\xba\xba\xe6\xb0\x91\xe5\x85\xb1\xe5\x92\x8c\xe5\x9b\xbd'
可见,'å£è¯å¥æ_æ°æµ'被检测为UTF-8编码。这是因为UTF-8是ASCII的超集。当字符串序列中所有字符均为ASCII符号(前128个字符)时,chardet认为该串为ASCII编码;当字符串序列中也含有所有扩展ASCII符号时,chardet很可能认为该串为UTF-8编码。此外,print根据本地操作系统默认字符编码(GBK),将'汉中华人民共和国'打印为姹変腑鍗庝汉姘戝叡鍜屽浗。
3.1.2 根据文件列表信息匹配
通过正则表达式提取文件列表中的目录大小、文件数目、文件名及其大小、创建时间等信息,再遍历移动硬盘乱码目录,进行匹配和更名。为保险起见,应维护一份映射文件,存储文件路径、原名和新名,以便恢复或校正。
为减少匹配和更名次数,只操作名称包含字母数字以外字符的目录和文件。此外,还可对文件列表排序,如dir path /S /O:S(按大小升序排列)。
3.1.3 机器学习
因为word、网页等文件打开后通常可以看到标题,作者得以整理若干文件乱码名与正常名的映射数据。这样,借助机器学习(如基于实例的算法),最终有望消除所有乱码。
显然,这一方案难度太高,并不现实。
3.2 逐步实践
3.2.1 获取单级目录及其文件信息
首先,创建名称正常的多级目录供调试用。之所以不用原始乱码目录调试,是因为一旦测试失败很可能会破坏"样本"。
然后,通过以下代码获取单级目录的大小、文件数目、文件名及大小、创建时间等信息:
import time
from os.path import join, getsize, getmtime, getctime
CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))
#os.getcwd()返回当前工作目录
def FilesInfo():
for root, dirs, files in os.walk(CURRENT_DIR):
for file in files:
path = join(root, file)
ctime = time.ctime(getctime(path)) #创建时间
print 'Name:%-12s Size:%-7s Ctime:%s' %(file, getsize(path), ctime)
print root, "consumes",
print sum(getsize(join(root, file)) for file in files),
print "bytes in", len(files), "non-directory files!"
注意,当本模块由其他模块import并执行时,os.getcwd()返回的并非本模块目录。
执行FilesInfo()后,输出结果如下:
Name:Coding.py Size:7936 Ctime:Mon Feb 29 09:41:15 2016
Name:d_res.bmp Size:522534 Ctime:Mon Feb 29 09:41:15 2016
Name:error3.bmp Size:70782 Ctime:Mon Feb 29 09:41:15 2016
Name:Open.bmp Size:354746 Ctime:Mon Feb 29 09:41:15 2016
Name:Thumbs.db Size:19968 Ctime:Mon Feb 29 09:41:47 2016
Name:typec.bmp Size:199022 Ctime:Mon Feb 29 09:41:15 2016
Name:WalkDir.py Size:4894 Ctime:Mon Feb 29 09:41:15 2016
Name:复Coding.py Size:6564 Ctime:Mon Feb 29 15:41:37 2016
E:\PyTest\stuff consumes 1186446 bytes in 8 non-directory files!
3.2.2 从文件列表中提取目录和文件信息
在命令提示符下dir \F出调试目录的结构。截取部分如下:
C:\Program Files\IDM Computer Solutions\UEStudio>e:
E:\PyTest 的目录
2016-02-24 11:53 <DIR> .
2016-02-24 11:53 <DIR> ..
