
Stratix内嵌存储器测试报告
Stratix和Stratix GX系列器件内嵌TriMatrix存储块包括512-bit M512块、4-Kbit M4K块及512-Kbit M-RAM块。TriMatrix存储结构可对输入和输出RAM块的信号加上寄存器级,实现同步(pipelined) RAM。所有TriMatrix存储器输入均为寄存器级,提供同步写周期。输出寄存器可被旁路(bypassed)。全同步的简单或真正双端口TriMatrix存储器的工作速度高达312MHz,可工作于flow-through模式(仅有输入寄存器级)或pipelined模式(输入输出寄存器级)。
Stratix和Stratix GX系列器件不支持异步存储器(没有输入输出寄存器级),但支持 flow-through读取,即在时钟周期里读地址载入时输出数据有效(the output data is available during the clock cycle when the read address is driven into it)。对于简单/真正双端口M512和M4K存储块,在时钟下降沿读入读使能和读地址寄存器值(clocking the read enable and read address registers on the negative clock edge),并将输出寄存器旁路,就实现了flow-through读取。
声明:以下测试均基于Stratix系列EP1S40F1020C5器件。所给出的波形图均为实测结果,只是分析理解未必正确,仅供参考。
一. altdpram测试
TriMatrix存储器支持混合宽度配置,即允许读写端口数据宽度不同。在这种模式下,低位LSB最先写入/读出。
例如写数据(输入)宽度为8bit,读数据(输出)宽度为2bit。设二进制数据0000_0001写入写地址wrdaddress 0,则输出端读出数据如表1所示:
表1 混合宽度配置
|
读地址rdaddress |
×2 data |
|
00 |
01(LSB of ×8 data) |
|
01 |
00 |
|
10 |
00 |
|
11 |
00(MSB of ×8 data) |
1.1 文本输入方式
采用文本输入方式描述了一个32×8的RAM块。其中输入数据宽度为8bit,输出数据宽度为2bit。读输出地址宽度为7bit写输入地址宽度为5bit,低地址存低位,高地址存高位。
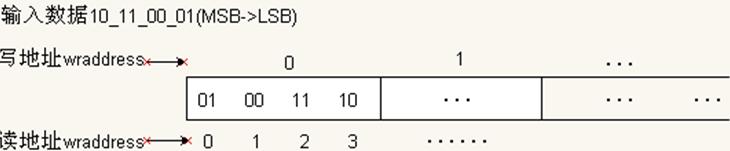
图1 RAM块存储单元示意图
该RAM块的设计,利用了Quartus软件LPM宏单元库中的altdpram函数。altdpram函数描述了一个简单的双端口RAM。一个端口只能写,一个只能读,读写有两套总线,读和写有各自的时钟线、地址总线、数据总线和使能端,可同时进行读写操作。此外altdpram模块还有一个全局清零端口。

图2 简单双端口RAM模型
同步altdpram的读写时序仿真波形如图3和图4所示。这里inclk和outclk共用一个时钟clock。加上输出级寄存器后,读出数据延时了一个时钟周期,但时钟到输出延时非常小,且Altera强烈推荐采用同步RAM,因此这种RAM完全适合于时钟频率较高的应用。
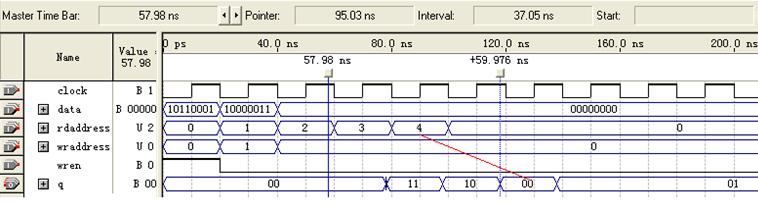
图3 altdpram仿真波形-1
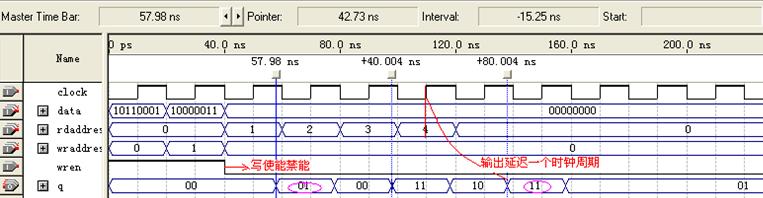
图4 altdpram仿真波形-2
图3中,第一个时钟周期里,wren写使能有效。时钟沿到来时,输入数据10110001锁存入写地址wrdaddress 0指示的存储单元,读地址rdaddress 0读出的数据是写入前的旧值(00)。从第二个地址rdaddress 1开始读新写入的值(00)。第二个时钟周期,wren禁能,输入数据10000011无效,所以rdaddress 4读出wrdaddress 1所指存储单元的旧值(00)。
图4中有两处改动,即wren、rdaddress 0信号持续至第二个时钟周期。观察粉色椭圆所圈的数据,可知符合以上的分析。
1.2 图形输入方式
采用图形输入方式,直接调用lpm参数化模块库中的altdpram符号。端口连接相应输入输出,如图5所示:

图5 altdpram简单双端口电路原理图
编译结果及仿真波形与文本输入方式基本相同。注意,在设置altdpram器件的参数时,没有选择输出级寄存器,输出数据比图3、4早一个时钟周期。
Note:
1. 打开Quartus -> Help -> Contents目录下Shortcuts -> Megafunctions/LPM或选择Help -> Mega functions/LPM命令,即可获得参数库的元件帮助文档。