2016-02-23 17:22 1,434 backup_ver2.py
然后,通过ParseFileList()函数解析出"E:\PyTest"之类的路径:
import codecs, re
def ParseFileList():
#Windows记事本默认的字符编码为"ANSI"(实际是GBK)
file = codecs.open(r'E:\PyTest\filelist.txt', encoding='gbk')
for line in file:
#下句等效于m = re.match(u' (.+) 的目录\s*$', line)
m = re.compile(u""" # Python默认字符编码为Ansi, 需加u转为Unicode
(.+) 的目录 # 将' 的目录'前的部分作为分组(Group)
\s*$ # 行尾""", re.X).match(line)
if m != None:
print m.groups()[0]
注意,此处并未使用内置的open()方法打开文件。因为该方法得到的line为str类型,需要使用正确的编码格式进行decode(),否则将无法匹配到"的目录"。而codecs.open()方法打开文件时读取的就是Unicode类型,不容易出现编码问题。
当然,若将源代码文件中的字符编码声明改为#coding=gbk,并去掉pattern字符串前缀u,则使用内置的open()方法仍可匹配到"的目录"。
目录大小、文件数目、文件名及其大小等,均可通过合适的正则表达式提取。然而,作者很快意识到,根据文件列表遍历和更名的方案实现起来过于复杂。于是,放弃正则匹配的尝试。
3.2.3 遍历目录并更名
虽然文件列表正则匹配的方案不可行,但遍历和更名却是所有方案所必需的。
Python中有三种遍历目录的方法,即os.listdir()、os.walk()和 os.path.walk()。这三者中,作者首选os.walk()方法,遍历代码如下:
import os
def ValidateDir(dirPath):
#判断路径是否为Unicode。若否,将其转换为Unicode编码
if isinstance(dirPath, unicode) == False:
#下句等效于dirPath = dirPath.decode('utf8')
dirPath = unicode(dirPath, 'utf8')
#判断路径是否存在(不区分大小写)
if os.path.exists(dirPath) == False:
print dirPath + ' is non-existent!'
return ''
#判断路径是否为目录(不区分大小写)
if os.path.isdir(dirPath) == False:
print dirPath + ' is not a directory!'
return ''
return dirPath
def WalkDirReport(dirPath, fileNum):
print '##############' + str(fileNum) + ' files processed##############'
def WalkDir(dirPath):
dirPath = ValidateDir(dirPath)
if not dirPath:
return
#遍历路径下的文件及子目录
fileNum = 0
for root, dirs, files in os.walk(dirPath):
for file in files:
#处理文件
#ChangeNames(root, file)
#RestoreNames(root, file)
fileNum += 1
while(fileNum % 100) == 0:
prompt = '$' + str(fileNum) + ' files processed, ' \
+ '''pause for checking. Type 'c' to continue: '''
if raw_input(prompt) == 'c':
break
WalkDirReport(dirPath, fileNum)
其中,ValidateDir()用于校验路径合法性,同时还将非Unicode路径转为Unicode路径(该步骤也可由使用者自行完成)。
os.listdir()方法遍历目录则较为"笨拙",对比如下:
def WalkDir_unsafe(dirPath):
dirPath = ValidateDir(dirPath)
if not dirPath:
return
#遍历路径下的文件及子目录
fileNum = 0
nameList = os.listdir(dirPath)
for name in nameList:
path = os.path.join(dirPath, name)
#类型为目录,递归(存在栈溢出风险)
if os.path.isdir(path) == True:
fileNum += WalkDir_unsafe(path)
continue
#处理文件
'''此时name等效于os.path.basename(path),即文件名;
dirPath等效于os.path.dirname(path),即目录名;
path等效于os.path.abspath(os.path.basename(path)),即绝对路径'''
fileNum += 1
return fileNum
因为采用递归处理,所以该方法存在栈溢出风险(不过作者尚未遇到这种情况)。使用时,需按照如下方式调用:
WalkDirReport(r'E:\Pytest\测试', WalkDir_unsafe(r'E:\Pytest\测试'))
注意,虽然os.walk()本身仍由os.listdir()递归实现,但却是生成器(generator)写法,相比普通递归更节省内存资源。
遍历目录调试通过后,就可着手实现目录和文件更名。为简单起见,更名规则为"尾部添0",即"E:\a\b.txt"会转换为"E:\a0\b.txt0"。同时提供恢复函数,以便反复调试。代码如下:
def ChangeNames(dir, file):
#将'E:\a\b.txt'转换为'E:\a0\b.txt0',以此类推
filePath = os.path.join(dir, file)
newdir = dir.split('\\')
newdir[1:] = map(lambda x: x+'0', newdir[1:]) #盘符不变
newdir = '\\'.join(newdir)
ufilePath = os.path.join(newdir, file) + '0'
print filePath + ' => ' + ufilePath
os.renames(filePath, ufilePath)
def RestoreNames(dir, file):
#将'E:\a0\b.txt0'恢复为'E:\a\b.txt',以此类推
filePath = os.path.join(dir, file)
newdir = dir.split('\\')
newdir[1:] = map(lambda x: x[:-1], newdir[1:])
newdir = '\\'.join(newdir)
ufilePath = os.path.join(newdir, file)[:-1]
print filePath + ' => ' + ufilePath
os.renames(filePath, ufilePath)
可见,"添0"和恢复的方法比较"笨拙"。但作为Python新手,作者暂时只能如此。结合遍历代码,ChangeNames()和RestoreNames()可有效地更名和恢复。
注意os.renames()方法,该方法可对嵌套目录及其文件更名,可能会创建临时目录以存放新命名的子目录和文件。因此,若以WalkDir(r'E:\bPytest')方式调用且bPytest目录下存在空的子目录,则更名后该子目录保持原名原位置(仍在E:\bPytest目录下),而其他子目录及文件被更名且"转移"到E:\bPytest0目录下——同时出现bPytest和bPytest0两个目录!
3.2.4 消除单个文件名乱码
遍历和更名调试成功后,接下来便是重中之重——乱码文件名恢复。
浏览各种网络资料后,作者终于在Stackoverflow网站上一则问答Getting correct utf8 Chinese characters from messed-up iso-8859-1 in Python and MySQL里找到一线曙光。回答者通过u'最'.encode('cp1252').decode('utf8')成功地将最转换为"最"——这与作者遇到的乱码何其相似!
在尝试cp1252、cp1254...等众多Windows编码后,作者终于找到正确的编码格式,即latin_1,别名iso-8859-1, iso8859-1, 8859, cp819, latin, latin1, L1。测试代码如下:
print u'项ç®ä¸éæCUnitè¿è¡å¼åæµè¯'.encode('latin_1').decode('utf8')
print u'ãNBCå¤é´æ°é»(2011-2å£)'.encode('latin_1').decode('utf8')
print 'æ°æµªå客'.decode('utf8').encode('latin_1').decode('utf8')
其中,u'string'等效于'string'.decode('utf8')。运行结果为:
项目中集成CUnit进行开发测试
《NBC夜间新闻(2011-2季)
新浪博客
经人工检验,完全符合期望!
此时再回想Roly-Poly提供的Java转码语句:
String str = new String(new String(messyName.getBytes("ISO-8859-1"), "GBK").getBytes("GBK"), "UTF-8");
因为字符串在Java内存中以Unicode编码存储,且getBytes()和new String()分别对应Python里的encode()和decode(),所以等效的Python转码语句如下:
str = u'messyName'.encode('latin_1').decode('gbk').encode('gbk').decode('utf8')
从字符编码规则可知,经过GBK编解码"中转"后,很可能出现data loss。以第一章的两个文件名为例,其Python转码如下:
s1 = u'GNU Readlineåºå½æ°çåºç¨ç¤ºä¾'.encode('latin_1').decode('gbk').encode('gbk','replace').decode('utf8')