Quqrtus软件由于某些原因而停止响应时,关闭重启后打开工程。可从File -> Recent Projects打开工程。如果没有弹出HDL文件及.vwf波形文件,可从Project Navigator中打开,不必重新寻找文件路径。当然,一般还要对工程进行再编译。
RAM读写数据时,如果Functional仿真波形正确,Timing仿真波形有误,那么可能是读写时钟频率过高,将周期变大试试看。此外,Timing仿真更接近实际情况,而且Timing仿真时会指定RAM块的类型,从而确定时钟的触发沿(如M512和M4K在时钟下降沿写入,M-RAM则在上升沿写入)。当然,在时序要求比较宽松时,一般先进行功能仿真,不必考虑延时(除了内核固有延时),便于验证。
2. 在一个工程下可以编译多个HDL文件或原理图。Project -> Set as Top-Level Entity将当前工作文件设置为顶层文件,则Compile时只编译顶层文件及其所调用的模块(波形文件仿真时必须在Simulator Tool中添加相应的.vwf文件)。注意同一工程下建立和添加多个文件时(包括图形编辑窗中多个模块),一定要在Device Design Files中添加所需文件或删除不存在文件的路径,否则编译时会出现“…undefined…”或“…missing..”之类的错误。此外,多个文件名不能重名,否则会出现实体“…already exists…”的编译警告。
文件名不要采用“123”、“***_v”、“***_vhd”等形式。
3. 波形数据段可以前后拖动或复制粘贴,这可在一定程度上减少重新赋值的麻烦。拖动不同于复制或重设,不会因为没有对齐而产生“毛刺”。选中一段波形按“Delete”键,即可删除该段波形。
在“Edit”中将“End Time”增大一倍,波形会自动复制一份(而不是全零值)接在原波形的后面。“Grid Size”可设置网格大小,当网格设置很小时可将波形图放大,否则有时显示不出小精度的网格。
编辑波形文件时,Node Finder里设置Filter-->Pins:all & Registers:post-fitting,可以将中间寄存器加入波形仿真中,便于观察中间结果。需要注意的是,修改源程序并编译后,初始化波形文件中节点node一般无需重新添加,除非源程序中修改了位宽参数。
4. 在Quartus II的时序分析报告中,选中要查看的时序路径,单击鼠标右键,即可弹出一些查看路径细节的选项。如果选择“Locate”-->“Locate in RTL Viewer”或“Locate in Technology Map Viewer”,就可看到RTL或工艺映射查看器中对应的路径。如果选择“List Paths”命令,则在Quartus II的“消息窗口(Message Window)”的System页面中看到所选路径的延时细节。推荐第二种方式,因为在消息窗口可以展开路径细节,同时点击右键也有“Locate”选项。
注意,RTL Viewer基于初步综合编译,所以所示的时序路径可能不准确(不过会给出类似教材中直观的路径,便于对照理解)。另外,RTL Viewer列出了源节点和目的节点之间所有可能的路径。为了获得更准确的时序路径,可以在Technology Map Viewer中查看。
5. 推荐采用混合输入方式,这样可以利用图形输入方式设计和调试的优点。例如在图形编辑窗中调用参数库元件并设置参数后,如果再想修改某些参数,就可以在该例化块上点右键选择“MegaWizard Plug-in Manager”,修改相应参数后右键“Update Symbol or Block”即可,非常方便且不易出错。
如果要将LPM中的某一宏功能块,如lpm_rom、lpm_ram、lpm_fifo作为自己以HDL表述的设计项目中的一个元件,可以首先利用Quartus内嵌的宏功能块处理器,根据项目需要对LPM块的参数作适当设置,由此产生一个特定的LPM HDL源程序描述,最后利用元件例化语句,在顶层设计中调用该模块。
6. Quartus中对于altdpram宏单元的建议:
This megafunction is provided only for backward compatibility in Cyclone, Cyclone II, HardCopy Stratix, Stratix, and Stratix GX designs; instead, Altera recommends using the altsyncram megafunction. …… Altera strongly recommends using synchronous rather than asynchronous RAM functions.