s2 = u'å®æ¤è¿ç¨æ¥æ¶ç»ç«¯è¾å
¥çä¸ç§åéæ§æ¹æ³'.encode('latin_1').decode('gbk','replace').encode('gbk','replace').decode('utf8','replace')
s3 = u'å®æ¤è¿ç¨æ¥æ¶ç»ç«¯è¾å
¥çä¸ç§åéæ§æ¹æ³'.encode('latin_1').decode('utf8')
print s1 #GNU Readline库函数的应用示例
print s2 #守护进程接收终�?输入的一种变通�?方法
print s3 #守护进程接收终端输入的一种变通性方法
其中,'replace'参数以适当的字符替换编解码过程中无法识别的字符,否则将产生UnicodeDecodeError和UnicodeEncodeError异常。可见,就本文问题而言,并不需要GBK编解码"中转"。
3.2.5 消除单级目录下文件名乱码
文件名字符串乱码恢复成功后,接下来将对文件更名。该步骤需要在挂接移动硬盘的Windows 7主机上进行,因为在Windows XP主机上文件名乱码无法以期望的方式显示和解析。例如:
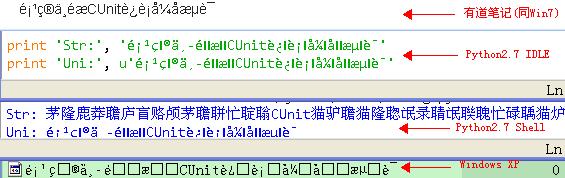
最后那个以乱码字符串为名创建的文件,无法打开(UEStudio提示"含有一个无效的路径",记事本提示"无效的窗口句柄"),os.rename()也会报错。
在Windows 7主机上,作者从移动硬盘拷贝一个单级乱码目录至磁盘作调试用。然后,编写代码恢复该目录下的所有乱码文件名:
from nt import chdir
def RecodeName(dirPath):
nameList = os.listdir(dirPath)
for fileName in nameList:
try:
ufileName = fileName.encode('latin_1').decode('utf8')
except UnicodeEncodeError as e:
print '[e]' + fileName + '(Possibly needn\'t xcode!)'
continue
print (fileName + ' => ' + ufileName)
#rename之前要先用chdir()函数进入到目标文件所在的路径
chdir(dirPath)
os.rename(fileName, ufileName)
因为存在某些文件已被手工更名的可能性,encode('latin_1')时会抛出UnicodeEncodeError异常,所以需要跳过这些文件。
运行结果如下:
8.26å京990å°ç»éªï¼å¸æ对以åç人æå¸®å© - è±è¯æä¸èè¯(TOEIC) - 大家论å -.url => 8.26南京990小经验,希望对以后的人有帮助 - 英语托业考试(TOEIC) - 大家论坛 -.url
~2011.5.29~æä¸905ææ³~æ谢大家ç½è®ºå~å¸æè½ç»å¤§å®¶å¸¦æ¥å¸®å© - è±è¯æä¸èè¯(TOEIC) - 大家论å -.url => ~2011.5.29~托业905感想~感谢大家网论坛~希望能给大家带来帮助 - 英语托业考试(TOEIC) - 大家论坛 -.url
ä¸å½é
æç½.url => 中国雅思网.url
å¦ä½æé«è±è¯å¬å_æé«è±è¯å¬åçæ¹æ³_å¬å课å .url => 如何提高英语听力_提高英语听力的方法_听力课堂.url
>>>
经验证,指定目录下所有乱码文件名均正确恢复。
3.2.6 消除嵌套目录名及其文件名乱码
单级目录下文件名乱码消除后,作者换用os.renames()方法消除嵌套目录名及其文件名。代码如下:
def RecodeNames(dir, file):
filePath = os.path.join(dir, file)
try:
filePathNew = filePath.encode('latin_1').decode('utf8')
except UnicodeEncodeError as e:
'''os.renames()会创建临时目录以存放新命名的子目录和文件,故此处异常
表明最底层文件已解码成功(可能是手工处理),但其目录路径仍未解码。
因此,需构造已解码全路径,以便renames将上述文件拷贝至新目录。
'''
print '[e]' + filePath + '(Possibly needn\'t xcode!)'
filePathNew = os.path.join(dir.encode('latin_1').decode('utf8'), file)
print (filePath + ' => ' + filePathNew)
os.renames(filePath, filePathNew)
以WalkDir(r'F:\Pytest\Study')运行,结果如下:
F:\Pytest\Study\John_æ°æµªå客.url => F:\Pytest\Study\John_新浪博客.url
[e]F:\Pytest\Study\ABR\~2011.5.29~托业905感想~感谢大家网论坛~希望能给大家带来帮助 - 英语托业考试(TOEIC) - 大家论坛 -.url(Possibly needn't xcode!)