编译时的警告:
Warning: Assertion warning: altram does not support Stratix device family -- attempting best-case memory conversions, but power-up states and read during write behavior will be different for Stratix devices.
即altram类型的RAM块不支持Stratix系列器件。后面的lpm_ram_dq、lpm_ram_dq也有同样的建议和警告,但是仿真结果均与理论分析吻合。换用altram支持的系列器件,仿真波形与之相同。
另外,最好在Tools -> MegaWizard Plug-In Manager中的storage部分选择库元件,因为此处可以设置器件系列,不支持的库元件会不显示或不可选。而在图形编辑窗用“symbol”选择参数库元件时,不能保证这点。此外,MegaWizard Plug-In Manager可以设置生成HDL文件和波形文件,尤其是波形文件特别有用,形象地给出了仿真波形示例,极大地方便了理解元件功能。当然,这里给出的波形文件是基于Functional仿真的(也只能给出功能仿真示例,因为时序仿真对不同的器件结果是不同的)。
二. lpm_ram_dp测试
lpm_ram_dp参数模块可配置成一个口读,一个口写,读写可以同时进行,也可以配置成两个口同时读或者同时写。其配置及功能与altdpram基本相同,只是没有全局清零端口。
三. altsyncram测试
可定制简单ROM,单端口RAM,简单双端口RAM,真正双端口RAM。图6所示即为真正双端口RAM模型,图中左边的A端口和右边的B端口都支持读写操作,wren信号高为写操作,低为读操作。
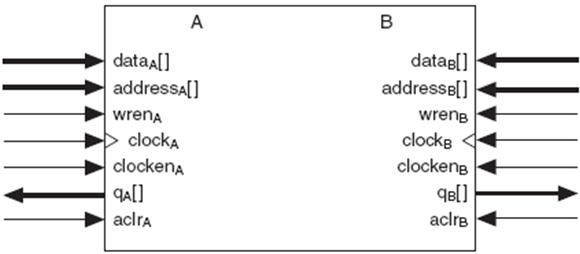
图6 真正双端口RAM模型
在M4K和M-RAM存储块中,字节使能(byte enable)可以屏蔽(mask)输入数据以便仅写入特定的字节。未写入的字节单元保持原来写入的旧值。写使能信号(wren)与字节使能信号(byteena)一起控制RAM块的写操作。byteena信号的缺省值为高电平(enabled),此时写操作仅由wren信号控制。
只有altsyncram宏功能具有字节使能端。当采用M4K存储块时,要求输入数据宽度为16、18、32或36bit,否则字节使能端口不可选。M4K的字节选择功能如表2所示:
表2 M4K存储块的字节使能
|
byteena |
datain×18 |
datain×36 |
|
[0] = 1 |
[8..0] |
[8..0] |
|
[1] = 1 |
[17..0] |
[17..9] |
|
[2] = 1 |
— |
[26..18] |
|
[3] = 1 |
— |
[35..27] |
采用图形设计输入方式,直接调用lpm参数化模块库中的altsyncram符号。端口连接相应输入输出,如图7所示:

图7 altsyncram真双端口电路原理图
其中,输入数据宽度为16bit,输出数据宽度也为16bit。地址宽度为5bit,字节使能信号2bit。RAM块大小为2^5×16。
编译仿真结果如图8所示:
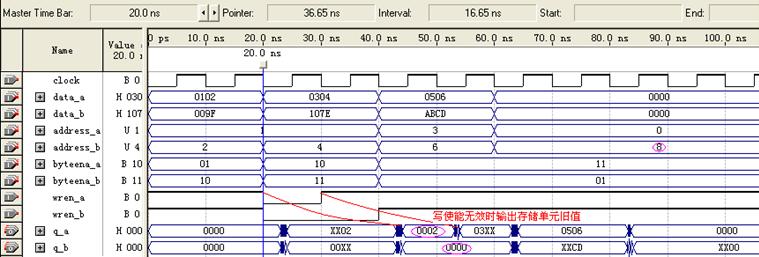
图8 altsyncram仿真波形
如图8所示,第三个时钟沿到来时,wren_a为低电平(disabled)并持续一个时钟周期。此时data_a输入数据0304h无法写入,q_a输出为0002h。之所以高字节为00h,是因为前一个data_a输入数据0102h的高字节未写入address_a 1地址指示的存储单元(字节使能信号byteena_a为01),从而该存储单元的值为0002。
在第四个时钟沿到来时,wren_a为高电平(enabled),byteena_a为10,此时输入数据高字节03h写入address_a 1单元,低字节04h被屏蔽,q_a输出03XXh。
至于为什么wren_a为高,byteena_a为01时q_a输出XX20h;wren_a变低时输出0002h,原因还不清楚。只是参数库提供的波形也是这样的。
注意:在双端口RAM方式下,无论是读或写都是针对同一个物理RAM块进行的。address_a 0与address_b 0指示同样的存储单元,所以在65.0ns时钟上升沿到来时,address_a与address_b分别置为0和8。如果均指向单元0,则会出现下面的警告:
Warning: Simultaneous write to memory block address 0 at time 68.9ns in vector source file -- data is invalid in memory block.
四.altshift测试
在一些DSP应用中,如FIR滤波器、伪随机码生成器、多信道滤波、自相关和协相关函数等,往往需要一些多抽头的移位寄存器来存储本地数据。传统的实现方法时用FPGA内部的触发器串接组成,优点是抽头灵活,容易使用,但在实际设计中,往往会出现LE中的触发器资源紧张的情况。M512和M4K支持移位寄存器模式,用它们来实现移位寄存器可节省逻辑单元和布线资源,并且效率更高。
设移位寄存器输入数据宽度为w,抽头(taps)长度为m,抽头数为n。如图9所示。在用RAM块实现移位寄存器时,需满足w×n小于RAM块最大支持的数据宽度,w×n×m小于RAM块的最大比特数。M4K的最大数据宽度为18bit,最大比特数为576。M4K的最大数据宽度为36bit,最大比特数为4608。而如果需要更大的移位寄存器可以用更多的RAM级联实现。
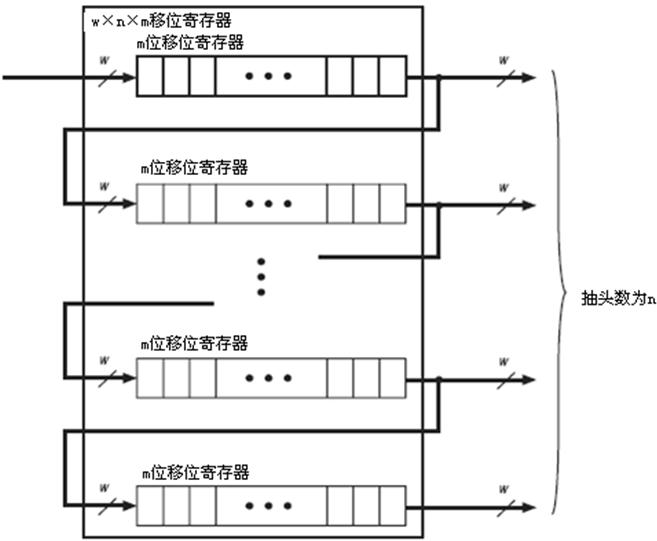
图9 RAM块实现移位寄存器
在MegaWizard Plug-In Manager中调用altshift_tags,勾选“Create groups for each tap output”。如图10所示:
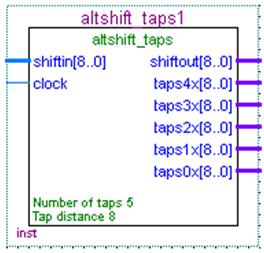
图10 altshift_tags移位寄存器模型
设置移入移出数据宽度(w)均为9bit,移位宽度(m)为9bit。时延参数模块建立的移存器,没有对m即每级移存器宽度的设置,默认和数据宽度w相同。抽头数taps为n,抽头距离(tap_distance)为3,表示经过3个时钟周期才移到下一级。中间各级结果taps可输出。