F:\Pytest\Study\ABR\~2011.5.29~托业905感想~感谢大家网论坛~希望能给大家带来帮助 - 英语托业考试(TOEIC) - 大家论坛 -.url => F:\Pytest\Study\ABR\~2011.5.29~托业905感想~感谢大家网论坛~希望能给大家带来帮助 - 英语托业考试(TOEIC) - 大家论坛 -.url
F:\Pytest\Study\å¾
读\ãNBCå¤é´æ°é»(2011-2å£)ã(NBC Nightly News)([m4v]è±è¯å¬åä¸è½½ -å¦ä¹ èµæåº.url => F:\Pytest\Study\待读\《NBC夜间新闻(2011-2季)》(NBC Nightly News)([m4v]英语听力下载 -学习资料库.url
##############3 files processed##############
可见,根目录和子目录及所有下属文件均正确更名。
读者可能已经注意到,上述根目录路径名均为英文字符。假如该路径包含已解码的中文目录名(可能是手工处理)呢?例如将Study目录名改为外语学习。显然,encode('latin_1')时会触发UnicodeEncodeError异常。因此,编解码时需要跳过这些中文目录名:
def RecodeNames(dir, file):
filePath = os.path.join(dir, file)
#对路径解码
paths = filePath.split('\\')
for i in range(len(paths)):
try:
paths[i] = paths[i].encode('latin_1').decode('utf8')
except UnicodeEncodeError as e:
#路径可能出现已解码的中文(可能是手工处理),不再重复解码
continue
filePathNew = '\\'.join(paths)
print (filePath + ' => ' + filePathNew)
os.renames(filePath, filePathNew)
什么?假如目录名包含部分乱码部分中文字符?拜托,这种情况不可能出现。
3.2.7 恢复原始乱码目录和文件名
激动人心的时刻来到了!本节将正式处理移动硬盘中的原始乱码目录和文件名。基于以上调试结果,最终的乱码恢复代码如下:
failedNamesList = []
def RecordFailedNames(name):
failedNamesList.append(name)
import ctypes
def RecodeNames(dir, file):
filePath = os.path.join(dir, file)
#对路径解码
paths = filePath.split('\\')
for i in range(len(paths)):
try:
paths[i] = paths[i].encode('latin_1').decode('utf8')
except UnicodeEncodeError as e:
#路径可能出现已解码的中文(可能是手工处理),不再重复解码
continue
filePathNew = '\\'.join(paths)
print (filePath + ' => ' + filePathNew)
try:
os.renames(filePath, filePathNew)
except WindowsError as e:
print "[e]WindowsError({0}): {1}".format(e.winerror, ctypes.FormatError(e.winerror))
RecordFailedNames(filePath)
def WalkDirReport(dirPath, fileNum):
print '##############' + str(fileNum) + ' files processed##############'
print 'Failed files(%d):' %(len(failedNamesList))
for i in range(len(failedNamesList)):
print ' ' + failedNamesList[i]
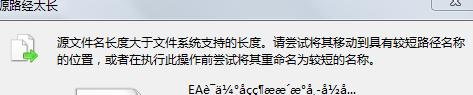
某些乱码文件名过长(多为.mht文件),os.renames()时会触发WindowsError[3]异常,如:

事实上,在资源管理器里打开这些文件时,会提示"源路径过长":
上述代码可有效地恢复原始乱码目录和文件名。当时的运行截图如下:
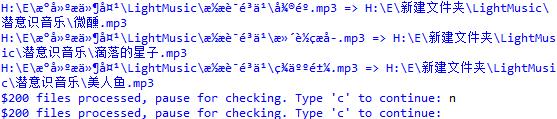
以及

经初步检验,更名成功。此时可通过tree命令生成生成目录树,与原先保存的文件列表对比。遗憾的是,两者树状列表顺序不同,无法直接对比。当然,如果够闲,也可以编程比照。
四. 后记
本文所述的乱码恢复实践其实是种"摸着石头过河(trial and error)"的过程。如果当初先研究字符编码,而不是左右开弓,应该会避免不少弯路。当然论及性价比,孰优孰劣,亦未可知。
最后,关于Python字符编码基础知识,作者将在后续文章中加以说明,同时澄清本文一些谬误之处。脸皮薄,就不说"敬请期待"了~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号