编译仿真结果如图11所示:

图11 altshift测试仿真波形
五.lpm_ram_dq测试
lpm_ram_dq模块相对简单,读与写共用一组地址总线,有各自的数据线和时钟线。该测试加入了内存初始化文件mif。若没有数据写入端口,该模块就实现了ROM功能。
所有的Stratix存储器配置都必须为同步输入,因此ROM的地址线均有一级寄存器输入级。输出数据可以有一级寄存器输出级(Registered),也可以不选该寄存器级(combinatorial)。ROM的读操作等效于单端口RAM的读操作。
测试电路原理图如图12所示,其中we为写使能信号。

图12 lpm_ram_dq电路原理图(单端口RAM应用)
下面是VHDL格式的ROM数据初始化文件(文件可用任何文本编辑器实现):


1 WIDTH = 9; --存储器数据宽度为9位 2 DEPTH = 16; --存储器容量为16个单元 3 4 ADDRESS_RADIX = HEX; --地址用16进制表示 5 DATA_RADIX = BIN; --数据用二进制表示 6 7 CONTENT BEGIN 8 00 : 000000001; --前一列表示地址,后一列表示该地址的初始化数据 9 01 : 111101100; 10 02 : 111111101; 11 ………… 12 0E : 111011110; 13 0F : 000001100; 14 END;
初始化存储单元内容如图13所示,定义了16×8的RAM块(仅仅是模拟ROM)。

图13 初始化存储单元内容
编译仿真结果如图14所示:
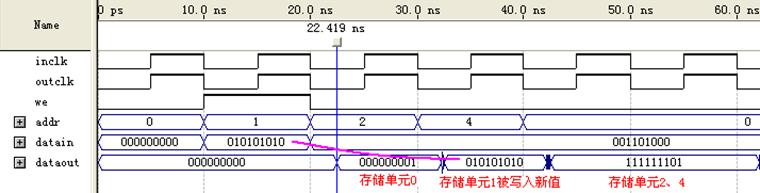
图14 lpm_ram_dq仿真波形
可以看出,在we写使能为高(enabled)时,输入数据datain(010101010)写入addr 1指示的内存单元。其他时钟周期的功能等效于ROM。
如果采用文本输入方式,可参考以下程序:
1 /*****instantiation of lpm_ram_dq, 9-bit data, 16 address location****/ 2 module lpm_ramdq_test(dataout,datain,addr,we,inclk,outclk); 3 4 parameter data_width = 9, addr_width = 4; 5 output[data_width-1:0] dataout; //端口定义 6 input[data_width-1:0] datain; 7 input[addr_width-1:0] addr; 8 input we,inclk,outclk; 9 10 //lpm_ram_dq 元件例化 11 lpm_ram_dq ram( .data(datain),.address(addr),.we(we),.inclock(inclk),.outclock(outclk),.q(dataout)); 12 defparam ram.lpm_width = data_width; //定义数据宽度 13 defparam ram.lpm_widthad = addr_width; //定义地址宽度 14 defparam ram.lpm_indata = "REGISTERED"; 15 defparam ram.lpm_outdata = "REGISTERED"; 16 defparam ram.lpm_file = "lpm_ramdq_test.mif"; //RAM块中的内容取自该文件 17 18 endmodule
六.lpm_ram_io测试
lpm_ram_io模块数据输入输出口为单一的IO口,共用一组地址总线和数据总线,与普通的RAM一样。它不可编辑只能直接调用。
在MegaWizard Plug-In Manager中调用lpm_ram_io。如图15所示:

图15 lpm_ram_io模型
其中,inclock实现由IO口向存储器载入数据同步化,inclock实现由存储器读数据到IO口同步化。dio为存储器双向数据端口。we写使能,高电平时向存储器写操作有效。outenab输出使能,高电平时由存储器读数据到IO口,低电平时由IO口写数据至存储器中。
表3 inclock上升沿时同步读/写(所有输入寄存器级)
|
we |
outenab |
功能 |
|
L |
L |
高阻(输出禁能) |
|
× |
H |
地址所指存储单元数据读到dio口 |
|
H |
L |
dio口写数据到地址所指存储单元 |
编译结果如图16所示:
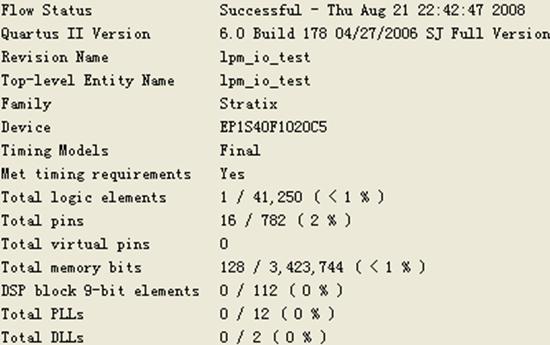
图16 lpm_ram_io测试编译报告
仿真波形如图17、18所示:
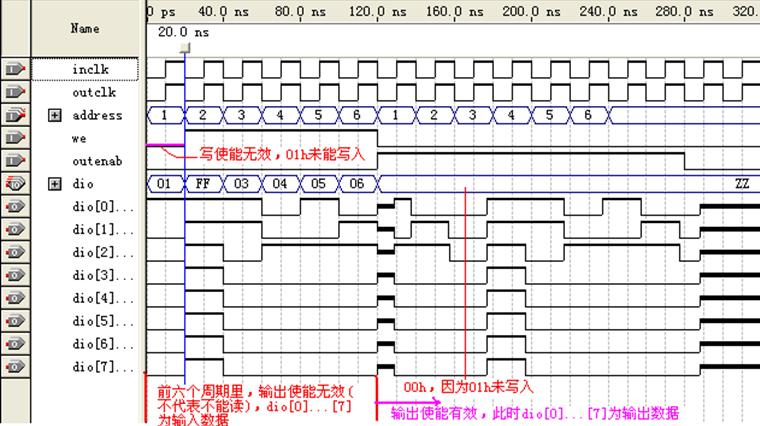
图17 lpm_ram_io测试仿真波形-1
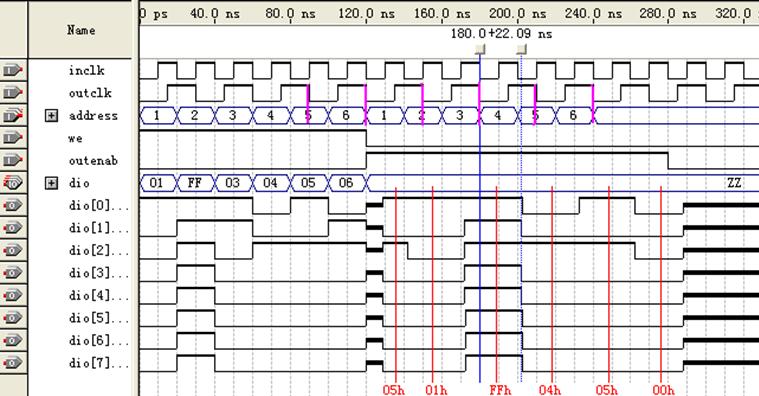
图18 lpm_ram_io测试仿真波形-2
如图17所示we为低,outenab为高时,输出dio并非立即输出address 1指向的存储内容(01h),而是先输出了address 5和6指向的内容(05h、06h)。图18中也有类似情况。与师兄讨论得知,他也遇到这样的疑惑,不清楚原因何在。我查看了帮助文档,也没有找到明确的解释。
-------------------------------以下的分析方法不正确。正确分析见《基于建立/保持时间等的参数化时序分析》一文----------------------------
初步想法是,inclk上升沿控制写入数据,outclk下降沿控制输出数据。为什么猜测inclk和outclk采用不同的触发沿呢?我想,可能是为了避免读写冲突。实际设计中,常会将inclk和outclk连接在一起共用一个时钟,这样如果采用同样的触发沿,we与outenab同时为高时,就会出现同时对一个存储单元进行读写。究竟是先读后写还是先写后读呢?如果we先作用,则读出新写入的数据;反之则读出旧值。而lpm_ram_io并没有类似lpm_ram_dp的解决读写冲突的机制,所以只好借助inclk和outclk采用不同的触发沿来解决冲突。
在前六个inclk时钟周期里,虽然we为高,outclk仍能控制输出寄存器,只是此时outenab为低,输出禁能(输出寄存器只进不出而已)。由于inclk与outclk之间存在延迟,所以当第六个inclk时钟周期结束时,outclk下降沿将address 5和6指向的内容指向的内容输入(此时输出使能!),这就解释了图18中红线所指05h…00h及之前一小段高阻。
附:Quartus II帮助文档关于lpm_ram_io的描述(也是疑惑之处:注意outclk的触发沿)

测试一altdpram仿真中,inclk和outclk共用一个时钟clock。如果采用两个不同的时钟,仿真波形也符合关于lpm_ram_io的分析。波形如图19所示:
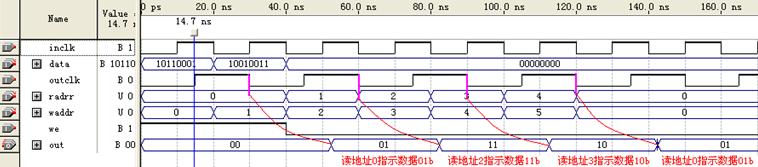
图19 altdpram不同时钟测试仿真波形
-------------------------------以上的分析方法不正确。正确分析见《基于建立/保持时间等的参数化时序分析》一文----------------------------
七.lpm_ram_shiftreg测试
Altera建议使用lpm_shiftreg宏功能代替其他类型的移存器功能。
在MegaWizard Plug-In Manager中调用lpm_shiftreg。如图20所示:
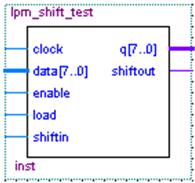
图20 lpm_shiftreg移位寄存器模型
enable为时钟使能输入。对于串行移位操作,load取低电平(缺省值),enable必须为高电平。对于并行加载(load)操作,load必须为高电平,而enable必须为高或不接。
data是将要进行移位的数据,由load控制输入。q是移位以后得到的结果。shiftin是移入补位的bit,shiftout是移出的bit。当LPM_DIRECTION="LEFT"时,shiftout端口值等于q[LPM_WIDTH-1];当LPM_DIRECTION="RIGHT"时,shiftout端口值等于q[0]。
编译结果如图21所示,表明lpm_shiftreg是用LE综合的,并未用到RAM块。
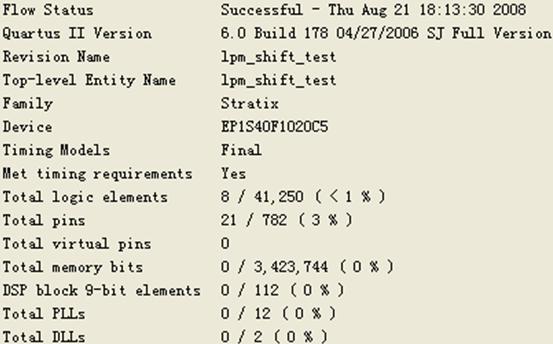
图21 lpm_shiftreg测试编译报告
仿真波形如图22所示:

图22 lpm_shiftreg仿真波形
八.附录
对同一地址的Read-During-Write(RDW)操作
对同一地址同时读写有两种情况,即:相同端口(same-port)和混合端口(mixed-port)。
图23描述了两种端口RDW模式下的数据流。

图23 RDW端口模式数据流
1. 相同端口RDW模式
对于单端口RAM或真正双端口RAM的RDW模式,新数据在其被写入的时钟的上升沿有效(the new data is available on the rising edge of the same clock cycle it was written on)。任意大小的存储块均如此。
图24给出了相同端口RDW模式的功能仿真波形(未加输出级寄存器)。
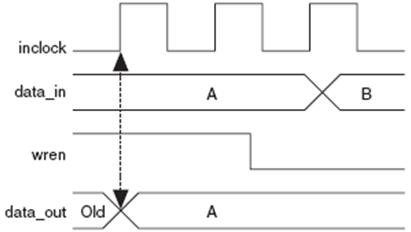
图24 lpm_shiftreg仿真波形
2. 混合端口RDW模式
对于简单或真正双端口RAM的RDW模式,在同一个时钟上升沿,两个端口同时对同一地址写操作或者进行读写两种操作,则会发生冲突。前者称为写冲突,后者称为读写冲突。
发生写冲突时存入该地址单元的将是未知的。要实现有效地向同一个地址单元写入数据,A端口的写时钟(write clock)上升沿必须出现在B端口的写时钟上升沿后的最大写周期时间间隔之后(the rising edge of the write clock for port A must occur following the maximum write cycle time interval after the rising edge of the write clock for port B)。因为在写时钟的下降沿,数据被写入M512和M4K RAM块中,所以A端口写时钟的上升沿要比B端口时钟的下降沿晚到来1/2个最大写时钟周期(the rising edge of the write clock for port A should occur following half of the maximum write cycle time interval after the falling edge of the write clock for port B)。如果不满足这个时间要求,则存入此地址单元的数据无效。
发生读写冲突时,一般此时写入数据有效,读出数据为未知(Unkown)。但是M512和M4K内部的一种机制允许用户选择发生读写冲突时希望读出的输出值:该次写操作之前的旧(Old)值还是未知(Unkown)值。如果用户选择了旧值,那么读操作将立即在本次时钟“上升沿”完成,读出旧值,而写操作将在紧跟其后的时钟“下降沿”完成,把新值写入RAM中,同时又避免了同一时钟沿的读写冲突。
在MegaWizard中生成RAM时可选择读写冲突的读出值,如图25所示:
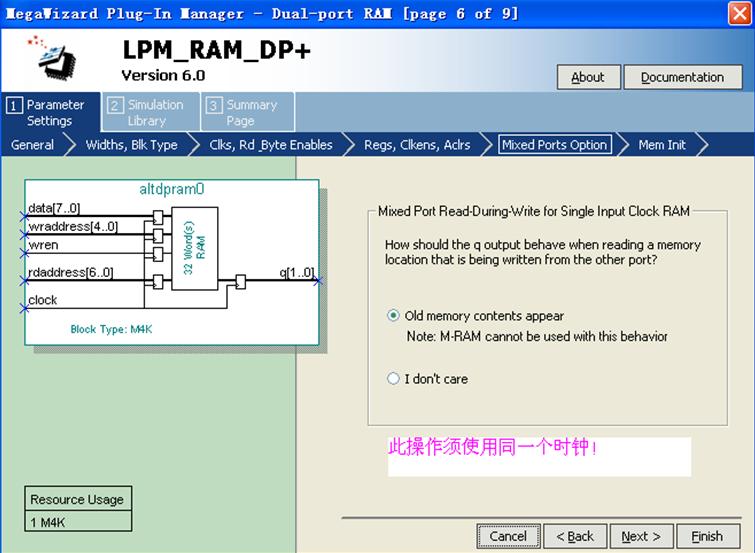
图25 lpm_shiftreg仿真波形
图26和图27给出了混合端口RDW模式的功能仿真波形(未加输出级寄存器)。
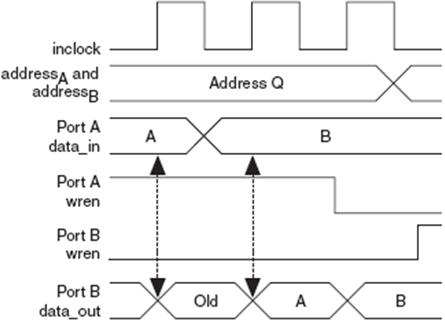
图26 混合端口RDW功能仿真波形-1(OLD_DATA)
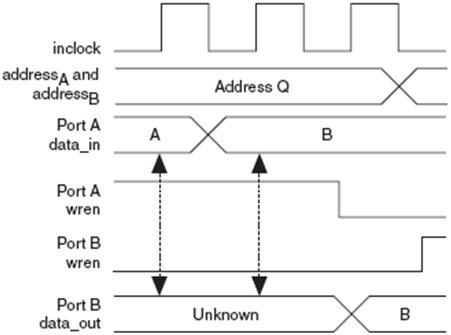
图27 混合端口RDW功能仿真波形-2(DONT_CARE)
注意,如果M512和M4K在实现双端口RAM时,两个端口使用不同的时钟,则发生读写冲突时,读出值也只能是未知值,因为这时读写时钟沿将不受控制。
在MegaWizard中选择“I don't care”或调用模块时设置参数DONT_CARE(取旧值设为OLD_DATA),将memory function植入TriMatrix存储块时编译器具有更大灵活性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号